Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano wyzwalacze zdarzeń związanych z magazynem, które można utworzyć w potokach usługi Azure Data Factory lub Azure Synapse Analytics.
Architektura sterowana zdarzeniami to typowy wzorzec integracji danych, który obejmuje produkcję, wykrywanie, zużycie i reakcję na zdarzenia. Scenariusze integracji danych często wymagają od klientów wyzwalania potoków wyzwalanych ze zdarzeń na koncie usługi Azure Storage, takich jak przybycie lub usunięcie pliku na koncie usługi Azure Blob Storage. Technologie Data Factory i Azure Synapse Analytics natywnie integrują się z usługą Azure Event Grid, co pozwala na uruchamianie potoków w odpowiedzi na określone zdarzenia.
Zagadnienia dotyczące aktywacji zdarzeń przechowywania danych
Podczas korzystania z wyzwalaczy zdarzeń magazynu należy wziąć pod uwagę następujące kwestie:
- Integracja opisana w tym artykule zależy od usługi Azure Event Grid. Upewnij się, że subskrypcja jest zarejestrowana u dostawcy zasobów usługi Event Grid. Aby uzyskać więcej informacji, zobacz Dostawcy zasobów i ich typy. Musisz mieć możliwość wykonania
Microsoft.EventGrid/eventSubscriptions/czynności. Akcja ta jest częścią wbudowanej roliEventGrid EventSubscription Contributor. - Jeśli używasz tej funkcji w usłudze Azure Synapse Analytics, upewnij się, że subskrypcja została również zarejestrowana u dostawcy zasobów usługi Data Factory. W przeciwnym razie zostanie wyświetlony komunikat z informacją, że "tworzenie subskrypcji zdarzeń nie powiodło się".
- Jeśli konto usługi Blob Storage znajduje się za prywatnym punktem końcowym i blokuje dostęp do sieci publicznej, należy skonfigurować reguły sieci, aby umożliwić komunikację z usługi Blob Storage do usługi Event Grid. Możesz udzielić dostępu magazynu do zaufanych usług Azure, takich jak Event Grid, zgodnie z dokumentacją usługi Storage, lub skonfigurować prywatne punkty końcowe dla usługi Event Grid, które są mapowane na przestrzeń adresową sieci wirtualnej, zgodnie z dokumentacją usługi Event Grid.
- Wyzwalacz zdarzeń związanych z magazynowaniem danych obsługuje obecnie tylko konta usługi Azure Data Lake Storage Gen2 i konta magazynowe ogólnego przeznaczenia wersji 2. Jeśli pracujesz ze zdarzeniami magazynu protokołu bezpiecznego transferu plików (SFTP), musisz również określić API danych SFTP w sekcji filtrowania. Ze względu na ograniczenia Event Grid, usługa Data Factory obsługuje maksymalnie 500 wyzwalaczy zdarzeń magazynowych na jedno konto magazynowe.
- Aby utworzyć nowy wyzwalacz zdarzenia pamięci masowej lub zmodyfikować istniejący, konto platformy Azure używane do logowania się do usługi oraz do wdrażania wyzwalacza zdarzenia pamięci masowej musi mieć odpowiednie uprawnienia kontroli dostępu opartej na rolach (Azure RBAC) na koncie pamięci masowej. Żadne inne uprawnienia nie są wymagane. Główna usługa dla Azure Data Factory i Azure Synapse Analytics nie potrzebuje specjalnych uprawnień do konta magazynu ani usługi Event Grid. Aby uzyskać więcej informacji na temat kontroli dostępu, zobacz sekcję Kontrola dostępu oparta na rolach.
- Jeśli zastosowano blokadę Azure Resource Manager na koncie przechowywania, może to mieć wpływ na możliwość wyzwalacza blobów do tworzenia lub usuwania blobów. Blokada
ReadOnlyuniemożliwia tworzenie i usuwanie, a blokadaDoNotDeleteuniemożliwia usunięcie. Upewnij się, że uwzględnisz te ograniczenia, aby uniknąć problemów z wyzwalaczami. - Nie zalecamy używania wyzwalaczy przybycia plików jako mechanizmu wyzwalającego wyjść przepływu danych. Przepływy danych wykonują szereg zadań zmiany nazw plików i przetasowania plików partycji w folderze docelowym, które mogą przypadkowo wyzwolić zdarzenie pojawienia się pliku przed zakończeniem przetwarzania danych.
Tworzenie wyzwalacza za pomocą interfejsu użytkownika
W tej sekcji pokazano, jak utworzyć wyzwalacz zdarzenia magazynowania w interfejsie użytkownika potoku usługi Azure Data Factory i Azure Synapse Analytics.
Przejdź do karty Edycja w usłudze Data Factory lub na karcie Integracja w usłudze Azure Synapse Analytics.
W menu wybierz pozycję Wyzwalacz, a następnie wybierz pozycję Nowy/Edytuj.
Na stronie Dodawanie wyzwalaczy wybierz pozycję Wybierz wyzwalacz, a następnie wybierz pozycję + Nowy.
Wybierz typ wyzwalacza zdarzenia magazynowania.
Wybierz swoje konto magazynu z listy rozwijanej subskrypcji Azure lub ręcznie, używając identyfikatora zasobu konta magazynu. Wybierz kontener, na którym mają wystąpić zdarzenia. Wybór kontenera jest wymagany, ale wybranie wszystkich kontenerów może prowadzić do dużej liczby zdarzeń.
Właściwości
Blob path begins withiBlob path ends withumożliwiają określenie kontenerów, folderów i nazw obiektów blob, dla których mają być odbierane zdarzenia. Wyzwalacz zdarzenia przechowywania wymaga zdefiniowania co najmniej jednej z tych właściwości. Można użyć różnych wzorców dla właściwościBlob path begins withiBlob path ends with, jak pokazano w przykładach w dalszej części tego artykułu.-
Blob path begins with: ścieżka blobu musi rozpoczynać się od ścieżki folderu. Prawidłowe wartości to2018/i2018/april/shoes.csv. Nie można wybrać tego pola, jeśli nie wybrano kontenera. -
Blob path ends with: Ścieżka obiektu blob musi kończyć się nazwą pliku lub rozszerzeniem. Prawidłowe wartości toshoes.csvi.csv. Nazwy kontenerów i folderów, po określeniu, muszą być oddzielone segmentem/blobs/. Na przykład kontener o nazwieordersmoże mieć wartość/orders/blobs/2018/april/shoes.csv. Aby określić folder w dowolnym kontenerze, pomiń znak wiodący/. Na przykładapril/shoes.csvwyzwala zdarzenie w dowolnym pliku o nazwieshoes.csvw folderze o nazwieaprilw dowolnym kontenerze.
Należy pamiętać, że
Blob path begins withiBlob path ends withsą jedynymi dozwolonymi wzorcami dopasowania w wyzwalaczu zdarzeń pamięci masowej. Inne typy dopasowywania znaków wieloznacznych nie są obsługiwane dla typu wyzwalacza.-
Wybierz, czy wyzwalacz odpowiada na zdarzenie utworzenia obiektu blob, zdarzenie usunięcia obiektu blob lub oba te zdarzenia. W określonej lokalizacji magazynu każde zdarzenie wyzwala potoki usługi Data Factory i Azure Synapse Analytics skojarzone z wyzwalaczem.
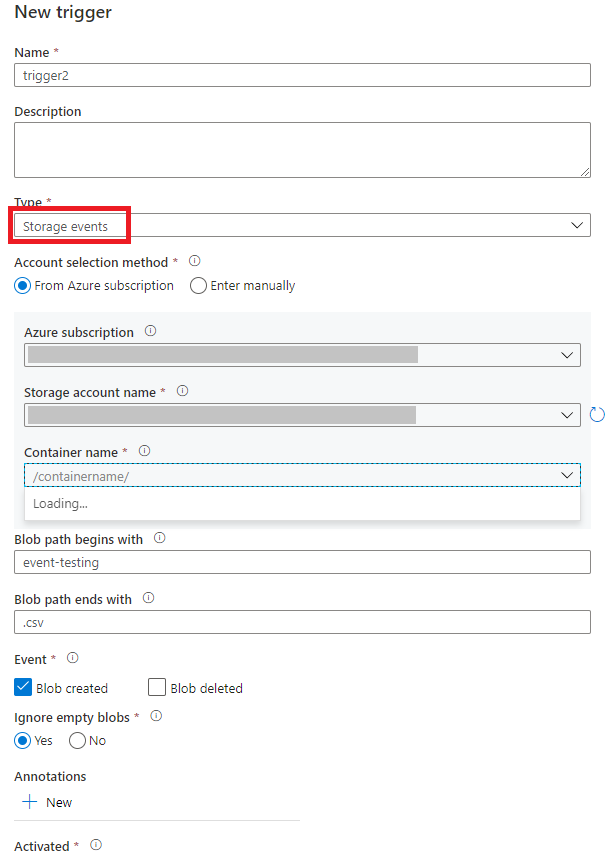
Wybierz, czy wyzwalacz ma ignorować blob z zerową liczbą bajtów.
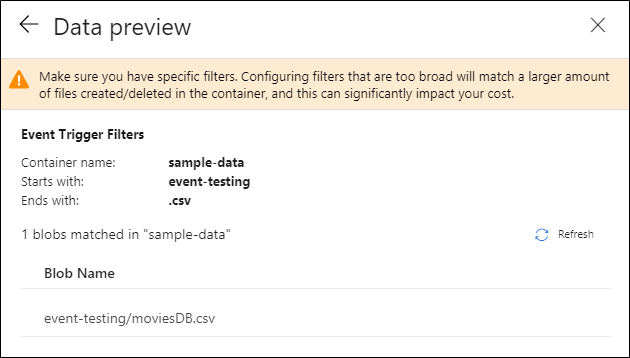
Po skonfigurowaniu wyzwalacza wybierz pozycję Dalej: podgląd danych. Na tym ekranie przedstawiono istniejące obiekty blob zgodne z konfiguracją wyzwalacza zdarzeń przechowywania. Upewnij się, że masz określone filtry. Konfigurowanie filtrów, które są zbyt szerokie, może odpowiadać dużej liczbie plików, które zostały utworzone lub usunięte i może znacząco wpłynąć na koszt. Po zweryfikowaniu warunków filtrowania wybierz pozycję Zakończ.
Aby dołączyć potok do tego wyzwalacza, przejdź do kanwy potoku i wybierz Wyzwalacz>Nowy/Edytuj. Po wyświetleniu okienka bocznego wybierz listę rozwijaną Wybierz wyzwalacz i wybierz utworzony wyzwalacz. Wybierz pozycję Dalej: podgląd danych, aby potwierdzić, że konfiguracja jest poprawna. Następnie wybierz przycisk Dalej , aby sprawdzić, czy podgląd danych jest poprawny.
Jeśli potok ma parametry, możesz je określić w okienku parametrów uruchamiania wyzwalacza. Wyzwalacz zdarzenia magazynowego przechwytuje ścieżkę folderu i nazwę pliku bloba we właściwościach
@triggerBody().folderPathi@triggerBody().fileName. Aby użyć wartości tych właściwości w potoku, należy przypisać właściwości do parametrów potoku. Po zamapowaniu właściwości na parametry, w całym potoku można uzyskać dostęp do wartości przechwyconych przez wyzwalacz za pomocą wyrażenia@pipeline().parameters.parameterName. Aby uzyskać szczegółowe wyjaśnienie, zobacz Reference trigger metadata in pipelines.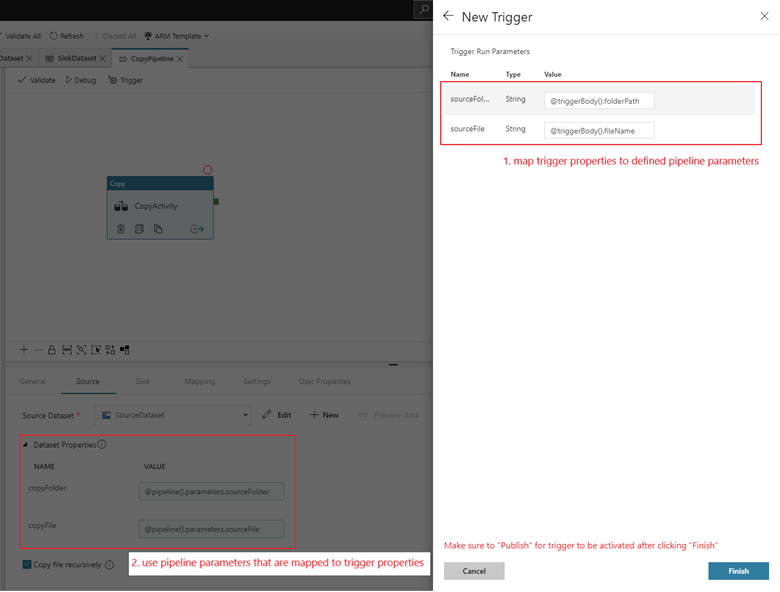
W poprzednim przykładzie wyzwalacz jest skonfigurowany do uruchamiania, gdy ścieżka obiektu blob kończąca się na .csv zostanie utworzona w folderze event-testing w kontenerze sample-data. Właściwości
folderPathifileNameodzwierciedlają lokalizację nowego obiektu blob. Na przykład po dodaniu MoviesDB.csv do ścieżki sample-data/event-testing@triggerBody().folderPathma wartośćsample-data/event-testingi@triggerBody().fileNamema wartośćmoviesDB.csv. Te wartości są mapowane w przykładzie na parametrysourceFolderisourceFilepotoku, które mogą być używane w całym jego przebiegu odpowiednio jako@pipeline().parameters.sourceFolderi@pipeline().parameters.sourceFile.Po zakończeniu wybierz pozycję Zakończ.


Schemat systemu JSON
Poniższa tabela zawiera omówienie elementów schematu związanych z wyzwalaczami zdarzeń związanych z magazynowaniem.
| Element JSON | opis | Typ | Dozwolone wartości | Wymagane |
|---|---|---|---|---|
| zakres | Identyfikator zasobu usługi Azure Resource Manager dla konta magazynu. | Sznurek | Identyfikator usługi Azure Resource Manager | Tak. |
| wydarzenia | Typ zdarzeń, które powodują wyzwolenie tego wyzwalacza. | Tablica |
Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Tak, dowolna kombinacja tych wartości. |
blobPathBeginsWith |
Ścieżka obiektu blob musi zaczynać się od wzorca, który został podany, aby wyzwalacz mógł się uruchomić. Na przykład wyzwalacz uruchamia się tylko dla obiektów blob znajdujących się w folderze /records/blobs/december/ w kontenerze december. |
Sznurek | Podaj wartość co najmniej jednej z następujących właściwości: blobPathBeginsWith lub blobPathEndsWith. |
|
blobPathEndsWith |
Ścieżka obiektu blob musi kończyć się zadanym wzorcem, aby wyzwalacz się uruchomił. Na przykład december/boxes.csv uruchamia wyzwalacz tylko dla obiektów blob nazwanych boxes w folderze december. |
Sznurek | Podaj wartość co najmniej jednej z następujących właściwości: blobPathBeginsWith lub blobPathEndsWith. |
|
ignoreEmptyBlobs |
Określa, czy obiekty blob o zerowej długości uruchamiają potok. Domyślnie jest to ustawiona wartość true. |
Boolowski | prawda lub fałsz | Nr. |
Przykłady wyzwalaczy zdarzeń przechowywania
Ta sekcja zawiera przykłady ustawień wyzwalacza zdarzeń pamięci.
Ważne
Musisz uwzględnić segment ścieżki /blobs/, jak pokazano w poniższych przykładach, za każdym razem, gdy określasz kontener i folder, kontener i plik lub kontener, plik i folder. W przypadku blobPathBeginsWith interfejs użytkownika automatycznie dodaje /blobs/ między nazwą folderu a nazwą kontenera w pliku JSON wyzwalacza.
| Własność | Przykład | opis |
|---|---|---|
Blob path begins with |
/containername/ |
Odbiera zdarzenia dla dowolnego obiektu blob w kontenerze. |
Blob path begins with |
/containername/blobs/foldername/ |
Odbiera zdarzenia dla obiektów blob w kontenerze containername oraz folderze foldername. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
Możesz również odwołać się do podfolderu. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Odbiera zdarzenia dla bloba o nazwie file.txt w folderze foldername w kontenerze containername. |
Blob path ends with |
file.txt |
Odbiera zdarzenia dla obiektu blob o nazwie file.txt w dowolnej ścieżce. |
Blob path ends with |
/containername/blobs/file.txt |
Odbiera zdarzenia dla obiektu blob o nazwie file.txt w kontenerze containername. |
Blob path ends with |
foldername/file.txt |
Odbiera zdarzenia dla obiektu blob o nazwie file.txt w folderze foldername w dowolnym kontenerze. |
Kontrola dostępu oparta na rolach
Potoki usługi Data Factory i Azure Synapse Analytics używają kontroli dostępu opartej na rolach (RBAC) platformy Azure w celu zapewnienia, że nieautoryzowany dostęp do nasłuchiwania, subskrybowania aktualizacji i wyzwalania potoków połączonych z zdarzeniami obiektów blob są ściśle zabronione.
- Aby pomyślnie utworzyć nowy wyzwalacz zdarzenia przechowywania lub zaktualizować istniejący, konto Azure zalogowane do usługi musi mieć odpowiedni dostęp do odpowiedniego konta przechowywania. W przeciwnym razie operacja kończy się niepowodzeniem z komunikatem "Odmowa dostępu".
- Usługa Data Factory i usługa Azure Synapse Analytics nie muszą mieć specjalnych uprawnień do instancji usługi Event Grid i nie trzeba przypisywać specjalnych uprawnień RBAC do konta usługi Data Factory lub Azure Synapse Analytics do wykonywania operacji.
Dowolne z następujących ustawień RBAC działa dla wyzwalaczy zdarzeń w magazynie:
- Rola właściciela konta magazynu
- Rola współautora na koncie magazynowym
-
Microsoft.EventGrid/EventSubscriptions/Writeuprawnienia do konta magazynu/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
Szczególnie:
- Podczas tworzenia w fabryce danych (na przykład w środowisku deweloperskim) zalogowane konto na platformie Azure musi mieć wspomniane uprawnienia.
- Podczas publikowania za pośrednictwem ciągłej integracji i ciągłego dostarczania, konto używane do publikowania szablonu usługi Azure Resource Manager w środowisku testowym lub produkcyjnym musi mieć wymienione powyżej uprawnienie.
Aby zrozumieć, w jaki sposób usługa dostarcza te dwie obietnice, zróbmy krok wstecz i przyjrzyjmy się za kulisami. Poniżej przedstawiono wysokopoziomowe przepływy pracy integracji między usługą Data Factory, usługą Azure Synapse Analytics, magazynem i usługą Event Grid.
Utwórz nowy wyzwalacz zdarzeń dla przechowywania danych
Ten ogólny schemat przepływu pracy opisuje sposób, w jaki usługa Data Factory współdziała z usługą Event Grid, aby utworzyć wyzwalacz zdarzenia przechowywania. Przepływ danych jest taki sam w usłudze Azure Synapse Analytics, a potoki usługi Azure Synapse Analytics pełnią rolę fabryki danych na poniższym diagramie.
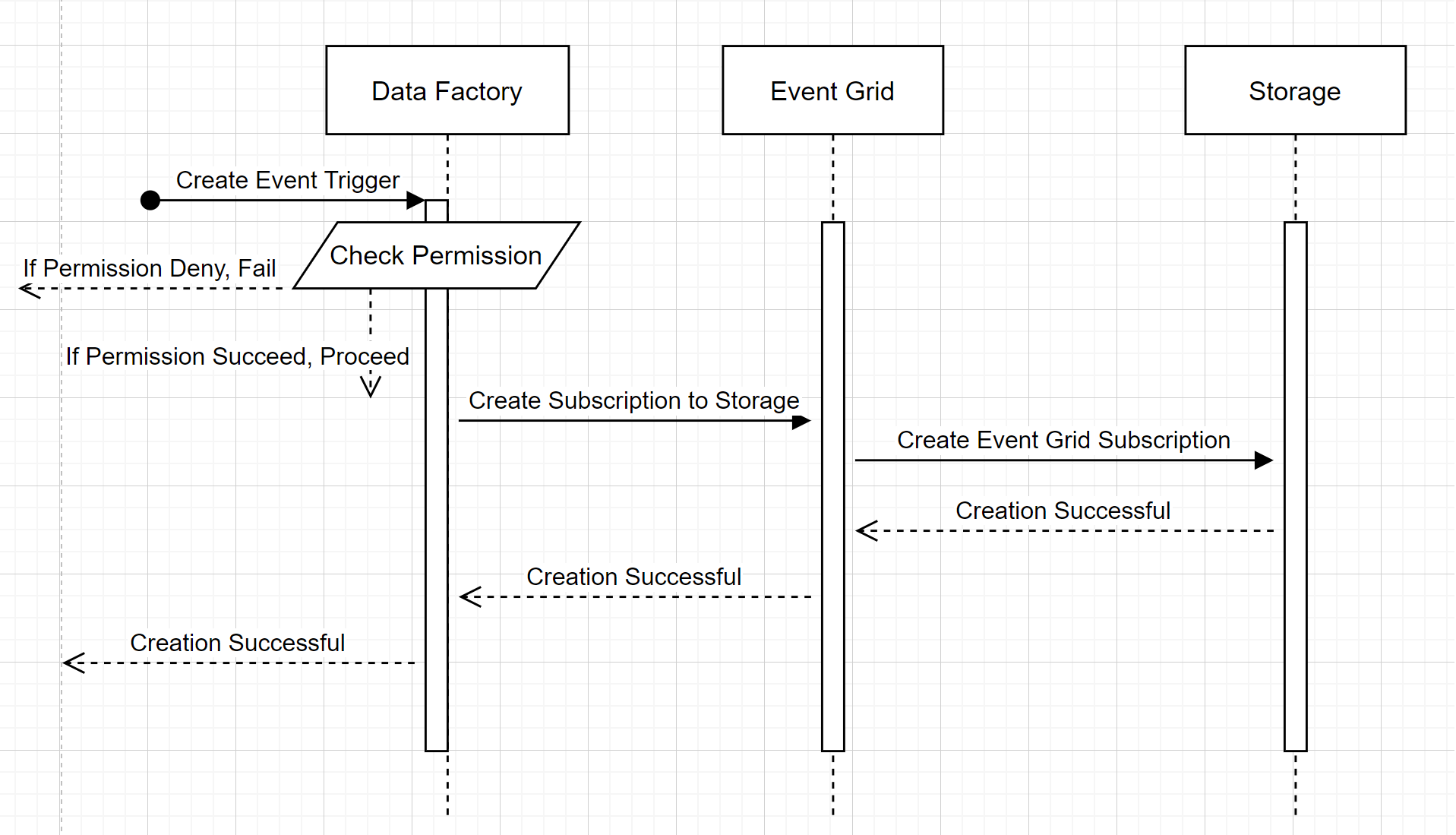
Dwa zauważalne spostrzeżenia w przepływach pracy:
- Usługi Data Factory i Azure Synapse Analytics nie nawiązują bezpośredniego kontaktu z kontem magazynu. Żądanie utworzenia subskrypcji jest zamiast tego przekazywane i przetwarzane przez usługę Event Grid. Usługa nie musi mieć uprawnień dostępu do konta pamięci masowej w tym kroku.
- Kontrola dostępu i sprawdzanie uprawnień są wykonywane w ramach usługi. Zanim usługa wyśle żądanie zasubskrybowania zdarzenia związanego z przechowywaniem, sprawdza uprawnienia użytkownika. W szczególności sprawdza, czy zalogowane konto platformy Azure, które próbuje utworzyć wyzwalacz zdarzenia magazynowego, ma odpowiedni dostęp do właściwego konta magazynu. Jeśli sprawdzanie uprawnień zakończy się niepowodzeniem, tworzenie wyzwalacza również zakończy się niepowodzeniem.
Uruchamianie potoku wyzwalania zdarzeń przechowywania
W tym ogólnym przepływie pracy opisano sposób uruchamiania potoków wyzwalacza zdarzeń magazynu za pośrednictwem usługi Event Grid. W przypadku usługi Azure Synapse Analytics przepływ danych jest taki sam, a potoki usługi Azure Synapse Analytics pełnią rolę usługi Data Factory na poniższym diagramie.
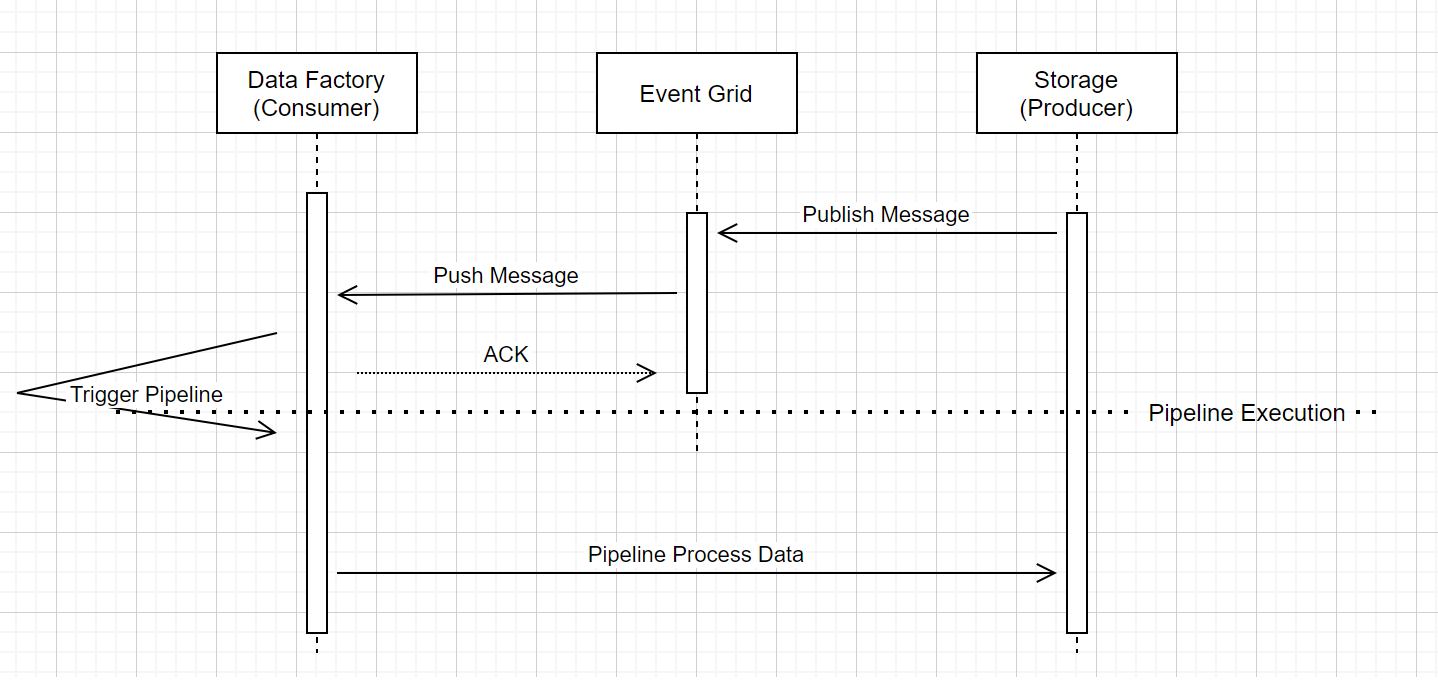
Trzy zauważalne objaśnienia w przepływie pracy są związane z potokami wyzwalania zdarzeń w usłudze:
Usługa Event Grid używa modelu wypychania, który przekazuje komunikat tak szybko, jak to możliwe, gdy magazyn umieszcza komunikat w systemie. Takie podejście różni się od systemu przesyłania wiadomości, takiego jak Kafka, w którym jest używany system pull.
Wyzwalacz zdarzenia działa jako aktywny nasłuchiwacz komunikatu przychodzącego i prawidłowo uruchamia powiązaną ścieżkę przetwarzania.
Wyzwalacz zdarzenia dotyczący magazynu sam w sobie nie nawiązuje bezpośredniego kontaktu z kontem magazynu.
- Jeśli masz operację kopiowania lub inną operację w integracji przepływu pracy w celu przetwarzania danych na koncie przechowywania, usługa nawiązuje bezpośredni kontakt z kontem przechowywania, używając poświadczeń zapisanych w usłudze powiązanej. Upewnij się, że połączona usługa jest odpowiednio skonfigurowana.
- Jeśli nie odwołujesz się do konta przechowywania w potoku, nie musisz przyznawać usłudze dostępu do konta przechowywania.
Powiązana zawartość
- Aby uzyskać więcej informacji na temat wyzwalaczy, zobacz Uruchamianie potoku i wyzwalacze.
- Aby odwołać się do metadanych wyzwalacza w potoku, zobacz sekcję Odwołania do metadanych wyzwalacza w uruchomieniach potoku.