Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Zautomatyzowane uczenie maszynowe (AutoML) jest przyjęte przez projekty uczenia maszynowego w celu trenowania, dostrajania i uzyskiwania najlepszych modeli automatycznie przy użyciu metryk docelowych określonych do prognozowania klasyfikacji, regresji i szeregów czasowych.
Jednym z wyzwań dla rozwiązania AutoML jest to, że nieprzetworzone dane z magazynu danych lub transakcyjnej bazy danych byłyby ogromnym zestawem danych, prawdopodobnie 10 GB. Duży zestaw danych wymaga dłuższego czasu na trenowanie modeli, dlatego zalecamy zoptymalizowanie przetwarzania danych przed wytrenowanie modeli usługi Azure Machine Learning. W tym samouczku przedstawiono sposób użycia usługi Azure Data Factory do partycjonowania zestawu danych w pliki AutoML dla zestawu danych usługi Machine Learning.
Projekt automatycznego uczenia maszynowego obejmuje następujące trzy scenariusze przetwarzania danych:
Partycjonowanie dużych danych na pliki AutoML przed wytrenowanie modeli.
Ramka danych biblioteki Pandas jest często używana do przetwarzania danych przed wytrenowanie modeli. Ramka danych Biblioteki Pandas działa dobrze w przypadku rozmiarów danych mniejszych niż 1 GB, ale jeśli dane są większe niż 1 GB, ramka danych biblioteki Pandas spowalnia przetwarzanie danych. Czasami może nawet zostać wyświetlony komunikat o błędzie braku pamięci. Zalecamy używanie formatu pliku Parquet na potrzeby uczenia maszynowego, ponieważ jest to binarny format kolumnowy.
Przepływy danych mapowania usługi Data Factory są wizualnie zaprojektowane przekształcenia danych, które zwalniają inżynierów danych z pisania kodu. Przepływy danych mapowania to zaawansowany sposób przetwarzania dużych danych, ponieważ potok używa skalowanych w poziomie klastrów Spark.
Podziel zestaw danych trenowania i zestaw danych testowych.
Zestaw danych trenowania będzie używany na potrzeby modelu trenowania. Testowy zestaw danych będzie używany do oceny modeli w projekcie uczenia maszynowego. Działanie Podziału warunkowego dla przepływów danych mapowania podzieliłoby dane treningowe i dane testowe.
Usuń niekwalifikowane dane.
Możesz usunąć niekwalifikowane dane, takie jak plik Parquet z zerowymi wierszami. W tym samouczku użyjemy działania Agregacja, aby uzyskać liczbę wierszy. Liczba wierszy będzie warunkiem usunięcia niekwalifikowanych danych.
Przygotowywanie
Użyj poniższej tabeli usługi Azure SQL Database.
CREATE TABLE [dbo].[MyProducts](
[ID] [int] NULL,
[Col1] [char](124) NULL,
[Col2] [char](124) NULL,
[Col3] datetime NULL,
[Col4] int NULL
)
Konwertowanie formatu danych na Parquet
Następujący przepływ danych przekonwertuje tabelę usługi SQL Database na format pliku Parquet:
- Źródłowy zestaw danych: tabela transakcji usługi SQL Database.
- Zestaw danych ujścia: magazyn obiektów blob z formatem Parquet.
Usuwanie niekwalifikowanych danych na podstawie liczby wierszy
Załóżmy, że musimy usunąć liczbę wierszy, która jest mniejsza niż dwie.
Użyj działania Agregacja, aby uzyskać liczbę wierszy. Użyj grupowania według na podstawie kolumny Col2 i agregacji z wartościami
count(1)dla liczby wierszy.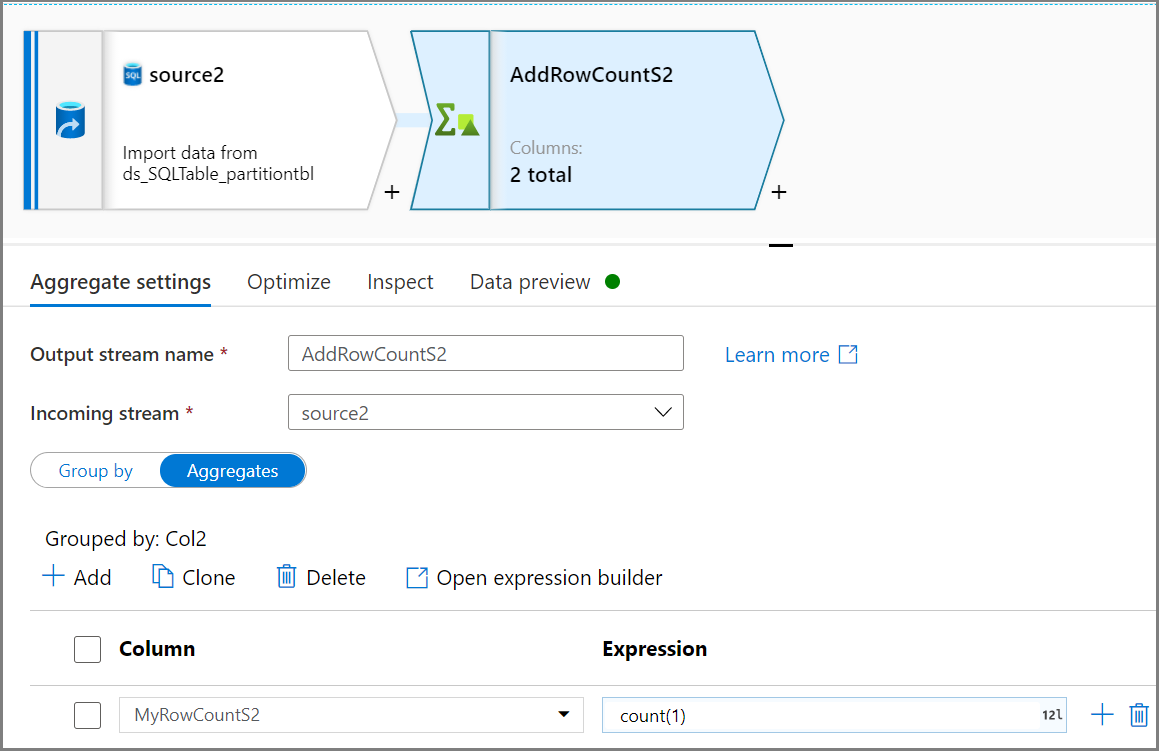
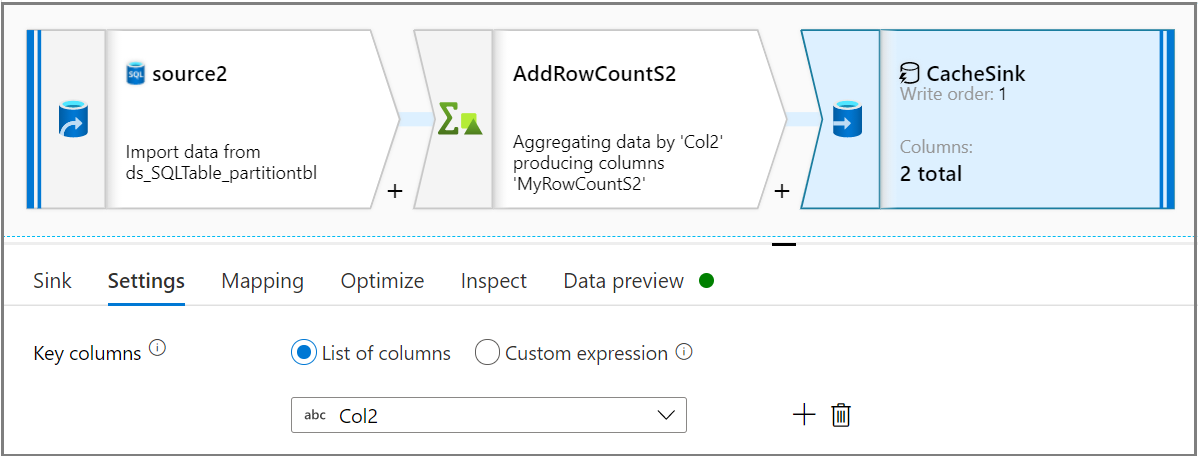
Korzystając z działania Ujście, wybierz typ ujścia jako Pamięć podręczna na karcie Ujście . Następnie wybierz odpowiednią kolumnę z listy rozwijanej Kolumny klucza na karcie Ustawienia .
Użyj działania Kolumna pochodna, aby dodać kolumnę liczby wierszy w strumieniu źródłowym. Na karcie Ustawienia kolumny pochodnej
CacheSink#lookupużyj wyrażenia , aby uzyskać liczbę wierszy z aplikacji CacheSink.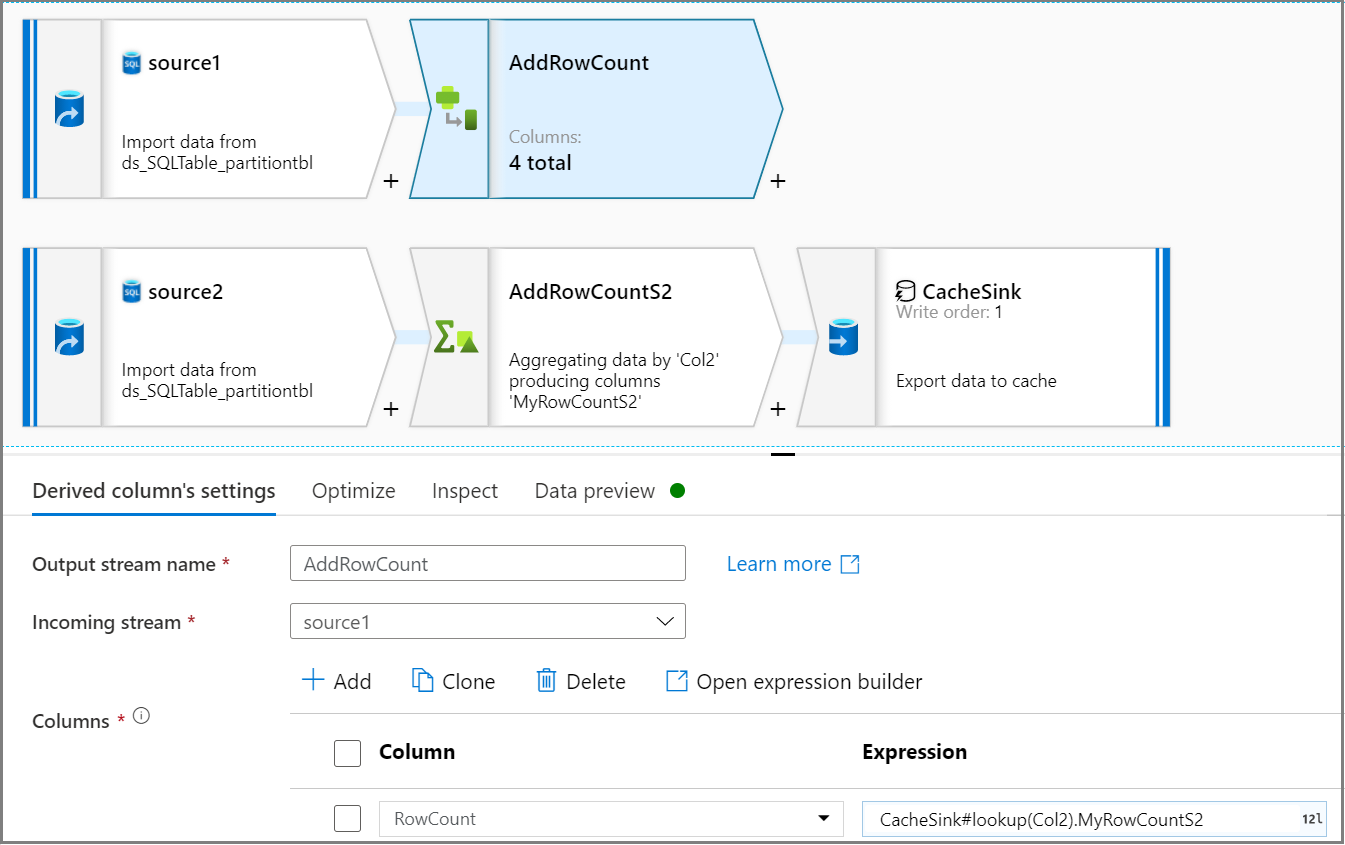
Użyj działania Dzielenie warunkowe, aby usunąć niekwalifikowane dane. W tym przykładzie liczba wierszy jest oparta na kolumnie Col2. Warunek polega na usunięciu liczby wierszy mniejszej niż dwa, więc dwa wiersze (ID=2 i ID=7) zostaną usunięte. Dane niekwalifikowane można zapisać w magazynie obiektów blob na potrzeby zarządzania danymi.
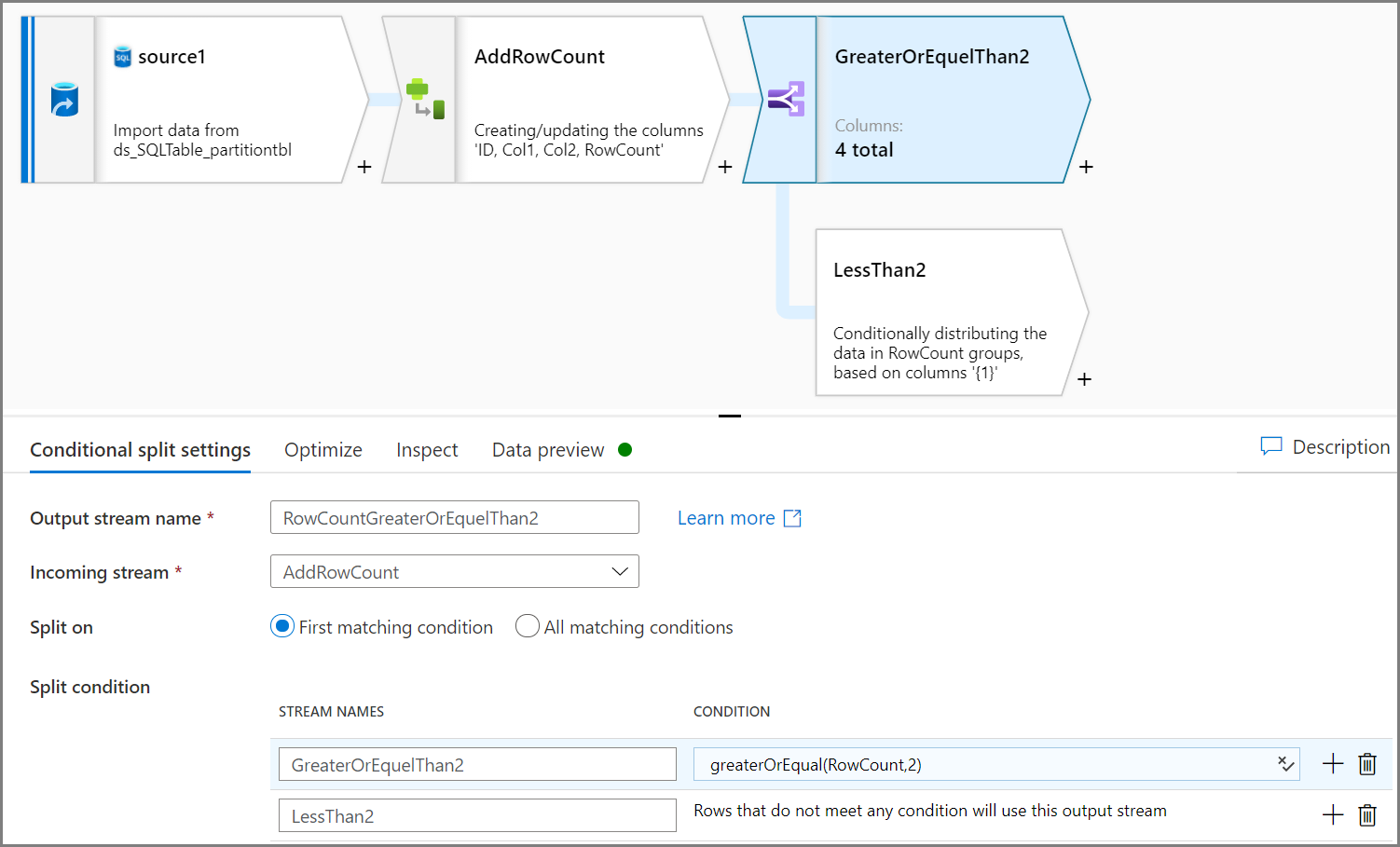
Uwaga
- Utwórz nowe źródło, aby uzyskać liczbę wierszy, które będą używane w oryginalnym źródle w kolejnych krokach.
- Używanie rozwiązania CacheSink z punktu widzenia wydajności.
Dzielenie danych treningowych i danych testowych
Chcemy podzielić dane treningowe i dane testowe dla każdej partycji. W tym przykładzie dla tej samej wartości kolumny Col2 pobierz dwa pierwsze wiersze jako dane testowe i pozostałe wiersze jako dane treningowe.
Użyj działania Okno, aby dodać jeden numer wiersza kolumny dla każdej partycji. Na karcie Over (Over) wybierz kolumnę dla partycji. W tym samouczku utworzymy partycje dla kolumny Col2. Nadaj zamówienie na karcie Sortowanie , które w tym samouczku będzie oparte na identyfikatorze. Nadaj kolejność na karcie Kolumny okna, aby dodać jedną kolumnę jako liczbę wierszy dla każdej partycji.
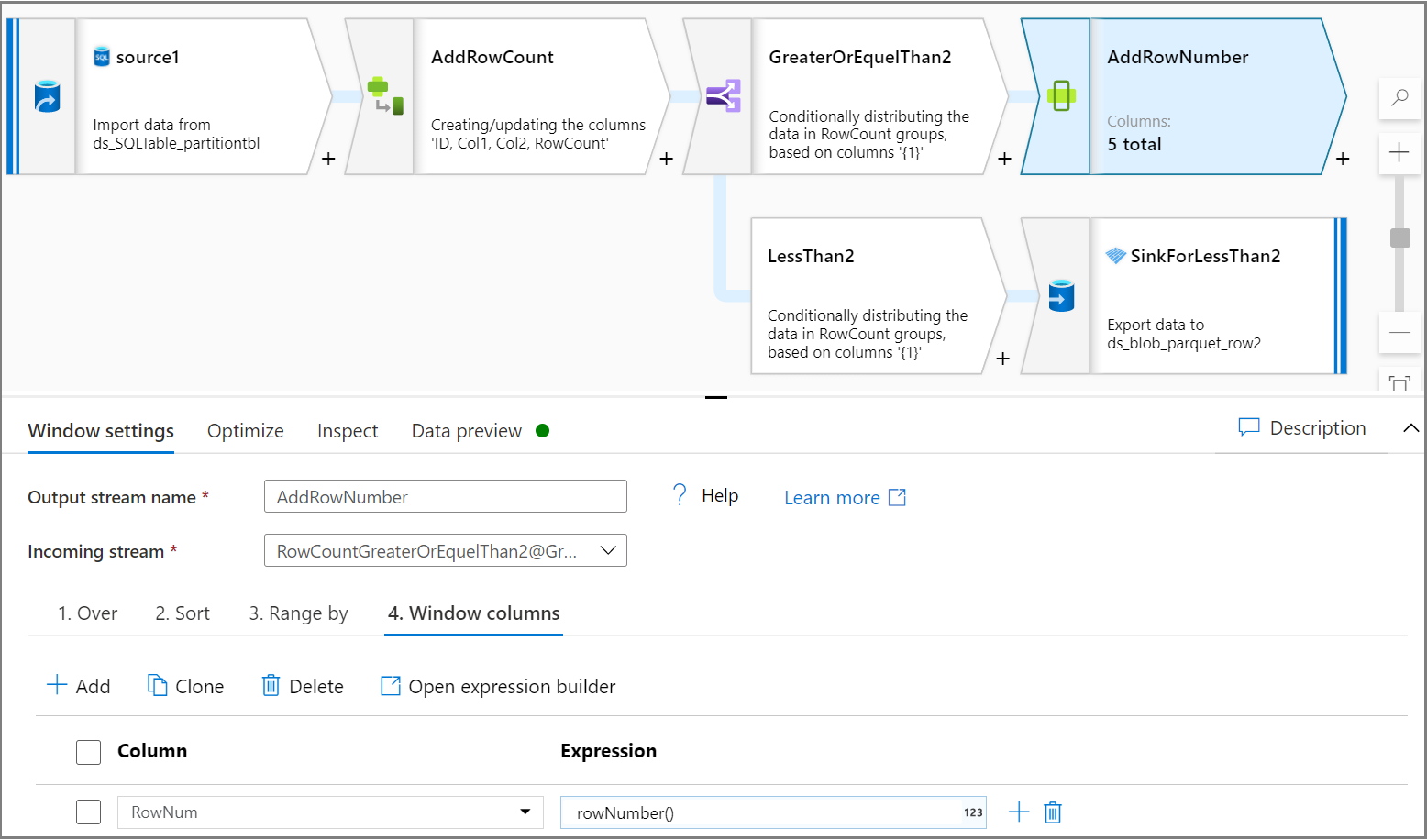
Użyj działania Podział warunkowy, aby podzielić dwa pierwsze wiersze każdej partycji na zestaw danych testowych i pozostałe wiersze na zestaw danych trenowania. Na karcie Ustawienia podziału warunkowego użyj wyrażenia
lesserOrEqual(RowNum,2)jako warunku.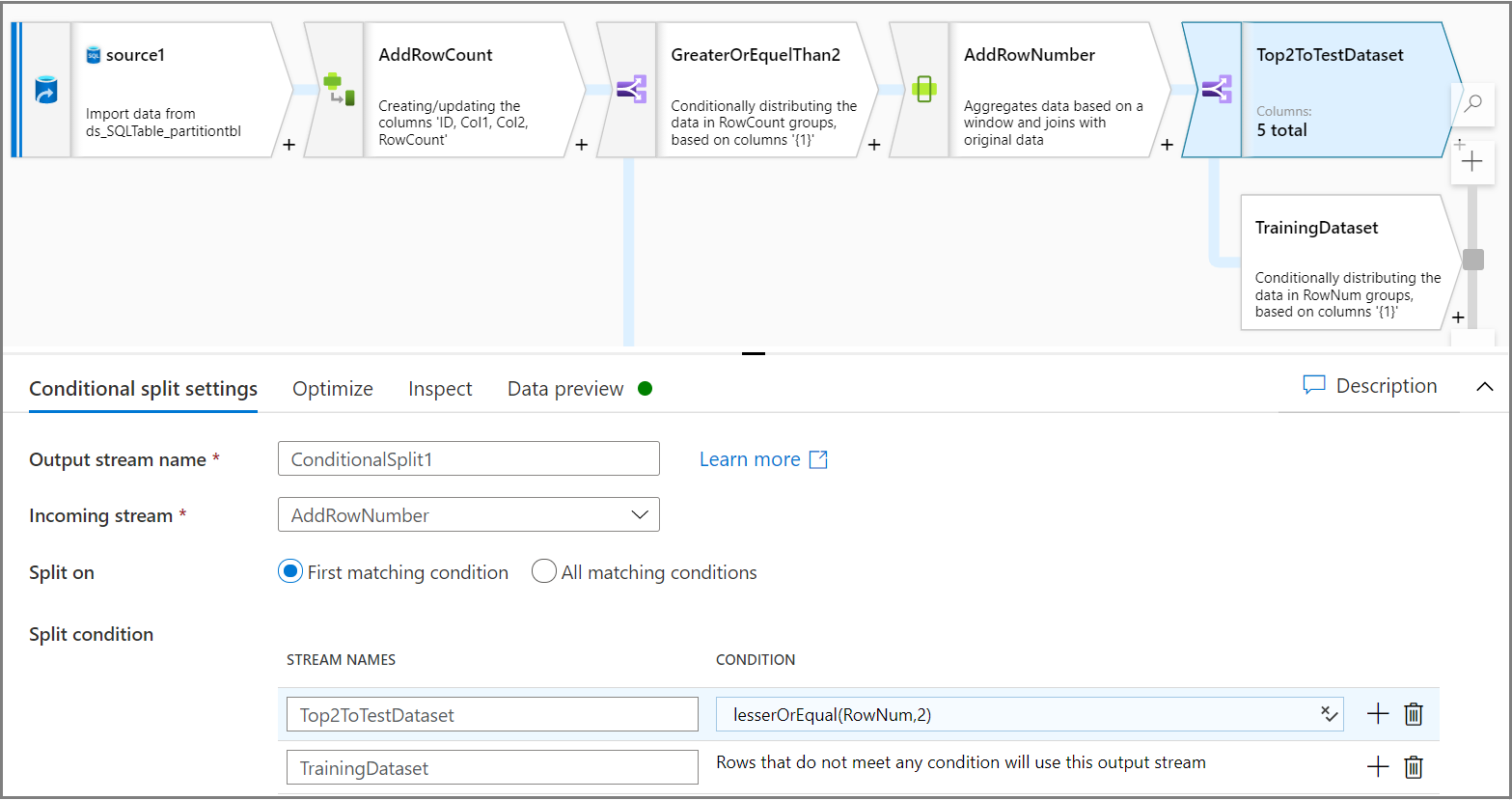
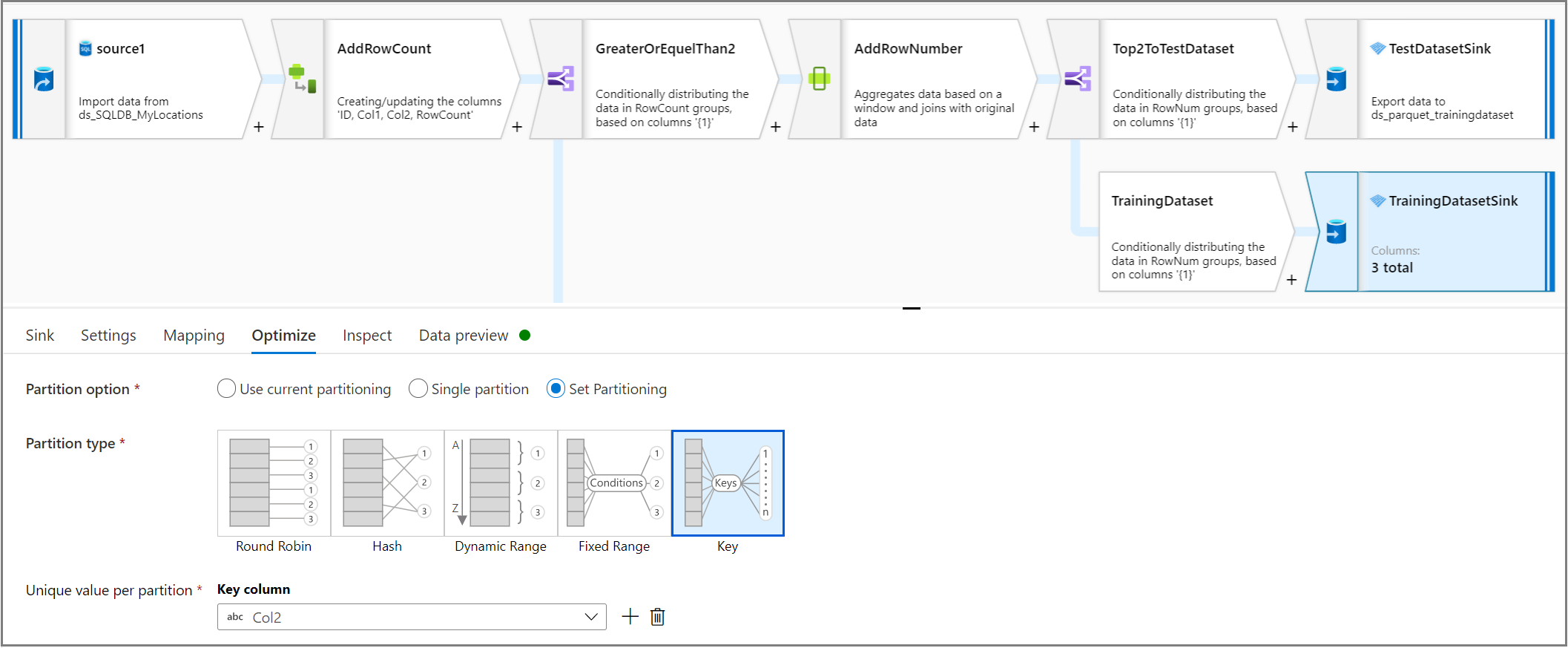
Partycjonowanie zestawów danych szkoleniowych i testowych przy użyciu formatu Parquet
Za pomocą działania ujścia na karcie Optymalizacja użyj wartości unikatowej na partycję , aby ustawić kolumnę jako klucz kolumny dla partycji.
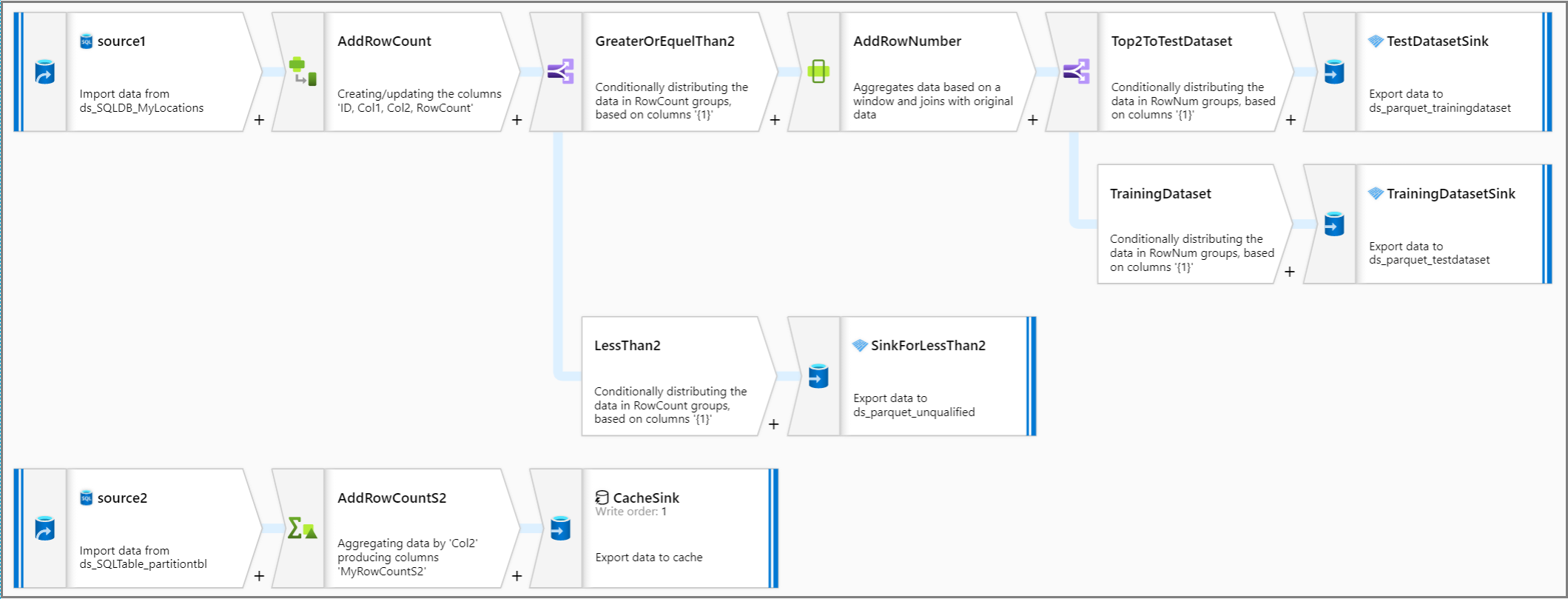
Przyjrzyjmy się całej logice potoku.
Powiązana zawartość
Utwórz pozostałą część logiki przepływu danych przy użyciu przekształceń przepływu mapowania danych.