Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Wskazówka
- Aby porównać transformacje przepływu danych mapowania do ich odpowiedników w Dataflow Gen2, zobacz Przewodnik po Dataflow Gen2 dla użytkowników przepływu danych mapowania.
- Aby zapoznać się z przekształceniami danych w Microsoft Fabric, zobacz Dataflow Gen2 overview .
Czym są przepływy danych mapowania?
Przepływy danych mapowania w Azure Data Factory to wizualnie projektowane transformacje danych. Przepływy danych umożliwiają inżynierom danych opracowywanie logiki przekształcania danych bez pisania kodu. Wynikowe przepływy danych są wykonywane jako działania w ramach potoków Azure Data Factory, które używają skalowanych w poziomie klastrów platformy Apache Spark. Działania przepływu danych można zoperacjonalizować przy użyciu istniejących Azure Data Factory możliwości planowania, sterowania, przepływu i monitorowania.
Mapowanie przepływów danych zapewnia środowisko wizualne bez konieczności kodowania. Przepływy danych działają na klastrach wykonywania zarządzanych przez usługę ADF, co umożliwia skalowane przetwarzanie danych. Azure Data Factory obsługuje całe tłumaczenie kodu, optymalizację ścieżki i wykonywanie zadań przepływu danych.
Wprowadzenie
Przepływy danych są tworzone w okienku zasobów fabrycznych, takich jak potoki i zestawy danych. Aby utworzyć data flow, wybierz znak plus obok pozycji Factory Resources a następnie wybierz Przepływ danych.
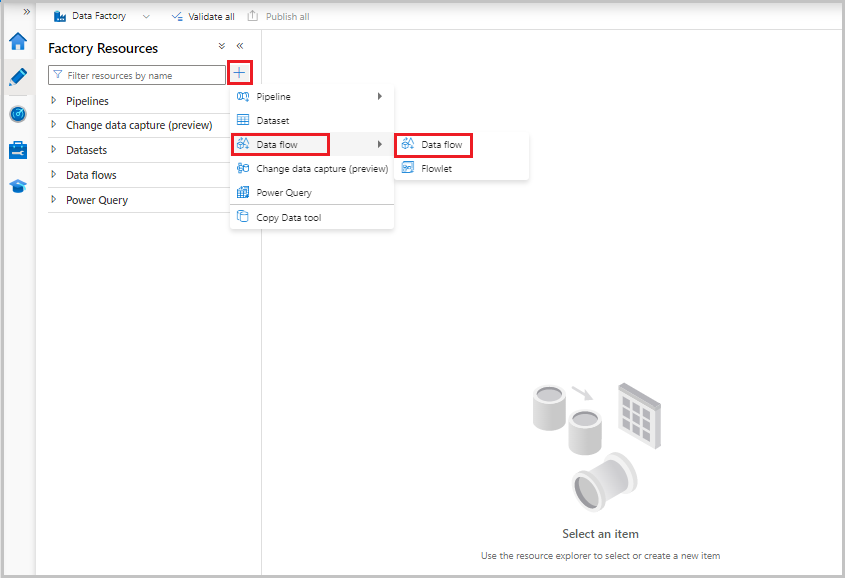 Ta akcja powoduje przejście do kanwy przepływu danych, w której można utworzyć logikę przekształcania. Wybierz pozycję Dodaj źródło , aby rozpocząć konfigurowanie transformacji źródłowej. Aby uzyskać więcej informacji, zobacz Przekształcanie źródła.
Ta akcja powoduje przejście do kanwy przepływu danych, w której można utworzyć logikę przekształcania. Wybierz pozycję Dodaj źródło , aby rozpocząć konfigurowanie transformacji źródłowej. Aby uzyskać więcej informacji, zobacz Przekształcanie źródła.
Tworzenie przepływów danych
Przepływ danych mapowania ma unikatową kanwę tworzenia, która ułatwia tworzenie logiki przekształcania. Kanwa przepływu danych jest podzielona na trzy części: górny pasek, graf i panel konfiguracji.
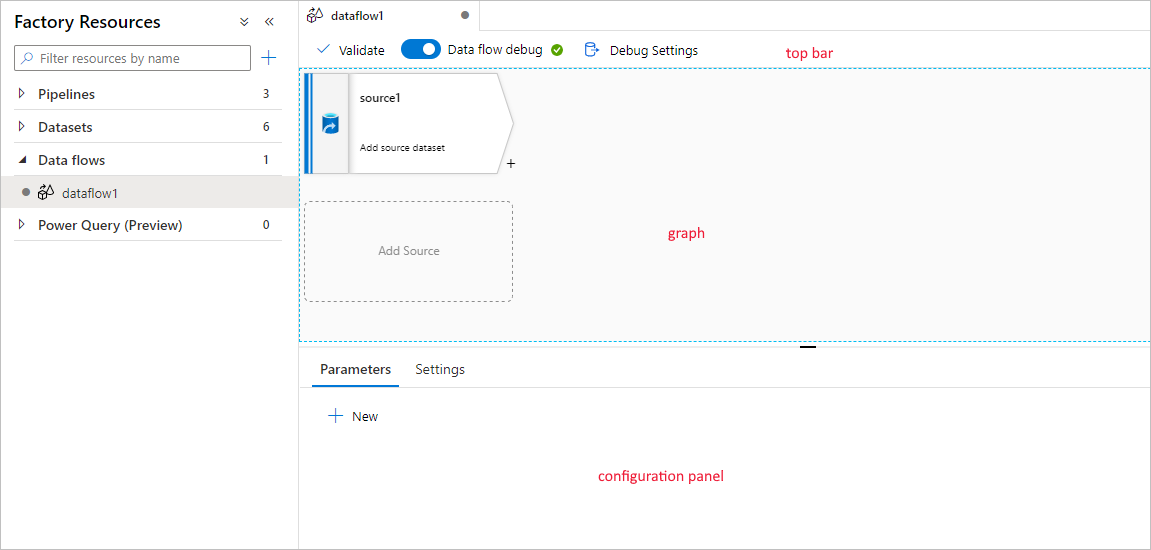
Graph
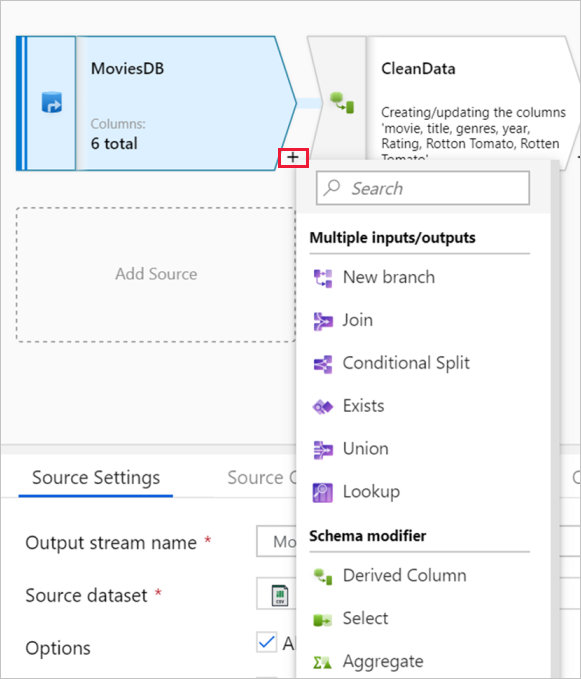
Wykres wyświetla strumień transformacji. Przedstawia ścieżkę pochodzenia danych źródłowych, w miarę jak przepływają do jednego lub więcej miejsc docelowych. Ujścia mogą być dowolnymi miejscami docelowymi źródeł danych, w których chcesz przenieść wyniki przekształconych danych. Aby dodać nowe źródło, wybierz pozycję Dodaj źródło. Aby dodać nową transformację, wybierz znak plus w prawym dolnym rogu istniejącej transformacji. Dowiedz się więcej na temat zarządzania wykresem przepływu danych.
Panel konfiguracji
Na panelu konfiguracji są wyświetlane ustawienia specyficzne dla aktualnie wybranej transformacji. Jeśli nie wybrano przekształcenia, zostanie wyświetlony przepływ danych. W ogólnej konfiguracji przepływu danych można dodać parametry za pomocą karty Parametry . Aby uzyskać więcej informacji, zobacz Mapowanie parametrów przepływu danych.
Każde przekształcenie zawiera co najmniej cztery karty konfiguracji.
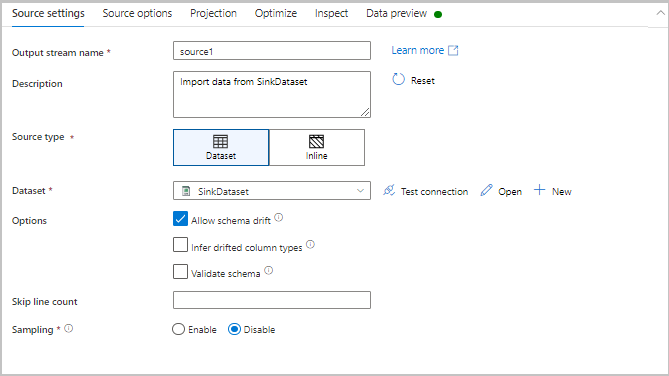
Ustawienia przekształcania
Pierwsza karta w okienku konfiguracji każdego przekształcenia zawiera ustawienia specyficzne dla tej transformacji. Aby uzyskać więcej informacji, zobacz stronę dokumentacji przekształcenia.
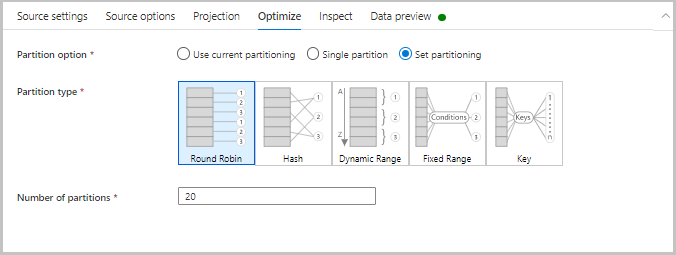
Optymalizacja
Karta Optymalizacja zawiera ustawienia służące do konfigurowania schematów partycjonowania. Aby dowiedzieć się więcej na temat optymalizowania przepływów danych, zobacz przewodnik dotyczący wydajności przepływu mapowania danych.
Inspekcja
Zakładka Inspekcja zapewnia widok metadanych strumienia danych, które są przekształcane. Liczby kolumn, zmienione kolumny, dodane kolumny, typy danych, kolejność kolumn i odwołania do kolumn. Podgląd to widok metadanych w trybie tylko do odczytu. Nie musisz mieć włączonego trybu debugowania, aby wyświetlić metadane w okienku Inspekcja .
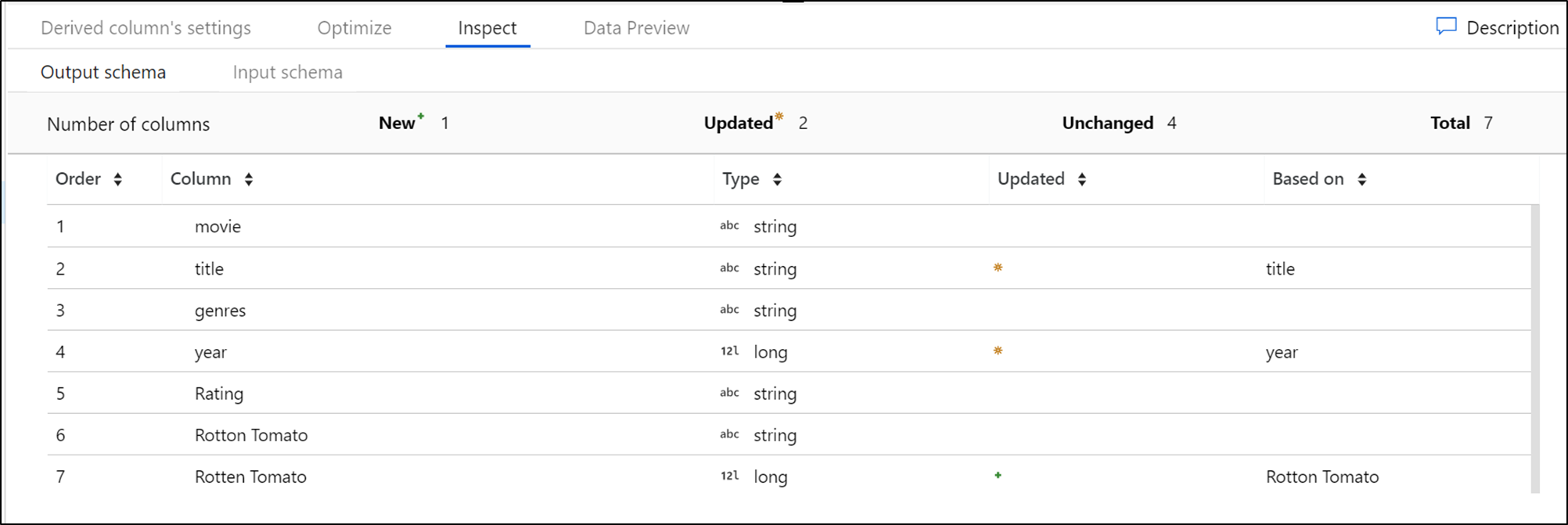
Po zmianie kształtu danych za pomocą przekształceń możesz zobaczyć przepływ zmian metadanych w okienku Inspekcja . Jeśli w transformacji źródłowej nie ma zdefiniowanego schematu, metadane nie są widoczne w okienku Inspekcja . Brak metadanych jest typowy w scenariuszach dryfu schematu.
Podgląd danych
Jeśli tryb debugowania jest włączony, karta Podgląd danych zawiera interaktywną migawkę danych w każdej transformacji. Aby uzyskać więcej informacji, zobacz Podgląd danych w trybie debugowania.
Górny pasek
Górny pasek zawiera akcje wpływające na cały przepływ danych, takie jak zapisywanie i walidacja. Możesz również wyświetlić źródłowy skrypt przepływu danych i kodu JSON logiki transformacji. Aby uzyskać więcej informacji, dowiedz się więcej na temat skryptu przepływu danych.
Dostępne przekształcenia
Przejrzyj omówienie przekształcania przepływu danych z mapowaniem, aby zobaczyć listę dostępnych przekształceń.
Typy danych w przepływie
- macierz
- binarny
- boolean
- złożony
- system dziesiętny (z uwzględnieniem precyzji)
- data
- float
- liczba całkowita
- długi
- mapa
- krótki
- ciąg
- sygnatura czasowa
Działanie przepływu danych
Przepływy danych mapowania są operacjonalizowane w potokach usługi ADF przy użyciu działania przepływu danych. Wszystko, co użytkownik musi zrobić, to określić, które środowisko uruchomieniowe integracji będzie używane, i przekazać wartości parametrów. Aby uzyskać więcej informacji, zapoznaj się z Azure Integration Runtime.
Tryb debugowania
Tryb debugowania umożliwia interaktywne wyświetlanie wyników każdego kroku transformacji podczas kompilowania i debugowania przepływów danych. Sesja debugowania może być używana zarówno podczas tworzenia logiki przepływu danych, jak i podczas uruchamiania debugowania potoków z działaniami przepływu danych. Aby dowiedzieć się więcej, zobacz dokumentację trybu debugowania.
Monitorowanie przepływów danych
Mapowanie przepływu danych integruje się z istniejącymi możliwościami monitorowania Azure Data Factory. Aby dowiedzieć się, jak zrozumieć dane wyjściowe monitorowania przepływu danych, zobacz Monitorowanie przepływów danych mapowania.
Zespół Azure Data Factory utworzył przewodnik dostrajania wydajności, który pomoże zoptymalizować czas wykonywania przepływów danych po utworzeniu logiki biznesowej.