Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
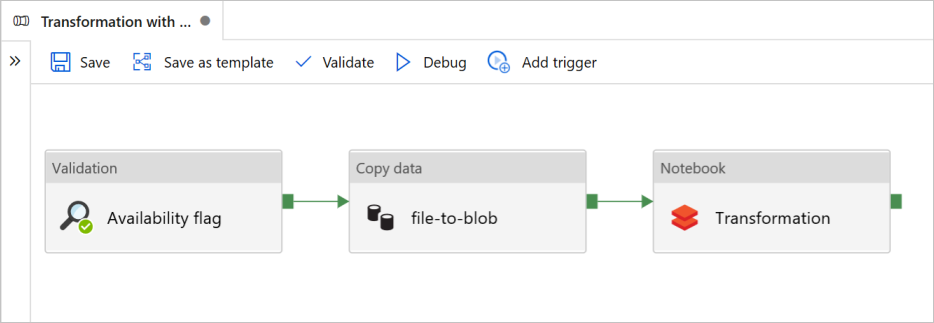
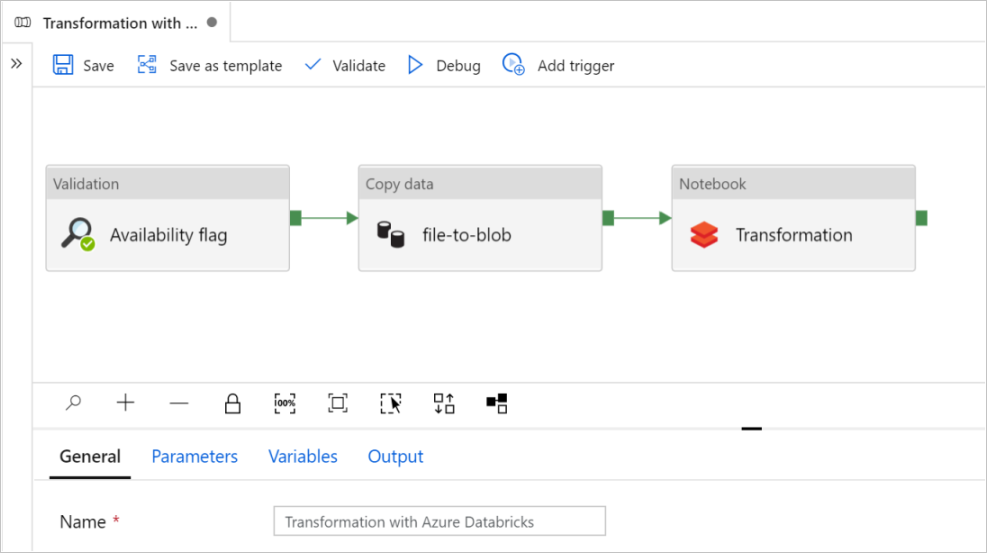
W tym samouczku utworzysz kompletny potok zawierający działania Walidacja, Kopiuj dane, oraz Notebook w Azure Data Factory.
Weryfikacja gwarantuje, że źródłowy zestaw danych jest gotowy do dalszego przetwarzania przed uruchomieniem zadania kopiowania i analizy.
Kopiowanie danych duplikuje źródłowy zestaw danych do magazynu docelowego, który jest instalowany jako DBFS w notesie Azure Databricks. W ten sposób zestaw danych może być używany bezpośrednio przez platformę Spark.
Notatnik uruchamia notatnik Databricks, który przekształca zbiór danych. Dodaje również zestaw danych do folderu z przetworzonymi danymi lub do usługi Azure Synapse Analytics.
Dla uproszczenia, w tym samouczku szablon nie zakłada zaplanowanego wyzwalacza. W razie potrzeby możesz go dodać.
Wymagania wstępne
Konto usługi Blob Storage Azure z kontenerem o nazwie
sinkdatado użycia jako ujście.Zanotuj nazwę konta magazynu, nazwę kontenera i klucz dostępu. Te wartości będą potrzebne w dalszej części szablonu.
Obszar roboczy Azure Databricks.
Importowanie notesu na potrzeby transformacji
Aby zaimportować notatnik Transformation do obszaru roboczego usługi Databricks:
Zaloguj się do obszaru roboczego Azure Databricks.
Kliknij prawym przyciskiem myszy folder w obszarze roboczym i wybierz polecenie Importuj.
Wybierz Importuj z: adres URL. W polu tekstowym wprowadź
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.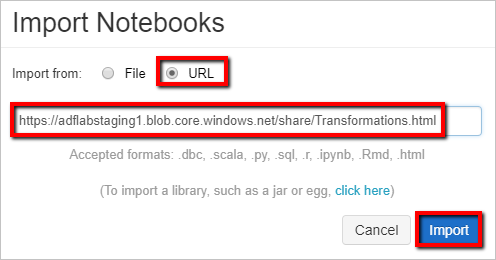
Teraz zaktualizujmy notatnik Transformation przy użyciu informacji o połączeniu magazynu.
W zaimportowanym notatniku przejdź do polecenia 5 jak pokazano w poniższym fragmencie kodu.
- Zastąp
<storage name>i<access key>własnymi informacjami o połączeniu magazynu. - Użyj konta magazynowego z kontenerem
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Zastąp
Wygeneruj token dostępu do Databricks, aby usługa Data Factory mogła uzyskać dostęp do platformy Databricks.
- W obszarze roboczym Azure Databricks wybierz nazwę użytkownika Azure Databricks na górnym pasku, a następnie wybierz pozycję Ustawienia z listy rozwijanej.
- Wybierz Deweloper.
- Obok pozycji Tokeny dostępu wybierz pozycję Zarządzaj.
- Wybierz pozycję Generuj nowy token.
- (Opcjonalnie) Wprowadź komentarz, który pomaga zidentyfikować ten token w przyszłości i zmienić domyślny okres istnienia tokenu na 90 dni. Aby utworzyć token bez okresu istnienia (niezalecane), pozostaw puste pole Okres istnienia (dni) (puste).
- Wybierz Generuj.
- Skopiuj wyświetlony token do bezpiecznej lokalizacji, a następnie wybierz pozycję Gotowe.
Zapisz token dostępu do późniejszego użycia podczas tworzenia połączonej usługi Databricks. Token dostępu wygląda mniej więcej tak: dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Jak używać tego szablonu
Przejdź do szablonu Transformation with Azure Databricks i utwórz nowe powiązane usługi dla następujących połączeń.
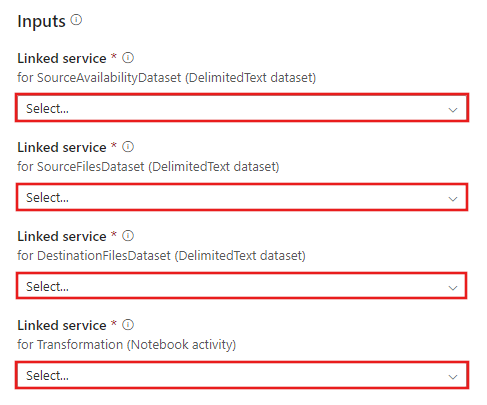
Połączenie do źródłowego bloba — aby uzyskać dostęp do danych źródłowych.
W tym ćwiczeniu można użyć publicznego magazynu obiektów blob, który zawiera pliki źródłowe. Aby uzyskać informacje o konfiguracji, zobacz poniższy zrzut ekranu. Użyj następującego adresu URL SAS (sygnatury dostępu współdzielonego), aby nawiązać połączenie z magazynem źródłowym (dostęp tylko do odczytu):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D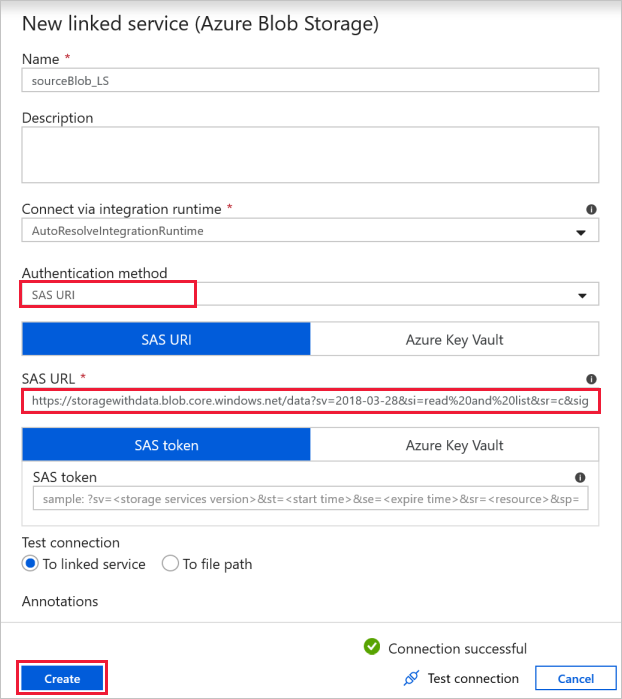
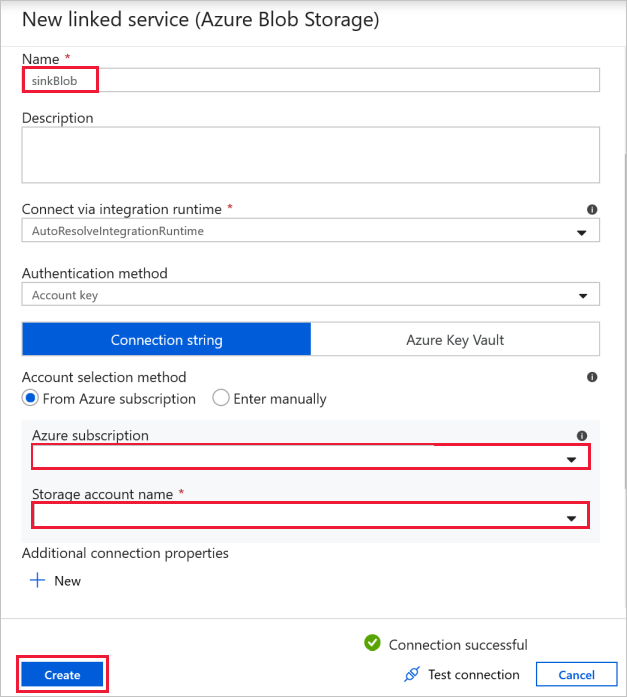
Docelowe połączenie obiektu Blob — do przechowywania skopiowanych danych.
W oknie Nowa połączona usługa wybierz docelowy obiekt blob magazynowy.
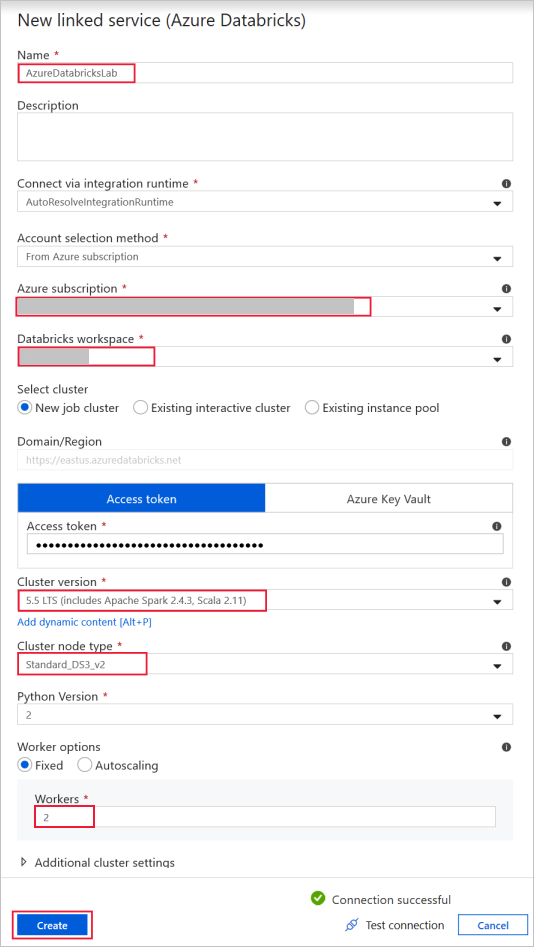
Azure Databricks — aby nawiązać połączenie z klastrem usługi Databricks.
Utwórz połączoną usługę Databricks przy użyciu wygenerowanego wcześniej klucza dostępu. Jeśli go masz, możesz wybrać klaster interaktywny. W tym przykładzie użyto opcji Nowy klaster zadań.
Wybierz Użyj tego szablonu. Zobaczysz utworzony potok.
Wprowadzenie i konfiguracja potoku
Większość ustawień w nowym ciągu technologicznym jest automatycznie konfigurowana przy użyciu wartości domyślnych. Przejrzyj konfigurację swojego potoku i wprowadź wszelkie niezbędne zmiany.
W aktywności
Walidacja flaga Dostępności sprawdź, czy wartość zestawu danych źródłowegojest ustawiona na , który utworzyłeś wcześniej. 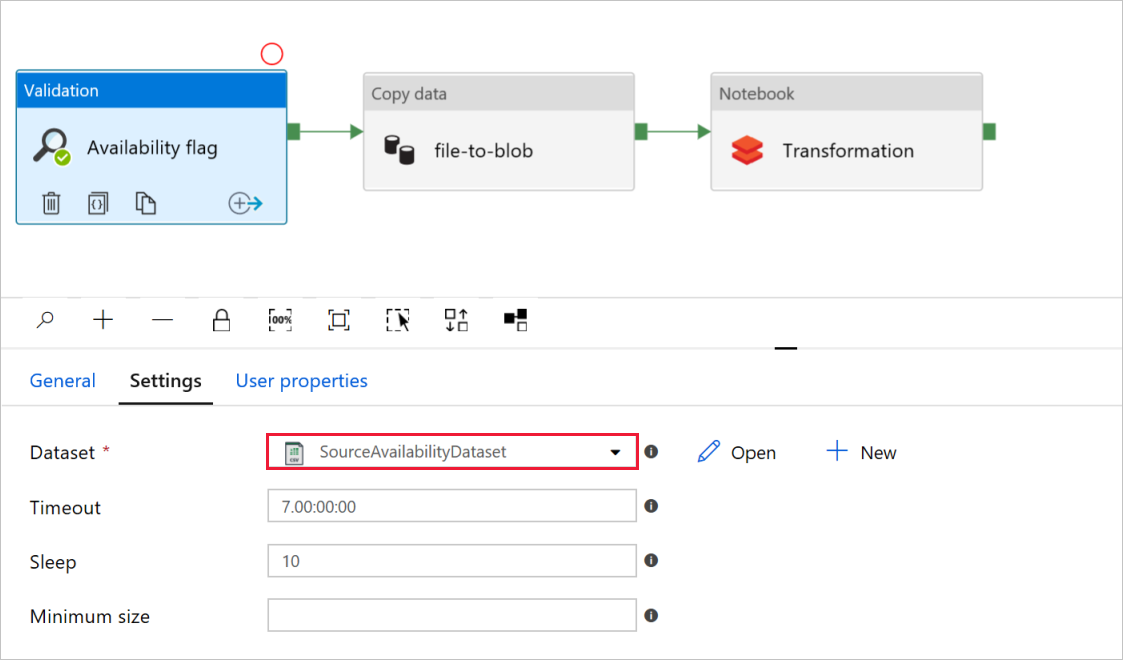
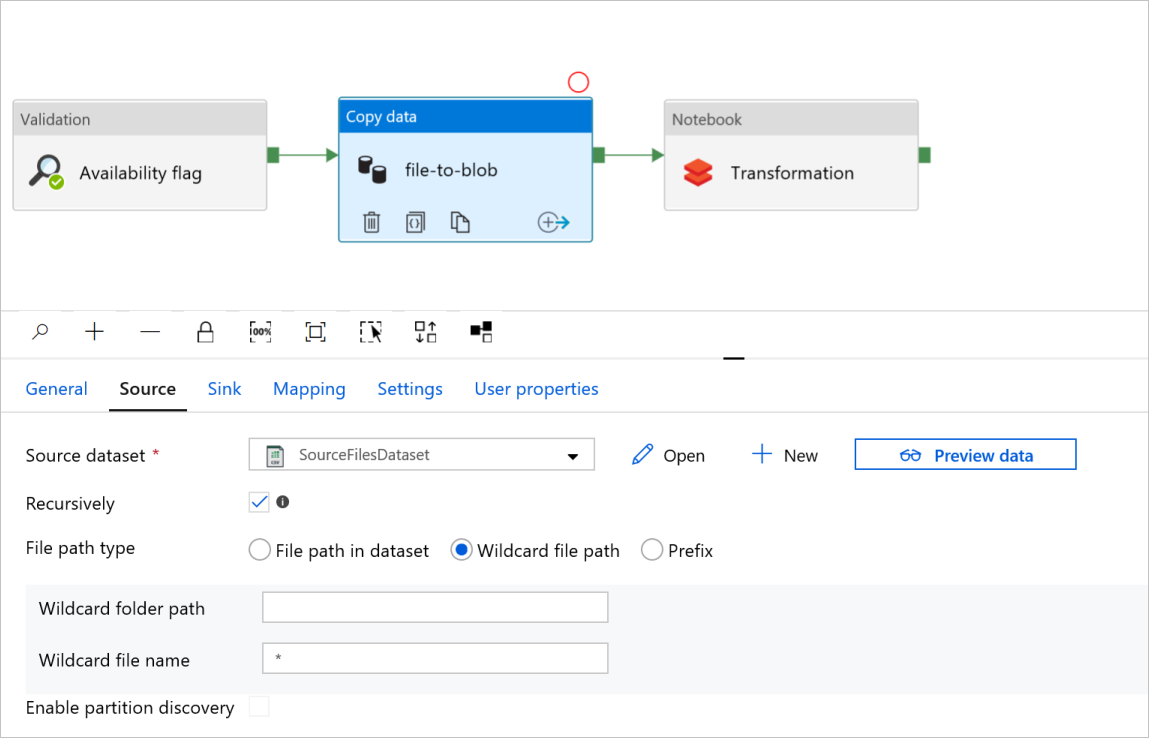
W aktywności Copy datafile-to-blob, sprawdź karty Źródło i Ujście. W razie potrzeby zmień ustawienia.
Karta Źródło
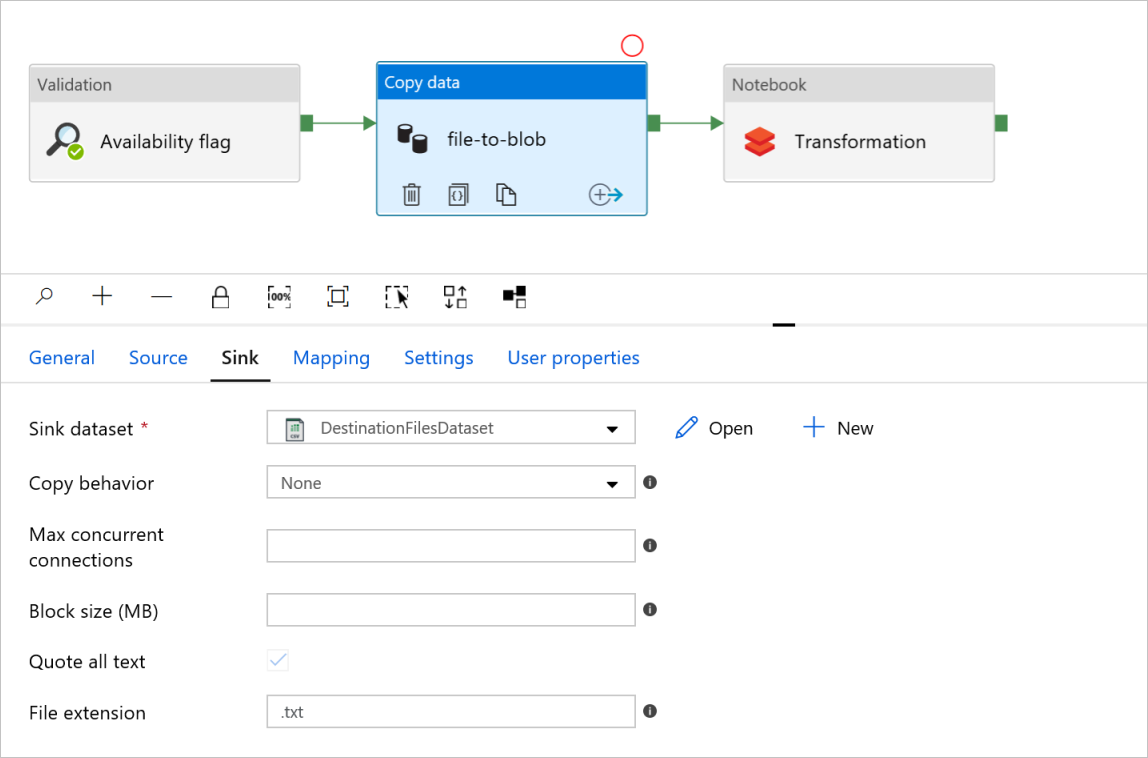
Karta Ujście
W aktywności NotesPrzekształcanie przejrzyj i zaktualizuj ścieżki i ustawienia zgodnie z potrzebami.
Połączona usługa Databricks powinna zostać wstępnie wypełniona wartością z poprzedniego kroku, jak pokazano poniżej:
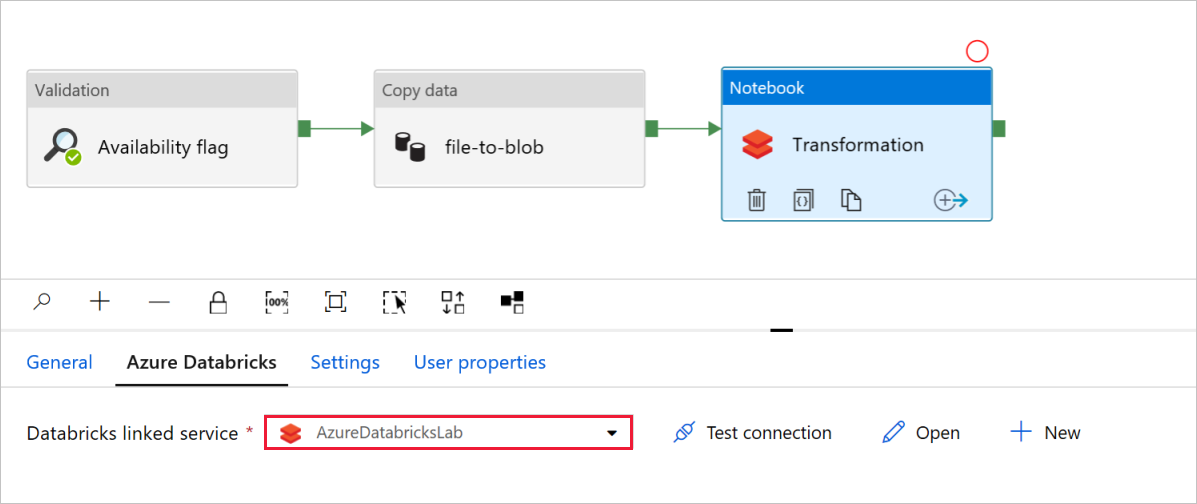
Aby sprawdzić ustawienia notebooka:
Wybierz kartę Ustawienia . W polu Ścieżka notesu sprawdź, czy ścieżka domyślna jest poprawna. Może być konieczne przeglądanie i wybieranie właściwej ścieżki notatnika.
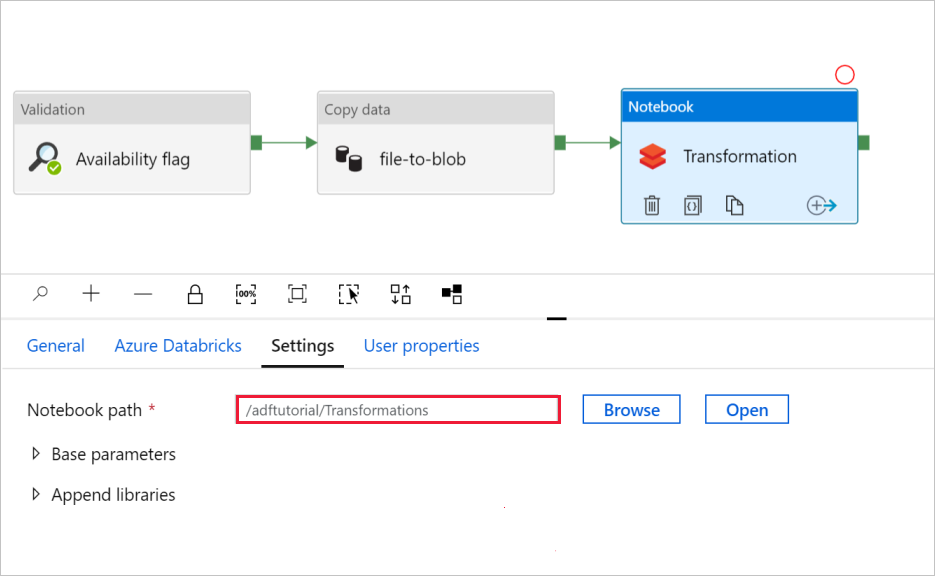
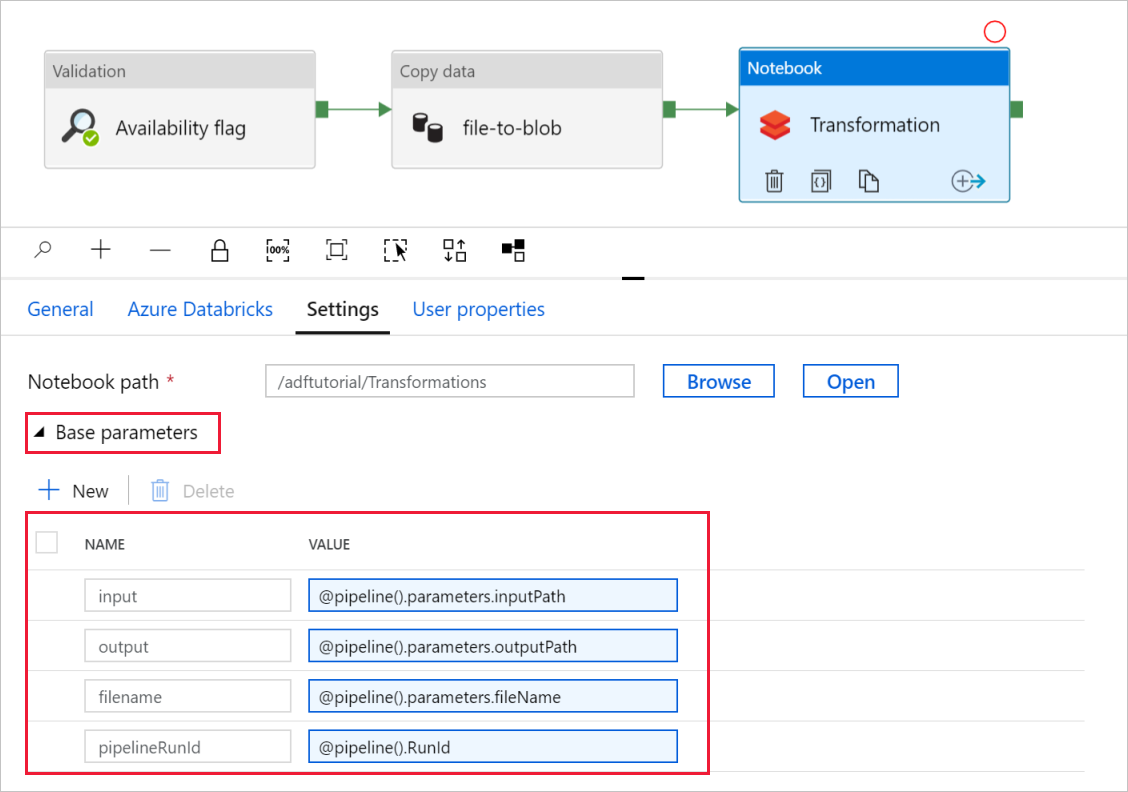
Rozwiń selektor Podstawowe parametry i sprawdź, czy parametry są zgodne z tym, co pokazano na poniższym zrzucie ekranu. Te parametry są przekazywane do notatnika Databricks przez Data Factory.
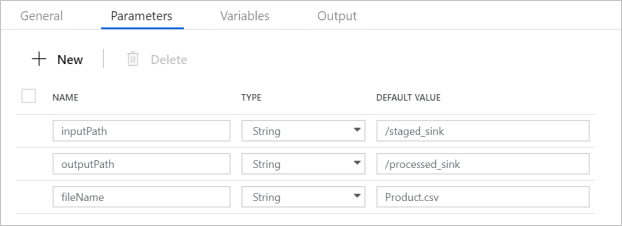
Sprawdź, czy parametry potoku są zgodne z tym, co pokazano na poniższym zrzucie ekranu:
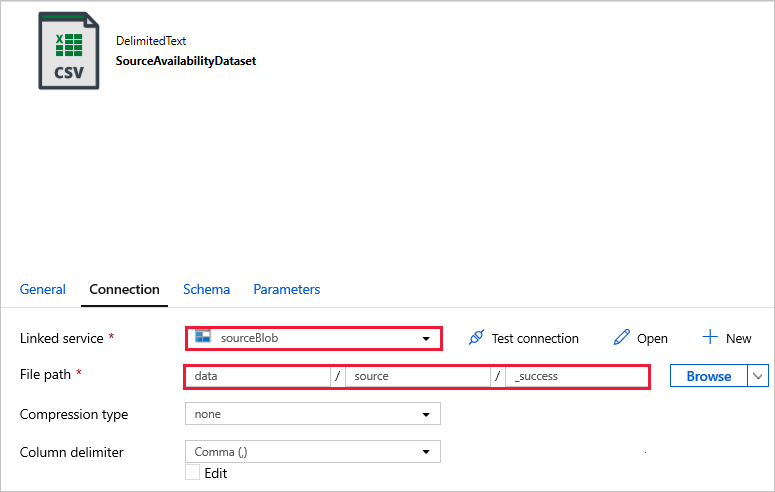
Połącz się z zestawami danych.
Uwaga
W poniższych zestawach danych ścieżka pliku została automatycznie określona w szablonie. Jeśli są wymagane jakiekolwiek zmiany, upewnij się, że określono ścieżkę zarówno dla kontenera , jak i katalogu w przypadku wystąpienia błędu połączenia.
SourceAvailabilityDataset — aby sprawdzić, czy dane źródłowe są dostępne.
SourceFilesDataset — aby uzyskać dostęp do danych źródłowych.
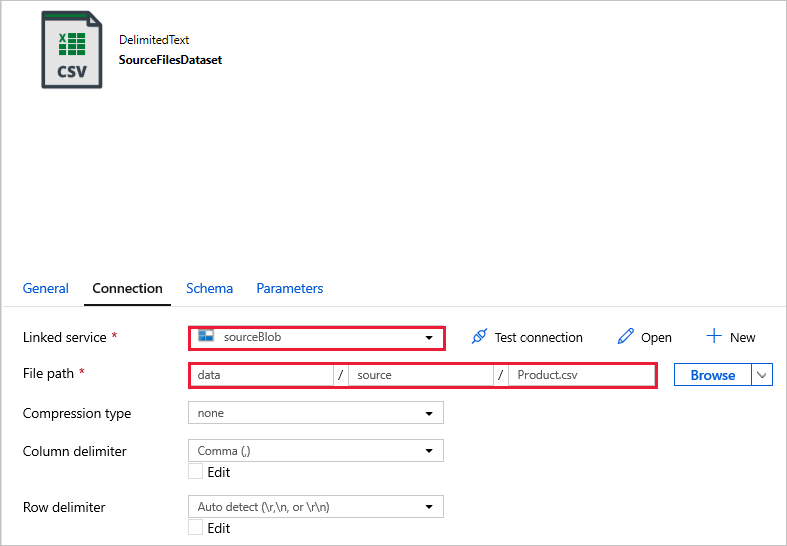
DestinationFilesDataset — aby skopiować dane do lokalizacji docelowej ujścia. Użyj następujących wartości:
Połączona usługa -
sinkBlob_LSutworzona w poprzednim kroku.Ścieżka pliku -
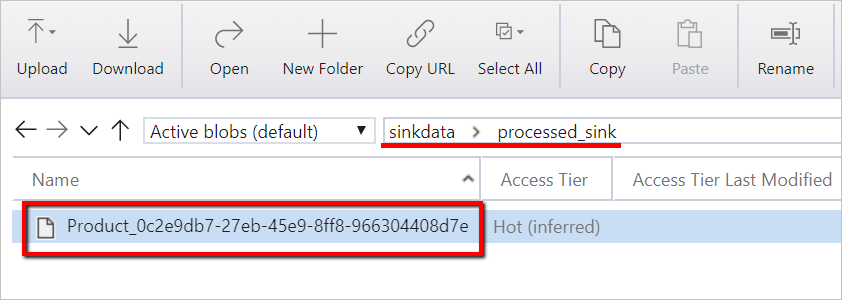
sinkdata/staged_sink.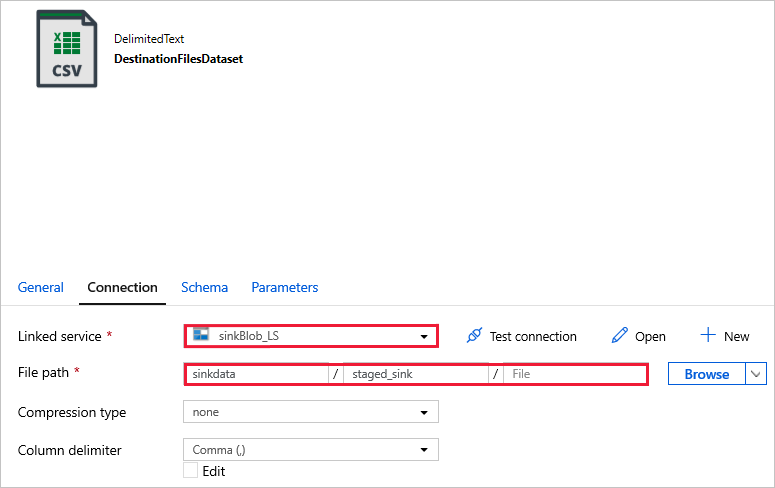
Wybierz Debuguj, aby uruchomić potok. Znajdziesz link do dzienników Databricks, aby uzyskać bardziej szczegółowe dzienniki Spark.
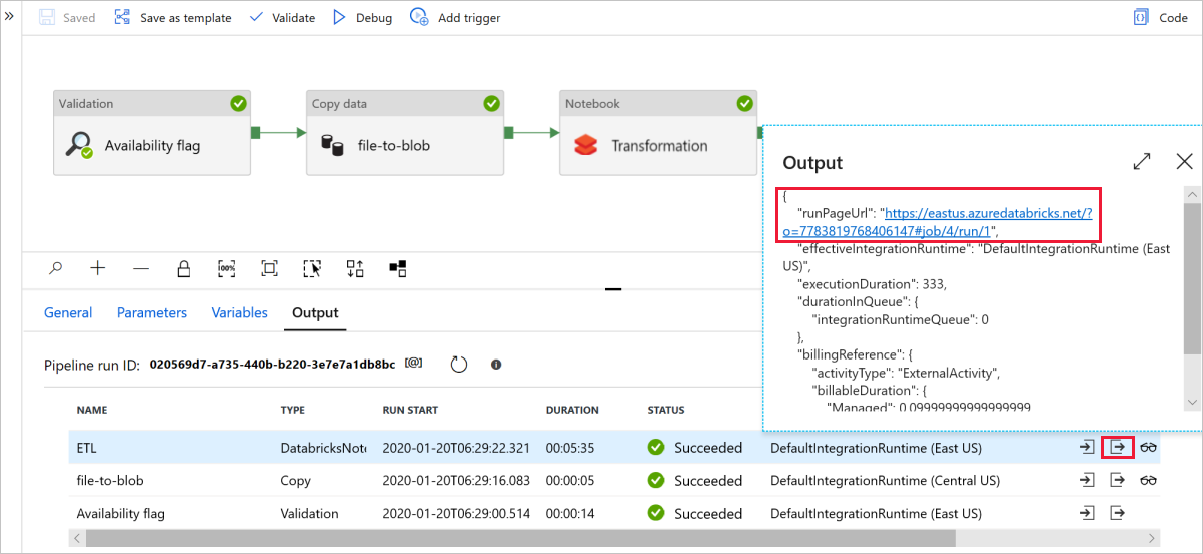
Plik danych można również zweryfikować przy użyciu Azure Storage Explorer.
Uwaga
W celu korelacji z przebiegami potoków w usłudze Data Factory, ten przykład dołącza identyfikator przebiegu potoku z Data Factory do folderu wyjściowego. Pomaga to śledzić pliki generowane przez każdy przebieg.