Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Potok danych w obszarze roboczym usługi Azure Data Factory lub Synapse Analytics przetwarza dane w połączonych usługach magazynowych przy użyciu połączonych usług obliczeniowych. Zawiera sekwencję działań, w których każde działanie wykonuje określoną operację przetwarzania. W tym artykule opisano aktywność Data Lake Analytics U-SQL, która uruchamia skrypt U-SQL na połączonej usłudze obliczeniowej Azure Data Lake Analytics.
Utwórz konto usługi Azure Data Lake Analytics przed utworzeniem potoku z użyciem operacji U-SQL w Data Lake Analytics. Aby dowiedzieć się więcej o Azure Data Lake Analytics, zobacz Rozpocznij pracę z Azure Data Lake Analytics.
Dodaj działanie U-SQL dla Azure Data Lake Analytics do potoku za pomocą interfejsu użytkownika
Aby użyć działania U-SQL dla Azure Data Lake Analytics w ramach potoku, wykonaj następujące kroki:
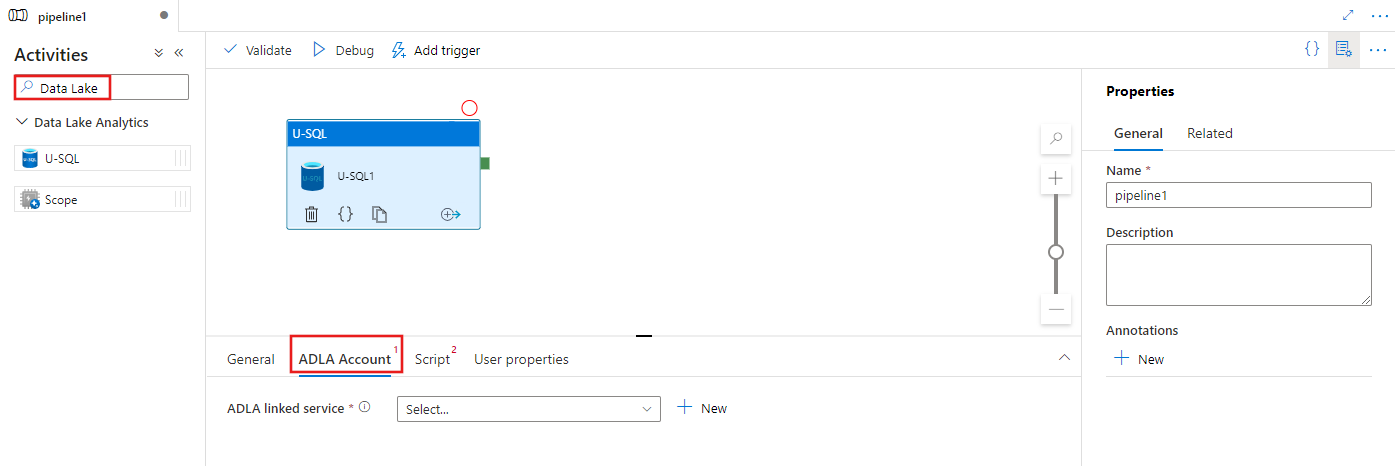
Wyszukaj Data Lake w okienku Działania potoku i przeciągnij działanie U-SQL na kanwę potoku.
Wybierz nowe działanie U-SQL na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę ADLA aby wybrać lub utworzyć nową połączoną usługę Azure Data Lake Analytics, która będzie używana do wykonywania działania U-SQL.
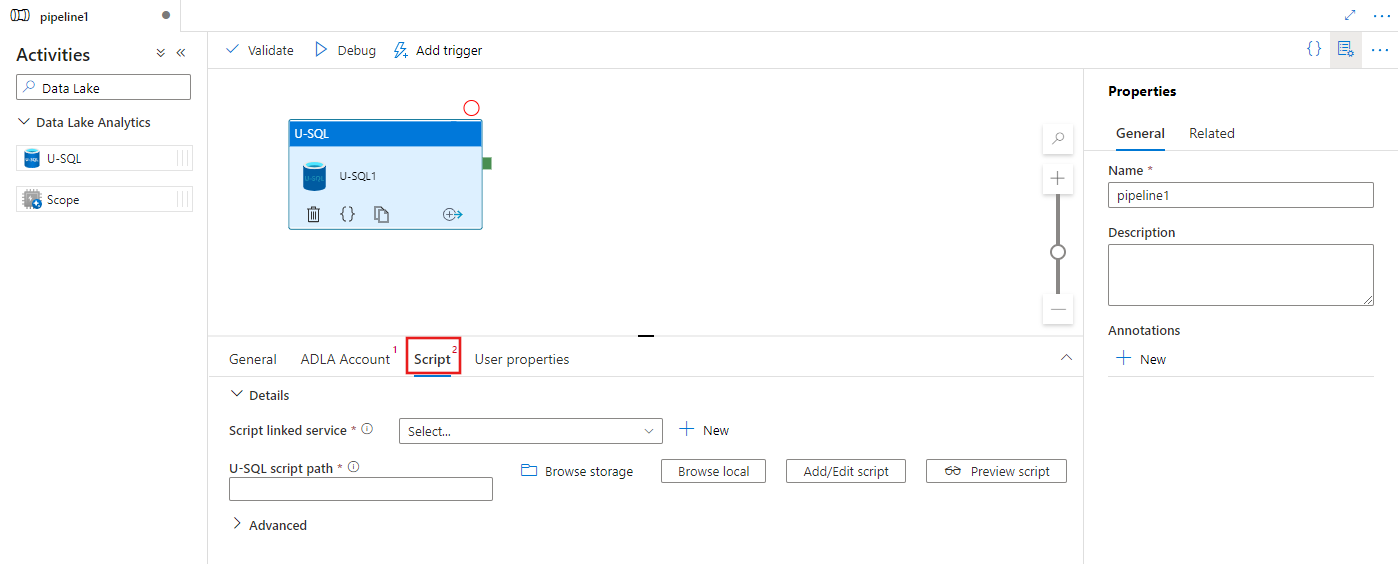
Wybierz kartę Skrypt, aby wybrać lub utworzyć nową usługę połączoną z magazynem oraz ścieżkę w lokalizacji magazynowej, która będzie hostować skrypt.
połączona usługa Azure Data Lake Analytics
Utwórz połączoną usługę Azure Data Lake Analytics, aby połączyć usługę obliczeniową Azure Data Lake Analytics z workspace’m Azure Data Factory lub Synapse Analytics. Działanie Data Lake Analytics U-SQL w potoku odnosi się do tej połączonej usługi.
Poniższa tabela zawiera opisy właściwości ogólnych używanych w definicji JSON.
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość typu powinna być ustawiona na: AzureDataLakeAnalytics. | Tak |
| accountName | Azure Data Lake Analytics nazwa konta. | Tak |
| dataLakeAnalyticsUri | URI usługi Azure Data Lake Analytics | Nie. |
| subscriptionId | identyfikator subskrypcji Azure | Nie. |
| resourceGroupName | nazwa grupy zasobów Azure | Nie. |
Uwierzytelnianie głównego elementu usługi
Połączona usługa Azure Data Lake Analytics wymaga uwierzytelniania jednostki usługi w celu nawiązania połączenia z usługą Azure Data Lake Analytics. Aby użyć uwierzytelniania pryncypała usługi, zarejestruj jednostkę aplikacji w Microsoft Entra ID i przyznaj jej dostęp zarówno do Data Lake Analytics, jak i używanego przez nią Data Lake Store. Aby uzyskać szczegółowe instrukcje, zobacz Uwierzytelnianie typu service-to-service. Zanotuj następujące wartości, których użyjesz do zdefiniowania połączonej usługi:
- Identyfikator aplikacji
- Klucz aplikacji
- Identyfikator dzierżawy
Nadaj jednostce usługi uprawnienia do Azure Data Lake Analytics przy użyciu kreatora Dodawania użytkownika.
Użyj uwierzytelniania jednostki usługi, określając następujące właściwości:
| Właściwości | Opis | Wymagane |
|---|---|---|
| servicePrincipalId | Określ identyfikator klienta aplikacji. | Tak |
| servicePrincipalKey | Określ klucz aplikacji. | Tak |
| tenant | Określ informacje o dzierżawie (nazwę domeny lub identyfikator dzierżawy), w ramach których znajduje się aplikacja. Możesz go pobrać, umieszczając wskaźnik myszy w prawym górnym rogu portalu Azure. | Tak |
Przykład: uwierzytelnianie głównego podmiotu usługi
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Aby dowiedzieć się więcej o połączonej usłudze, zobacz Powiązane usługi obliczeniowe.
Aktywność Data Lake Analytics U-SQL
Poniższy fragment JSON definiuje pipeline z aktywnością U-SQL w Data Lake Analytics. Definicja działania zawiera odwołanie do utworzonej wcześniej usługi połączonej Azure Data Lake Analytics. Aby wykonać skrypt języka U-SQL w usłudze Data Lake Analytics, usługa przesyła skrypt, który określiłeś, do Data Lake Analytics, a wymagane dane wejściowe i dane wyjściowe są zdefiniowane w skrypcie, aby Data Lake Analytics mogło je pobrać i przetworzyć.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
W poniższej tabeli opisano nazwy i opisy właściwości specyficznych dla tego działania.
| Właściwości | Opis | Wymagane |
|---|---|---|
| nazwa | Nazwa aktywności w pipeline | Tak |
| opis | Tekst opisujący działanie. | Nie. |
| typ | W przypadku działania Data Lake Analytics U-SQL typ działania to DataLakeAnalyticsU-SQL. | Tak |
| linkedServiceName | Połączona usługa z Azure Data Lake Analytics. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Dotyczący połączonych usług obliczeniowych. | Tak |
| scriptPath | Ścieżka do folderu zawierającego skrypt U-SQL. W nazwie pliku jest uwzględniana wielkość liter. | Tak |
| scriptLinkedService | Połączona usługa, która łączy Azure Data Lake Store lub Azure Storage który zawiera skrypt | Tak |
| stopień równoległości | Maksymalna liczba węzłów jednocześnie używanych do uruchamiania zadania. | Nie. |
| priorytet | Określa, które zadania z wszystkich znajdujących się w kolejce powinny zostać wybrane do uruchomienia jako pierwsze. Im niższa liczba, tym wyższy priorytet. | Nie. |
| parametry | Parametry do przekazania do skryptu U-SQL. | Nie. |
| wersjaWykonawcza | Wersja środowiska uruchomieniowego silnika U-SQL, której chcesz użyć. | Nie. |
| trybKompilacji | Tryb kompilacji języka U-SQL. Musi być jedną z tych wartości: Semantyka: przeprowadzaj tylko kontrole semantyczne i niezbędne kontrole poprawności, Pełne: wykonaj pełną kompilację, w tym sprawdzanie składni, optymalizację, generowanie kodu itp., SingleBox: wykonaj pełną kompilację z ustawieniem TargetType na SingleBox. Jeśli nie określisz wartości dla tej właściwości, serwer określi optymalny tryb kompilacji. |
Nie. |
Zobacz SearchLogProcessing.txt dla definicji skryptu.
Przykładowy skrypt U-SQL
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
W powyższym przykładzie skryptu dane wejściowe i wyjściowe skryptu są definiowane w parametrach @in i @out . Wartości parametrów @in i @out skryptu U-SQL są przekazywane dynamicznie przez usługę przy użyciu sekcji "parameters".
Możesz również określić inne właściwości, takie jak stopień równoległości (degreeOfParallelism) i priorytet, w definicji potoku dla zadań uruchamianych w usłudze Azure Data Lake Analytics.
Parametry dynamiczne
W przykładowej definicji potoku, parametry wejścia i wyjścia mają przypisane stałe wartości.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Zamiast tego można użyć parametrów dynamicznych. Na przykład:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
W takim przypadku pliki wejściowe są nadal pobierane z folderu /datalake/input, a pliki wyjściowe są generowane w folderze /datalake/output. Nazwy plików są dynamiczne w oparciu o czas rozpoczęcia okna, który jest przekazywany w momencie wyzwalania potoku.
Powiązana zawartość
Zapoznaj się z następującymi artykułami, które wyjaśniają sposób przekształcania danych na inne sposoby: