Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Działanie MapReduce usługi HDInsight w Azure Data Factory lub Synapse Analytics rurze wywołuje program MapReduce na własnym lub na żądanie klastrze usługi HDInsight. Ten artykuł opiera się na artykule dotyczącym działań przekształcania danych, który zawiera ogólne omówienie transformacji danych i obsługiwanych działań przekształcania.
Aby dowiedzieć się więcej, zapoznaj się z artykułami wprowadzającymi dotyczącymi Azure Data Factory i Synapse Analytics i wykonaj samouczek: Tutorial: przekształcanie danych przed przeczytaniem tego artykułu.
Aby uzyskać szczegółowe informacje na temat uruchamiania skryptów Pig/Hive w klastrze usługi HDInsight z potoku przy użyciu działań Pig i Hive usługi HDInsight, zobacz Pig i Hive.
Dodawanie działania MapReduce usługi HDInsight do potoku za pomocą interfejsu użytkownika
Aby użyć działania MapReduce usługi HDInsight do potoku, wykonaj następujące kroki:
Wyszukaj MapReduce w panelu Działania potoku i przeciągnij operację MapReduce do kanwy potoku.
Wybierz nowe działanie MapReduce na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę Klaster usługi HDI, aby wybrać lub utworzyć nową połączoną usługę z klastrem usługi HDInsight, który będzie używany do wykonywania działania MapReduce.
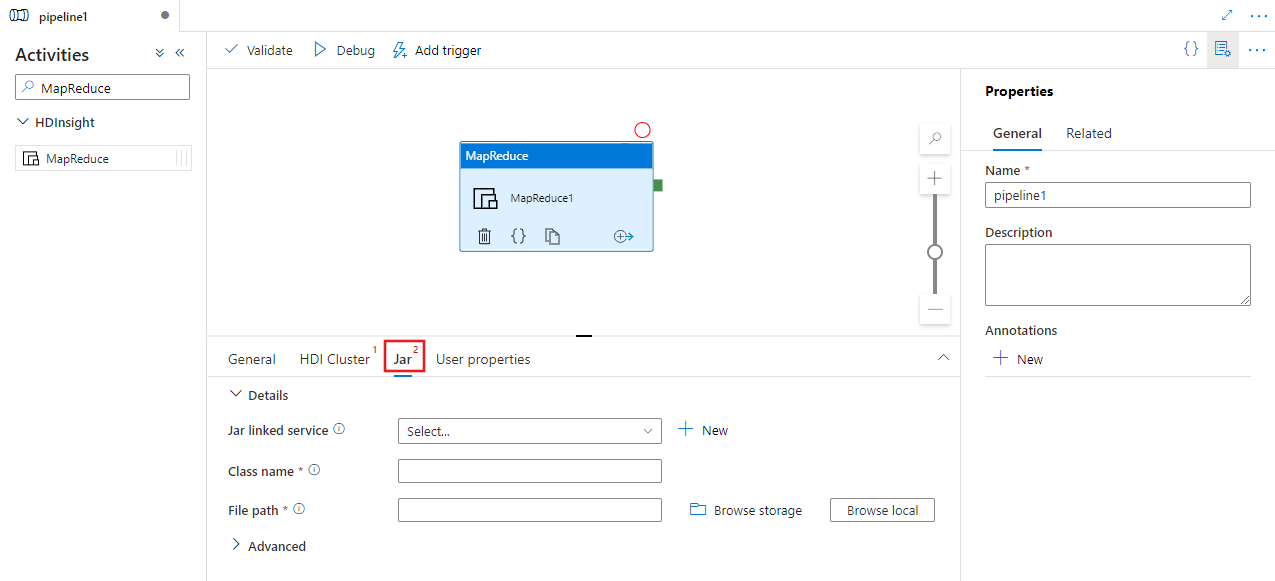
Wybierz kartę Jar aby wybrać lub utworzyć nową połączoną usługę Jar na koncie Azure Storage, które będzie hostować skrypt. Określ w nim nazwę klasy, która ma zostać wykonana, oraz ścieżkę pliku w lokalizacji przechowywania. Można również skonfigurować zaawansowane szczegóły, w tym lokalizację bibliotek Jar, konfigurację debugowania oraz argumenty i parametry, które mają być przekazywane do skryptu.
Składnia
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Szczegóły składni
| Właściwości | Opis | Wymagane |
|---|---|---|
| nazwa | Nazwa działania | Tak |
| opis | Tekst opisujący, do czego służy działanie | Nie. |
| typ | W przypadku działania MapReduce typ działania to HDinsightMapReduce | Tak |
| linkedServiceName | Odwołanie do klastra HDInsight zarejestrowanego jako usługa powiązana. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Dotyczący połączonych usług obliczeniowych. | Tak |
| className | Nazwa klasy, która ma zostać uruchomiona | Tak |
| jarLinkedService | Odwołanie do usługi połączonej z Azure Storage, używanej do przechowywania plików JAR. Obsługiwane są tylko Azure Blob Storage i ADLS Gen2 połączone usługi. Jeśli nie określisz tej połączonej usługi, zostanie użyta usługa połączona Azure Storage zdefiniowana w połączonej usłudze HDInsight. | Nie. |
| jarFilePath | Podaj ścieżkę do plików Jar przechowywanych w Azure Storage, do których odwołuje się plik jarLinkedService. W nazwie pliku jest uwzględniana wielkość liter. | Tak |
| jarlibs | Tablica ciągów ścieżki do plików biblioteki Jar, do których odwołuje się zadanie przechowywane w Azure Storage zdefiniowanym w pliku jarLinkedService. W nazwie pliku jest uwzględniana wielkość liter. | Nie. |
| getDebugInfo | Określa, kiedy pliki dziennika są kopiowane do Azure Storage używanego przez klaster HDInsight lub określonego przez jarLinkedService. Dozwolone wartości: Brak, Zawsze lub Niepowodzenie. Wartość domyślna: None. | Nie. |
| Argumenty | Określa tablicę argumentów dla zadania Hadoop. Argumenty są przekazywane jako parametry wiersza polecenia do każdego zadania. | Nie. |
| Definiuje | Określ parametry jako pary klucz/wartość, aby odwoływać się do skryptu Hive. | Nie. |
Przykład
Możesz użyć działania MapReduce usługi HDInsight, aby uruchomić dowolny plik jar MapReduce w klastrze usługi HDInsight. W poniższej przykładowej definicji JSON potoku działanie usługi HDInsight jest skonfigurowane do uruchamiania pliku JAR Mahout.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
W sekcji argumentów można określić wszystkie argumenty programu MapReduce. W czasie wykonywania zostanie wyświetlonych kilka dodatkowych argumentów (na przykład mapreduce.job.tags) ze struktury MapReduce. Aby odróżnić swoje argumenty od argumentów MapReduce, rozważ użycie zarówno opcji, jak i wartości jako argumentów, jak pokazano w poniższym przykładzie (-s,--input,--output itp., są opcjami bezpośrednio następującymi wartościami).
Powiązana zawartość
Zapoznaj się z następującymi artykułami, które wyjaśniają sposób przekształcania danych na inne sposoby: