Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym samouczku tworzysz potok usługi Data Factory, prezentujący niektóre funkcje przepływu sterowania. Ten przepływ wykonuje prostą kopię z kontenera w Azure Blob Storage do innego kontenera na tym samym koncie magazynowym. Jeśli działanie kopiowania zakończy się powodzeniem, pipeline wysyła szczegóły zakończonej pomyślnie operacji kopiowania (takie jak ilość zapisanych danych) w e-mailu potwierdzającym sukces. W przypadku niepowodzenia działania kopiowania, potok wysyła szczegóły dotyczące niepowodzenia kopiowania (takie jak komunikat o błędzie) w wiadomości e-mail informującej o niepowodzeniu. W samouczku pokazano, jak przekazać parametry.
Ogólne omówienie scenariusza: 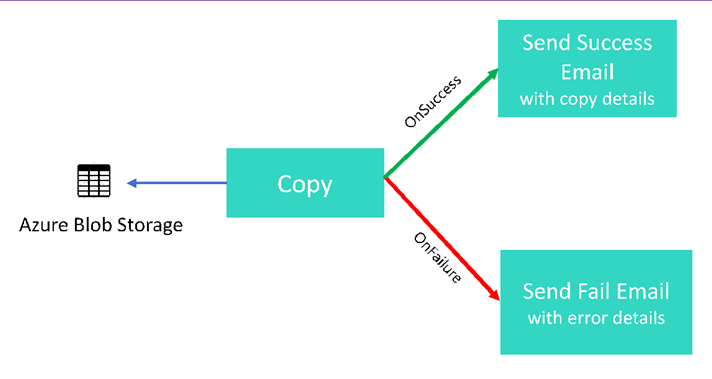
W tym samouczku wykonasz następujące kroki:
- Tworzenie fabryki danych.
- Utwórz połączoną usługę Azure Storage.
- Tworzenie zbioru danych Blob Azure
- Utwórz potok, który zawiera Copy activity i Web activity
- Wysyłanie danych wyjściowych działań do kolejnych działań
- Korzystanie z przekazywania parametrów i ze zmiennych systemowych
- Rozpocznij uruchomienie potoku
- Monitoruj potok i uruchomienia działań
W tym samouczku korzystamy z portalu Azure. Możesz użyć innych mechanizmów do interakcji z Azure Data Factory. Zapoznaj się z sekcją "Szybki start" w spisie treści.
Wymagania wstępne
- Subskrypcja Azure. Jeśli nie masz subskrypcji Azure, przed rozpoczęciem utwórz konto free.
- konto Azure Storage. Ty używasz magazynu obiektów blob jako źródłowego magazynu danych. Jeśli nie masz konta magazynu Azure, zobacz artykuł Utwórz konto magazynu aby uzyskać instrukcje tworzenia konta.
- Azure SQL Database. Baza danych jest używana jako magazyn danych ujścia. Jeśli nie masz bazy danych w Azure SQL Database, zobacz artykuł Utwórz bazę danych w Azure SQL Database aby uzyskać instrukcje tworzenia bazy danych.
Utwórz tabelę obiektów blob
Uruchom program Notatnik. Skopiuj poniższy tekst i zapisz go na dysku jako plik input.txt.
John,Doe Jane,DoeUżyj narzędzi, takich jak Azure Storage Explorer wykonaj następujące czynności:
- Utwórz kontener adfv2branch.
- Utwórz folder input w kontenerze adfv2branch.
- Przekaż plik input.txt do kontenera.
Tworzenie punktów końcowych przepływu pracy poczty e-mail
Aby wyzwolić wysyłanie wiadomości e-mail z potoku, użyj Azure Logic Apps aby zdefiniować przepływ pracy. Aby uzyskać więcej informacji na temat tworzenia przepływu pracy w aplikacji logiki typu Consumption, zobacz Tworzenie przykładowego przepływu pracy w aplikacji logiki typu Consumption.
Przepływ pracy dla wiadomości e-mail dotyczących sukcesów
Utwórz przepływ pracy aplikacji logiki typu Consumption o nazwie CopySuccessEmail. Dodaj wyzwalacz żądania o nazwie Przy odebraniu żądania HTTP i dodaj akcję Office 365 Outlook o nazwie Send an email. Jeśli zostanie wyświetlony monit, zaloguj się do konta Office 365 Outlook.
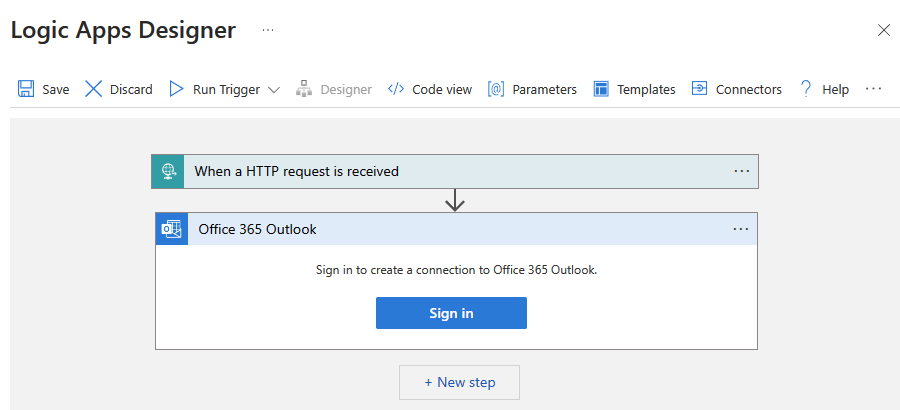
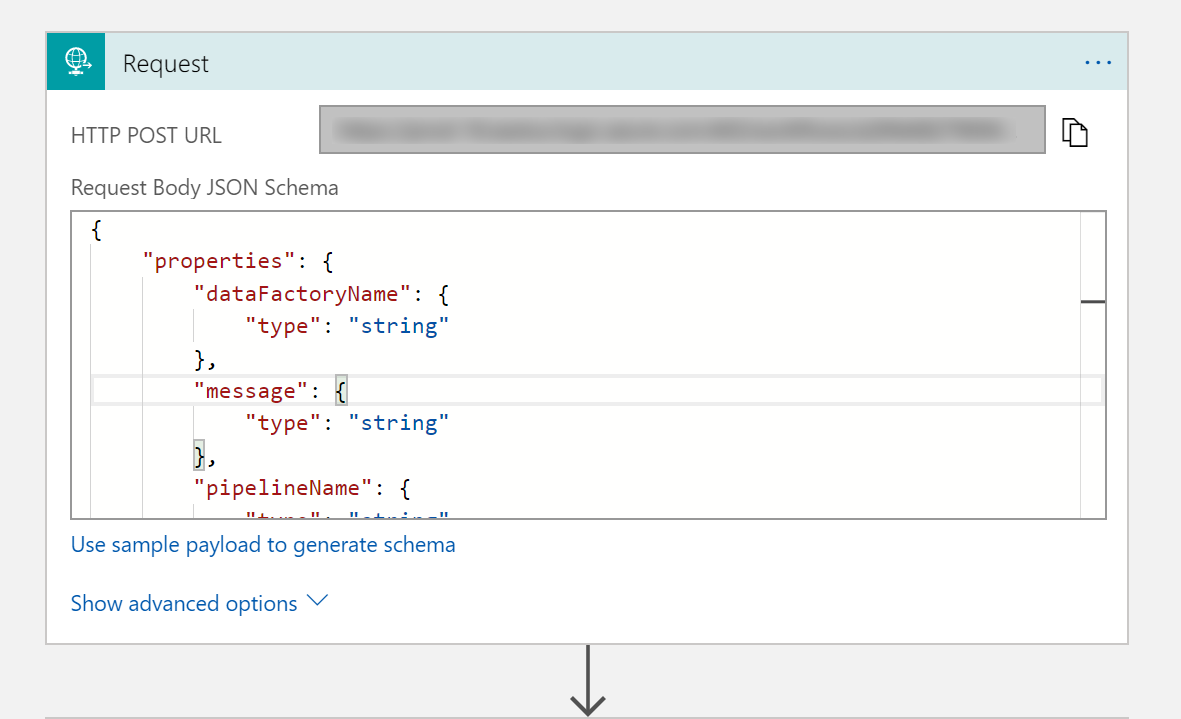
W przypadku wyzwalacza Żądanie wypełnij pole Schemat treści JSON następującym kodem JSON:
{
"properties": {
"dataFactoryName": {
"type": "string"
},
"message": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"receiver": {
"type": "string"
}
},
"type": "object"
}
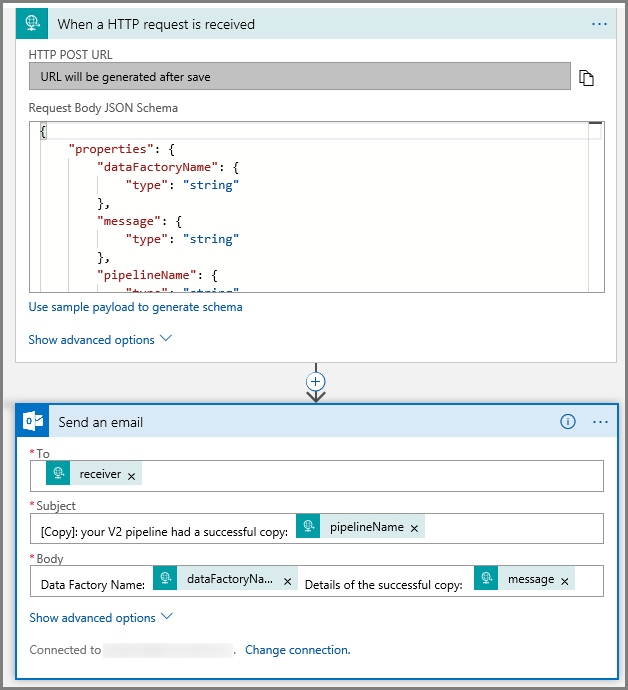
Wyzwalacz "Żądanie" w projektancie przepływu pracy powinien wyglądać jak na obrazie poniżej.
W przypadku akcji Wyślij wiadomość e-mail dostosuj sposób formatowania wiadomości e-mail przy użyciu właściwości przekazanych w schemacie JSON treści żądania. Oto przykład:
Zapisz przepływ pracy. Zapisz adres URL żądania HTTP POST dla przepływu pracy wiadomości e-mail związanej z sukcesem:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Przepływ pracy wiadomości e-mail z informacją o niepowodzeniu
Wykonaj te same kroki, aby utworzyć inny przepływ pracy aplikacji logiki o nazwie CopyFailEmail. W wyzwalaczu Żądanie wartość schematu JSON treści żądania jest taka sama. Zmień format wiadomości e-mail, na przykład element Subject, aby przekształcić wiadomość e-mail w wiadomość z informacją o niepowodzeniu. Oto przykład:
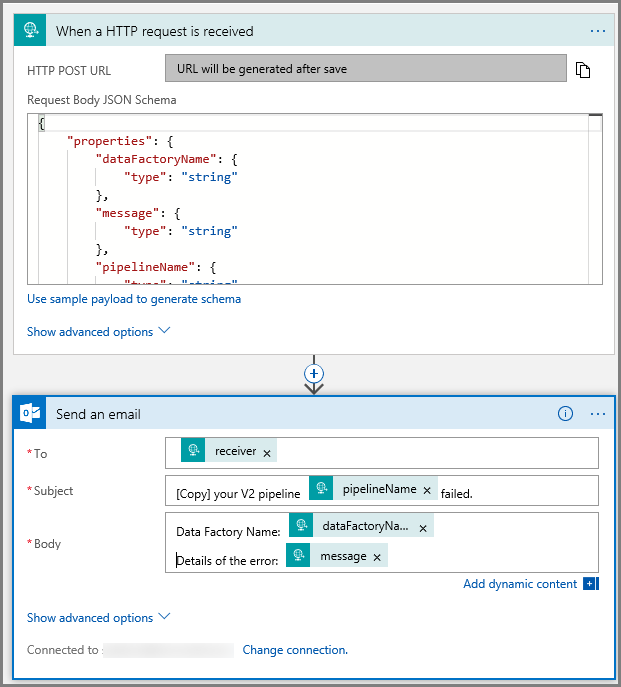
Zapisz przepływ pracy. Zapisz adres URL żądania HTTP POST dla przepływu pracy wiadomości e-mail z informacją o niepowodzeniu:
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Teraz powinny być zapisane dwa adresy URL przepływów pracy:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Tworzenie fabryki danych
Uruchom Microsoft Edge lub Google Chrome przeglądarki internetowej. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko w przeglądarkach internetowych Microsoft Edge i Google Chrome.
Rozwiń menu w lewym górnym rogu i wybierz pozycję Utwórz zasób. Następnie wybierz pozycję Analytics>Data Factory :
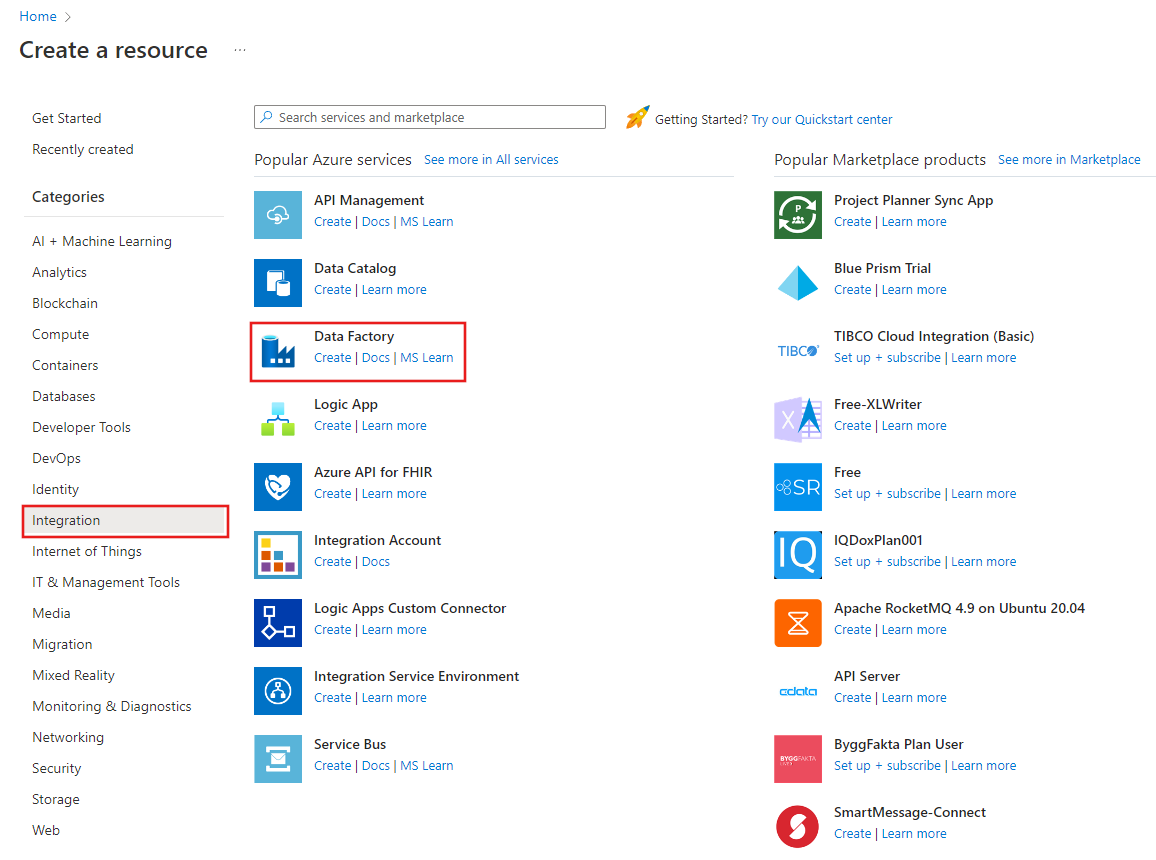
Na stronie Nowa fabryka danych wprowadź wartość ADFTutorialDataFactory w polu Nazwa.
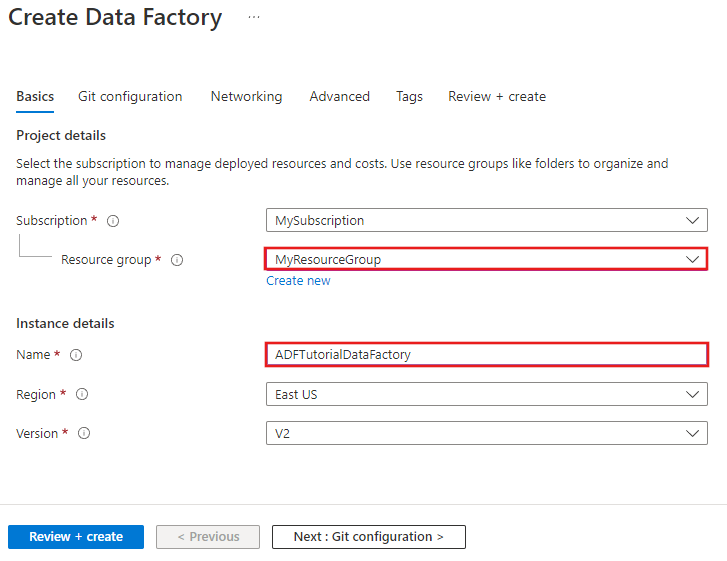
Nazwa fabryki danych Azure musi być unikatowa na całym świecie. Jeśli wystąpi poniższy błąd, zmień nazwę fabryki danych (np. twojanazwaADFTutorialDataFactory) i spróbuj utworzyć ją ponownie. Artykuł Data Factory — Naming Rules (Usługa Data Factory — reguły nazewnictwa) zawiera reguły nazewnictwa artefaktów usługi Data Factory.
Nazwa fabryki danych "ADFTutorialDataFactory" jest niedostępna.
Wybierz swoją subskrypcję Azure, w której chcesz utworzyć fabrykę danych.
Dla opcji Grupa zasobów wykonaj jedną z następujących czynności:
Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Aby dowiedzieć się więcej o grupach zasobów, zobacz Za pomocą grup zasobów do zarządzania zasobami Azure.
Wybierz V2 dla wersji.
Wybierz lokalizację dla fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (Azure Storage, Azure SQL Database itp.) i obliczenia (HDInsight itp.) używane przez fabrykę danych mogą znajdować się w innych regionach.
Wybierz opcję Przypnij do pulpitu nawigacyjnego.
Kliknij pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlona strona Fabryka danych, jak pokazano na poniższej ilustracji.
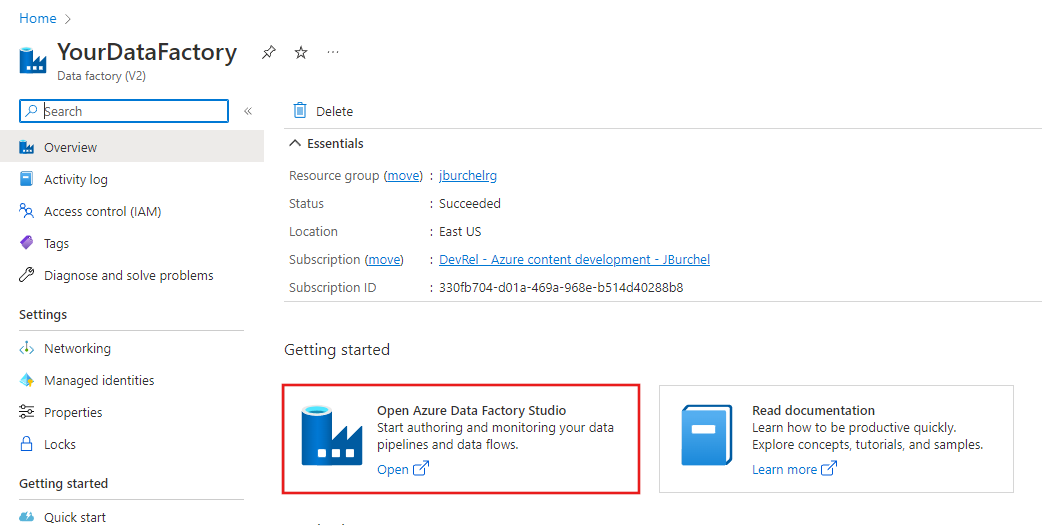
Kliknij kafelek Otwórz Azure Data Factory Studio, aby otworzyć interfejs użytkownika Azure Data Factory na osobnej karcie.
Utwórz potok
W tym kroku utworzysz potok z jednym działaniem kopiowania i dwoma działaniami sieciowymi. Do utworzenia potoku używasz następujących funkcji:
- Parametry dla potoku, do których dostęp mają zestawy danych.
- Działania sieciowe wywołujące przepływy pracy aplikacji Logic Apps w celu wysyłania wiadomości e-mail informujących o powodzeniu/niepowodzeniu.
- Łączenie jednego działania z innym (w przypadku powodzenia i niepowodzenia)
- Używanie danych wyjściowych działania jako danych wejściowych kolejnego działania
Na stronie głównej interfejsu użytkownika usługi Data Factory kliknij kafelek Orkiestracja .
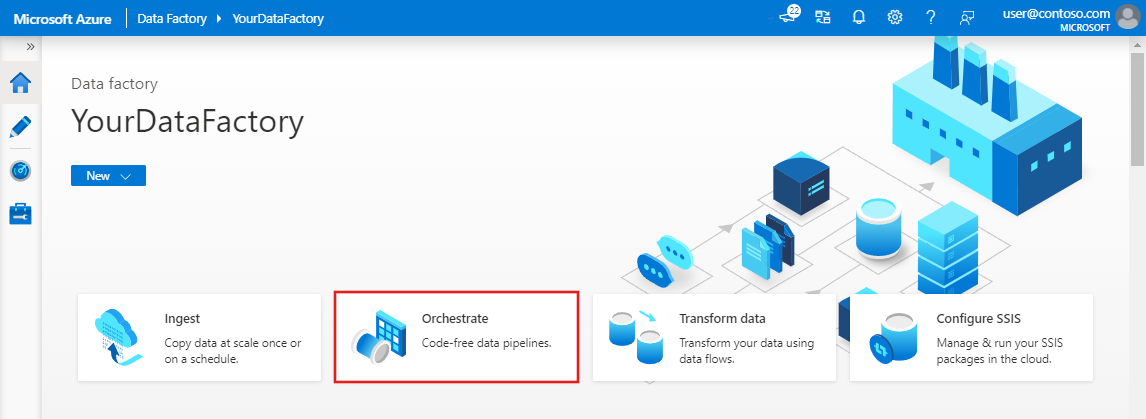
W oknie właściwości dla potoku przejdź do karty Parametry i użyj przycisku Nowy, aby dodać następujące trzy parametry typu String: sourceBlobContainer, sinkBlobContainer oraz receiver.
- sourceBlobContainer — parametr w potoku używany przez zestaw danych źródłowych obiektu blob.
- sinkBlobContainer — parametr w potoku używany przez zestaw danych obiektów blob ujścia
- receiver — ten parametr jest używany przez dwa działania w sieci Web w przepływie pracy, które wysyłają wiadomości e-mail z informacją o sukcesie lub niepowodzeniu do odbiorcy, którego adres e-mail jest określony przez ten parametr.
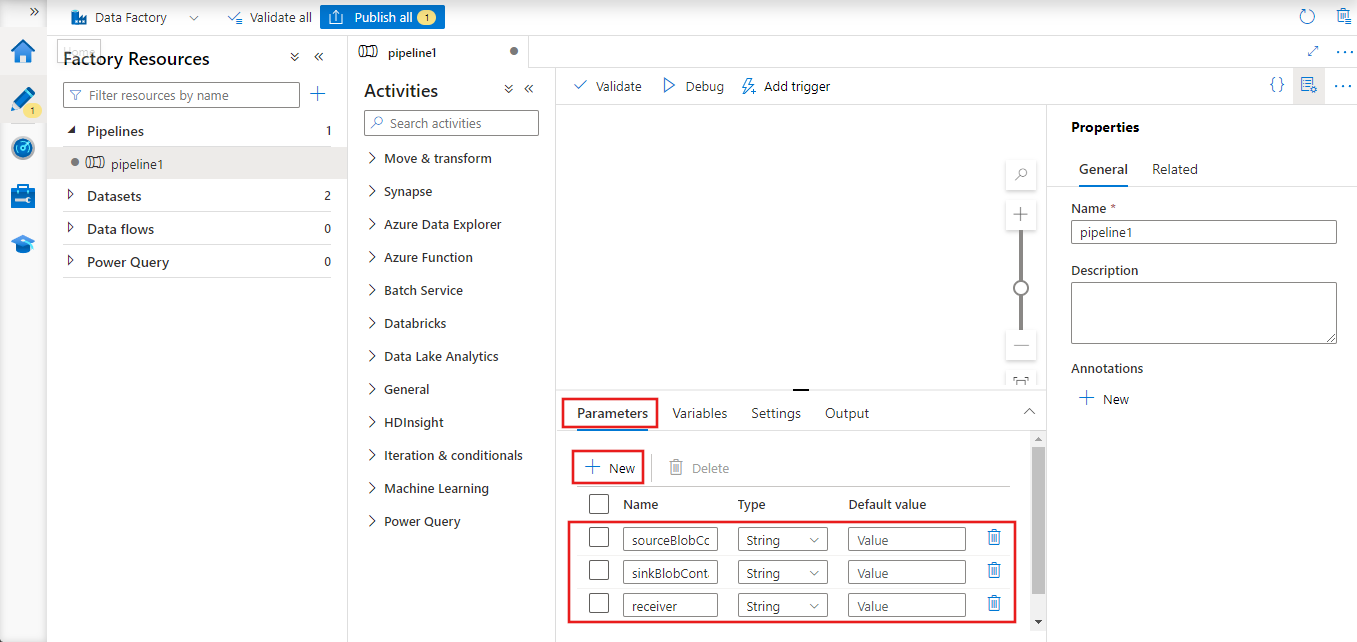
W przyborniku Działania wyszukaj aktywność Kopiuj i upuść i przeciągnij aktywność Kopiuj na powierzchnię projektanta przepływu danych.
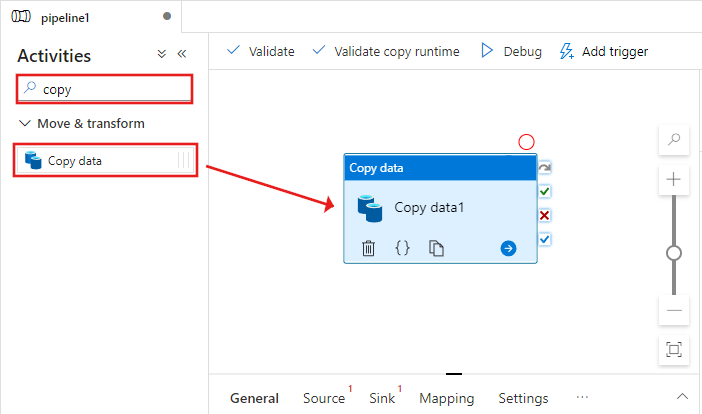
Wybierz działanie Kopiowania przeciągnięte na obszar projektanta potoku. W oknie Właściwości dla działania Kopiowanie znajdującego się na dole przejdź do karty Źródło, a następnie kliknij pozycję + Nowy. W tym kroku utworzysz zestaw danych źródłowych dla działania kopiowania.
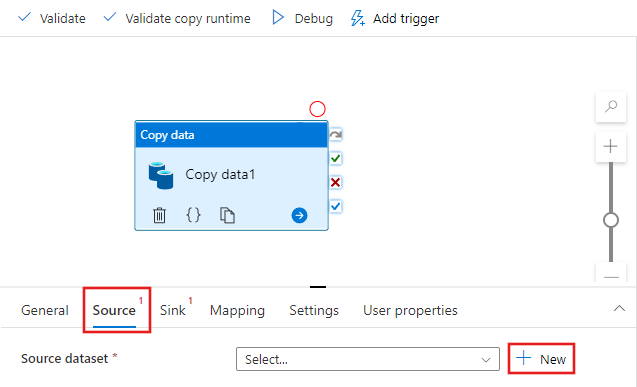
W oknie Nowy zestaw danych wybierz kartę Azure u góry, a następnie wybierz Azure Blob Storage i wybierz Continue.
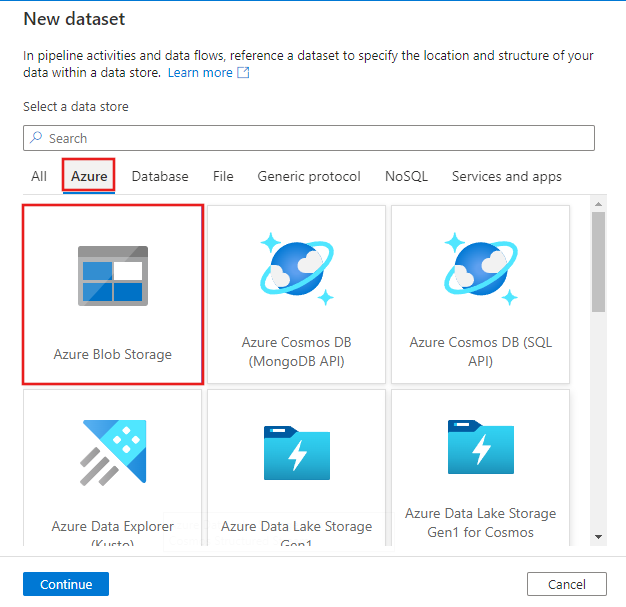
W oknie Wybieranie formatu wybierz pozycję RozdzielanyTekst i wybierz pozycję Kontynuuj.

Zostanie wyświetlona nowa karta o nazwie Ustaw właściwości. Zmień nazwę zestawu danych na SourceBlobDataset. Wybierz listę rozwijaną Połączona usługa i wybierz +Nowy, aby utworzyć nową połączoną usługę ze źródłowym zestawem danych.
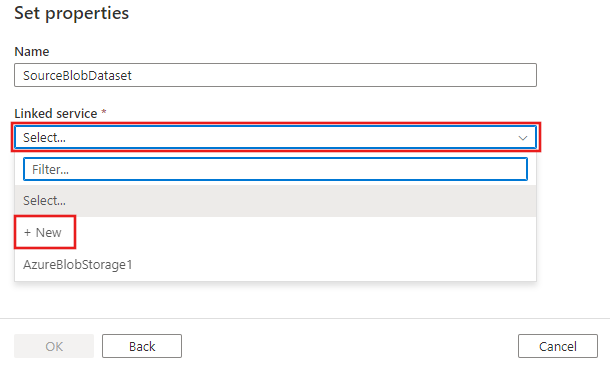
Zostanie wyświetlone okno Nowa połączona usługa , w którym można wypełnić wymagane właściwości połączonej usługi.
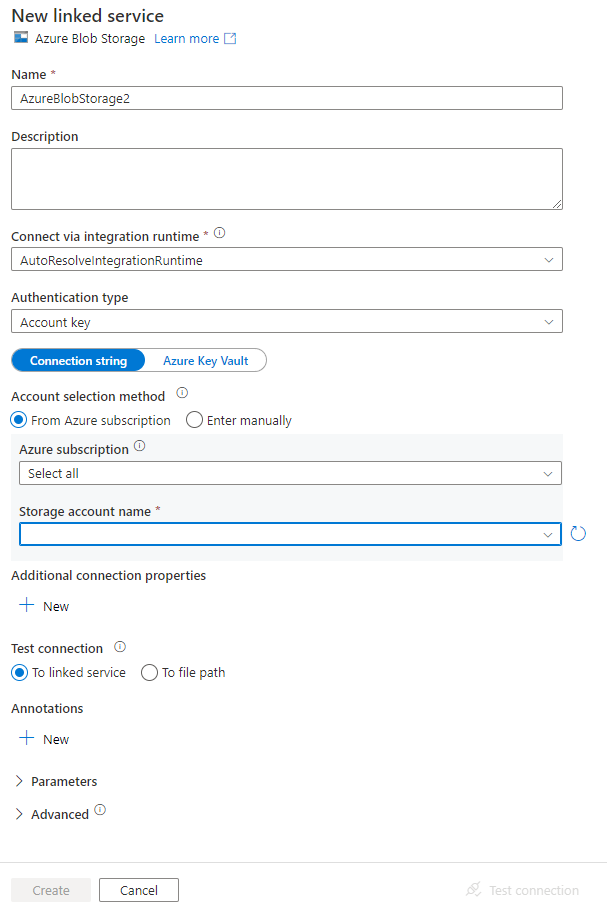
W oknie Nowa połączona usługa wykonaj następujące czynności:
- Wprowadź wartość AzureStorageLinkedService w polu Nazwa.
- Wybierz konto magazynu Azure dla nazwy konta Storage.
- Kliknij pozycję Utwórz.
W wyświetlonym oknie Ustawianie właściwości wybierz pozycję Otwórz ten zestaw danych , aby wprowadzić sparametryzowaną wartość dla nazwy pliku.
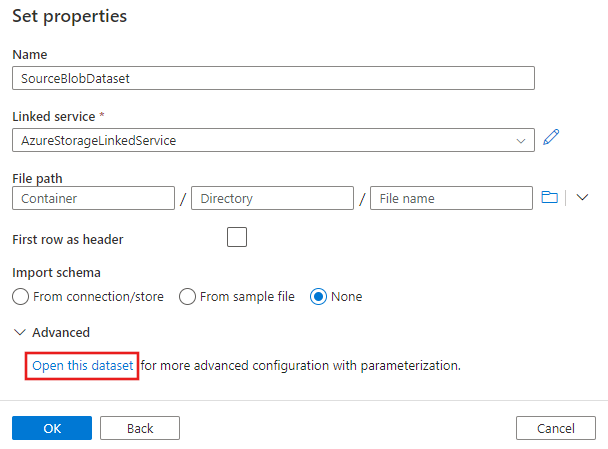
Wprowadź wartość
@pipeline().parameters.sourceBlobContainerjako folder orazemp.txtjako nazwę pliku.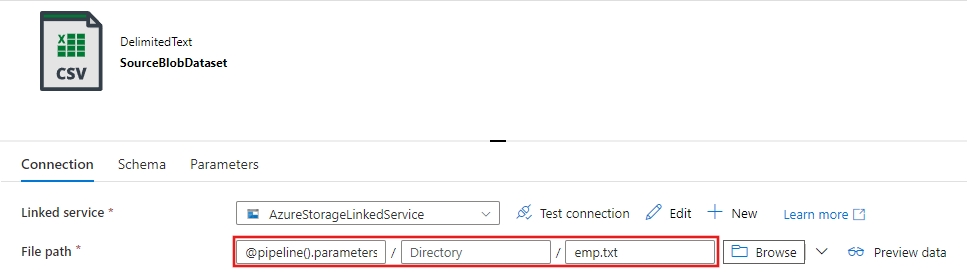
Przełącz się z powrotem na kartę potoku (lub kliknij potok w widoku drzewa po lewej stronie), a następnie wybierz aktywność Kopiuj w kreatorze. Upewnij się, że dla zestawu danych źródłowych wybrano nowy zestaw danych.
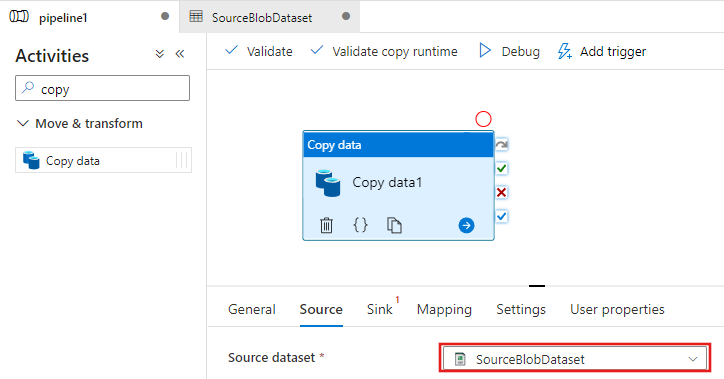
W oknie Właściwości przejdź do karty Ujście, a następnie kliknij pozycję + Nowy dla elementu Zestaw danych ujścia. W tym kroku utworzysz zestaw danych ujścia dla działania kopiowania w sposób podobny do tworzenia zestawu danych źródłowych.
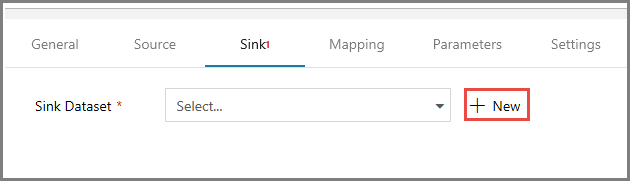
W oknie Nowy zestaw danych wybierz Azure Blob Storage i kliknij Continue, a następnie ponownie wybierz DelimitedText ponownie na Wybierz format i kliknij ponownie Continue.
Na stronie Ustawianie właściwości zestawu danych wprowadź wartość SinkBlobDataset w polu Nazwa, a następnie wybierz pozycję AzureStorageLinkedService dla pozycji LinkedService.
Rozwiń sekcję Zaawansowane na stronie właściwości i wybierz pozycję Otwórz ten zestaw danych.
Na karcie Połączenie zestawu danych zmodyfikuj ścieżkę pliku. Wprowadź
@pipeline().parameters.sinkBlobContainerdla folderu i@concat(pipeline().RunId, '.txt')dla nazwy pliku. Wyrażenie wykorzystuje identyfikator bieżącego uruchomienia potoku jako nazwę pliku. Aby uzyskać listę obsługiwanych zmiennych systemowych i wyrażeń, zobacz Zmienne systemowe i Język wyrażeń.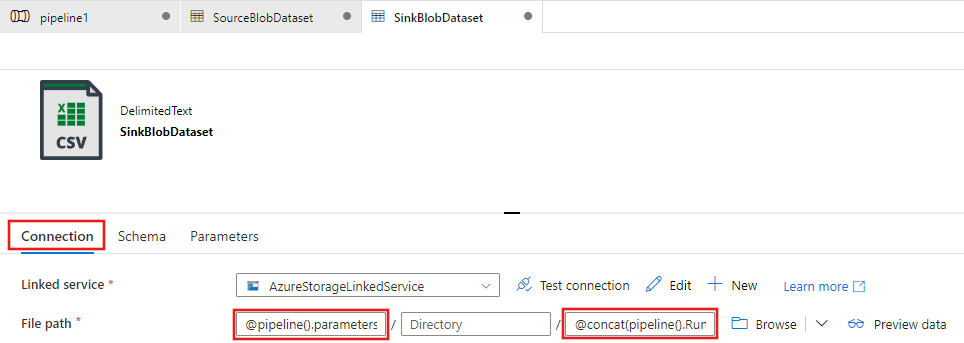
Przejdź do zakładki pipeline na górze. Wyszukaj Web w polu wyszukiwania i przeciągnij i upuść aktywność Web na powierzchnię projektanta potoku. Ustaw nazwę działania na wartość SendSuccessEmailActivity. Działanie internetowe umożliwia wywołanie dowolnego punktu końcowego REST. Aby uzyskać więcej informacji na temat działania, zobacz Działanie internetowe. Ten pipeline używa Aktywności internetowej do uruchomienia przepływu pracy e-mail w usłudze Logic Apps.
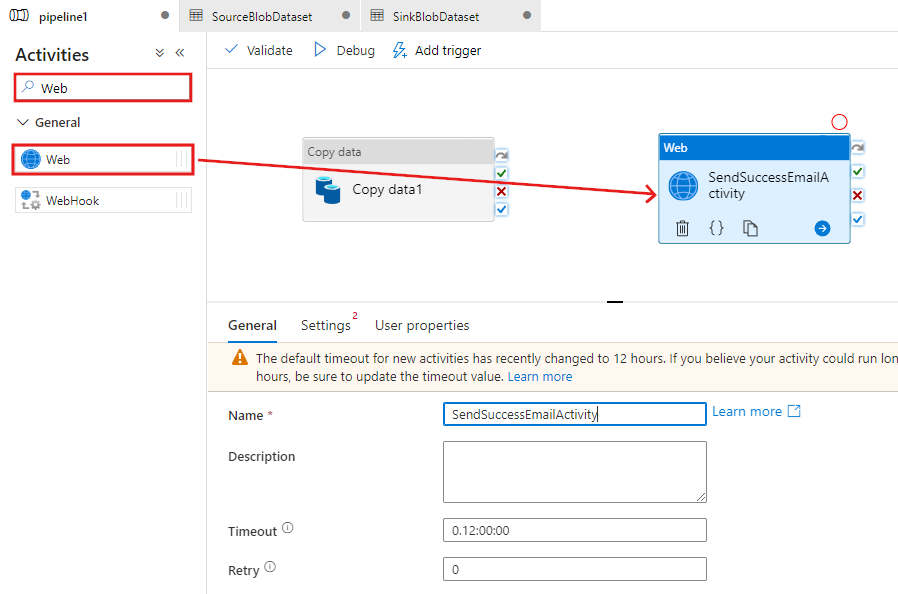
Z karty Ogólne przejdź do karty Ustawienia i wykonaj następujące czynności:
W pozycji Adres URL podaj adres URL dla przepływu pracy aplikacji Logic Apps, który wysyła wiadomość e-mail z potwierdzeniem powodzenia.
Wybierz wartość POST dla pozycji Metoda.
Kliknij link + Dodaj nagłówek w sekcji Nagłówki.
Dodaj nagłówek Content-Type i ustaw go na wartość application/json.
Podaj następujący kod JSON w pozycji Treść.
{ "message": "@{activity('Copy1').output.dataWritten}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }Treść wiadomości zawiera następujące właściwości:
Komunikat: Przekazywanie wartości
@{activity('Copy1').output.dataWritten. Uzyskuje dostęp do właściwości poprzedniego działania kopiowania danych i przekazuje wartość danych zapisanych. W przypadku niepowodzenia przekaż dane wyjściowe błędu zamiast@{activity('CopyBlobtoBlob').error.message.Nazwa fabryki danych — przekazywanie wartości
@{pipeline().DataFactory}To jest zmienna systemowa, umożliwiająca dostęp do odpowiedniej nazwy fabryki danych. Lista zmiennych systemowych jest dostępna w artykule Zmienne systemowe.Nazwa pipeline'a — przekazywanie wartości
@{pipeline().Pipeline}. Jest to również zmienna systemowa, która umożliwia dostęp do odpowiedniej nazwy potoku.Odbiorca - przekazywanie wartości "@pipeline().parameters.receiver"). Dostęp do parametrów potoku.
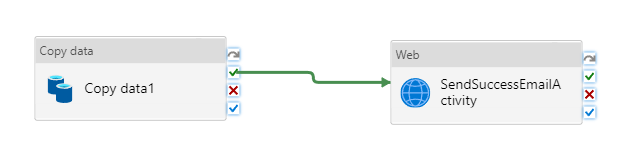
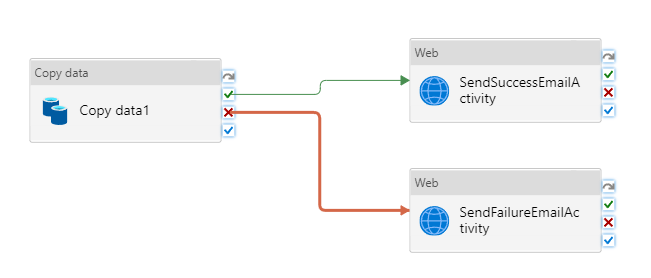
Połącz czynność Copy z czynnością Web, przeciągając zielony przycisk obok Copy i upuszczając go na czynność Web.
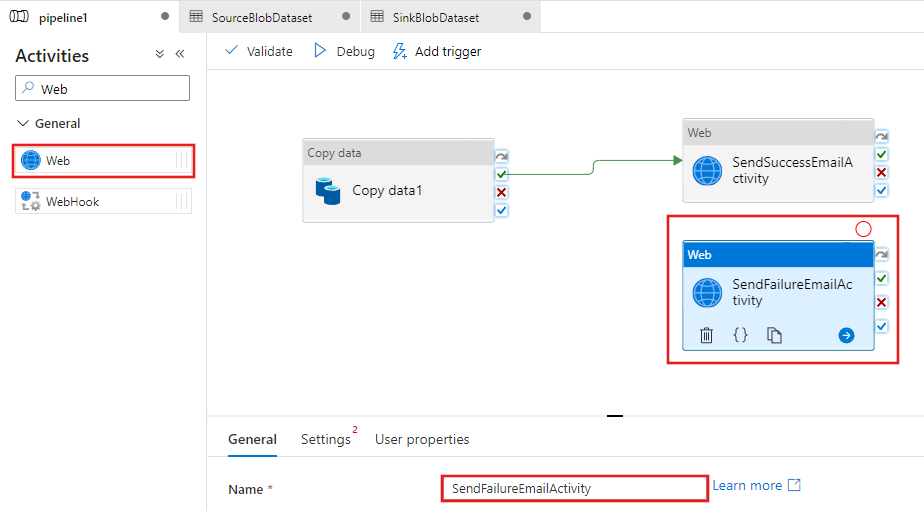
Przeciągnij kolejną aktywność Web z przybornika Działania i upuść ją na obszarze projektanta potoku, a następnie ustaw nazwę na SendFailureEmailActivity.
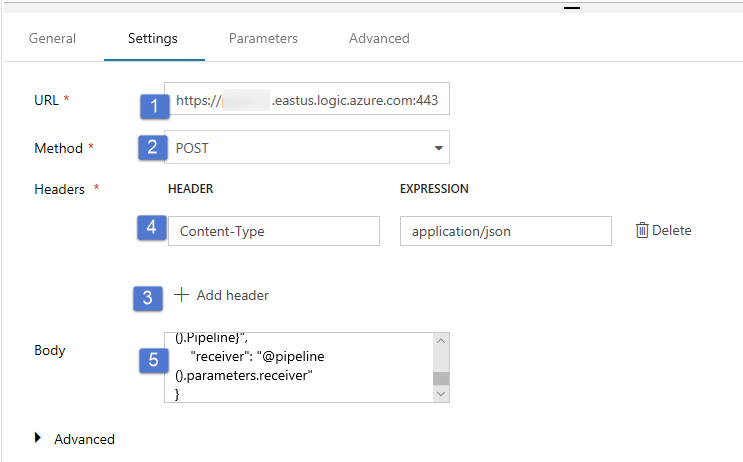
Przejdź do karty Ustawienia i wykonaj następujące czynności:
W pozycji Adres URL określ adres URL dla przepływu pracy aplikacji logicznych, który wysyła wiadomość e-mail o niepowodzeniu.
Wybierz wartość POST dla pozycji Metoda.
Kliknij link + Dodaj nagłówek w sekcji Nagłówki.
Dodaj nagłówek Content-Type i ustaw go na wartość application/json.
Podaj następujący kod JSON w pozycji Treść.
{ "message": "@{activity('Copy1').error.message}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }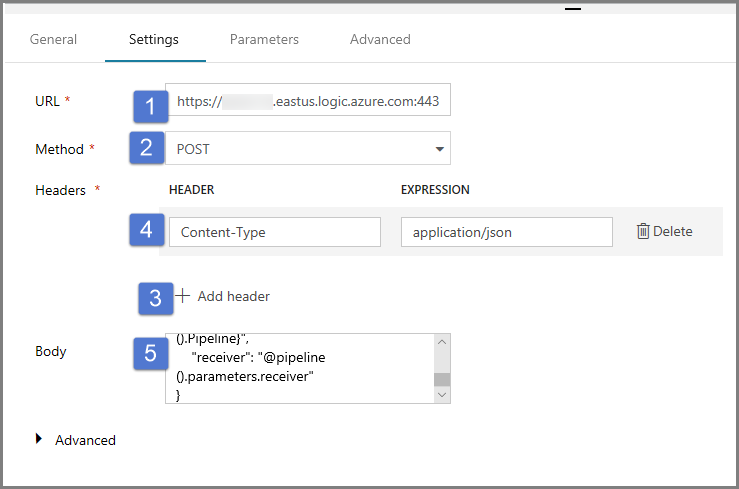
Wybierz czerwony przycisk X po prawej stronie akcji Kopiowanie w projektancie potoku i przenieś go na właśnie utworzoną aktywność SendFailureEmailActivity.
Aby zweryfikować potok danych, kliknij przycisk Weryfikuj na pasku narzędzi. Zamknij okno Dane wyjściowe weryfikacji potoku, klikając na przycisk >>.
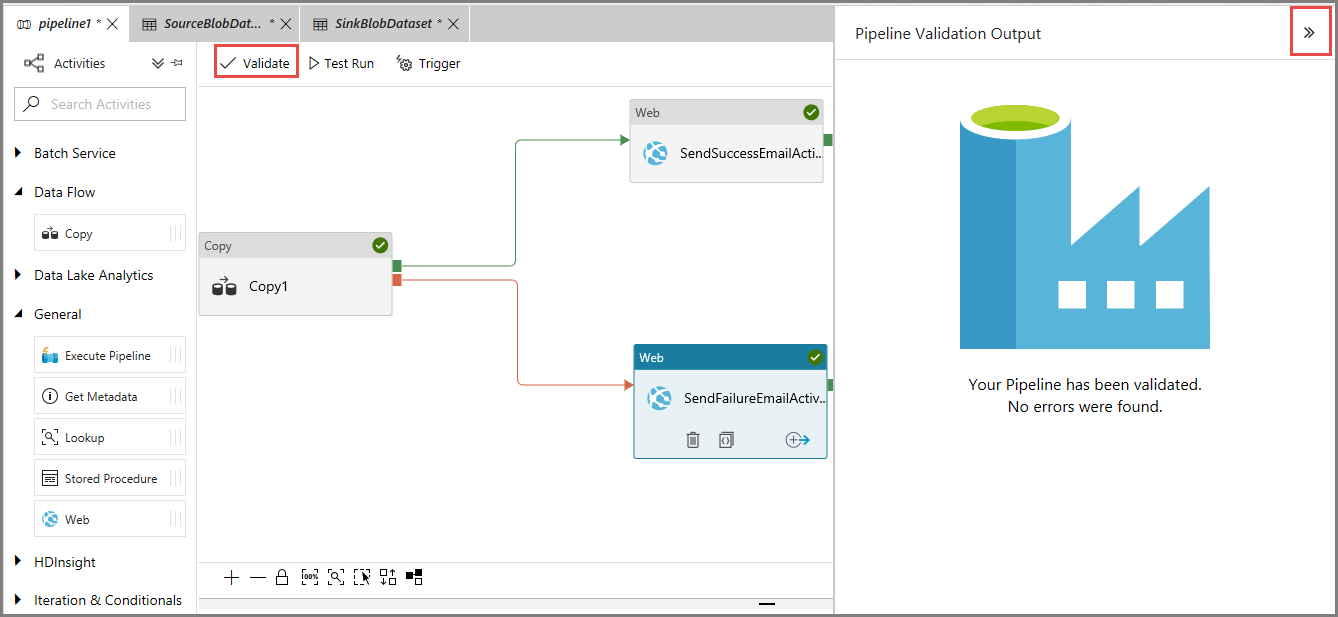
Aby opublikować jednostki (zestawy danych, potoki itp.) w usłudze Data Factory, wybierz Opublikuj wszystko. Poczekaj na wyświetlenie komunikatu Pomyślnie opublikowano.

Wyzwól uruchomienie potoku, które zakończy się powodzeniem
Aby uruchomić potok, kliknij Uruchom na pasku narzędzi, a następnie kliknij Uruchom teraz.
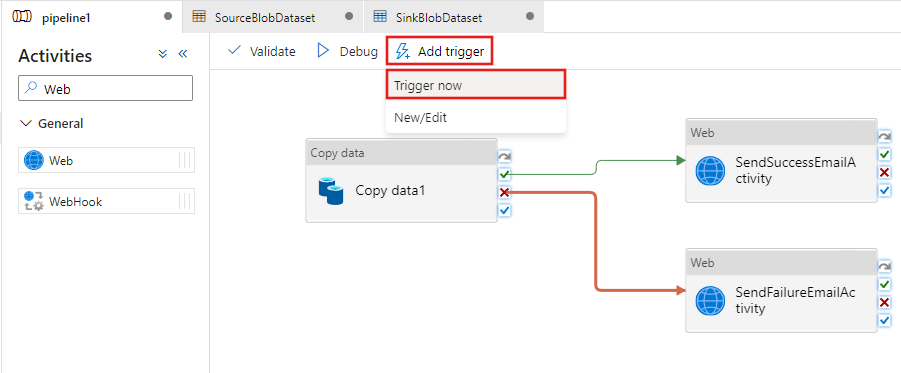
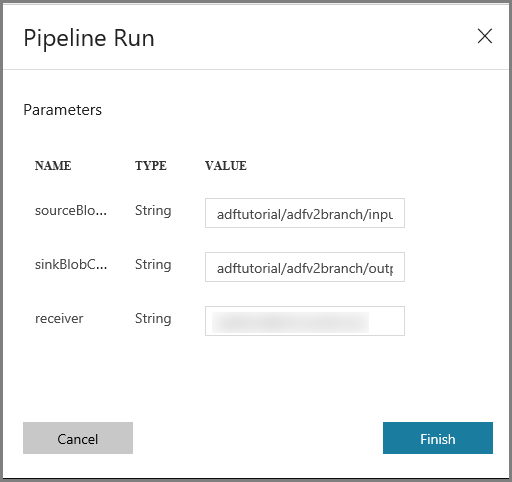
W oknie Przebieg potoku wykonaj następujące czynności:
Wprowadź wartość adftutorial/adfv2branch/input dla parametru sourceBlobContainer.
Wprowadź wartość adftutorial/adfv2branch/output dla parametru sinkBlobContainer.
Wprowadź adres e-mail odbiorcy receiver.
Kliknij przycisk Zakończ
Monitorowanie pomyślnego uruchomienia potoku
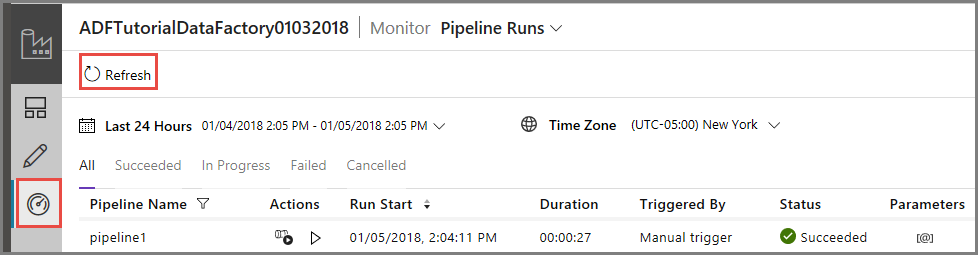
Aby monitorować działanie potoku, przejdź do karty Monitorowanie po lewej stronie. Zostanie wyświetlone uruchomienie potoku, które zostało wyzwolone ręcznie przez Ciebie. Kliknij przycisk Odśwież, aby odświeżyć listę.
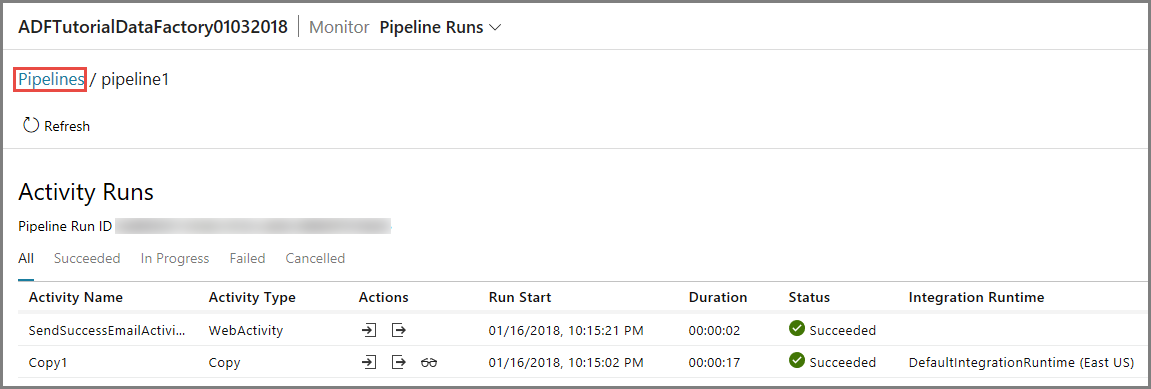
Aby wyświetlić uruchomienia działań skojarzone z tym uruchomieniem potoku, kliknij na pierwszy link w kolumnie Akcje. Do poprzedniego widoku można wrócić, klikając pozycję Potoki u góry. Kliknij przycisk Odśwież, aby odświeżyć listę.
Uruchom potok, który zakończy się niepowodzeniem
Przejdź do karty Edycja po lewej stronie.
Aby uruchomić potok, kliknij Uruchom na pasku narzędzi, a następnie kliknij Uruchom teraz.
W oknie Przebieg potoku wykonaj następujące czynności:
- Wprowadź adftutorial/dummy/input dla parametru sourceBlobContainer. Upewnij się, że folder „dummy” nie istnieje w kontenerze adftutorial.
- Wprowadź adftutorial/dummy/output jako parametr sinkBlobContainer.
- Wprowadź adres e-mail odbiorcy receiver.
- Kliknij przycisk Zakończ.
Monitoruj nieudane uruchomienie potoku
Aby monitorować działanie potoku, przejdź do karty Monitorowanie po lewej stronie. Zostanie wyświetlone uruchomienie potoku, które zostało wyzwolone ręcznie przez Ciebie. Kliknij przycisk Odśwież, aby odświeżyć listę.
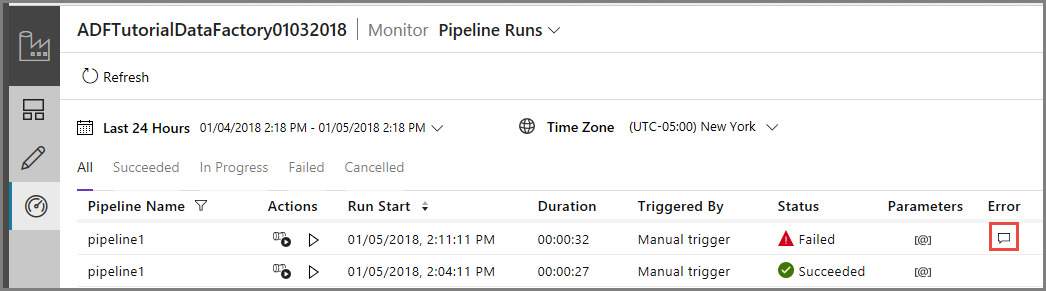
Kliknij link Błąd przebiegu potoku, aby wyświetlić szczegóły dotyczące błędu.

Aby wyświetlić uruchomienia działań skojarzone z tym uruchomieniem potoku, kliknij na pierwszy link w kolumnie Akcje. Kliknij przycisk Odśwież, aby odświeżyć listę. Zwróć uwagę, że działanie kopiowania w przepływie pracy nie powiodło się. Działanie internetowe powiodło się i do określonego odbiorcy została wysłana wiadomość o niepowodzeniu.
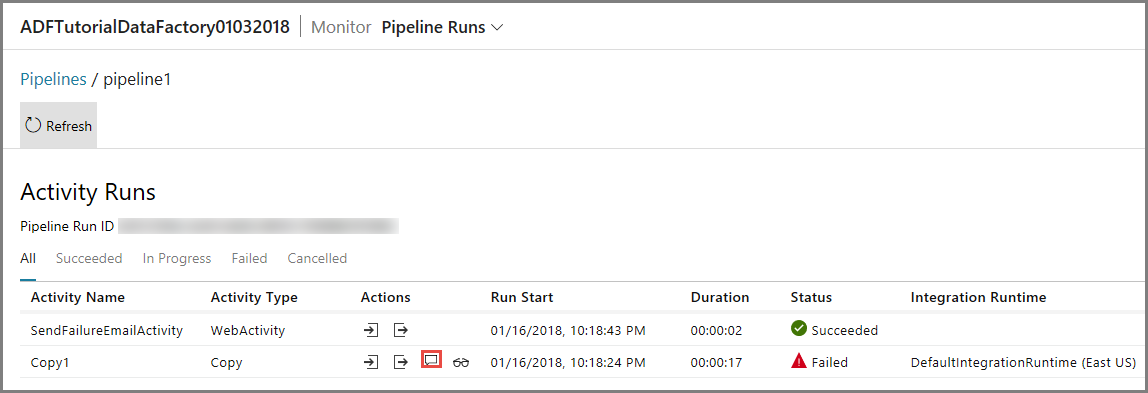
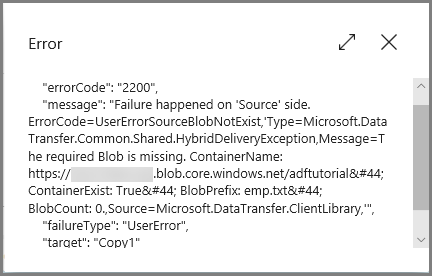
Kliknij link Błąd w kolumnie Akcje, aby wyświetlić szczegóły dotyczące błędu.
Powiązana zawartość
W ramach tego samouczka wykonano następujące procedury:
- Tworzenie fabryki danych.
- Utwórz połączoną usługę Azure Storage.
- Tworzenie zbioru danych Blob Azure
- Utwórz potok zawierający akcję kopiowania i akcję sieciową.
- Wysyłanie danych wyjściowych działań do kolejnych działań
- Korzystanie z przekazywania parametrów i ze zmiennych systemowych
- Rozpocznij uruchomienie potoku
- Monitoruj potok i uruchomienia działań
Teraz możesz przejść do sekcji Pojęcia, aby uzyskać więcej informacji na temat Azure Data Factory.