Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Uzdatnianie danych w fabryce danych umożliwia tworzenie interaktywnych kombinacji Power Query natywnie w usłudze ADF, a następnie uruchamianie ich na dużą skalę wewnątrz potoku ADF.
Tworzenie działania Power Query
Istnieją dwa sposoby tworzenia Power Query w Azure Data Factory. Jednym ze sposobów jest kliknięcie ikony znaku plus i wybranie Power Query w okienku zasobów fabrycznych.
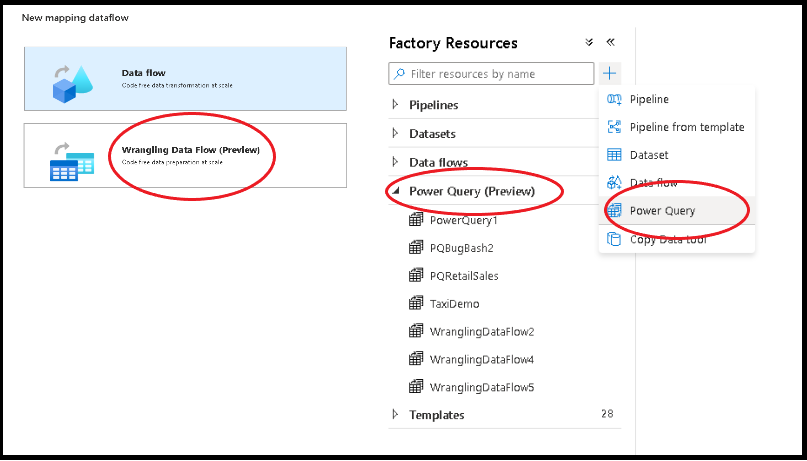
Druga metoda znajduje się w okienku działań kanwy potoku. Otwórz akordeon Power Query i przeciągnij działanie Power Query na kanwę.
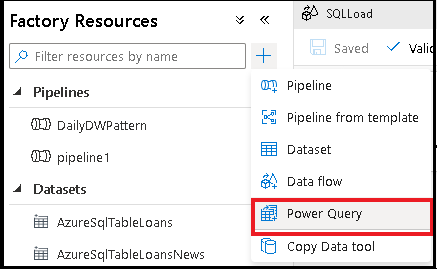
Tworzenie działania uzdatniania danych Power Query
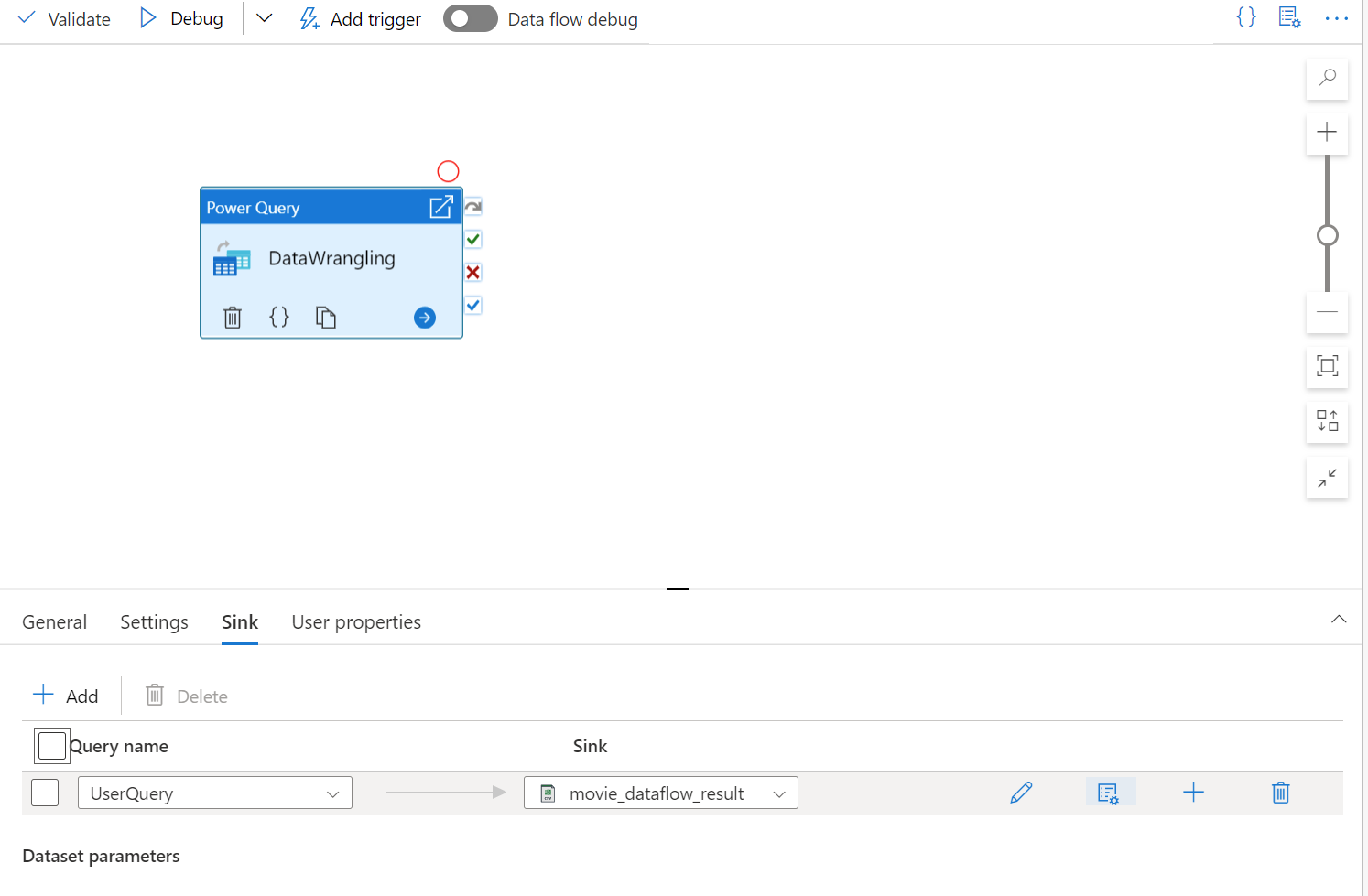
Dodaj zestaw danych Source dla kompilacji Power Query. Możesz wybrać istniejący zestaw danych lub utworzyć nowy. Po zapisaniu mash-upu możesz utworzyć potok, dodać działanie uzdatniania danych Power Query do potoku i wybrać zestaw danych ujścia, aby poinformować usługę ADF, gdzie mają wylądować dane. Chociaż można wybrać jeden lub więcej źródłowych zestawów danych, w tej chwili dozwolony jest tylko jeden odbiornik. Wybranie zestawu danych ujścia jest opcjonalne, ale wymagany jest co najmniej jeden źródłowy zestaw danych.
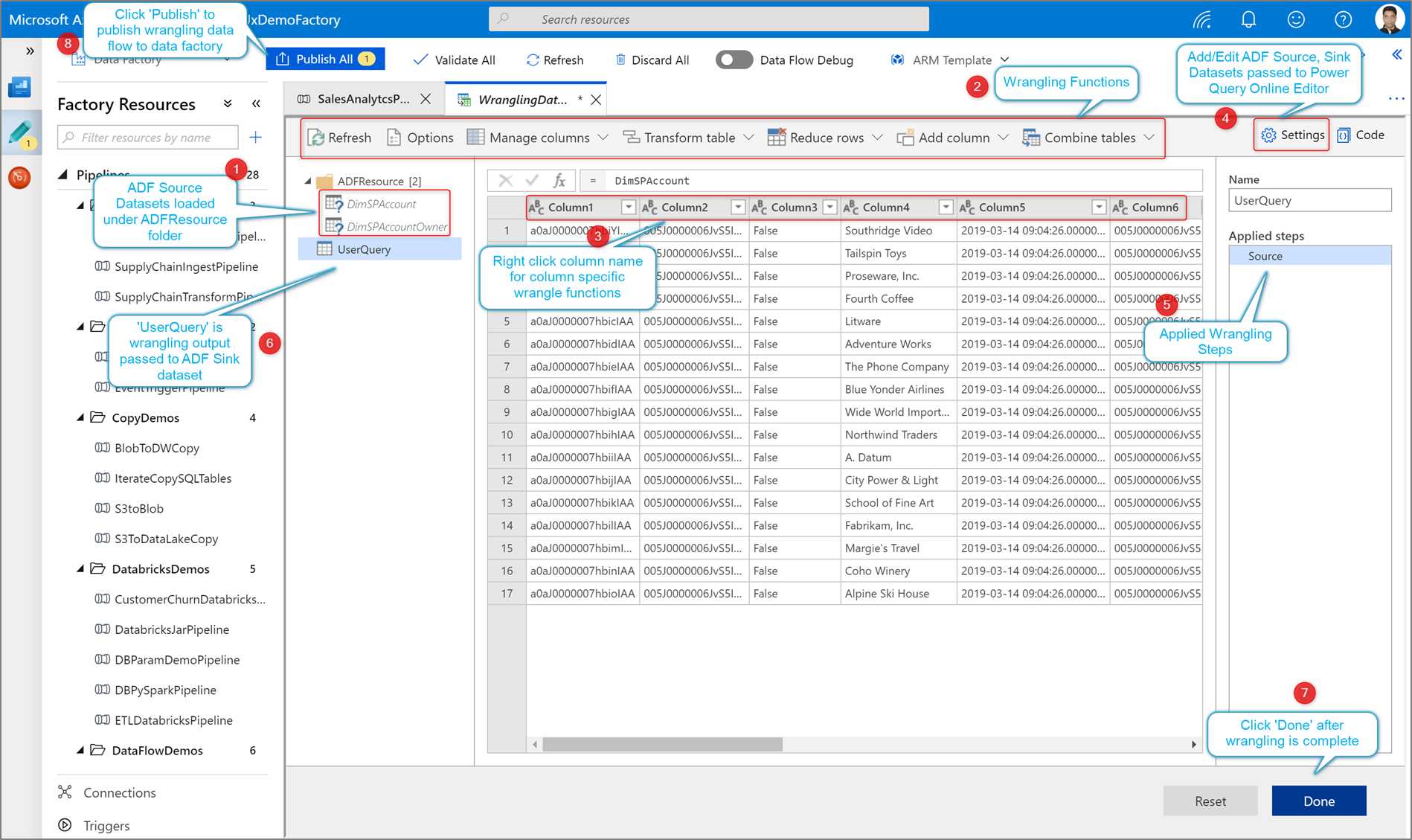
Kliknij pozycję Utwórz aby otworzyć edytor mashupów usługi Power Query Online.
Najpierw wybierz źródło zestawu danych dla edytora mashupów.
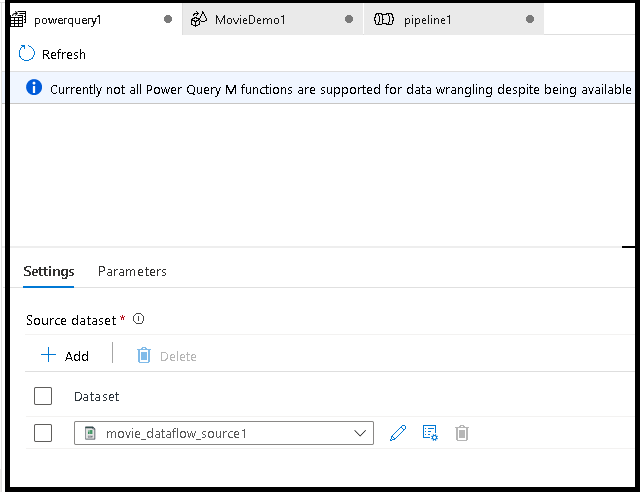
Po zakończeniu tworzenia Power Query możesz go zapisać, a następnie utworzyć potok. Musisz dodać mashup jako czynność do potoku danych. Dzieje się tak, gdy utworzysz/wybierzesz zestaw danych ujścia, aby wylądować dane. Możesz również ustawić właściwości docelowego zestawu danych, klikając drugi przycisk po prawej stronie docelowego zestawu danych. Pamiętaj, aby zmienić opcję partycji w obszarze "Optymalizacja" na "Pojedyncza partycja", jeśli chcesz uzyskać tylko jeden plik wyjściowy.
Twórz zapytania Power Query do przygotowywania danych bez użycia kodu. Aby uzyskać listę dostępnych funkcji, zobacz funkcje przekształcania. Usługa ADF tłumaczy skrypt języka M na skrypt przepływu danych, dzięki czemu można wykonać Power Query z dużą wydajnością, korzystając ze środowiska Spark przepływu danych Azure Data Factory.
Uruchamianie i monitorowanie działania uzdatniania danych Power Query
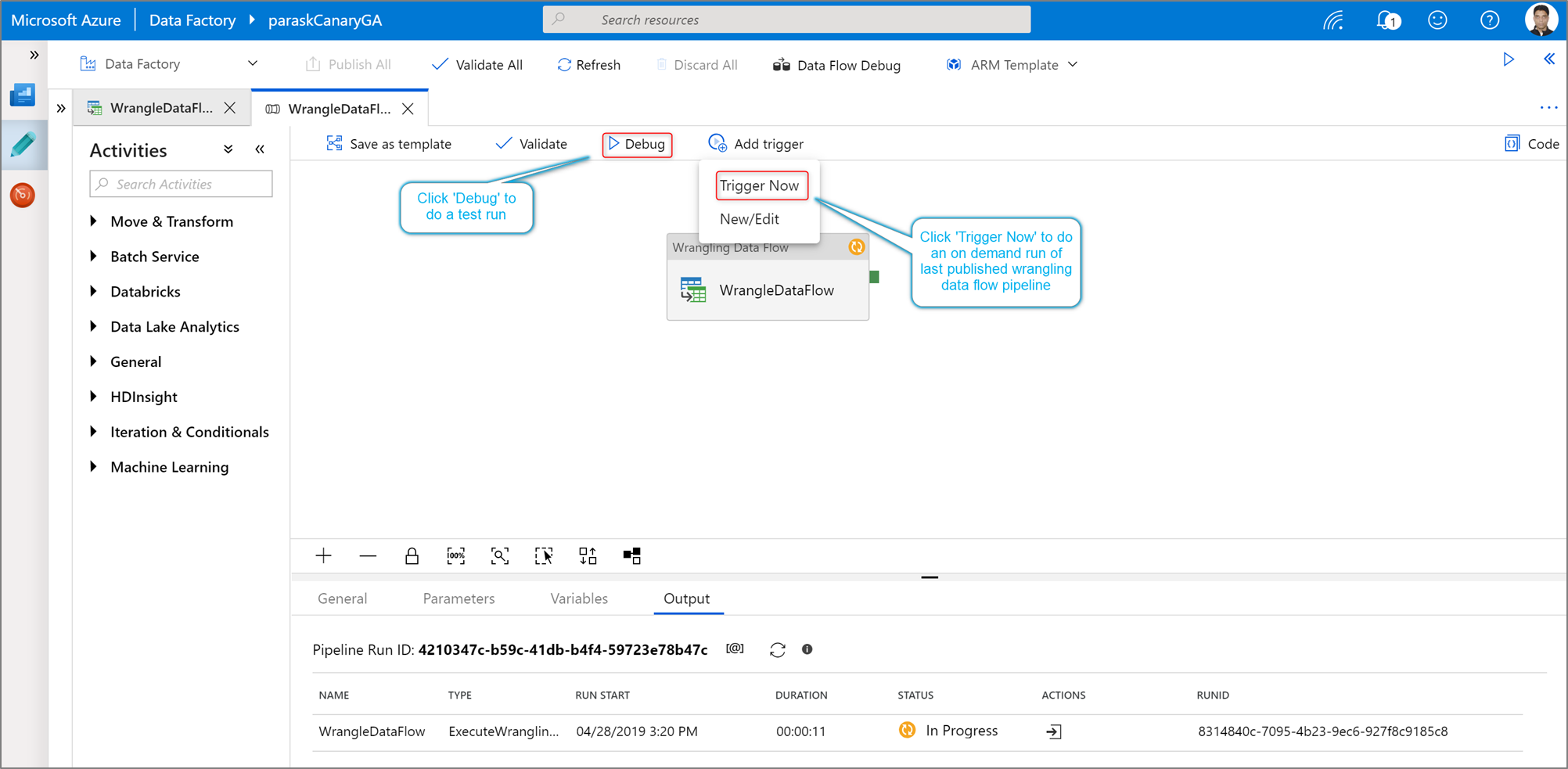
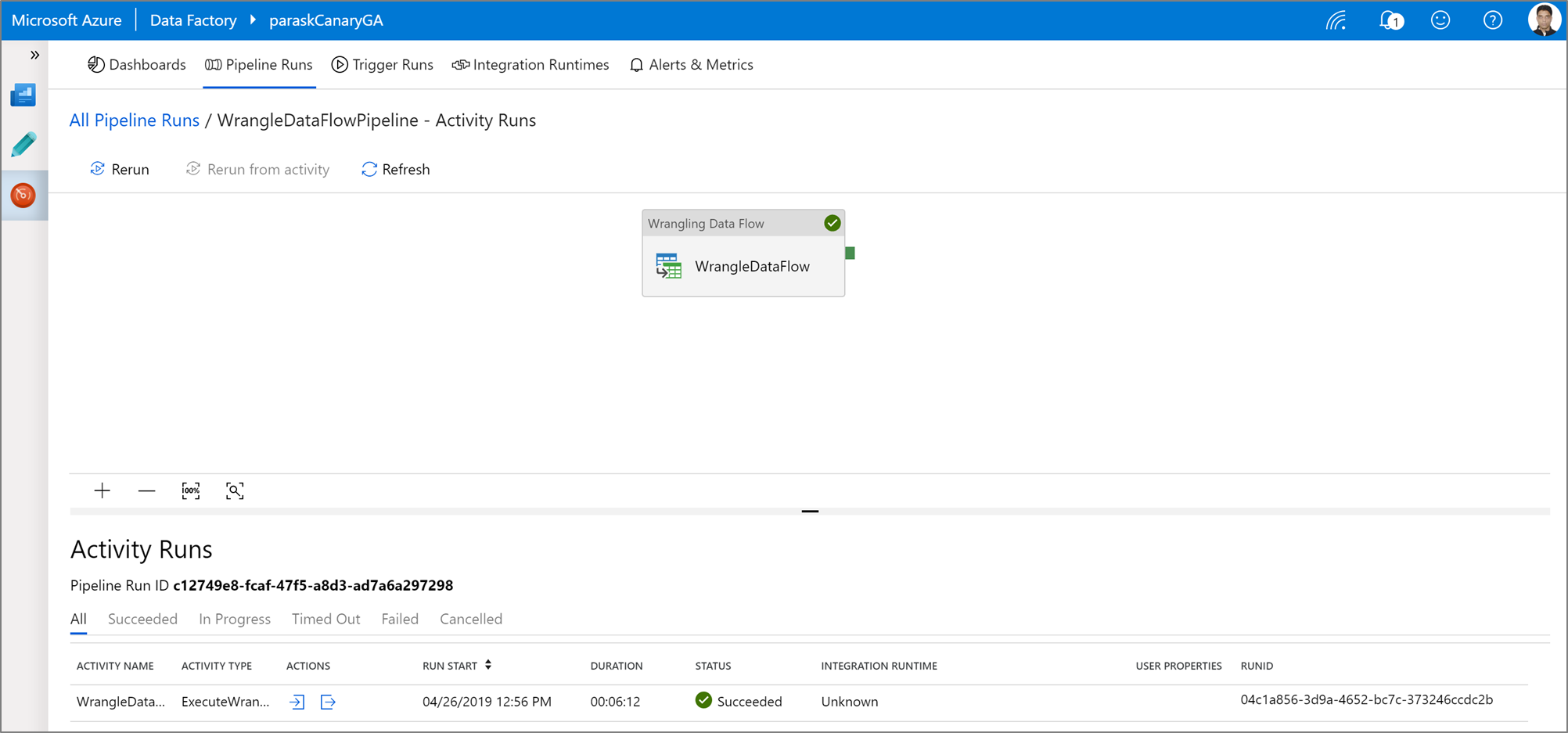
Aby wykonać uruchomienie debugowania potoku Power Query, kliknij Debug na kanwie potoku. Po opublikowaniu potoku, naciśnięcie opcji Uruchom teraz spowoduje wykonanie uruchomienia na żądanie ostatniego opublikowanego potoku. Potoki Power Query można zaplanować ze wszystkimi istniejącymi wyzwalaczami Azure Data Factory.
Przejdź do karty Monitor aby zwizualizować dane wyjściowe wyzwalanego działania Power Query.
Powiązana zawartość
Dowiedz się, jak utworzyć przepływ danych mapowania.