Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Ta funkcja jest dostępna w wersji beta. Administratorzy kont mogą kontrolować dostęp do tej funkcji ze strony Podglądy .
Dzięki integracji agenta kodowania usługi Azure Databricks możesz zarządzać dostępem i użyciem agentów kodowania, takich jak Cursor, Gemini CLI, Codex CLI i Claude Code. Zbudowany na AI Gateway, zapewnia ograniczanie szybkości, śledzenie użycia oraz tabele wnioskowania dla narzędzi do kodowania.
Funkcje
- Dostęp: bezpośredni dostęp do różnych narzędzi i modeli kodowania, a wszystko w ramach jednej faktury.
- Możliwość obserwowania: jeden ujednolicony pulpit nawigacyjny do śledzenia użycia, wydatków i metryk we wszystkich narzędziach do kodowania.
- Ujednolicone zarządzanie: Administratorzy mogą zarządzać uprawnieniami modelu i limitami danych bezpośrednio poprzez bramę sztucznej inteligencji.
Requirements
- Usługa AI Gateway (wersja beta) w wersji zapoznawczej jest włączona dla Twojego konta.
- Obszar roboczy usługi Azure Databricks w obsługiwanym regionie Bramy Sztucznej Inteligencji (beta).
- Katalog Unity włączony dla obszaru roboczego. Zobacz Umożliwienie obszaru roboczego dla Unity Catalog.
Obsługiwani agenci
Obsługiwane są następujące agenty kodowania:
Konfiguracja
Cursor
Aby skonfigurować Cursor do używania punktów końcowych AI Gateway:
Krok 1. Konfigurowanie podstawowego adresu URL i klucza interfejsu API
Otwórz kursor i przejdź do Ustawienia>Ustawienia kursora>Modele>Klucze API.
Włącz zastąpienie podstawowego adresu URL OpenAI i wprowadź adres URL:
https://<ai-gateway-url>/cursor/v1Zastąp
<ai-gateway-url>adresem URL punktu końcowego swojej bramy AI.Wklej osobisty token dostępu usługi Azure Databricks w polu Klucz interfejsu API OpenAI .
Krok 2. Dodawanie modeli niestandardowych
- Kliknij + Dodaj model niestandardowy w ustawieniach kursora.
- Dodaj nazwę punktu końcowego dla AI Gateway i aktywuj przełącznik.
Uwaga / Notatka
Obecnie obsługiwane są tylko punkty końcowe modelu podstawowego utworzone przez usługę Azure Databricks.
Krok 3. Testowanie integracji
- Otwórz tryb zapytania
Cmd+L(macOS) lubCtrl+L(Windows/Linux) i wybierz model. - Wyślij wiadomość. Wszystkie żądania są teraz kierowane przez usługę Azure Databricks.
Interfejs wiersza polecenia Codex
Krok 1. Ustawianie zmiennej środowiskowej DATABRICKS_TOKEN
export DATABRICKS_TOKEN=<databricks_pat_token>
Krok 2. Konfigurowanie klienta Codex
Utwórz lub edytuj plik konfiguracji Codex pod adresem ~/.codex/config.toml:
profile = "default"
[profiles.default]
model_provider = "proxy"
model = "databricks-gpt-5-2"
[model_providers.proxy]
name = "Databricks Proxy"
base_url = "https://<ai-gateway-url>/openai/v1"
env_key = "DATABRICKS_TOKEN"
wire_api = "responses"
Zastąp <ai-gateway-url> adresem URL punktu końcowego Twojej bramy AI.
Gemini CLI
Krok 1. Instalowanie najnowszej wersji interfejsu wiersza polecenia Gemini
npm install -g @google/gemini-cli@nightly
Krok 2. Konfigurowanie zmiennych środowiskowych
Utwórz plik ~/.gemini/.env i dodaj następującą konfigurację. Aby uzyskać więcej informacji, zobacz dokumentację uwierzytelniania interfejsu wiersza polecenia Gemini .
GEMINI_MODEL=databricks-gemini-2-5-flash
GOOGLE_GEMINI_BASE_URL=https://<ai-gateway-url>/gemini
GEMINI_API_KEY_AUTH_MECHANISM="bearer"
GEMINI_API_KEY=<databricks_pat_token>
Zastąp <ai-gateway-url> adresem URL punktu końcowego AI Gateway i <databricks_pat_token> swoim osobistym tokenem dostępu.
Claude Code
Krok 1. Konfigurowanie klienta programu Claude Code
Dodaj następującą konfigurację do ~/.claude/settings.json. Aby uzyskać więcej informacji, zobacz dokumentację ustawień kodu Claude'a .
{
"env": {
"ANTHROPIC_MODEL": "databricks-claude-opus-4-6",
"ANTHROPIC_BASE_URL": "https://<ai-gateway-url>/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<databricks_pat_token>",
"ANTHROPIC_CUSTOM_HEADERS": "x-databricks-use-coding-agent-mode: true",
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"
}
}
Zastąp <ai-gateway-url> adresem URL punktu końcowego AI Gateway i <databricks_pat_token> osobistym tokenem dostępu.
Krok 2 (opcjonalnie): Konfigurowanie kolekcji metryk OpenTelemetry
Zobacz Konfigurowanie zbierania danych OpenTelemetry, aby uzyskać szczegółowe informacje na temat eksportowania metryk i dzienników z Claude Code do zarządzanych przez Unity Catalog tabel Delta.
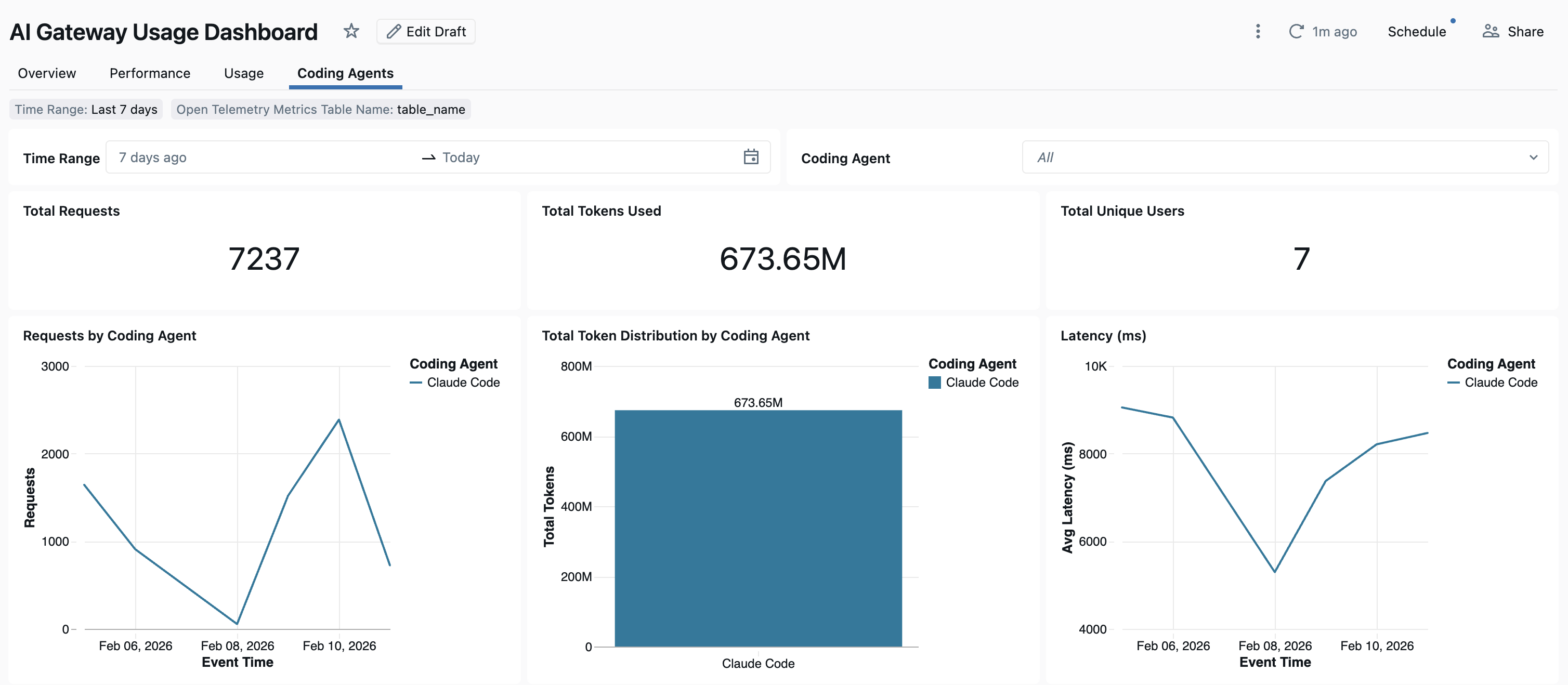
Dashboard
Po śledzeniu użycia agenta kodowania za pośrednictwem bramy sztucznej inteligencji możesz wyświetlać i monitorować metryki na wbudowanym pulpicie nawigacyjnym.
Aby uzyskać dostęp do pulpitu nawigacyjnego, wybierz pozycję Wyświetl pulpit nawigacyjny na stronie bramy sztucznej inteligencji. Spowoduje to utworzenie wstępnie skonfigurowanego pulpitu nawigacyjnego z wykresami dotyczącymi użycia narzędzi do kodowania.

Konfigurowanie zbierania danych OpenTelemetry
Usługa Azure Databricks obsługuje eksportowanie metryk i dzienników OpenTelemetry z Claude Code do zarządzanych tabel Delta w wykazie aparatu Unity. Wszystkie metryki to dane szeregów czasowych eksportowane przy użyciu standardowego protokołu metryk OpenTelemetry, a dzienniki są eksportowane przy użyciu protokołu dzienników OpenTelemetry. Aby uzyskać informacje o dostępnych metrykach i zdarzeniach, zobacz Claude Code monitoring usage (Użycie monitorowania kodu Claude'a).
Requirements
- Usługa OpenTelemetry w wersji zapoznawczej usługi Azure Databricks jest włączona. Zobacz Zarządzanie wersjami zapoznawczami usługi Azure Databricks.
Krok 1: Tworzenie tabel OpenTelemetry w Unity Catalog
Utwórz prekonfigurowane tabele zarządzane Unity Catalog za pomocą schematów metryk i dzienników OpenTelemetry.
Tabela metryk
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_metrics (
name STRING,
description STRING,
unit STRING,
metric_type STRING,
gauge STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
sum STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
aggregation_temporality: STRING,
is_monotonic: BOOLEAN
>,
histogram STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
bucket_counts: ARRAY<LONG>,
explicit_bounds: ARRAY<DOUBLE>,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
min: DOUBLE,
max: DOUBLE,
aggregation_temporality: STRING
>,
exponential_histogram STRUCT<
attributes: MAP<STRING, STRING>,
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
scale: INT,
zero_count: LONG,
positive_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
negative_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
flags: INT,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
min: DOUBLE,
max: DOUBLE,
zero_threshold: DOUBLE,
aggregation_temporality: STRING
>,
summary STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
quantile_values: ARRAY<STRUCT<
quantile: DOUBLE,
value: DOUBLE
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
metadata MAP<STRING, STRING>,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
metric_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
Tabela dzienników
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_logs (
event_name STRING,
trace_id STRING,
span_id STRING,
time_unix_nano LONG,
observed_time_unix_nano LONG,
severity_number STRING,
severity_text STRING,
body STRING,
attributes MAP<STRING, STRING>,
dropped_attributes_count INT,
flags INT,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
log_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
Krok 2. Aktualizowanie pliku ustawień kodu Claude'a
Dodaj następujące zmienne środowiskowe do bloku env w pliku ~/.claude/settings.json, aby włączyć eksportowanie metryk i dzienników.
{
"env": {
"CLAUDE_CODE_ENABLE_TELEMETRY": "1",
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_METRICS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_METRICS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/metrics",
"OTEL_EXPORTER_OTLP_METRICS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_metrics",
"OTEL_METRIC_EXPORT_INTERVAL": "10000",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_LOGS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_LOGS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/logs",
"OTEL_EXPORTER_OTLP_LOGS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_logs",
"OTEL_LOGS_EXPORT_INTERVAL": "5000"
}
}
Zastąp następujące elementy:
-
<workspace-url>przy użyciu adresu URL obszaru roboczego usługi Azure Databricks. -
<databricks_pat_token>przy użyciu osobistego tokenu dostępu. -
<catalog>.<schema>.<table_prefix>z prefiksem wykazu, schematu i tabeli używanym podczas tworzenia tabel OpenTelemetry.
Uwaga / Notatka
Wartość domyślna OTEL_METRIC_EXPORT_INTERVAL to 60000 ms (60 sekund). Powyższy przykład ustawia wartość 10000 ms (10 sekund). Wartość domyślna OTEL_LOGS_EXPORT_INTERVAL to 5000 ms (5 sekund).
Krok 3. Uruchamianie kodu Claude'a
claude
Dane powinny trafić do tabel katalogu Unity w ciągu 5 minut.