Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Ta funkcja jest dostępna w wersji beta. Administratorzy kont mogą kontrolować dostęp do tej funkcji ze strony podglądów konsoli konta. Zobacz Zarządzanie podglądami Azure Databricks.
Na tej stronie opisano sposób monitorowania użycia punktów końcowych bramy AI Unity przy użyciu tabeli systemu śledzenia użycia.
Tabela śledzenia użycia automatycznie przechwytuje szczegóły żądania i odpowiedzi dla punktu końcowego, rejestruje podstawowe metryki, takie jak użycie tokenu i opóźnienie. Dane w tej tabeli umożliwiają monitorowanie użycia, śledzenie kosztów i uzyskiwanie szczegółowych informacji na temat wydajności i zużycia punktów końcowych.
Requirements
- Usługa Unity AI Gateway w wersji zapoznawczej jest włączona dla twojego konta. Zobacz Zarządzanie podglądami Azure Databricks.
- Obszar roboczy Azure Databricks w regionie obsługiwanym przez Unity AI Gateway.
- Unity Catalog jest włączony dla obszaru roboczego. Zobacz Umożliwienie obszaru roboczego dla Unity Catalog.
Zapytanie do tabeli użycia
Usługa Unity AI Gateway rejestruje dane użycia w tabeli systemowej system.ai_gateway.usage . Tabelę można wyświetlić w interfejsie użytkownika lub wykonać zapytanie za pomocą Databricks SQL albo notebooka.
Uwaga / Notatka
Tylko administratorzy kont mają uprawnienia do wyświetlania lub wykonywania zapytań dotyczących system.ai_gateway.usage tabeli.
Aby wyświetlić tabelę w interfejsie użytkownika, kliknij link tabeli monitorowania użycia na stronie punktu końcowego, aby otworzyć tabelę w Eksploratorze Katalogu.
Aby wysłać zapytanie do tabeli z bazy danych Databricks SQL lub notesu:
SELECT * FROM system.ai_gateway.usage;
Wbudowany dashboard dla użycia
Importowanie wbudowanego pulpitu nawigacyjnego użycia
Administratorzy konta mogą importować wbudowany pulpit nawigacyjny użycia bramy AI Unity, klikając pozycję Utwórz pulpit nawigacyjny na stronie bramy sztucznej inteligencji, aby monitorować użycie, śledzić koszty i uzyskiwać wgląd w wydajność i zużycie punktów końcowych. Pulpit nawigacyjny jest publikowany z uprawnieniami administratora konta, co umożliwia osobom przeglądającym uruchamianie zapytań przy użyciu uprawnień wydawcy. Aby uzyskać więcej informacji, zobacz Opublikuj pulpit nawigacyjny. Administratorzy konta mogą również zaktualizować magazyn używany do uruchamiania zapytań pulpitu nawigacyjnego, które mają zastosowanie do wszystkich kolejnych zapytań.

Uwaga / Notatka
Importowanie panelu sterowania jest ograniczone do administratorów kont, ponieważ wymaga uprawnień SELECT dla tabeli system.ai_gateway.usage. Dane pulpitu nawigacyjnego usage podlegają zasadom przechowywania tabeli. Zobacz Które tabele systemowe są dostępne?.
Aby ponownie załadować pulpit nawigacyjny z najnowszego szablonu, administratorzy kont mogą kliknąć pozycję Ponownie zaimportuj pulpit nawigacyjny na stronie bramy AI. Spowoduje to zaktualizowanie pulpitu nawigacyjnego przy użyciu nowych wizualizacji lub ulepszeń szablonu przy jednoczesnym zachowaniu konfiguracji magazynu.
Zobacz panel użycia
Aby wyświetlić pulpit nawigacyjny, kliknij pozycję Wyświetl pulpit nawigacyjny na stronie bramy sztucznej inteligencji. Wbudowany pulpit nawigacyjny zapewnia kompleksowy wgląd w wykorzystanie i wydajność końcówek Unity AI Gateway. Obejmuje ona wiele stron śledzących żądania, użycie tokenu, metryki opóźnień, współczynniki błędów i działanie agenta kodowania.

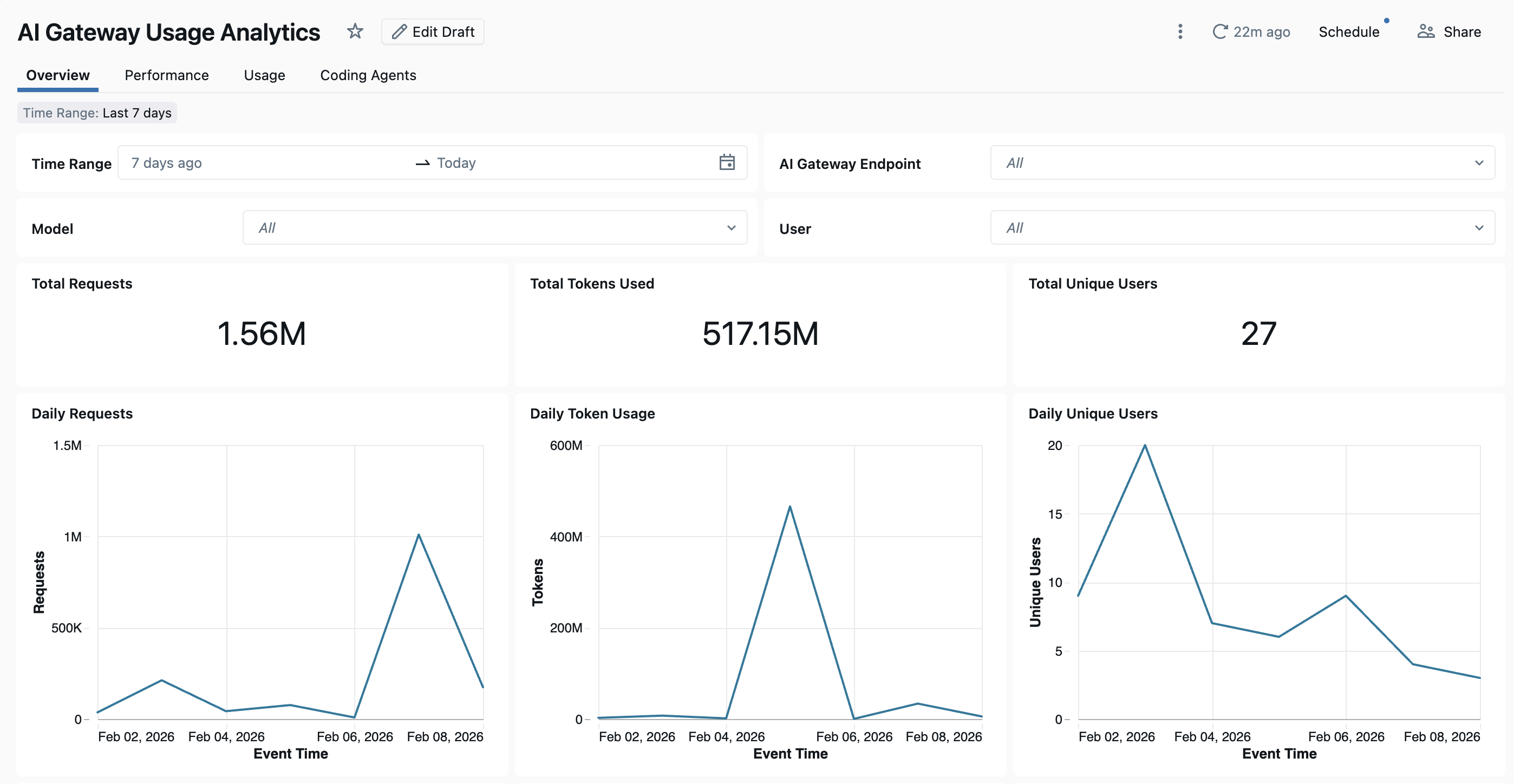
Pulpit nawigacyjny domyślnie udostępnia analizę między obszarami roboczymi. Wszystkie strony pulpitu nawigacyjnego można filtrować według zakresu dat i identyfikatora obszaru roboczego.
- Karta Przegląd: pokazuje ogólne metryki użycia, w tym dzienny wolumen żądań, trendy użycia tokenów w czasie, najlepsi użytkownicy według zużycia tokenów oraz łączną liczbę unikatowych użytkowników. Użyj tej karty, aby uzyskać szybką migawkę ogólnej aktywności usługi Unity AI Gateway i zidentyfikować najbardziej aktywnych użytkowników i modeli.
- Karta Wydajność: śledzi kluczowe metryki wydajności, w tym percentyle opóźnienia (P50, P90, P95, P99), czas pierwszego bajtu, współczynniki błędów i dystrybucje kodu stanu HTTP. Użyj tej karty do monitorowania kondycji punktu końcowego i identyfikowania wąskich gardeł wydajności lub problemów z niezawodnością.
- Karta Użycie: przedstawia szczegółowe podziały użycia według punktu końcowego, obszaru roboczego i obiektu żądającego. Na tej karcie przedstawiono wzorce użycia tokenów, dystrybucje żądań i współczynniki trafień pamięci podręcznej, aby ułatwić analizowanie i optymalizowanie kosztów.
- Karta agentów kodowania: śledzi aktywność zintegrowanych agentów kodowania, w tym Cursor, Claude Code, interfejs wiersza polecenia (CLI) Gemini i CLI Codex. Na tej karcie są wyświetlane metryki, takie jak dni aktywne, sesje kodowania, zatwierdzenia i wiersze kodu dodane lub usunięte w celu monitorowania użycia narzędzi deweloperskich. Aby uzyskać więcej informacji, zobacz Pulpit nawigacyjny agenta kodowania .
Schemat tabeli użycia
Tabela system.ai_gateway.usage ma następujący schemat:
| Nazwa kolumny | Typ | Opis | Example |
|---|---|---|---|
account_id |
STRING | Identyfikator konta. | 11d77e21-5e05-4196-af72-423257f74974 |
workspace_id |
STRING | Identyfikator przestrzeni roboczej. | 1653573648247579 |
request_id |
STRING | Unikatowy identyfikator żądania. | b4a47a30-0e18-4ae3-9a7f-29bcb07e0f00 |
schema_version |
INTEGER | Wersja schematu rekordu użycia. | 1 |
endpoint_id |
STRING | Unikatowy identyfikator punktu końcowego bramy AI Unity. | 43addf89-d802-3ca2-bd54-fe4d2a60d58a |
endpoint_name |
STRING | Nazwa punktu końcowego bramy Unity AI Gateway. | databricks-gpt-5-2 |
endpoint_tags |
MAP | Tagi skojarzone z punktem końcowym. | {"team": "engineering"} |
endpoint_metadata |
STRUCT | Metadane punktu końcowego, w tym creator, creation_time, last_updated_time, destinations, inference_table i fallbacks. |
{"creator": "user.name@email.com", "creation_time": "2026-01-06T12:00:00.000Z", ...} |
event_time |
TIMESTAMP | Sygnatura czasowa odebrania żądania. | 2026-01-20T19:48:08.000+00:00 |
latency_ms |
LONG | Łączne opóźnienie w milisekundach. | 300 |
time_to_first_byte_ms |
LONG | Czas do pierwszego bajtu w milisekundach. | 300 |
destination_type |
STRING | Typ miejsca docelowego (na przykład model zewnętrzny lub model podstawowy). | PAY_PER_TOKEN_FOUNDATION_MODEL |
destination_name |
STRING | Nazwa modelu docelowego lub dostawcy. | databricks-gpt-5-2 |
destination_id |
STRING | Unikatowy identyfikator miejsca docelowego. | 507e7456151b3cc89e05ff48161efb87 |
destination_model |
STRING | Określony model używany w ramach żądania. | GPT-5.2 |
requester |
STRING | Identyfikator użytkownika lub jednostki usługi, która złożyła żądanie. | user.name@email.com |
requester_type |
STRING | Typ obiektu żądającego (użytkownik, jednostka usługi lub grupa użytkowników). | USER |
ip_address |
STRING | Adres IP obiektu żądającego. | 1.2.3.4 |
url |
STRING | Adres URL żądania. | https://<ai-gateway-url>/mlflow/v1/chat/completions |
user_agent |
STRING | Agent użytkownika żądającego. | OpenAI/Python 2.13.0 |
api_type |
STRING | Typ wywołania interfejsu API (na przykład czat, ukończenie lub osadzanie). | mlflow/v1/chat/completions |
request_tags |
MAP | Tagi skojarzone z żądaniem. | {"team": "engineering"} |
input_tokens |
LONG | Liczba tokenów wejściowych. | 100 |
output_tokens |
LONG | Liczba tokenów wyjściowych. | 100 |
total_tokens |
LONG | Całkowita liczba tokenów (dane wejściowe i wyjściowe). | 200 |
token_details |
STRUCT | Szczegółowy podział tokenów, w tym cache_read_input_tokens, cache_creation_input_tokensi output_reasoning_tokens. |
{"cache_read_input_tokens": 100, ...} |
response_content_type |
STRING | Typ zawartości odpowiedzi. | application/json |
status_code |
INT | Kod statusu HTTP odpowiedzi. | 200 |
routing_information |
STRUCT | Szczegóły routingu dla prób powrotu . Zawiera tablicę z elementami attempts, priority, action, destination, destination_id, status_code, error_code, latency_ms, start_time i end_time dla każdego modelu wypróbowanego podczas żądania. |
{"attempts": [{"priority": "1", ...}]} |