Konfigurowanie ustawień potoku dla narzędzia Delta Live Tables
Ten artykuł zawiera szczegółowe informacje na temat konfigurowania ustawień potoku dla tabel delta Live Tables. Usługa Delta Live Tables ma interfejs użytkownika do konfigurowania i edytowania ustawień potoku. Interfejs użytkownika ma również możliwość wyświetlania i edytowania ustawień w formacie JSON.
Uwaga
Większość ustawień można skonfigurować przy użyciu interfejsu użytkownika lub specyfikacji JSON. Niektóre opcje zaawansowane są dostępne tylko przy użyciu konfiguracji JSON.
Usługa Databricks zaleca zapoznanie się z ustawieniami funkcji Delta Live Tables przy użyciu interfejsu użytkownika. W razie potrzeby możesz bezpośrednio edytować konfigurację JSON w obszarze roboczym. Pliki konfiguracji JSON są również przydatne podczas wdrażania potoków w nowych środowiskach lub przy użyciu interfejsu wiersza polecenia lub interfejsu API REST.
Aby uzyskać pełne odwołanie do ustawień konfiguracji JSON tabel delta live tables, zobacz Delta Live Tables pipeline configurations (Konfiguracje potoków tabel delta live tables).
Uwaga
- Ponieważ zasoby obliczeniowe są w pełni zarządzane dla bezserwerowych potoków DLT (publiczna wersja zapoznawcza), ustawienia obliczeniowe, takie jak rozszerzone skalowanie automatyczne, zasady klastra, typy wystąpień i tagi klastra są niedostępne w interfejsie użytkownika tabel delta Live Tables po wybraniu opcji Bezserwerowe dla potoku.
- Nie można ręcznie dodać ustawień obliczeniowych w
clustersobiekcie w konfiguracji JSON dla potoku i próba wykonania tej czynności powoduje wystąpienie błędu.
Aby dowiedzieć się więcej na temat włączania bezserwerowych potoków DLT, skontaktuj się z zespołem konta usługi Azure Databricks.
Wybieranie wersji produktu
Wybierz wersję produktu Delta Live Tables z najlepszymi funkcjami dla wymagań potoku. Dostępne są następujące wersje produktów:
Coredo uruchamiania obciążeń pozyskiwania strumieniowego.CoreWybierz wersję, jeśli potok nie wymaga zaawansowanych funkcji, takich jak przechwytywanie danych zmian (CDC) lub oczekiwania dotyczące tabel delta Live Tables.Prodo uruchamiania pozyskiwania strumieniowego i obciążeń CDC. WersjaProproduktu obsługuje wszystkieCorefunkcje oraz obsługę obciążeń wymagających aktualizacji tabel na podstawie zmian w danych źródłowych.Advanceddo uruchamiania obciążeń pozyskiwania przesyłania strumieniowego, obciążeń CDC i obciążeń, które wymagają oczekiwań. WersjaAdvancedproduktu obsługuje funkcjeCoreiProedycji, a także obsługuje wymuszanie ograniczeń jakości danych z oczekiwaniami funkcji Delta Live Tables.
Edycję produktu można wybrać podczas tworzenia lub edytowania potoku. Dla każdego potoku można wybrać inną wersję. Zobacz stronę produktu Delta Live Tables.
Uwaga: Jeśli potok zawiera funkcje nieobsługiwane przez wybraną wersję produktu, na przykład oczekiwania, zostanie wyświetlony komunikat o błędzie wyjaśniający przyczynę błędu. Następnie możesz edytować potok, aby wybrać odpowiednią wersję.
Wybieranie trybu potoku
Potok można aktualizować w sposób ciągły lub za pomocą wyzwalaczy ręcznych na podstawie trybu potoku. Zobacz Ciągłe i wyzwalane wykonywanie potoku.
Wybieranie zasad klastra
Użytkownicy muszą mieć uprawnienia do wdrażania zasobów obliczeniowych w celu skonfigurowania i zaktualizowania potoków tabel na żywo delty. Administratorzy obszaru roboczego mogą skonfigurować zasady klastra, aby zapewnić użytkownikom dostęp do zasobów obliczeniowych dla tabel delta Live Tables. Zobacz Define limits on Delta Live Tables pipeline compute (Definiowanie limitów dla obliczeń potoku delta live tables).
Uwaga
Zasady klastra są opcjonalne. Sprawdź się z administratorem obszaru roboczego, jeśli nie masz uprawnień obliczeniowych wymaganych dla tabel delta Live Tables.
Aby upewnić się, że wartości domyślne zasad klastra są poprawnie stosowane, ustaw
apply_policy_default_valueswartość natruew konfiguracjach klastra w konfiguracji potoku:{ "clusters": [ { "label": "default", "policy_id": "<policy-id>", "apply_policy_default_values": true } ] }
Konfigurowanie bibliotek kodu źródłowego
Selektora plików można użyć w interfejsie użytkownika tabel delta Live Tables, aby skonfigurować kod źródłowy definiujący potok. Kod źródłowy potoku jest zdefiniowany w notesach usługi Databricks lub skryptach SQL lub Python przechowywanych w plikach obszaru roboczego. Podczas tworzenia lub edytowania potoku można dodać jeden lub więcej notesów lub plików obszaru roboczego albo kombinację notesów i plików obszaru roboczego.
Ponieważ tabele na żywo funkcji Delta automatycznie analizują zależności zestawu danych w celu skonstruowania grafu przetwarzania dla potoku, możesz dodać biblioteki kodu źródłowego w dowolnej kolejności.
Można również zmodyfikować plik JSON tak, aby zawierał kod źródłowy funkcji Delta Live Tables zdefiniowany w skryptach SQL i Python przechowywanych w plikach obszaru roboczego. Poniższy przykład obejmuje notesy i pliki obszaru roboczego:
{
"name": "Example pipeline 3",
"storage": "dbfs:/pipeline-examples/storage-location/example3",
"libraries": [
{ "notebook": { "path": "/example-notebook_1" } },
{ "notebook": { "path": "/example-notebook_2" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.sql" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.py" } }
]
}
Określanie lokalizacji przechowywania
Możesz określić lokalizację magazynu dla potoku, który publikuje w magazynie metadanych Hive. Główną motywacją do określenia lokalizacji jest kontrolowanie lokalizacji przechowywania obiektów dla danych zapisywanych przez potok.
Ponieważ wszystkie tabele, dane, punkty kontrolne i metadane potoków tabel delta Live Tables są w pełni zarządzane przez tabele Delta Live Tables, większość interakcji z zestawami danych delta Live Tables odbywa się za pośrednictwem tabel zarejestrowanych w magazynie metadanych Hive lub wykazie aparatu Unity.
Określanie schematu docelowego dla tabel wyjściowych potoku
Opcjonalnie należy określić element docelowy do publikowania tabel utworzonych przez potok w dowolnym momencie, gdy przejdziesz poza programowanie i testowanie dla nowego potoku. Publikowanie potoku w miejscu docelowym powoduje, że zestawy danych są dostępne do wykonywania zapytań w innym miejscu w środowisku usługi Azure Databricks. Zobacz Publikowanie danych z tabel delta Live Tables do magazynu metadanych Hive lub Używanie wykazu aparatu Unity z potokami tabel delta Live Tables.
Konfigurowanie ustawień obliczeniowych
Uwaga
Ponieważ zasoby obliczeniowe są w pełni zarządzane dla bezserwerowych potoków DLT (publiczna wersja zapoznawcza), ustawienia obliczeniowe są niedostępne po wybraniu opcji Bezserwerowe dla potoku.
Każdy potok delta live tables ma dwa skojarzone klastry:
- Klaster
updatesprzetwarza aktualizacje potoku. - Klaster
maintenanceuruchamia codzienne zadania konserwacji.
Konfiguracja używana przez te klastry jest określana przez clusters atrybut określony w ustawieniach potoku.
Ustawienia obliczeniowe, które mają zastosowanie tylko do określonego typu klastra, można dodać przy użyciu etykiet klastra. Istnieją trzy etykiety, których można użyć podczas konfigurowania klastrów potoków:
Uwaga
Ustawienie etykiety klastra można pominąć, jeśli definiujesz tylko jedną konfigurację klastra. Etykieta default jest stosowana do konfiguracji klastra, jeśli nie podano ustawienia etykiety. Ustawienie etykiety klastra jest wymagane tylko wtedy, gdy trzeba dostosować ustawienia dla różnych typów klastrów.
- Etykieta
defaultdefiniuje ustawienia obliczeniowe, które mają być stosowane zarówno do klastrów, jakupdatesimaintenance. Zastosowanie tych samych ustawień do obu klastrów zwiększa niezawodność przebiegów konserwacji, zapewniając, że wymagane konfiguracje, takie jak poświadczenia dostępu do danych dla lokalizacji magazynu, są stosowane do klastra konserwacji. - Etykieta
maintenancedefiniuje ustawienia obliczeniowe, które mają zastosowanie tylko do klastramaintenance. Możesz również użyćmaintenanceetykiety, aby zastąpić ustawienia skonfigurowane przez etykietędefault. - Etykieta
updatesdefiniuje ustawienia, które mają zastosowanie tylko do klastraupdates.updatesUżyj etykiety, aby skonfigurować ustawienia, które nie powinny być stosowane do klastramaintenance.
Ustawienia zdefiniowane przy użyciu default etykiet i updates są scalane w celu utworzenia ostatecznej konfiguracji klastra updates . Jeśli to samo ustawienie jest definiowane przy użyciu default etykiet i , updates ustawienie zdefiniowane za updates pomocą etykiety zastępuje ustawienie zdefiniowane za default pomocą etykiety.
W poniższym przykładzie zdefiniowano parametr konfiguracji platformy Spark, który jest dodawany tylko do konfiguracji klastra updates :
{
"clusters": [
{
"label": "default",
"autoscale": {
"min_workers": 1,
"max_workers": 5,
"mode": "ENHANCED"
}
},
{
"label": "updates",
"spark_conf": {
"key": "value"
}
}
]
}
Funkcja Delta Live Tables ma podobne opcje dla ustawień klastra jako inne zasoby obliczeniowe w usłudze Azure Databricks. Podobnie jak w przypadku innych ustawień potoku, można zmodyfikować konfigurację JSON dla klastrów, aby określić opcje, które nie są obecne w interfejsie użytkownika. Zobacz Obliczenia.
Uwaga
- Ponieważ środowisko uruchomieniowe delta Live Tables zarządza cyklem życia klastrów potoków i uruchamia niestandardową wersję środowiska Databricks Runtime, nie można ręcznie ustawić niektórych ustawień klastra w konfiguracji potoku, takiej jak wersja platformy Spark lub nazwy klastra. Zobacz Atrybuty klastra, które nie są konfigurowalne przez użytkownika.
- Potoki delty tabel na żywo można skonfigurować do korzystania z aplikacji Photon. Zobacz Co to jest Photon?.
Wybieranie typów wystąpień do uruchomienia potoku
Domyślnie tabele delta live wybierają typy wystąpień dla węzłów sterowników i procesów roboczych, które uruchamiają potok, ale można również ręcznie skonfigurować typy wystąpień. Na przykład możesz wybrać typy wystąpień, aby poprawić wydajność potoku lub rozwiązać problemy z pamięcią podczas uruchamiania potoku. Typy wystąpień można skonfigurować podczas tworzenia lub edytowania potoku przy użyciu interfejsu API REST lub w interfejsie użytkownika delty tabel na żywo.
Aby skonfigurować typy wystąpień podczas tworzenia lub edytowania potoku w interfejsie użytkownika tabel delta Live Tables:
- Kliknij przycisk Ustawienia.
- W sekcji Zaawansowane ustawień potoku w menu rozwijanym Typ procesu roboczego i Typ sterownika wybierz typy wystąpień potoku.
Aby skonfigurować typy wystąpień w ustawieniach JSON potoku, kliknij przycisk JSON i wprowadź konfiguracje typu wystąpienia w konfiguracji klastra:
Uwaga
Aby uniknąć przypisywania niepotrzebnych zasobów do maintenance klastra, w tym przykładzie updates użyto etykiety do ustawienia typów wystąpień tylko dla klastra updates . Aby przypisać typy wystąpień do obu updates klasterów maintenance , użyj default etykiety lub pomiń ustawienie etykiety. Etykieta default jest stosowana do konfiguracji klastra potoku, jeśli nie podano żadnego ustawienia etykiety. Zobacz Konfigurowanie ustawień obliczeniowych.
{
"clusters": [
{
"label": "updates",
"node_type_id": "Standard_D12_v2",
"driver_node_type_id": "Standard_D3_v2",
"..." : "..."
}
]
}
Używanie skalowania automatycznego w celu zwiększenia wydajności i zmniejszenia użycia zasobów
Użyj rozszerzonego skalowania automatycznego, aby zoptymalizować wykorzystanie klastra potoków. Rozszerzone skalowanie automatyczne dodaje dodatkowe zasoby tylko wtedy, gdy system określi te zasoby, zwiększy szybkość przetwarzania potoku. Zasoby są zwalniane, gdy nie są już potrzebne, a klastry są zamykane natychmiast po zakończeniu wszystkich aktualizacji potoku.
Aby dowiedzieć się więcej na temat rozszerzonego skalowania automatycznego, w tym szczegółów konfiguracji, zobacz Optymalizowanie wykorzystania klastra potoków tabel na żywo różnicowych przy użyciu rozszerzonego skalowania automatycznego.
Opóźnianie zamykania zasobów obliczeniowych
Ponieważ klaster Delta Live Tables automatycznie zamyka się, gdy nie jest używany, odwoływanie się do zasad klastra, które ustawiają wartość autotermination_minutes w konfiguracji klastra, powoduje błąd. Aby kontrolować zachowanie zamykania klastra, można użyć trybu programowania lub produkcji lub użyć pipelines.clusterShutdown.delay ustawienia w konfiguracji potoku. Poniższy przykład ustawia wartość pipelines.clusterShutdown.delay na 60 sekund:
{
"configuration": {
"pipelines.clusterShutdown.delay": "60s"
}
}
Gdy tryb production jest włączony, domyślna wartość parametru pipelines.clusterShutdown.delay to 0 seconds. Gdy tryb development jest włączony, domyślna wartość to 2 hours.
Tworzenie klastra z jednym węzłem
Jeśli w ustawieniach klastra ustawiono num_workers wartość 0, klaster zostanie utworzony jako klaster z jednym węzłem. Skonfigurowanie automatycznie skalowanego klastra i ustawienie wartości min_workers na 0 i wartości max_workers na 0 również powoduje utworzenie klastra z jednym węzłem.
Jeśli skonfigurujesz klaster skalowania automatycznego i ustawisz tylko min_workers wartość 0, klaster nie zostanie utworzony jako klaster z jednym węzłem. Klaster ma co najmniej jeden aktywny proces roboczy przez cały czas do zakończenia jego działania.
Przykładowa konfiguracja klastra do utworzenia klastra z pojedynczym węzłem na platformie Delta Live Tables:
{
"clusters": [
{
"num_workers": 0
}
]
}
Konfigurowanie tagów klastra
Możesz użyć tagów klastra do monitorowania użycia klastrów potoków. Dodaj tagi klastra w interfejsie użytkownika tabel Delta Live Tables podczas tworzenia lub edytowania potoku albo edytując ustawienia JSON dla klastrów potoków.
Konfiguracja magazynu w chmurze
Aby uzyskać dostęp do usługi Azure Storage, należy skonfigurować wymagane parametry, w tym tokeny dostępu, przy użyciu spark.conf ustawień w konfiguracjach klastra. Aby zapoznać się z przykładem konfigurowania dostępu do konta magazynu usługi Azure Data Lake Storage Gen2 (ADLS Gen2), zobacz Bezpieczne uzyskiwanie dostępu do poświadczeń magazynu przy użyciu wpisów tajnych w potoku.
Parametryzowanie deklaracji zestawu danych w języku Python lub SQL
Kod Python i SQL definiujący zestawy danych można sparametryzować przy użyciu ustawień potoku. Parametryzacja umożliwia następujące przypadki użycia:
- Oddzielanie długich ścieżek i innych zmiennych od kodu.
- Zmniejszenie ilości danych przetwarzanych w środowiskach programistycznych lub przejściowych w celu przyspieszenia testowania.
- Ponowne użycie tej samej logiki przekształcania w celu przetworzenia z wielu źródeł danych.
W poniższym przykładzie użyto startDate wartości konfiguracji, aby ograniczyć potok programowania do podzestawu danych wejściowych:
CREATE OR REFRESH LIVE TABLE customer_events
AS SELECT * FROM sourceTable WHERE date > '${mypipeline.startDate}';
@dlt.table
def customer_events():
start_date = spark.conf.get("mypipeline.startDate")
return read("sourceTable").where(col("date") > start_date)
{
"name": "Data Ingest - DEV",
"configuration": {
"mypipeline.startDate": "2021-01-02"
}
}
{
"name": "Data Ingest - PROD",
"configuration": {
"mypipeline.startDate": "2010-01-02"
}
}
Interwał wyzwalacza potoków
pipelines.trigger.interval Służy do kontrolowania interwału wyzwalacza dla przepływu aktualizującego tabelę lub cały potok. Ponieważ wyzwalany potok przetwarza każdą tabelę tylko raz, pipelines.trigger.interval parametr jest używany tylko w przypadku potoków ciągłych.
Usługa Databricks zaleca ustawienie pipelines.trigger.interval dla poszczególnych tabel ze względu na różne wartości domyślne dla zapytań przesyłanych strumieniowo i wsadowych. Ustaw wartość potoku tylko wtedy, gdy przetwarzanie wymaga kontrolowania aktualizacji dla całego grafu potoku.
Tabelę można ustawić pipelines.trigger.interval przy użyciu języka spark_conf Python lub SET w języku SQL:
@dlt.table(
spark_conf={"pipelines.trigger.interval" : "10 seconds"}
)
def <function-name>():
return (<query>)
SET pipelines.trigger.interval=10 seconds;
CREATE OR REFRESH LIVE TABLE TABLE_NAME
AS SELECT ...
Aby ustawić pipelines.trigger.interval potok, dodaj go do configuration obiektu w ustawieniach potoku:
{
"configuration": {
"pipelines.trigger.interval": "10 seconds"
}
}
Zezwalaj użytkownikom niebędącym administratorem na wyświetlanie dzienników sterowników z potoku obsługującego wykaz aparatu Unity
Domyślnie tylko właściciel potoku i administratorzy obszaru roboczego mają uprawnienia do wyświetlania dzienników sterowników z klastra z uruchomionym potokiem obsługującym wykaz aparatu Unity. Możesz włączyć dostęp do dzienników sterowników dla dowolnego użytkownika z uprawnieniami CAN MANAGE, CAN VIEW lub CAN RUN, dodając następujący parametr konfiguracji platformy Spark do configuration obiektu w ustawieniach potoku:
{
"configuration": {
"spark.databricks.acl.needAdminPermissionToViewLogs": "false"
}
}
Dodawanie powiadomień e-mail dotyczących zdarzeń potoku
Możesz skonfigurować co najmniej jeden adres e-mail, aby otrzymywać powiadomienia, gdy wystąpią następujące czynności:
- Aktualizacja potoku zostanie ukończona pomyślnie.
- Aktualizacja potoku kończy się niepowodzeniem z możliwością ponowienia próby lub błędem, który nie można ponowić. Wybierz tę opcję, aby otrzymywać powiadomienie dotyczące wszystkich niepowodzeń potoku.
- Aktualizacja potoku kończy się niepowodzeniem z błędem niemożliwym do ponowienia próby (krytycznym). Wybierz tę opcję, aby otrzymywać powiadomienie tylko wtedy, gdy wystąpi błąd niemożliwy do ponowienia próby.
- Pojedynczy przepływ danych kończy się niepowodzeniem.
Aby skonfigurować powiadomienia e-mail podczas tworzenia lub edytowania potoku:
- Kliknij pozycję Dodaj powiadomienie.
- Wprowadź co najmniej jeden adres e-mail, aby otrzymywać powiadomienia.
- Kliknij pole wyboru dla każdego typu powiadomienia, które ma być wysyłane na skonfigurowane adresy e-mail.
- Kliknij pozycję Dodaj powiadomienie.
Kontrolowanie zarządzania grobowcami dla zapytań typu SCD 1
Następujące ustawienia mogą służyć do kontrolowania zachowania zarządzania grobowcami dla DELETE zdarzeń podczas przetwarzania typu 1 scD:
pipelines.applyChanges.tombstoneGCThresholdInSeconds: ustaw tę wartość tak, aby odpowiadała najwyższemu oczekiwanemu interwałowi w sekundach między danymi poza kolejnością. Wartość domyślna to 172800 sekund (2 dni).pipelines.applyChanges.tombstoneGCFrequencyInSeconds: to ustawienie steruje tym, jak często, w sekundach, grobowce są sprawdzane pod kątem czyszczenia. Wartość domyślna to 1800 sekund (30 minut).
Zobacz Stosowanie zmian interfejsu API: upraszczanie przechwytywania danych zmian w tabelach delta live.
Konfigurowanie uprawnień potoku
Aby zarządzać uprawnieniami w potoku, musisz mieć CAN MANAGE uprawnienia lub IS OWNER w potoku.
Na pasku bocznym kliknij pozycję Tabele na żywo delty.
Wybierz nazwę potoku.
Kliknij menu
 kebab, a następnie wybierz pozycję Uprawnienia.
kebab, a następnie wybierz pozycję Uprawnienia.W obszarze Ustawienia uprawnień wybierz menu rozwijane Wybierz użytkownika, grupę lub jednostkę usługi, a następnie wybierz użytkownika, grupę lub jednostkę usługi.
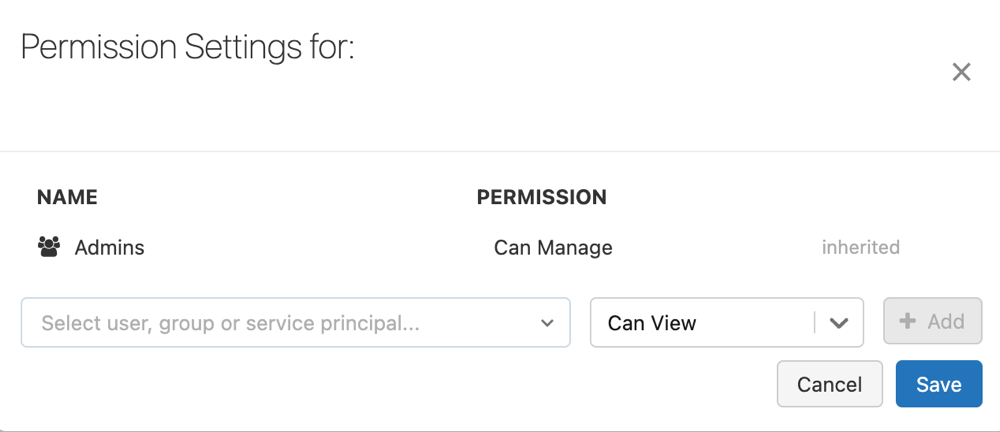
Wybierz uprawnienie z menu rozwijanego uprawnień.
Kliknij przycisk Dodaj.
Kliknij przycisk Zapisz.
Włączanie magazynu stanów bazy danych RocksDB dla tabel na żywo usługi Delta
Zarządzanie stanem opartym na bazie bazy danych RocksDB można włączyć, ustawiając następującą konfigurację przed wdrożeniem potoku:
{
"configuration": {
"spark.sql.streaming.stateStore.providerClass": "com.databricks.sql.streaming.state.RocksDBStateStoreProvider"
}
}
Aby dowiedzieć się więcej na temat magazynu stanów bazy danych RocksDB, w tym zaleceń dotyczących konfiguracji bazy danych RocksDB, zobacz Configure RocksDB state store on Azure Databricks (Konfigurowanie magazynu stanów bazy danych RocksDB w usłudze Azure Databricks).
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla