Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na tej stronie opisano sposób odczytywania danych udostępnionych ci przy użyciu protokołu otwartego udostępniania Delta Sharing z tokenami uwierzytelniającymi. Zawiera instrukcje dotyczące odczytywania udostępnionych danych przy użyciu następujących narzędzi:
W tym otwartym modelu udostępniania użyjesz pliku poświadczeń udostępnionego członkowi zespołu przez dostawcę danych, aby uzyskać bezpieczny dostęp do odczytu do udostępnionych danych. Dostęp trwa tak długo, jak dane uwierzytelniające są ważne, a dostawca kontynuuje udostępnianie danych. Dostawcy zarządzają wygasaniem i rotacją poświadczeń. Aktualizacje danych są dostępne niemal w czasie rzeczywistym. Możesz odczytywać i tworzyć kopie udostępnionych danych, ale nie można modyfikować danych źródłowych.
Notatka
Jeśli dane zostały Ci udostępnione przy użyciu Databricks-to-Databricks Delta Sharing, nie potrzebujesz pliku poświadczeń, aby uzyskać dostęp do tych danych, a ta strona nie ma zastosowania do Ciebie. Zamiast tego zobacz Odczyt danych udostępnionych przy użyciu Databricks-to-Databricks Delta Sharing (dla odbiorców).
W poniższych sekcjach opisano, jak używać Azure Databricks, Apache Spark, pandas, klientów Iceberg i Power BI w celu uzyskiwania dostępu do udostępnionych danych i odczytywania ich przy użyciu pliku poświadczeń. Aby uzyskać pełną listę łączników usługi Delta Sharing i informacje o sposobie ich używania, zobacz dokumentację Delta Sharing open source. Jeśli napotkasz problemy z dostępem do danych udostępnionych, skontaktuj się z dostawcą danych.
Przed rozpoczęciem
Członek zespołu musi pobrać plik poświadczeń udostępniony przez dostawcę danych i użyć bezpiecznego kanału, aby udostępnić ci ten plik lub lokalizację pliku. Zobacz Uzyskaj dostęp w modelu otwartego udostępniania.
Aby uzyskać dokumentację specyficzną dla łącznika, zobacz stronę pobierania poświadczeń.
Azure Databricks: Odczytywanie udostępnionych danych przy użyciu otwartych łączników udostępniania
W tej sekcji opisano sposób importowania dostawcy i wykonywania zapytań dotyczących udostępnionych danych w Eksploratorze wykazu lub w notesie Python:
Jeśli obszar roboczy Azure Databricks został włączony do Unity Catalog, użyj interfejsu użytkownika dostawcy importu w Eksploratorze katalogu. Możesz wykonać następujące czynności bez konieczności przechowywania lub określania pliku poświadczeń:
- Utwórz katalogi z udostępnień jednym kliknięciem.
- Użyj mechanizmów kontroli dostępu katalogu Unity, aby umożliwić dostęp do udostępnionych tabel.
- Zadawaj zapytania dotyczące udostępnionych danych przy użyciu standardowej składni Unity Catalog.
- Zastosuj zaktualizowane poświadczenia do istniejącego obiektu dostawcy bez ponownego utworzenia katalogu. Zobacz Rotacja poświadczeń dla otwartych adresatów.
Jeśli obszar roboczy Azure Databricks nie jest włączony dla Unity Catalog, użyj instrukcji notatnika Python jako przykładu.
Eksplorator wykazu
Wymagane uprawnienia: administrator Katalogu lub użytkownik, który ma uprawnienia CREATE PROVIDER i USE PROVIDER dla magazynu metadanych Unity Catalog.
W obszarze roboczym Azure Databricks kliknij pozycję
 Katalog aby otworzyć Eksplorator Katalogu.
Katalog aby otworzyć Eksplorator Katalogu.W górnej części okienka Wykaz kliknij
 i wybierz Delta Sharing.
i wybierz Delta Sharing.Alternatywnie w prawym górnym rogu kliknij Udostępnij > Delta Sharing.
Na karcie Udostępnione mi kliknij pozycję Importuj dane.
Wprowadź nazwę dostawcy.
Nazwa nie może zawierać spacji.
Przekaż plik poświadczeń udostępniony przez dostawcę.
Wielu dostawców ma własne sieci Delta Sharing, z których możesz otrzymywać udziały. Aby uzyskać więcej informacji, zobacz konfiguracje specyficzne dla dostawcy.
(Optional) Wprowadź komentarz.
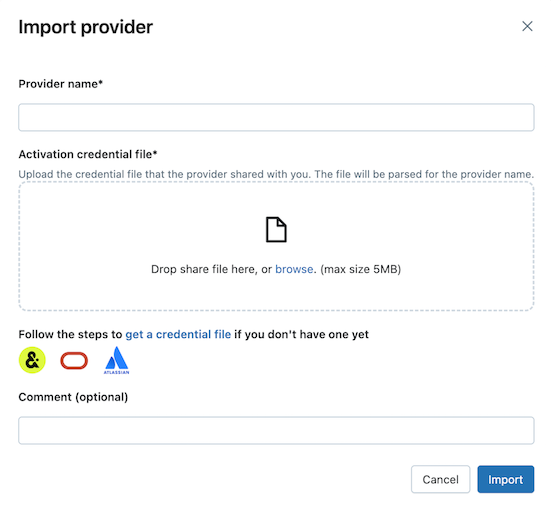
Kliknij Import.
Utwórz wykazy na podstawie udostępnionych danych.
Na karcie Udziałów kliknij pozycję Utwórz katalog w wierszu udziałów.
Aby uzyskać informacje na temat tworzenia wykazu na podstawie udziału przy użyciu języka SQL lub interfejsu wiersza polecenia usługi Databricks, zobacz Tworzenie wykazu na podstawie udziału.
Udziel dostępu do katalogów.
Zobacz Jak udostępnić dane mojemu zespołowi? i Zarządzaj uprawnieniami dla schematów, tabel i woluminów w katalogu Delta Sharing.
Odczytaj udostępnione obiekty danych tak, jak każdy obiekt danych zarejestrowany w Unity Catalog.
Aby uzyskać szczegółowe informacje i przykłady, zobacz dostęp do danych w udostępnionej tabeli lub woluminie.
Python
W tej sekcji opisano sposób używania otwartego łącznika udostępniania do uzyskiwania dostępu do danych udostępnionych przy użyciu notesu w obszarze roboczym Azure Databricks. Użytkownik lub inny członek zespołu przechowuje plik poświadczeń w Azure Databricks, a następnie używa go do uwierzytelniania na koncie Azure Databricks dostawcy danych i odczytywania danych udostępnionych przez dostawcę danych.
Notatka
W tych instrukcjach założono, że obszar roboczy Azure Databricks nie jest włączony przez Unity Catalog. Jeśli używasz Unity Catalog, nie musisz wskazywać pliku poświadczeń podczas odczytywania z udostępnienia. Możesz odczytywać z udostępnionych tabel tak, jak z dowolnej tabeli zarejestrowanej w Unity Catalog. Usługa Databricks zaleca użycie interfejsu użytkownika dostawcy importu w Eksploratorze wykazu zamiast instrukcji podanych tutaj.
Najpierw zapisz plik poświadczeń jako plik obszaru roboczego Azure Databricks, aby użytkownicy w zespole mogli uzyskiwać dostęp do udostępnionych danych.
Aby zaimportować plik poświadczeń w obszarze roboczym Azure Databricks, zobacz Importuj plik.
Udziel innym użytkownikom uprawnień dostępu do pliku, klikając
 Obok pliku wybierz pozycję Udostępnij (uprawnienia). Wprowadź tożsamości Azure Databricks, którym powinien być przyznany dostęp do pliku.
Obok pliku wybierz pozycję Udostępnij (uprawnienia). Wprowadź tożsamości Azure Databricks, którym powinien być przyznany dostęp do pliku.Aby uzyskać więcej informacji na temat uprawnień do plików, zobacz Listy ACL plików.
Teraz, gdy plik poświadczeń jest przechowywany, użyj notebooka, aby wyświetlić listę i odczytywać udostępnione tabele.
W obszarze roboczym Azure Databricks kliknij pozycję Nowy > Notebook.
Aby uzyskać więcej informacji na temat notesów Azure Databricks, zobacz Databricks notebooks.
Aby użyć Python lub
pandas, aby uzyskać dostęp do danych udostępnionych, zainstaluj łącznik delta-sharing Python connector. W edytorze notatnika wklej następujące polecenie:%sh pip install delta-sharingUruchom komórkę.
Biblioteka
delta-sharingPython jest zainstalowana w klastrze, jeśli nie została jeszcze zainstalowana.Używając Pythona, wyświetl listę tabel w udziale.
W nowej komórce wklej następujące polecenie. Zastąp ścieżkę obszaru roboczego ścieżką do pliku poświadczeń.
Po uruchomieniu kodu Python odczytuje plik poświadczeń.
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()Uruchom komórkę.
Wynikiem jest tablica tabel, wraz z metadanymi dla każdej tabeli. W poniższym wyniku widać dwie tabele:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Jeśli dane wyjściowe są puste lub nie zawierają oczekiwanych tabel, skontaktuj się z dostawcą danych.
Zapytać wspólną tabelę.
Używanie języka Scala:
W nowej komórce wklej następujące polecenie. Po uruchomieniu kodu plik poświadczeń jest odczytywany z pliku obszaru roboczego.
Zamień zmienne w następujący sposób:
-
<profile-path>: ścieżka robocza pliku poświadczeń. Na przykład,/Workspace/Users/user.name@email.com/config.share. -
<share-name>: wartośćshare=dla tabeli. -
<schema-name>: wartośćschema=dla tabeli. -
<table-name>: wartośćname=dla tabeli.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Uruchom komórkę. Za każdym razem, gdy ładujesz współdzieloną tabelę, widzisz aktualne dane ze źródła.
Aby wykonywać zapytania dotyczące kolumn śledzenia wierszy w udostępnionej tabeli, zobacz Odczytywanie kolumn śledzenia wierszy w tabelach udostępnionych.
-
Korzystanie z języka SQL:
Aby wykonać zapytanie do danych przy użyciu SQL, tworzysz lokalną tabelę w przestrzeni roboczej na podstawie tabeli współdzielonej, a następnie wykonujesz zapytanie do tej lokalnej tabeli. Dane współdzielone nie są przechowywane ani buforowane w tabeli lokalnej. Za każdym razem, gdy wyszukujesz w lokalnej tabeli, widzisz aktualny stan współdzielonych danych.
W nowej komórce wklej następujące polecenie.
Zamień zmienne w następujący sposób:
-
<local-table-name>: nazwa lokalnej tabeli. -
<profile-path>: lokalizacja pliku z poświadczeniami. -
<share-name>: wartośćshare=dla tabeli. -
<schema-name>: wartośćschema=dla tabeli. -
<table-name>: wartośćname=dla tabeli.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;Gdy uruchomisz polecenie, dane współdzielone są bezpośrednio zapytane. Aby przetestować, zapytanie jest kierowane do tabeli, a zwracane są pierwsze 10 wyników.
-
Jeśli dane wyjściowe są puste lub nie zawierają oczekiwanych danych, skontaktuj się z dostawcą danych.
Klienci Iceberg: odczytywanie udostępnionych danych
Ważne
Ta funkcja jest w Public Preview.
Użyj zewnętrznych klientów Iceberg, takich jak Snowflake, Trino, Flink i Spark, aby odczytywać udostępnione zasoby danych z dostępem bez kopii przy użyciu interfejsu API katalogu REST Apache Iceberg.
Uzyskiwanie poświadczeń połączenia
Zanim uzyskasz dostęp do udostępnionych zasobów danych za pomocą zewnętrznych klientów Iceberg, zbierz następujące poświadczenia:
- Punkt końcowy katalogu REST Iceberg
- Prawidłowy token elementu nośnego
- Nazwa udziału
- (Opcjonalnie) Przestrzeń nazw lub nazwa schematu
- (Opcjonalnie) Nazwa tabeli
Punkt końcowy katalogu REST Iceberg (icebergEndpoint) i token Bearer znajdują się w pliku poświadczeń udostępnionym Tobie przez dostawcę danych. Aby uzyskać więcej informacji, zobacz Przed rozpoczęciem. Nazwy udziału, przestrzeni nazw i nazwy tabeli można odnaleźć programowo przy użyciu interfejsów API udostępniania różnicowego.
Ważne
Element icebergEndpoint znajduje się w pliku poświadczeń i ma format <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg.
W poniższych przykładach pokazano, jak uzyskać dodatkowe poświadczenia. Wprowadź punkt końcowy, punkt końcowy Iceberg i token typu Bearer z pliku poświadczeń:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Notatka
Ta metoda zawsze pobiera najbardziej aktualną listę zasobów. Wymaga to jednak dostępu do Internetu i może być trudniejsze do zintegrowania w środowiskach bez kodu.
Konfiguracja katalogu Iceberg
Po uzyskaniu niezbędnych poświadczeń połączenia skonfiguruj klienta tak, aby używał punktów końcowych katalogu REST Iceberg do tworzenia tabel i wykonywania względem nich zapytań.
Dla każdego udziału utwórz integrację katalogową.
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;Opcjonalnie dodaj,
REFRESH_INTERVAL_SECONDSaby zachować aktualność metadanych. Ustaw wartość na podstawie częstotliwości aktualizacji katalogu.REFRESH_INTERVAL_SECONDS = 30Po skonfigurowaniu wykazu utwórz bazę danych z katalogu. Spowoduje to automatyczne utworzenie wszystkich schematów i tabel w tym wykazie.
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );Aby potwierdzić, że udostępnianie zakończyło się pomyślnie, wykonaj zapytanie z tabeli w bazie danych. Powinny zostać wyświetlone dane udostępnione z Azure Databricks.
Jeśli wynik jest pusty lub wystąpi błąd, wykonaj następujące typowe kroki rozwiązywania problemów:
- Dokładnie sprawdź uprawnienia, stan generowania migawki i poświadczenia REST.
- Skontaktuj się z dostawcą danych.
- Zapoznaj się z dokumentacją specyficzną dla klienta Iceberg.
Przykład: uzyskiwanie dostępu do udostępnionych tabel przy użyciu różnych klientów Iceberg
W poniższych przykładach pokazano, jak uzyskać dostęp do tabel Delta przy użyciu zewnętrznych klientów Iceberg, takich jak Snowflake, Apache Spark, PyIceberg i REST API, po uzyskaniu swoich poświadczeń dostępu. Aby uzyskać więcej informacji na temat uzyskiwania poświadczeń połączenia, zobacz Przed rozpoczęciem.
Snowflake
Aby odczytać udostępnione zasoby danych w usłudze Snowflake, przekaż pobrany plik poświadczeń i wygeneruj niezbędne polecenie SQL:
W linku aktywacji funkcji Delta Sharing kliknij ikonę Snowflake.
Na stronie integracji rozwiązania Snowflake przekaż plik poświadczeń otrzymany od dostawcy danych.
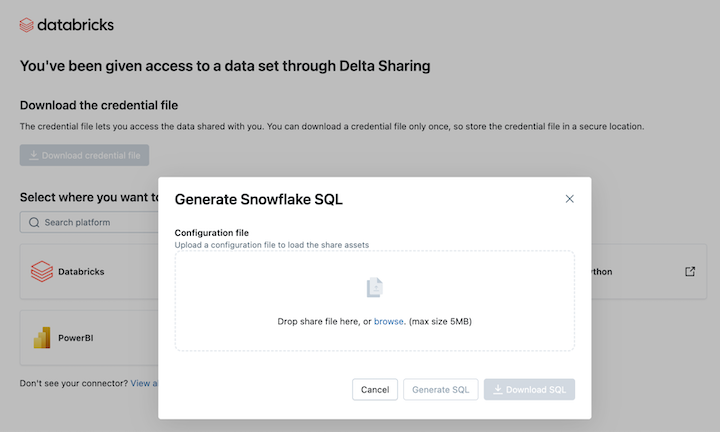
Po załadowaniu poświadczeń wybierz udział, do którego chcesz uzyskać dostęp w Snowflake.
Kliknij pozycję Generuj sql po wybraniu żądanych zasobów.
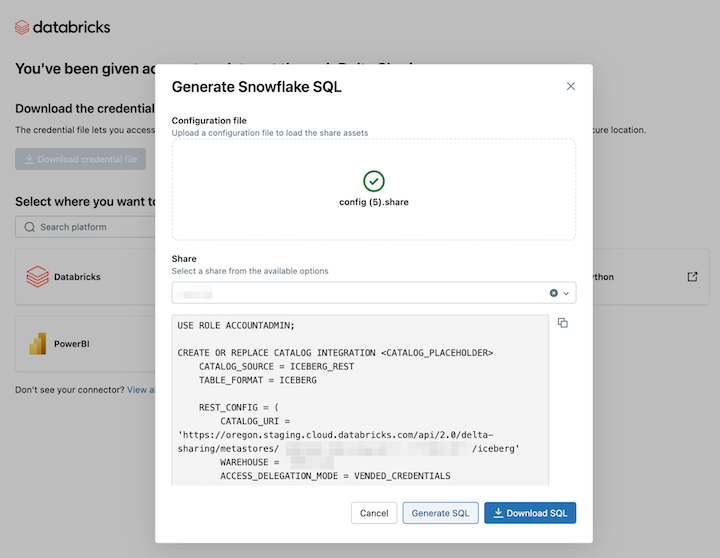
Skopiuj i wklej wygenerowany język SQL do arkusza snowflake. Zastąp
CATALOG_PLACEHOLDERciąg nazwą katalogu, którego chcesz użyć, iDATABASE_PLACEHOLDERnazwą bazy danych, której chcesz użyć.
Ograniczenia
Nawiązywanie połączenia z katalogiem REST Góry lodowej w aplikacji Snowflake ma następujące ograniczenia:
- Plik metadanych nie jest automatycznie aktualizowany przy użyciu najnowszej migawki. Należy polegać na automatycznym odświeżaniu lub ręcznym odświeżaniu.
- R2 nie jest obsługiwany.
- Obowiązują wszystkie ograniczenia klienta Iceberg.
Apache Spark
Aby uzyskać dostęp do udostępnionych tabel przy użyciu platformy Apache Spark, skonfiguruj interfejs API katalogu REST platformy Iceberg przy użyciu następujących ustawień. Zamień <spark-catalog-name> na nazwę swojego katalogu i wprowadź poświadczenia połączenia.
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg
PyIceberg to implementacja Python na potrzeby uzyskiwania dostępu do tabel góry lodowej bez używania maszyny JVM. PyIceberg wymaga pyarrow do operacji na tabelach, takich jak odczytywanie danych i przeglądanie metadanych tabeli. Zainstaluj aplikację PyIceberg z dodatkowymi pyarrow elementami:
pip install "pyiceberg[pyarrow]"
Aby uzyskać dostęp do tabel udostępnionych, dodaj następującą konfigurację katalogu do pliku konfiguracji PyIceberg:
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
interfejs API REST
Użyj wywołania interfejsu API REST, takiego jak w poniższym curl przykładzie, aby załadować tabelę i pobrać jej metadane wraz z tymczasowymi poświadczeniami na potrzeby uzyskiwania dostępu do plików danych:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
Odpowiedź zawiera metadane tabeli Iceberg, lokalizację S3 i tymczasowe poświadczenia platformy AWS, które umożliwiają klientowi odczytywanie plików danych:
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Ograniczenia klienta Iceberg
Podczas wykonywania zapytań dotyczących danych Delta Sharing z klientów Iceberg obowiązują następujące ograniczenia:
- W przypadku wyświetlania listy tabel w przestrzeni nazw, jeśli przestrzeń nazw zawiera więcej niż 100 widoków udostępnionych, odpowiedź jest ograniczona do pierwszych 100 widoków.
Apache Spark: odczytywanie udostępnionych danych
Aby uzyskać dostęp do udostępnionych danych za pomocą Spark w wersji 3.x lub wyższej, wykonaj następujące kroki.
Instrukcje te zakładają, że masz dostęp do pliku z danymi uwierzytelniającymi, który został udostępniony przez dostawcę danych. Zobacz Uzyskaj dostęp w modelu otwartego udostępniania.
Ważne
Upewnij się, że plik poświadczeń jest dostępny dla platformy Apache Spark przy użyciu ścieżki bezwzględnej. Ścieżka może odwoływać się do obiektu w chmurze lub obszaru Unity Catalogu.
Notatka
Jeśli używasz platformy Spark w obszarze roboczym Azure Databricks z włączoną opcją Unity Catalog i jeśli użyłeś interfejsu użytkownika importu do zaimportowania dostawcy i udostępnienia, instrukcje w tej sekcji nie dotyczą Ciebie. Można uzyskać dostęp do tabel udostępnionych tak samo jak do każdej innej tabeli zarejestrowanej w katalogu Unity. Nie musisz instalować łącznika delta-sharing Python lub podać ścieżkę do pliku poświadczeń. Zobacz Azure Databricks: Odczytywanie udostępnionych danych za pomocą otwartych łączników udostępniania.
Instalowanie łączników usługi Delta Sharing Python i Spark
Aby uzyskać dostęp do metadanych związanych z udostępnionymi danymi, takich jak lista tabel udostępnionych Tobie, wykonaj następujące czynności. W tym przykładzie użyto Python.
Zainstaluj łącznik delta-sharing Python. Aby uzyskać informacje na temat ograniczeń łącznika Python, zobacz ograniczenia łącznika usługi Delta Sharing Python.
pip install delta-sharingZainstaluj łącznik platformy Apache Spark.
Wymień zbiorcze tabele za pomocą Spark
Wymień tabele w udziale. W poniższym przykładzie zamień <profile-path> na lokalizację pliku uwierzytelniającego.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Wynikiem jest tablica tabel, wraz z metadanymi dla każdej tabeli. W poniższym wyniku widać dwie tabele:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Jeśli dane wyjściowe są puste lub nie zawierają oczekiwanych tabel, skontaktuj się z dostawcą danych.
Uzyskaj dostęp do współdzielonych danych za pomocą Spark
Uruchom następujące, zastępując te zmienne:
-
<profile-path>: lokalizacja pliku z poświadczeniami. -
<share-name>: wartośćshare=dla tabeli. -
<schema-name>: wartośćschema=dla tabeli. -
<table-name>: wartośćname=dla tabeli. -
<version-as-of>: opcjonalny. Wersja tabeli do załadowania danych. Działa tylko wtedy, gdy dostawca danych udostępnia historię tabeli. Wymagadelta-sharing-spark0.5.0 lub wyższą wersję. -
<timestamp-as-of>: opcjonalny. Załaduj dane w wersji sprzed lub o podanej sygnaturze czasowej. Działa tylko wtedy, gdy dostawca danych udostępnia historię tabeli. Wymagadelta-sharing-sparkwersji 0.6.0 lub nowszej.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Skala
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Uzyskaj dostęp do udostępnionego strumienia danych o zmianach za pomocą Spark
Jeśli historia tabeli została Ci udostępniona i w tabeli źródłowej jest włączony strumień zmian danych (CDF), uzyskaj dostęp do strumienia zmian danych, uruchamiając następujące polecenie, zastępując te zmienne. Wymaga delta-sharing-spark 0.5.0 lub wyższą wersję.
Należy podać jeden parametr początkowy.
-
<profile-path>: lokalizacja pliku z poświadczeniami. -
<share-name>: wartośćshare=dla tabeli. -
<schema-name>: wartośćschema=dla tabeli. -
<table-name>: wartośćname=dla tabeli. -
<starting-version>: opcjonalny. Początkowa wersja zapytania, włącznie. Określ jako Long. -
<ending-version>: opcjonalny. Końcowa wersja zapytania, włącznie. Jeśli końcowa wersja nie jest podana, API używa najnowszej wersji tabeli. -
<starting-timestamp>: opcjonalny. Początkowy znacznik czasu zapytania, który jest przekształcany na wersję utworzoną w czasie większym lub równym temu znacznikowi czasu. Określ jako ciąg w formacieyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>: opcjonalny. Znacznik końcowy zapytania, który jest przekształcany na wersję utworzoną wcześniej lub równą temu znacznikowi czasowemu. Określ to jako ciąg w formacieyyyy-mm-dd hh:mm:ss[.fffffffff]
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Skala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Jeśli dane wyjściowe są puste lub nie zawierają oczekiwanych danych, skontaktuj się z dostawcą danych.
Uzyskaj dostęp do współdzielonej tabeli za pomocą Spark Structured Streaming
Jeśli historia tabeli została z tobą udostępniona, możesz strumieniowo odczytywać udostępnione dane. Wymaga delta-sharing-spark wersji 0.6.0 lub nowszej.
Obsługiwane opcje:
-
ignoreDeletes: Ignoruj transakcje, które usuwają dane. -
ignoreChanges: Przetwórz ponownie aktualizacje, jeśli pliki zostały przepisane w tabeli źródłowej z powodu operacji zmiany danych, takiej jakUPDATE,MERGE INTO,DELETE(w ramach partycji) lubOVERWRITE. Niezmienione wiersze mogą nadal być emitowane. W związku z tym odbiorcy podrzędni powinni mieć możliwość obsługi duplikatów. Usunięcia nie są propagowane dalej.ignoreChangeszawieraignoreDeletes. W związku z tym, jeśli używaszignoreChanges, strumień nie jest zakłócany przez usunięcia lub aktualizacje tabeli źródłowej. -
startingVersion: Wersja współdzielonej tabeli, od której należy zacząć. Wszystkie zmiany tabeli począwszy od tej wersji (włącznie) są odczytywane przez źródło przesyłania strumieniowego. - Znacznik czasu, od którego zaczynamy. Wszystkie zmiany tabeli zatwierdzone w lub po określonym znaczniku czasu (włącznie) są odczytywane przez źródło przesyłania strumieniowego. Przykład:
"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: Liczba nowych plików, które należy rozważyć w każdej mikroserii. -
maxBytesPerTrigger: Ilość danych przetwarzanych w każdej mikro-partii. Ta opcja ustawia „miękki maks”, co oznacza, że partia przetwarza mniej więcej tę ilość danych i może przetworzyć więcej niż limit, aby przesunąć zapytanie strumieniowe do przodu w przypadkach, gdy najmniejsza jednostka wejściowa jest większa niż ten limit. -
readChangeFeed: Strumień odczytuje kanał danych zmiany wspólnej tabeli.
Nieobsługiwane opcje:
Trigger.availableNow
Przykładowe zapytania strukturalnego przesyłania strumieniowego
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Skala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Zobacz także Structured Streaming concepts.
Odczyt tabel z włączonymi wektorami usuwania lub mapowaniem kolumn
Ważne
Ta funkcja jest w Public Preview.
Wektory usuwania są funkcją optymalizacji przechowywania, którą Twój dostawca może włączyć w współdzielonych tabelach Delta. Zobacz Wektory usuwania w usłudze Databricks.
Azure Databricks obsługuje również mapowanie kolumn dla tabel delty. Zobacz Zmienianie nazw i usuwanie kolumn z mapowaniem kolumn Delta Lake.
Jeśli dostawca udostępnił tabelę z włączonymi wektorami usuwania lub mapowaniem kolumn, możesz odczytać tabelę za pomocą obliczeń działających w wersji delta-sharing-spark 3.1 lub wyższej. Jeśli używasz klastrów Databricks, możesz wykonywać odczyty wsadowe za pomocą klastra działającego na Databricks Runtime 14.1 lub nowszym. Zapytania typu CDF i przesyłania strumieniowego wymagają Databricks Runtime 14.2 lub nowszego.
Możesz wykonywać zapytania zbiorcze bez zmian, ponieważ mogą one automatycznie rozwiązywać responseFormat na podstawie funkcji tabeli udostępnionej tabeli.
Aby odczytać kanał danych zmian (CDF) lub wykonać zapytania strumieniowe dotyczące współdzielonych tabel z włączonymi wektorami usunięć lub mapowaniem kolumn, musisz ustawić dodatkową opcję responseFormat=delta.
Poniższe przykłady pokazują zapytania wsadowe, CDF i strumieniowe.
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Odczytywanie kolumn śledzenia wierszy w tabelach udostępnionych
Jeśli dostawca danych włączył śledzenie wierszy w udostępnionej tabeli, możesz wykonać zapytanie dotyczące kolumn metadanych śledzenia wierszy przy użyciu platformy Scala Spark. Aby uzyskać listę dostępnych kolumn, zobacz Śledzenie wierszy w usłudze Databricks .
Należy ustawić responseFormat opcję na delta.
spark.read.format("deltaSharing")
.option("responseFormat", "delta")
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.select("_metadata.row_id")
.show()
Notatka
Tylko format odpowiedzi różnicowej jest obsługiwany w przypadku wykonywania zapytań dotyczących kolumn śledzenia wierszy w kliencie platformy Spark. Złącza do zrzutu nie są obsługiwane.
Pandas: odczytywanie udostępnionych danych
Wykonaj następujące kroki, aby uzyskać dostęp do udostępnionych danych w wersji pandas 0.25.3 lub nowszej.
Instrukcje te zakładają, że masz dostęp do pliku z danymi uwierzytelniającymi, który został udostępniony przez dostawcę danych. Zobacz Uzyskaj dostęp w modelu otwartego udostępniania.
Notatka
Jeśli używasz pandas w obszarze roboczym Azure Databricks, który jest włączony dla Unity Catalog, i używasz interfejsu użytkownika do importowania dostawcy w celu zaimportowania dostawcy i dostępu, instrukcje w tej sekcji nie dotyczą Ciebie. Można uzyskać dostęp do tabel udostępnionych tak samo jak do każdej innej tabeli zarejestrowanej w katalogu Unity. Nie musisz instalować łącznika delta-sharing Python lub podać ścieżkę do pliku poświadczeń. Zobacz Azure Databricks: Odczytywanie udostępnionych danych za pomocą otwartych łączników udostępniania.
Instalowanie łącznika usługi Delta Sharing Python
Aby uzyskać dostęp do metadanych powiązanych z udostępnionymi danymi, takimi jak lista tabel udostępnionych Tobie, musisz zainstalować łącznik delta-sharing Python connector. Aby uzyskać informacje na temat ograniczeń łącznika Python, zobacz ograniczenia łącznika usługi Delta Sharing Python.
pip install delta-sharing
Wyświetlanie listy udostępnionych tabel przy użyciu pandas
Aby wyświetlić listę tabel w udziale, uruchom następujące polecenie, zastępując <profile-path>/config.share lokalizacją pliku uwierzytelniającego.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Jeśli dane wyjściowe są puste lub nie zawierają oczekiwanych tabel, skontaktuj się z dostawcą danych.
Uzyskiwanie dostępu do danych udostępnionych przy użyciu pandas
Aby uzyskać dostęp do danych udostępnionych w pandas przy użyciu Python, uruchom następujące polecenie, zastępując zmienne w następujący sposób:
-
<profile-path>: lokalizacja pliku z poświadczeniami. -
<share-name>: wartośćshare=dla tabeli. -
<schema-name>: wartośćschema=dla tabeli. -
<table-name>: wartośćname=dla tabeli.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Uzyskiwanie dostępu do udostępnionego źródła danych zmian przy użyciu polecenia pandas
Aby uzyskać dostęp do zestawienia danych zmian dla udostępnionej tabeli w pandas przy użyciu Python uruchom następujące polecenie, zastępując zmienne w następujący sposób. Kanał danych dotyczący zmian może być niedostępny, w zależności od tego, czy dostawca danych udostępnił kanał danych dotyczący zmian dla tabeli.
-
<starting-version>: opcjonalny. Początkowa wersja zapytania, włącznie. -
<ending-version>: opcjonalny. Końcowa wersja zapytania, włącznie. -
<starting-timestamp>: opcjonalny. Znacznik czasu rozpoczęcia zapytania. To jest przekształcone na wersję stworzoną większą lub równą temu znacznikowi czasu. -
<ending-timestamp>: opcjonalny. Końcowy znacznik czasu zapytania. Jest to wersja konwertowana na wersję utworzoną wcześniej lub równą temu znacznikowi czasu.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Jeśli dane wyjściowe są puste lub nie zawierają oczekiwanych danych, skontaktuj się z dostawcą danych.
Power BI: Odczytywanie udostępnionych danych
Łącznik Power BI Delta Sharing umożliwia odnajdywanie, analizowanie i wizualizowanie zestawów danych udostępnionych za pośrednictwem otwartego protokołu Delta Sharing.
Wymagania
- Power BI Desktop 2.99.621.0 lub nowszy.
- Dostęp do pliku z poświadczeniami, który został udostępniony przez dostawcę danych. Zobacz Uzyskaj dostęp w modelu otwartego udostępniania.
Połącz się z Databricks
Aby nawiązać połączenie z Azure Databricks przy użyciu łącznika usługi Delta Sharing, wykonaj następujące czynności:
- Otwórz plik z poświadczeniami współdzielonymi za pomocą edytora tekstu, aby uzyskać adres URL punktu końcowego i token.
- Otwórz Power BI Desktop.
- W menu Get Data wyszukaj Delta Sharing.
- Wybierz złącze i kliknij Połącz.
- Wprowadź URL punktu końcowego, który skopiowałeś z pliku z poświadczeniami, do pola URL serwera Delta Sharing.
- Opcjonalnie, na karcie Opcje zaawansowane, ustaw Limit wierszy jako maksymalną liczbę wierszy, które możesz pobrać. To jest domyślnie ustawione na 1 milion wierszy.
- Kliknij przycisk OK.
- Aby przeprowadzić autoryzację, skopiuj token, który otrzymałeś z pliku z danymi uwierzytelniającymi, do sekcji Token Bearer.
- Kliknij Połącz.
Ograniczenia łącznika Delta Sharing Power BI
Łącznik udostępniania różnicowego Power BI ma następujące ograniczenia:
- Dane ładowane przez konektor muszą mieścić się w pamięci twojej maszyny. Aby zarządzać tym wymaganiem, łącznik ogranicza liczbę importowanych wierszy do limitu Row Limit który został ustawiony na karcie Opcje zaawansowane w programie Power BI Desktop.
Tableau: Odczytaj dane współdzielone
Złącze Tableau Delta Sharing pozwala na odkrywanie, analizowanie i wizualizację zestawów danych, które są z Tobą udostępniane poprzez otwarty protokół Delta Sharing.
Wymagania
- Tableau Desktop i Tableau Server 2024.1 lub nowszy
- Dostęp do pliku z poświadczeniami, który został udostępniony przez dostawcę danych. Zobacz Uzyskaj dostęp w modelu otwartego udostępniania.
Nawiązywanie połączenia z usługą Azure Databricks
Aby nawiązać połączenie z Azure Databricks przy użyciu łącznika usługi Delta Sharing, wykonaj następujące czynności:
- Przejdź do Tableau Exchange, postępuj zgodnie z instrukcjami, aby pobrać łącze udostępniania Delta i umieścić go w odpowiednim folderze pulpitu.
- Otwórz Tableau Desktop.
- Na stronie Złącza wyszukaj „Delta Sharing by Databricks”.
- ** Wybierz Prześlij plik Share, i wybierz plik uwierzytelniający udostępniony przez dostawcę.
- Kliknij pozycję Pobierz dane.
- W Data Explorer wybierz tabelę.
- Opcjonalnie dodaj filtry SQL lub ograniczenia wierszy.
- Kliknij Get Table Data.
Ograniczenia
Złącze Tableau Delta Sharing ma następujące ograniczenia:
- Dane ładowane przez konektor muszą mieścić się w pamięci twojej maszyny. Aby zarządzać tym wymaganiem, łącznik ogranicza liczbę importowanych wierszy do limitu wierszy, który ustawiłeś w Tableau.
- Wszystkie kolumny są zwracane jako typ
String. - Filtr SQL działa tylko wtedy, gdy serwer Delta Sharing obsługuje predicateHint.
- Wektory usuwania nie są obsługiwane.
- Mapowanie kolumn nie jest obsługiwane.
ograniczenia łącznika Delta Sharing w Pythonie
Te ograniczenia dotyczą łącznika Delta Sharing dla Pythona.
- Łącznik usługi Delta Sharing Python w wersji 1.1.0 lub nowszej obsługuje zapytania migawek w tabelach z mapowaniem kolumn, ale zapytania CDF w tabelach z mapowaniem kolumn nie są obsługiwane.
- Łącznik usługi Delta Sharing Python kończy się niepowodzeniem zapytań CDF z
use_delta_format=True, jeśli schemat został zmieniony podczas zapytanego zakresu wersji.
Ograniczenia tabel strumieniowania
Można odczytać tylko bieżącą migawkę udostępnionej tabeli przesyłania strumieniowego. Następujące funkcje nie są obsługiwane w przypadku tabel przesyłania strumieniowego w otwartym udostępnianiu:
- Wykonywanie zapytań dotyczących danych historii tabeli
- Wykonywanie zapytań dotyczących strumienia danych zmian w tabeli (CDF)
- Używanie tabeli jako źródła dla Spark Structured Streaming
Zmaterializowane ograniczenia widoku
Można odczytać tylko bieżącą migawkę zmaterializowanego widoku udostępnionego. Używanie widoku zmaterializowanego jako źródła dla Spark Structured Streaming nie jest obsługiwane w kontekście otwartego udostępniania.
Złóż wniosek o nowe poświadczenie
Jeśli Twój URL aktywacji poświadczeń lub pobrane poświadczenia zostaną zgubione, uszkodzone lub naruszone, lub jeśli Twoje poświadczenia wygasną, a Twój dostawca nie prześle Ci nowych, skontaktuj się z dostawcą, aby poprosić o nowe poświadczenia.
Jeśli jesteś użytkownikiem Azure Databricks, który zaimportował poświadczenie jako obiekt dostawcy w Unity Catalog, zastosuj nowe poświadczenie przy użyciu interfejsu API REST Databricks. Zobacz Rotacja poświadczeń dla otwartych adresatów.