Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Pakiety deklaratywnej automatyzacji (wcześniej znane jako pakiety zasobów usługi Databricks) to narzędzie ułatwiające wdrażanie najlepszych praktyk inżynierii oprogramowania, w tym kontroli wersji, przeglądu kodu, testowania oraz ciągłej integracji i dostarczania (CI/CD) dla projektów danych i sztucznej inteligencji. Pakiety umożliwiają dołączanie metadanych wraz z plikami źródłowymi projektu, a także opisywanie zasobów usługi Databricks, takich jak zadania i potoki, jako pliki źródłowe. Ostatecznie pakiet to kompleksowa definicja projektu, w tym sposób, w jaki projekt powinien być ustrukturyzowany, przetestowany i wdrożony. Ułatwia to współpracę nad projektami podczas aktywnego opracowywania.
Kolekcja plików źródłowych i metadanych projektu pakietu jest wdrażana jako pojedynczy pakiet w środowisku docelowym. Pakiet zawiera następujące części:
- Wymagana infrastruktura chmury i konfiguracje obszaru roboczego
- Pliki źródłowe, takie jak notesy i pliki języka Python, które obejmują logikę biznesową
- Definicje i ustawienia zasobów Databricks, takich jak Lakeflow Jobs, potoki Lakeflow, panele, punkty końcowe udostępniania modeli, eksperymenty MLflow i zarejestrowane modele MLflow
- Testy jednostkowe i testy integracji
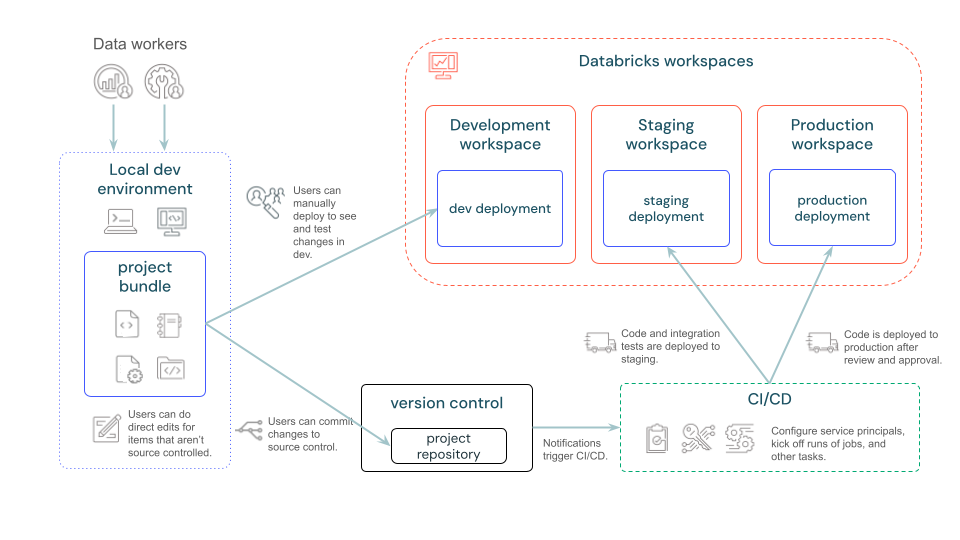
Na poniższym diagramie przedstawiono ogólny przegląd procesu rozwoju i CI/CD z pakietami.
Demonstracja wideo
W tym filmie wideo pokazano, jak pracować z pakietami deklaratywnej automatyzacji (5 minut).
Kiedy należy używać pakietów?
Pakiety automatyzacji deklaratywnej są podejściem infrastruktury jako kodu (IaC) do zarządzania projektami Databricks. Używaj ich, gdy chcesz zarządzać złożonymi projektami, w których wiele współautorów i automatyzacja jest niezbędnych, a ciągła integracja i ciągłe wdrażanie (CI/CD) są wymagane. Ponieważ pakiety są definiowane i zarządzane za pomocą szablonów YAML i plików tworzonych i utrzymywanych z kodem źródłowym, dobrze pasują do sytuacji, w których IaC jest odpowiednim podejściem.
Oto kilka idealnych scenariuszy dla pakietów:
- Opracowywanie projektów danych, analiz i uczenia maszynowego w środowisku opartym na zespole. Pakiety mogą ułatwić efektywne organizowanie różnych plików źródłowych i zarządzanie nimi. Zapewnia to bezproblemową współpracę i usprawnione procesy.
- Przyspiesz iterację w pracy nad problemami uczenia maszynowego. Zarządzaj zasobami potoku uczenia maszynowego (takimi jak zadania trenowania i wnioskowania wsadowego), korzystając z projektów uczenia maszynowego, które są zgodne z najlepszymi praktykami produkcyjnymi od początku.
- Ustaw standardy organizacyjne dla nowych projektów, tworząc niestandardowe szablony pakietów, które obejmują domyślne uprawnienia, główne usługi oraz konfiguracje CI/CD.
- Zgodność z przepisami: W branżach, w których zgodność z przepisami jest istotnym problemem, pakiety mogą pomóc w utrzymaniu historii wersji kodu i pracy infrastruktury. Pomaga to w zapewnianiu ładu i zapewnia spełnienie niezbędnych standardów zgodności.
Jak działają pakiety?
Metadane pakietu są definiowane przy użyciu plików YAML określających artefakty, zasoby i konfigurację projektu usługi Databricks. Databricks CLI może następnie służyć do weryfikowania, wdrażania i uruchamiania bundle przy użyciu tych plików YAML bundle. Projekty pakietów można uruchamiać ze środowisk IDE, terminali lub bezpośrednio w usłudze Databricks.
Pakiety można tworzyć ręcznie lub na podstawie szablonu. Interfejs wiersza polecenia usługi Databricks udostępnia szablony domyślne dla prostych przypadków użycia, ale w przypadku bardziej szczegółowych lub złożonych zadań można utworzyć niestandardowe szablony pakietów w celu zaimplementowania najlepszych rozwiązań zespołu i zachowania spójności typowych konfiguracji.
Aby uzyskać więcej informacji na temat konfiguracji YAML używanej do wyrażania pakietów automatyzacji deklaratywnej, zobacz Deklaratywne konfiguracje pakietów automatyzacji.
Co należy zainstalować, aby korzystać z pakietów?
Pakiety deklaratywnej automatyzacji są funkcją interfejsu CLI Databricks. Pakiety są kompilowane lokalnie, a następnie używasz interfejsu wiersza polecenia Databricks do wdrażania pakietów w docelowych zdalnych obszarach roboczych i uruchamiania przepływów pracy pakietów w tych obszarach z poziomu wiersza polecenia.
Uwaga / Notatka
Jeśli chcesz używać pakietów w obszarze roboczym, nie musisz instalować Databricks CLI. Zobacz Współpraca nad pakietami w obszarze roboczym.
Aby tworzyć, wdrażać i uruchamiać pakiety w obszarach roboczych usługi Azure Databricks:
Zdalne obszary robocze usługi Databricks muszą mieć włączone pliki obszaru roboczego. Jeśli używasz środowiska Databricks Runtime w wersji 11.3 LTS lub nowszej, ta funkcja jest domyślnie włączona.
Musisz zainstalować Databricks CLI, w wersji v0.218.0 lub nowszej. Aby zainstalować lub zaktualizować interfejs wiersza polecenia usługi Databricks, zobacz Instalowanie lub aktualizowanie interfejsu wiersza polecenia usługi Databricks.
Databricks zaleca regularne aktualizowanie do najnowszej wersji interfejsu wiersza polecenia, aby skorzystać z nowych funkcji pakietu. Aby znaleźć wersję zainstalowanego Databricks CLI, uruchom następujące polecenie:
databricks --versionSkonfigurowano interfejs wiersza polecenia usługi Databricks w celu uzyskiwania dostępu do obszarów roboczych usługi Databricks. Usługa Databricks zaleca skonfigurowanie dostępu przy użyciu uwierzytelniania użytkownika-maszyny (U2M) OAuth, które opisano w temacie Konfigurowanie dostępu do obszaru roboczego. Inne metody uwierzytelniania opisano w temacie Authentication for Deklaratative Automation Bundles (Uwierzytelnianie dla pakietów automatyzacji deklaratywnej).
Jak rozpocząć pracę z pakietami?
Najszybszym sposobem rozpoczęcia tworzenia pakietów lokalnych jest użycie szablonu projektu pakietu. Utwórz swój pierwszy projekt w pakiecie przy użyciu polecenia bundle init w interfejsie wiersza polecenia Databricks. To polecenie przedstawia wybór domyślnych szablonów pakietów udostępnianych przez usługę Databricks i zadaje serię pytań w celu zainicjowania zmiennych projektu.
databricks bundle init
Tworzenie pakietu to pierwszy krok w cyklu życia pakietu. Następnie opracuj swój pakiet, definiując ustawienia pakietu i zasoby w databricks.yml oraz plikach konfiguracji zasobów. Na koniec zweryfikuj i wdróż pakiet, a następnie uruchom przepływy pracy.
Napiwek
Przykłady konfiguracji pakietu można znaleźć w przykładach konfiguracji pakietu i repozytorium Przykłady pakietów w usłudze GitHub.
Następne kroki
- Utwórz pakiet, który wdraża notes w obszarze roboczym usługi Azure Databricks, a następnie uruchamia ten notes wdrożony w zadaniu lub potoku usługi Azure Databricks. Zobacz Tworzenie zadania przy użyciu pakietów automatyzacji deklaratywnej i opracowywanie potoków przy użyciu pakietów deklaratywnej automatyzacji.
- Utwórz pakiet, który wdraża i uruchamia stack technologiczny MLOps. Zobacz Deklaratywne pakiety automatyzacji dla platform MLOps.
- Rozpocznij wdrażanie pakietu w ramach workflowu CI/CD (ciągłej integracji/ciągłego wdrażania) w GitHub. Zobacz Uruchomienie przepływu pracy CI/CD z pakietem, który wykonuje aktualizację potoku.
- Utwórz pakiet, który buduje, wdraża i wywołuje plik typu wheel dla Pythona. Zobacz Tworzenie pliku wheel języka Python przy użyciu pakietów deklaratywnej automatyzacji.
- Wygeneruj konfigurację w pakiecie dla zadania lub innego zasobu w obszarze roboczym, a następnie powiąż ją z zasobem w obszarze roboczym, aby konfiguracja była zsynchronizowana. Zobacz tworzenie pakietów usługi Databricks i powiązanie wdrożenia pakietu usługi Databricks.
- Utwórz i wdróż pakiet w obszarze roboczym. Zobacz Współpraca nad pakietami w obszarze roboczym.
- Utwórz szablon niestandardowy, którego ty i inni mogą użyć do utworzenia pakietu. Szablon niestandardowy może zawierać domyślne uprawnienia, główne zasady usługi i niestandardową konfigurację CI/CD. Zobacz szablony projektów dla deklaratywnych pakietów automatyzacji.
- Migrowanie z dbx do deklaratywnych pakietów automatyzacji. Zobacz Migrowanie z bazy danych dbx do pakietów.
- Poznaj najnowsze główne nowe funkcje wydane dla pakietów deklaratywnej automatyzacji. Zobacz informacje o wydaniu funkcji deklaratywnych pakietów automatyzacji.