Połączenie usługi Databricks dla języka R
Uwaga
W tym artykule opisano sparklyr integrację z usługą Databricks Połączenie dla środowiska Databricks Runtime 13.0 lub nowszego. Ta integracja nie jest dostarczana przez usługę Databricks ani bezpośrednio obsługiwana przez usługę Databricks.
W przypadku pytań przejdź do społeczności Posit.
Aby zgłosić problemy, przejdź do sekcji sparklyr Problemy repozytorium w usłudze GitHub.
Aby uzyskać więcej informacji, zobacz Databricks Połączenie v2 w sparklyr dokumentacji.
W tym artykule pokazano, jak szybko rozpocząć pracę z usługą Databricks Połączenie przy użyciu języków R, sparklyri RStudio Desktop.
- Aby zapoznać się z wersją języka Python tego artykułu, zobacz Databricks Połączenie dla języka Python.
- Aby zapoznać się z wersją tego artykułu, zobacz Databricks Połączenie for Scala.
Usługa Databricks Połączenie umożliwia łączenie popularnych środowisk IDE, takich jak RStudio Desktop, serwery notesów i inne aplikacje niestandardowe do klastrów usługi Azure Databricks. Zobacz Co to jest usługa Databricks Połączenie?.
Samouczek
W tym samouczku są używane programy RStudio Desktop i Python 3.10. Jeśli jeszcze ich nie zainstalowano, zainstaluj programy R i RStudio Desktop i Python 3.10.
Aby uzyskać dodatkowe informacje na temat tego samouczka, zobacz sekcję "Databricks Połączenie" platformy Spark Połączenie i databricks Połączenie v2 w witrynie sparklyr internetowej.
Wymagania
Aby ukończyć ten samouczek, musisz spełnić następujące wymagania:
- Docelowy obszar roboczy i klaster usługi Azure Databricks muszą spełniać wymagania dotyczące konfiguracji klastra dla usługi Databricks Połączenie.
- Musisz mieć dostępny identyfikator klastra. Aby uzyskać identyfikator klastra, w obszarze roboczym kliknij pozycję Obliczenia na pasku bocznym, a następnie kliknij nazwę klastra. Na pasku adresu przeglądarki internetowej skopiuj ciąg znaków między
clustersiconfigurationw adresie URL.
Krok 1. Tworzenie osobistego tokenu dostępu
Uwaga
Usługa Databricks Połączenie na potrzeby uwierzytelniania języka R obecnie obsługuje tylko osobiste tokeny dostępu usługi Azure Databricks.
W tym samouczku używane jest uwierzytelnianie osobistego tokenu dostępu usługi Azure Databricks do uwierzytelniania w obszarze roboczym usługi Azure Databricks.
Jeśli masz już osobisty token dostępu usługi Azure Databricks, przejdź do kroku 2. Jeśli nie masz już osobistego tokenu dostępu usługi Azure Databricks, możesz wykonać ten krok bez wpływu na inne osobiste tokeny dostępu usługi Azure Databricks na koncie użytkownika.
Aby utworzyć osobisty token dostępu:
- W obszarze roboczym usługi Azure Databricks kliknij nazwę użytkownika usługi Azure Databricks na górnym pasku, a następnie wybierz pozycję Ustawienia z listy rozwijanej.
- Kliknij pozycję Deweloper.
- Obok pozycji Tokeny dostępu kliknij pozycję Zarządzaj.
- Kliknij pozycję Generuj nowy token.
- (Opcjonalnie) Wprowadź komentarz, który pomaga zidentyfikować ten token w przyszłości i zmienić domyślny okres istnienia tokenu na 90 dni. Aby utworzyć token bez okresu istnienia (niezalecane), pozostaw puste pole Okres istnienia (dni) (puste).
- Kliknij pozycję Generate (Generuj).
- Skopiuj wyświetlony token do bezpiecznej lokalizacji, a następnie kliknij przycisk Gotowe.
Uwaga
Pamiętaj, aby zapisać skopiowany token w bezpiecznej lokalizacji. Nie udostępniaj skopiowanego tokenu innym osobom. W przypadku utraty skopiowanego tokenu nie można wygenerować tego samego tokenu. Zamiast tego należy powtórzyć tę procedurę, aby utworzyć nowy token. Jeśli utracisz skopiowany token lub uważasz, że token został naruszony, usługa Databricks zdecydowanie zaleca natychmiastowe usunięcie tego tokenu z obszaru roboczego, klikając ikonę kosza (Odwołaj) obok tokenu na stronie Tokeny dostępu.
Jeśli nie możesz utworzyć lub użyć tokenów w obszarze roboczym, może to być spowodowane tym, że administrator obszaru roboczego wyłączył tokeny lub nie udzielił Ci uprawnień do tworzenia lub używania tokenów. Zobacz administratora obszaru roboczego lub następujące elementy:
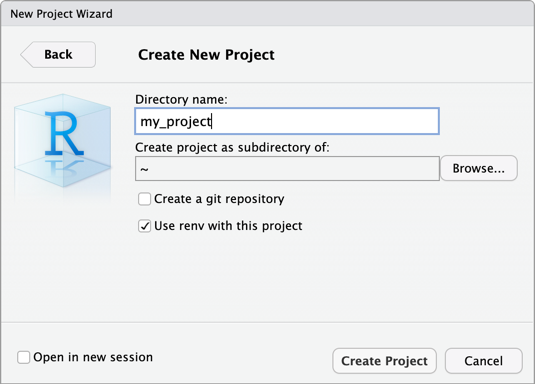
Krok 2. Tworzenie projektu
- Uruchom program RStudio Desktop.
- W menu głównym kliknij pozycję Plik > nowy projekt.
- Wybierz pozycję Nowy katalog.
- Wybierz pozycję Nowy projekt.
- W obszarze Nazwa katalogu i Utwórz projekt jako podkatalog wprowadź nazwę nowego katalogu projektu i miejsce utworzenia nowego katalogu projektu.
- Wybierz pozycję Użyj ponownego odwzorowania z tym projektem. Jeśli zostanie wyświetlony monit o zainstalowanie zaktualizowanej
renvwersji pakietu, kliknij przycisk Tak. - Kliknij pozycję Create Project (Utwórz projekt).
Krok 3. Dodawanie pakietu usługi Databricks Połączenie i innych zależności
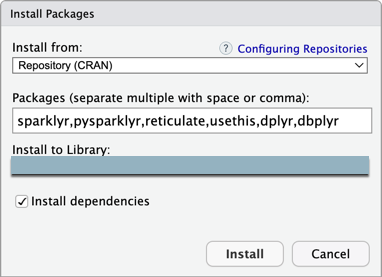
W menu głównym programu RStudio Desktop kliknij pozycję Narzędzia > Zainstaluj pakiety.
Pozostaw opcję Zainstaluj z zestawu na wartość Repository (CRAN).
W obszarze Pakiety wprowadź następującą listę pakietów, które są wymaganiami wstępnymi dla pakietu Połączenie usługi Databricks i tego samouczka:
sparklyr,pysparklyr,reticulate,usethis,dplyr,dbplyrPozostaw opcję Zainstaluj w bibliotece ustawioną na środowisko wirtualne języka R.
Upewnij się, że wybrano opcję Zainstaluj zależności .
Kliknij przycisk Zainstaluj.
Po wyświetleniu monitu w widoku Konsoli (Wyświetl > przenieś fokus do konsoli), aby kontynuować instalację, wprowadź .
YPakietysparklyripysparklyri oraz ich zależności są instalowane w środowisku wirtualnym języka R.W okienku Konsola użyj polecenia
reticulate, aby zainstalować język Python, uruchamiając następujące polecenie. (Usługa Databricks Połączenie dla języka R wymagareticulate, aby język Python był najpierw zainstalowany). W poniższym poleceniu zastąp3.10wersję główną i pomocniczą wersji języka Python zainstalowaną w klastrze usługi Azure Databricks. Aby znaleźć tę wersję główną i pomocniczą, zobacz sekcję "Środowisko systemowe" informacji o wersji środowiska Databricks Runtime klastra w wersjach i zgodności środowiska Databricks Runtime.reticulate::install_python(version = "3.10")W okienku Konsola zainstaluj pakiet usługi Databricks Połączenie, uruchamiając następujące polecenie. W poniższym poleceniu zastąp element
13.3wersją środowiska Databricks Runtime zainstalowaną w klastrze usługi Azure Databricks. Aby znaleźć tę wersję, na stronie szczegółów klastra w obszarze roboczym usługi Azure Databricks na karcie Konfiguracja zobacz pole Wersja środowiska uruchomieniowego usługi Databricks.pysparklyr::install_databricks(version = "13.3")Jeśli nie znasz wersji środowiska Databricks Runtime dla klastra lub nie chcesz go wyszukać, możesz zamiast tego uruchomić następujące polecenie i
pysparklyrwykona zapytanie względem klastra, aby określić poprawną wersję środowiska Databricks Runtime do użycia:pysparklyr::install_databricks(cluster_id = "<cluster-id>")Jeśli chcesz, aby projekt łączył się później z innym klastrem, który ma tę samą wersję środowiska Databricks Runtime niż określona przez Ciebie,
pysparklyrbędzie używać tego samego środowiska języka Python. Jeśli nowy klaster ma inną wersję środowiska Databricks Runtime, należy ponownie uruchomićpysparklyr::install_databrickspolecenie z nową wersją środowiska Databricks Runtime lub identyfikatorem klastra.
Krok 4. Ustawianie zmiennych środowiskowych dla adresu URL obszaru roboczego, tokenu dostępu i identyfikatora klastra
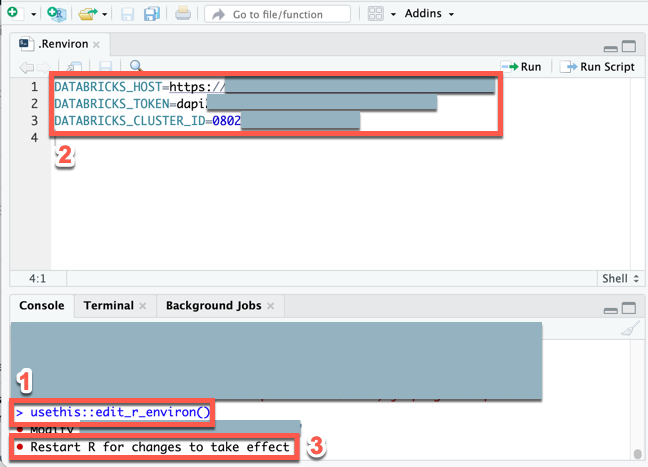
Usługa Databricks nie zaleca kodowania poufnych lub zmieniających się wartości, takich jak adres URL obszaru roboczego usługi Azure Databricks, osobisty token dostępu usługi Azure Databricks lub identyfikator klastra usługi Azure Databricks do skryptów języka R. Zamiast tego należy przechowywać te wartości oddzielnie, na przykład w lokalnych zmiennych środowiskowych. W tym samouczku jest używana wbudowana obsługa programu RStudio Desktop do przechowywania zmiennych środowiskowych w .Renviron pliku.
.RenvironUtwórz plik do przechowywania zmiennych środowiskowych, jeśli ten plik jeszcze nie istnieje, a następnie otwórz ten plik do edycji: w konsoli programu RStudio Desktop uruchom następujące polecenie:usethis::edit_r_environ()W wyświetlonym
.Renvironpliku (Wyświetl > przenieś fokus do źródła) wprowadź następującą zawartość. W tej zawartości zastąp następujące symbole zastępcze:- Zastąp
<workspace-url>ciąg adresem URL obszaru roboczego, na przykładhttps://adb-1234567890123456.7.azuredatabricks.net. - Zastąp
<personal-access-token>element osobistym tokenem dostępu usługi Azure Databricks z kroku 1. - Zastąp
<cluster-id>element identyfikatorem klastra z wymagań tego samouczka.
DATABRICKS_HOST=<workspace-url> DATABRICKS_TOKEN=<personal-access-token> DATABRICKS_CLUSTER_ID=<cluster-id>- Zastąp
Zapisz plik
.Renviron.Załaduj zmienne środowiskowe do języka R: w menu głównym kliknij pozycję Uruchom ponownie sesję > języka R.
Krok 5. Dodawanie kodu
W menu głównym programu RStudio Desktop kliknij pozycję Plik > nowy plik > R Script.
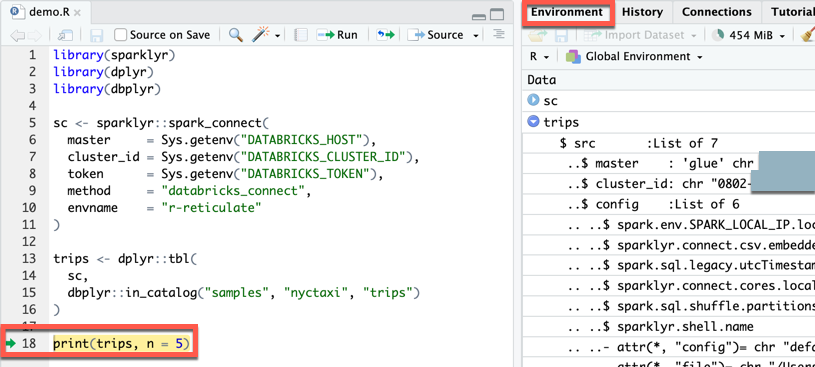
Wprowadź następujący kod w pliku, a następnie zapisz plik (Zapisz plik>) jako
demo.R:library(sparklyr) library(dplyr) library(dbplyr) sc <- sparklyr::spark_connect( master = Sys.getenv("DATABRICKS_HOST"), cluster_id = Sys.getenv("DATABRICKS_CLUSTER_ID"), token = Sys.getenv("DATABRICKS_TOKEN"), method = "databricks_connect", envname = "r-reticulate" ) trips <- dplyr::tbl( sc, dbplyr::in_catalog("samples", "nyctaxi", "trips") ) print(trips, n = 5)
Krok 6. Uruchamianie kodu
Na pulpicie programu RStudio na pasku narzędzi pliku
demo.Rkliknij pozycję Źródło.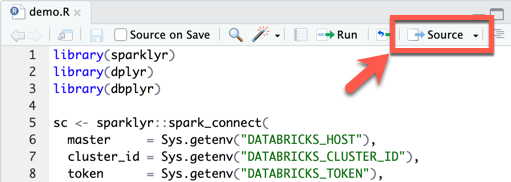
W konsoli pojawi się pięć pierwszych wierszy
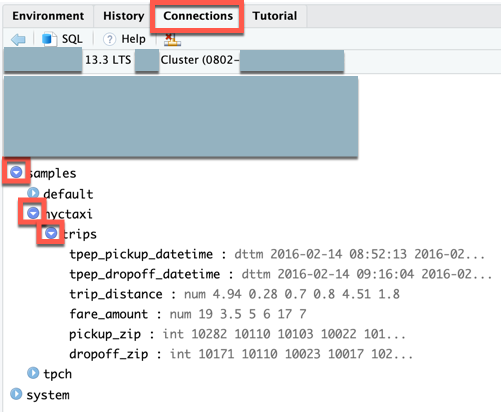
tripstabeli.W widoku Połączenie ions (View > Show Połączenie ions) możesz eksplorować dostępne wykazy, schematy, tabele i widoki.
Krok 7. Debugowanie kodu
demo.RW pliku kliknij gutter obok, aby ustawićprint(trips, n = 5)punkt przerwania.- Na pasku narzędzi
demo.Rpliku kliknij pozycję Źródło. - Gdy kod wstrzymuje działanie w punkcie przerwania, możesz sprawdzić zmienną w widoku Środowisko (Wyświetl > pokaż środowisko).
- W menu głównym kliknij pozycję Debuguj > kontynuuj.
- W konsoli pojawi się pięć pierwszych wierszy
tripstabeli.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla