Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga
W tym artykule opisano usługę Databricks Connect dla środowiska Databricks Runtime 13.3 LTS lub nowszego.
Databricks Connect to biblioteka klienta środowiska Databricks Runtime, która umożliwia łączenie się z Azure Databricks obliczeniami z środowisk IDE, takich jak Visual Studio Code, PyCharm i IntelliJ IDEA, notesy i dowolna aplikacja niestandardowa, aby umożliwić nowe interaktywne środowiska użytkownika oparte na Azure Databricks Lakehouse.
Program Databricks Connect jest dostępny dla następujących języków:
Co mogę zrobić za pomocą usługi Databricks Connect?
Za pomocą usługi Databricks Connect możesz napisać kod przy użyciu interfejsów API platformy Spark i uruchomić go zdalnie na komputerze Azure Databricks zamiast w lokalnej sesji platformy Spark.
Interaktywne programowanie i debugowanie z dowolnego środowiska IDE. Usługa Databricks Connect umożliwia deweloperom opracowywanie i debugowanie kodu w obliczeniach usługi Databricks przy użyciu natywnych funkcji uruchamiania i debugowania środowiska IDE. Rozszerzenie Databricks Visual Studio Code używa narzędzia Databricks Connect w celu zapewnienia wbudowanego debugowania kodu użytkownika w usłudze Databricks.
Tworzenie interaktywnych aplikacji danych. Podobnie jak sterownik JDBC, biblioteka Databricks Connect może być osadzona w dowolnej aplikacji w celu interakcji z usługą Databricks. Usługa Databricks Connect zapewnia pełną ekspresyjność Python za pośrednictwem programu PySpark, eliminując niezgodność języka programowania SQL i umożliwiając uruchamianie wszystkich przekształceń danych za pomocą platformy Spark w skalowalnych obliczeniach bezserwerowych usługi Databricks.
Jak to działa?
Usługa Databricks Connect jest oparta na rozwiązaniu Spark Connect typu open source, który ma oddzieloną architekturę client-server dla platformy Apache Spark, która umożliwia zdalną łączność z klastrami Spark przy użyciu interfejsu API ramki danych. Podstawowy protokół korzysta z nierozwiązanych planów logicznych platformy Spark i narzędzia Apache Arrow w oparciu o gRPC. Interfejs API klienta został zaprojektowany jako lekki, aby można go było osadzać wszędzie: na serwerach aplikacji, w środowiskach IDE, notesach i językach programowania.
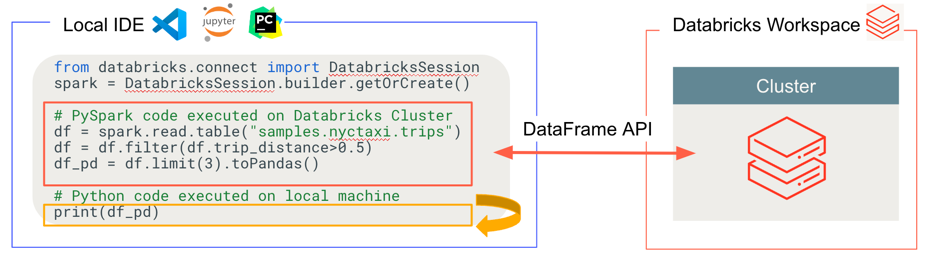
- Ogólny kod działa lokalnie: Kod Python i Scala są uruchamiane po stronie klienta, co umożliwia debugowanie interaktywne. Cały kod jest wykonywany lokalnie, podczas gdy cały kod Platformy Spark nadal działa w klastrze zdalnym.
-
API DataFrame są uruchamiane na platformie obliczeniowej Databricks. Wszystkie przekształcenia danych są konwertowane na plany platformy Spark i uruchamiane na obliczeniach usługi Databricks za pośrednictwem zdalnej sesji platformy Spark. Są one widoczne na lokalnym kliencie, gdy używasz poleceń, takich jak
collect(),show(),toPandas(). -
Kod UDF jest uruchamiany w obliczeniach usługi Databricks: Zdefiniowane lokalnie funkcje użytkownika są serializowane i przesyłane do klastra, gdzie kod UDF jest uruchamiany. Interfejsy API uruchamiające kod użytkownika w usłudze Databricks obejmują: funkcje definiowane przez użytkownika,
foreach,foreachBatch, itransformWithState. - W przypadku zarządzania zależnościami:
- Zainstaluj zależności aplikacji na komputerze lokalnym. Uruchamiają się lokalnie i muszą być zainstalowane w ramach twojego projektu, na przykład jako część środowiska wirtualnego Pythona.
- Zainstaluj zależności UDF na Databricks. Zobacz Zarządzanie zależnościami UDF (funkcji zdefiniowanej przez użytkownika).
Jak są powiązane usługi Databricks Connect i Spark Connect?
Spark Connect to protokół oparty na gRPC typu open source w ramach platformy Apache Spark, który umożliwia zdalne wykonywanie obciążeń Platformy Spark przy użyciu interfejsu API ramki danych.
W przypadku środowiska Databricks Runtime 13.3 LTS lub nowszego usługa Databricks Connect to rozszerzenie Spark Connect z dodatkowymi funkcjami i modyfikacjami w celu obsługi pracy z trybami obliczeniowymi Databricks i Unity Catalog.
Dodatkowe zasoby
Zapoznaj się z następującymi samouczkami, aby szybko rozpocząć tworzenie rozwiązań usługi Databricks Connect:
- Samouczek klasycznych obliczeń z użyciem Databricks Connect dla Python
- Samouczek korzystania z Databricks Connect do serverless compute w Pythonie
- Samouczek dotyczący klasycznych obliczeń w Databricks Connect dla Scali
- Samouczek dotyczący obliczeń bezserwerowych w usłudze Databricks Connect dla języka Scala
- Samouczek dotyczący programu Databricks Connect dla języka R
Aby wyświetlić przykładowe aplikacje korzystające z narzędzia Databricks Connect, zobacz repozytorium GitHub przykłady zawierające następujące przykłady: