Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten samouczek przeprowadzi Cię przez proces konfigurowania rozszerzenia Databricks dla Visual Studio Code, a następnie uruchamiania Pythona w klastrze Azure Databricks oraz jako zadania w Azure Databricks w zdalnym obszarze roboczym. Zobacz rozszerzenie Databricks dla Visual Studio Code.
Wymagania
Ten samouczek wymaga:
- Zainstalowano rozszerzenie usługi Databricks dla Visual Studio Code. Zobacz Install the Databricks extension for Visual Studio Code (Instalowanie rozszerzenia usługi Databricks).
- Do użycia jest zdalny klaster Azure Databricks. Zanotuj nazwę klastra. Aby wyświetlić dostępne klastry, na pasku bocznym obszaru roboczego Azure Databricks kliknij pozycję Compute. Zobacz Compute.
Krok 1. Tworzenie nowego projektu usługi Databricks
W tym kroku utworzysz nowy projekt usługi Databricks i skonfigurujesz połączenie ze zdalnym obszarem roboczym Azure Databricks.
- Uruchom Visual Studio Code, a następnie kliknij pozycję Plik > Otwórz folder i otwórz pusty folder na lokalnej maszynie dewelopera.
- Na pasku bocznym kliknij ikonę logo Databricks. Spowoduje to otwarcie rozszerzenia usługi Databricks.
- W widoku Konfiguracja kliknij pozycję Utwórz konfigurację.
- Zostanie otwarta paleta poleceń do skonfigurowania obszaru roboczego usługi Databricks. W polu Host usługi Databricks wprowadź lub wybierz adres URL dla poszczególnych obszarów roboczych, na przykład
https://adb-1234567890123456.7.azuredatabricks.net. - Wybierz profil uwierzytelniania dla projektu. Zobacz Konfigurowanie autoryzacji dla rozszerzenia usługi Databricks dla Visual Studio Code.
Krok 2. Dodawanie informacji o klastrze do rozszerzenia usługi Databricks i uruchamianie klastra
Mając już otwarty widok Konfiguracja, kliknij Wybierz klaster lub ikonę koła zębatego (Konfiguruj klaster).
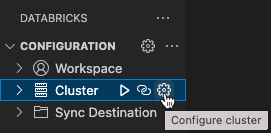
W palecie poleceń wybierz nazwę utworzonego wcześniej klastra.
Kliknij ikonę odtwarzania (Uruchom klaster), jeśli jeszcze nie został uruchomiony.
Krok 3. Tworzenie i uruchamianie kodu Python
Utwórz lokalny plik kodu Python: na pasku bocznym kliknij ikonę (Explorer).
W menu głównym kliknij pozycję Plik > Nowy plik i wybierz plik Python. Nadaj plikowi nazwę demo.py i zapisz go w katalogu głównym projektu.
Dodaj następujący kod do pliku, a następnie zapisz go. Ten kod tworzy i wyświetla zawartość podstawowej ramki danych PySpark:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Kliknij ikonę Uruchom w usłudze Databricks obok listy kart edytora, a następnie kliknij pozycję Przekaż i uruchom plik. Wynik jest wyświetlany w widoku Konsola debugowania.
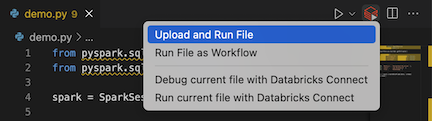
Alternatywnie w widoku Eksploratora kliknij prawym przyciskiem myszy
demo.pyplik, a następnie kliknij Uruchom w usłudze Databricks>Przekaż i uruchom plik.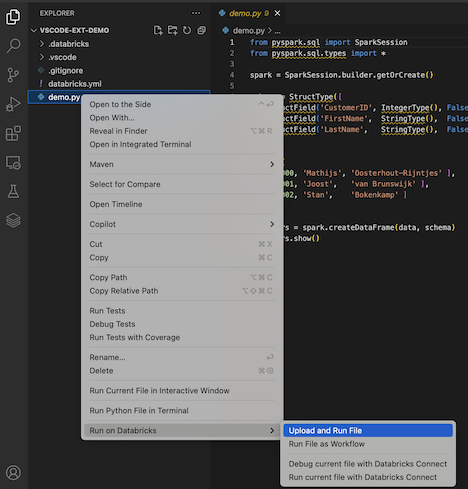
Krok 4. Uruchamianie kodu jako zadania
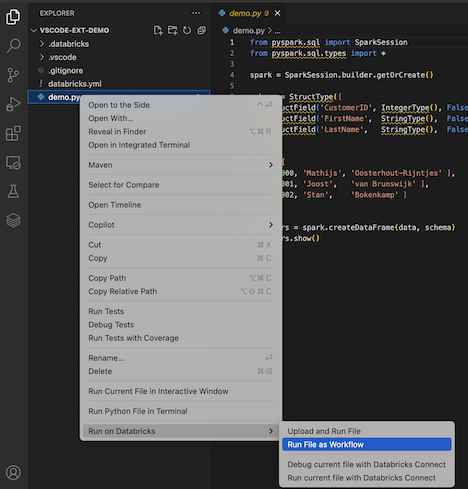
Aby uruchomić demo.py jako zadanie, kliknij ikonę Uruchom w Databricks obok listy kart edytora, a następnie kliknij pozycję Uruchom plik jako przepływ działania. Dane wyjściowe są wyświetlane na osobnej karcie edytora obok edytora demo.py plików.
![]()
Alternatywnie kliknij prawym przyciskiem myszy demo.py plik w panelu Eksplorator, a następnie wybierz polecenie Uruchom w usłudze Databricks>Uruchom plik jako przepływ pracy.
Następne kroki
Teraz, po pomyślnym użyciu rozszerzenia usługi Databricks dla Visual Studio Code w celu przekazania lokalnego pliku Python i uruchomienia go zdalnie, możesz również:
- Zapoznaj się z zasobami i zmiennymi pakietów deklaratywnej automatyzacji, korzystając z interfejsu użytkownika rozszerzenia. Zobacz funkcje rozszerzenia Deklaratywnych Pakietów Automatyzacji.
- Uruchom lub debuguj kod Python za pomocą usługi Databricks Connect. Zobacz Debugowanie kodu przy użyciu Databricks Connect dla rozszerzenia Databricks w Visual Studio Code.
- Uruchom plik lub notatnik jako zadanie Azure Databricks. Zobacz Uruchom plik w klastrze lub plik, notes jako zadanie w Azure Databricks przy użyciu rozszerzenia Databricks dla Visual Studio Code.
- Uruchamianie testów za pomocą polecenia
pytest. Zobacz Uruchom Python testy przy użyciu rozszerzenia usługi Databricks dla Visual Studio Code.