Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Skompiluj agenta sztucznej inteligencji i wdróż go przy użyciu usługi Databricks Apps. Usługa Databricks Apps zapewnia pełną kontrolę nad kodem agenta, konfiguracją serwera i przepływem pracy wdrażania. Takie podejście jest idealne, gdy potrzebujesz niestandardowego zachowania serwera, obsługi wersji opartej na usłudze Git lub lokalnego programowania w środowisku IDE.
Wskazówka
Jeśli agent używa tylko narzędzi hostowanych Azure Databricks i nie wymaga niestandardowej logiki między wywołaniami narzędzi, możesz użyć pętli Supervisor API (beta) aby umożliwić Azure Databricks zarządzanie pętlą agenta.
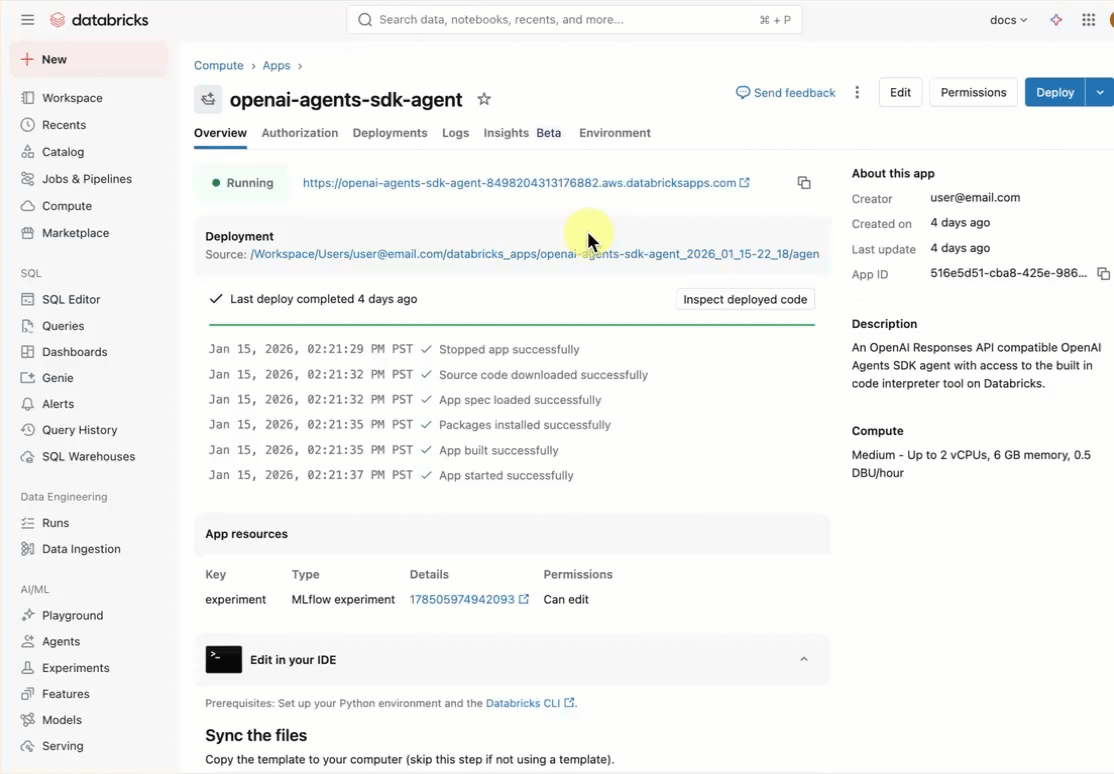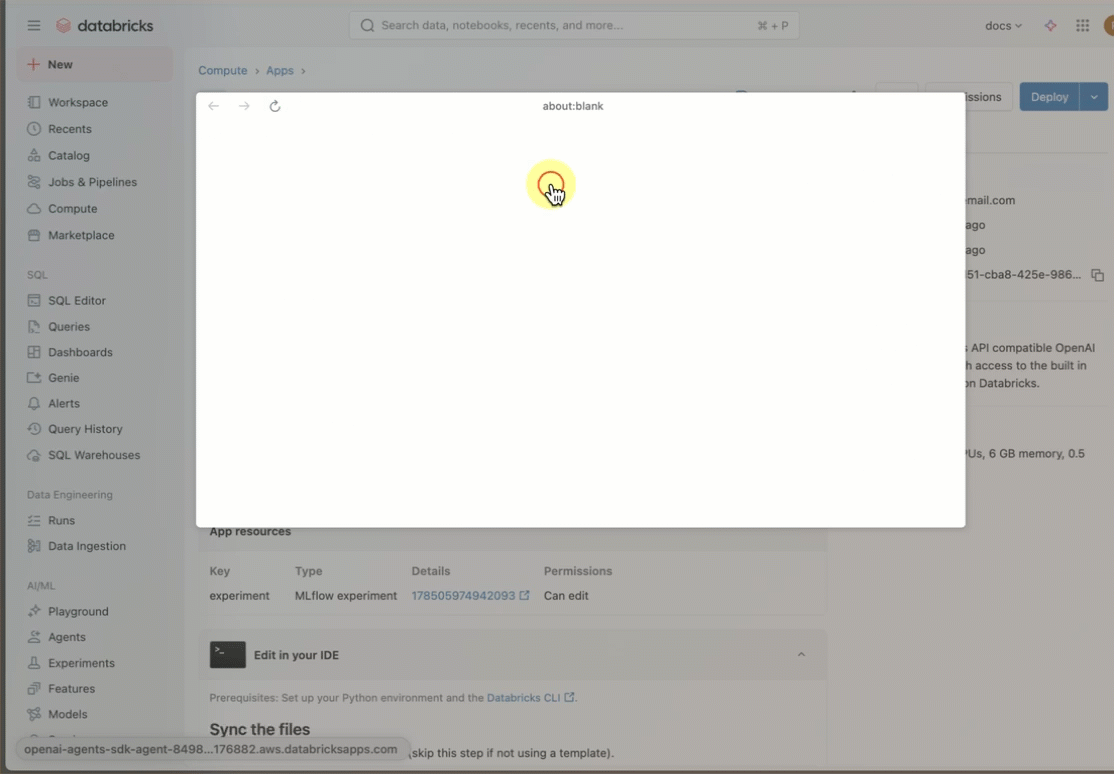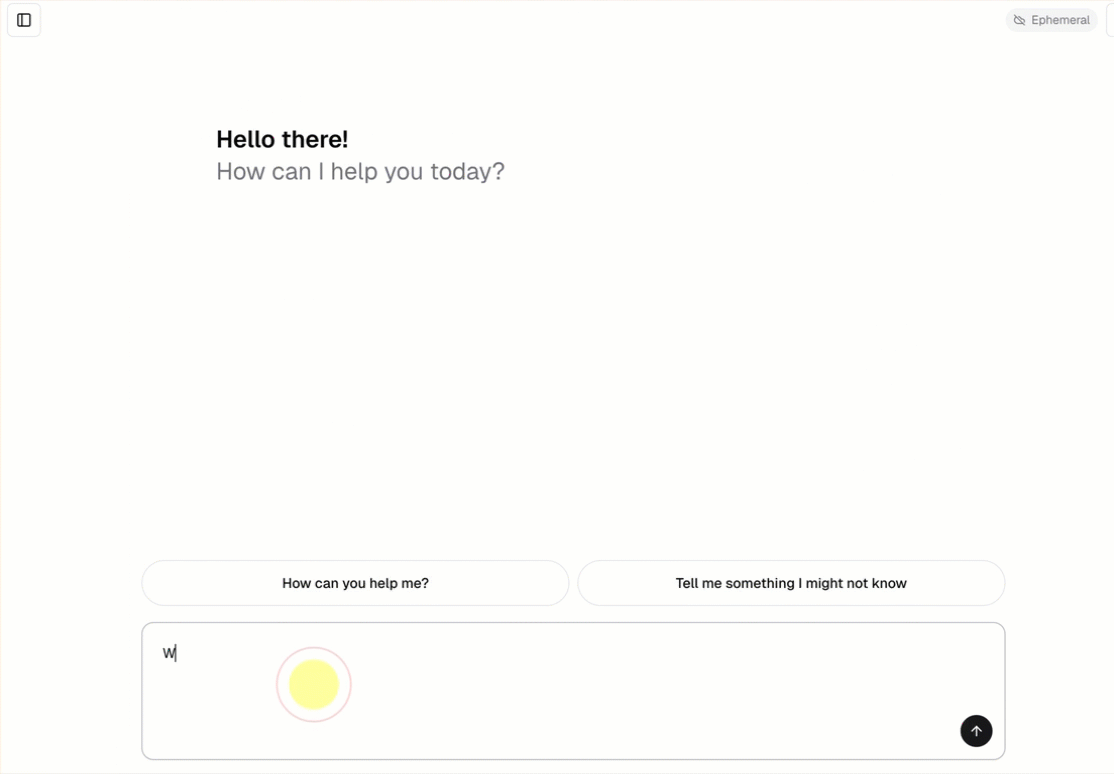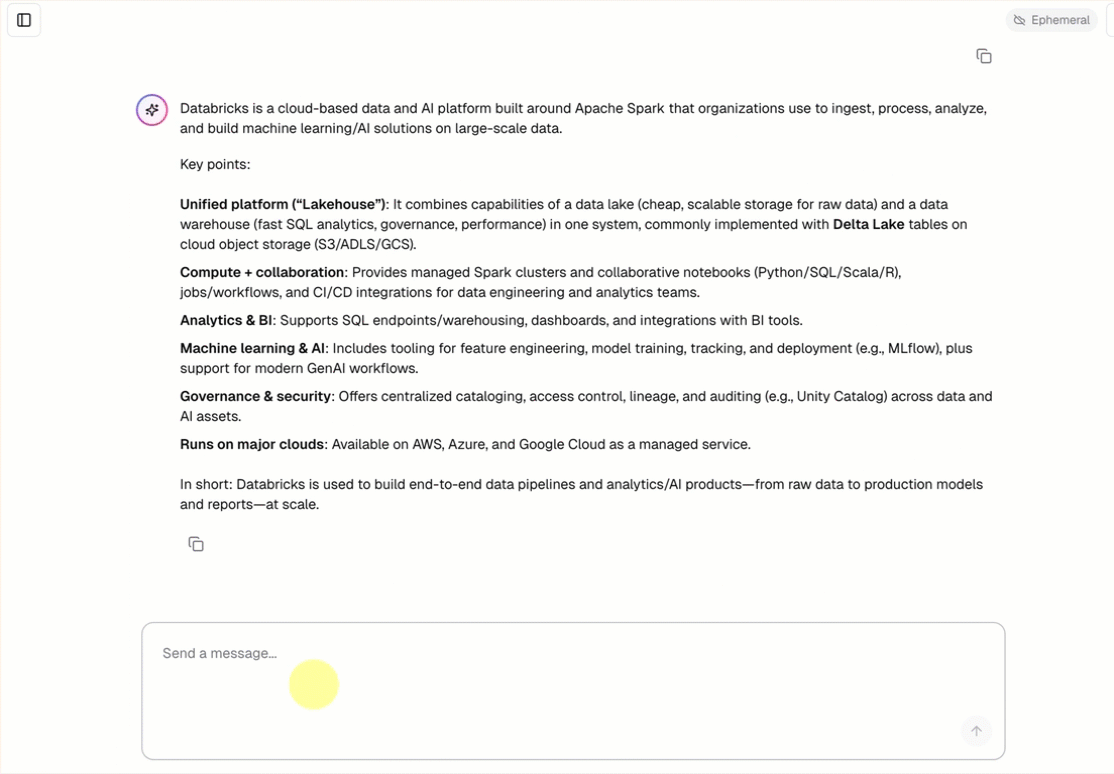
Każdy szablon agenta konwersacji zawiera wbudowany interfejs użytkownika czatu (pokazany powyżej) bez konieczności dodatkowej konfiguracji. Interfejs użytkownika czatu obsługuje odpowiedzi przesyłane strumieniowo, renderowanie Markdown, uwierzytelnianie w Databricks i opcjonalne archiwizowanie historii czatów.
Wymagania
Włącz aplikacje usługi Databricks w obszarze roboczym. Zobacz Konfigurowanie obszaru roboczego usługi Databricks Apps i środowiska programistycznego.
Krok 1. Klonowanie szablonu aplikacji agenta
Rozpocznij pracę przy użyciu wstępnie utworzonego szablonu agenta z repozytorium szablonów aplikacji usługi Databricks.
Ten samouczek używa szablonu agent-openai-agents-sdk, który obejmuje:
- Agent utworzony przy użyciu zestawu SDK agenta OpenAI
- Kod początkowy dla aplikacji agenta z interfejsem API REST konwersacji i interaktywnym interfejsem użytkownika czatu
- Kod do oceny agenta przy użyciu biblioteki MLflow
Wybierz jedną z następujących ścieżek, aby skonfigurować szablon:
Interfejs użytkownika obszaru roboczego
Zainstaluj szablon aplikacji przy użyciu interfejsu użytkownika obszaru roboczego. To instaluje aplikację i wdraża ją do zasobu obliczeniowego w twoim obszarze roboczym. Następnie można zsynchronizować pliki aplikacji ze środowiskiem lokalnym w celu dalszego programowania.
W obszarze roboczym usługi Databricks kliknij pozycję + Nowa>aplikacja.
Kliknij pozycję Agenci>Niestandardowy Agent (OpenAI SDK).
Utwórz nowy eksperyment MLflow o nazwie
openai-agents-templatei ukończ resztę konfiguracji w celu zainstalowania szablonu.Po utworzeniu aplikacji kliknij adres URL aplikacji, aby otworzyć interfejs użytkownika czatu.
Po utworzeniu aplikacji pobierz kod źródłowy na komputer lokalny, aby go dostosować:
Skopiuj pierwsze polecenie w obszarze Synchronizuj pliki
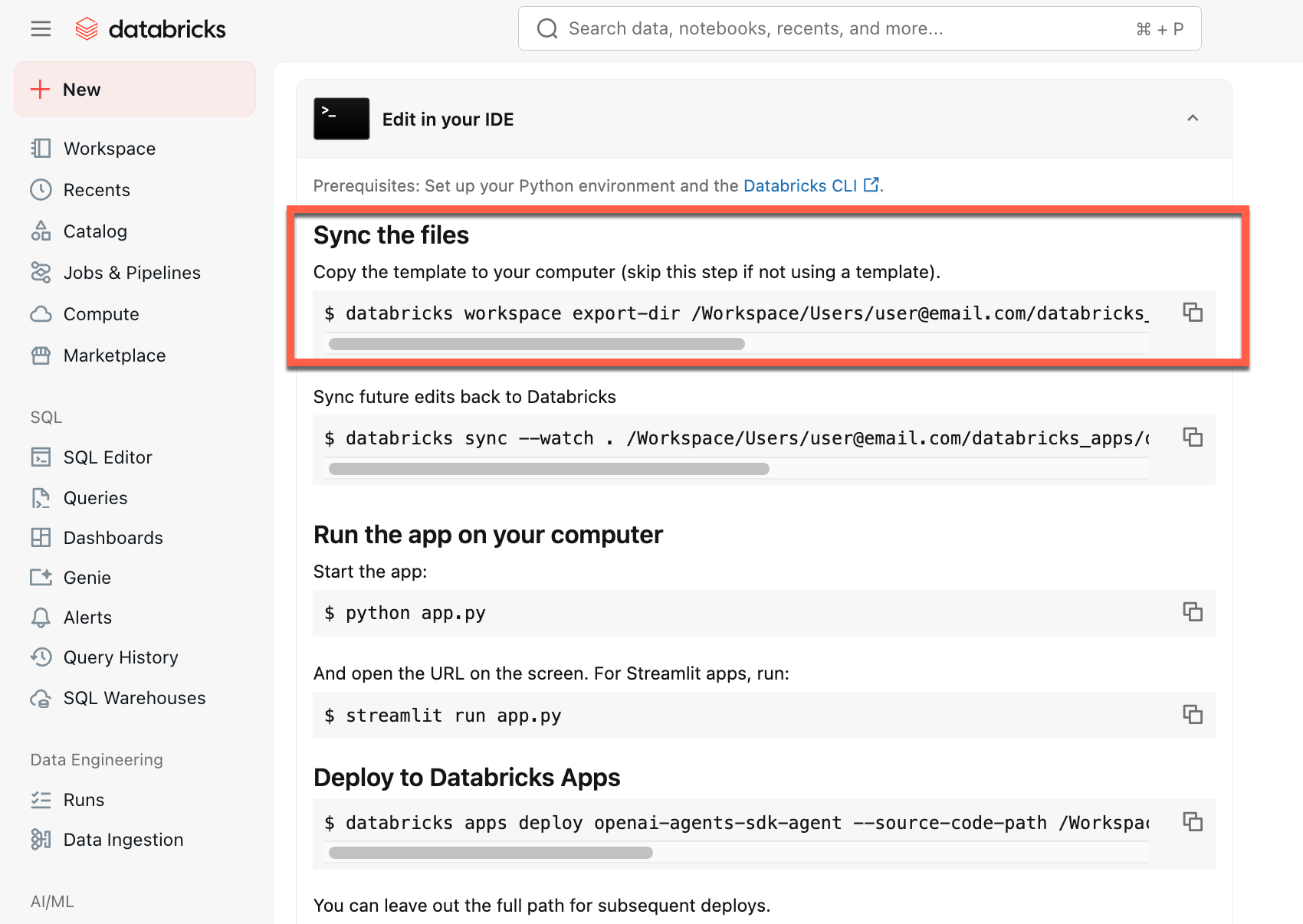
W terminalu lokalnym uruchom skopiowane polecenie.
Klonowanie z GitHub
Aby rozpocząć od środowiska lokalnego, sklonuj repozytorium szablonu agenta i otwórz agent-openai-agents-sdk katalog:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Krok 2. Omówienie aplikacji agenta
Szablon agenta demonstruje architekturę gotową do produkcji z tymi kluczowymi składnikami. Otwórz następujące sekcje, aby uzyskać więcej informacji na temat każdego składnika:

Otwórz następujące sekcje, aby uzyskać więcej informacji na temat każdego składnika:
 Wbudowana interfejs użytkownika czatu
Wbudowana interfejs użytkownika czatu
Szablon agenta automatycznie pobiera i uruchamia szablon aplikacji czatu jako fronton. Ten interfejs użytkownika czatu jest powiązany z tym samym wdrożeniem usługi Databricks Apps i obsługiwanym razem z agentem, dlatego nie jest wymagana żadna dodatkowa konfiguracja.
Interfejs użytkownika czatu można dostosować bezpośrednio w projekcie. Aby uzyskać więcej informacji na temat funkcji aplikacji do czatów, w tym sposobu włączania trwałej historii czatów i zbierania opinii użytkowników, zobacz Tworzenie i udostępnianie interfejsu użytkownika czatu w usłudze Databricks Apps.
 MLflow AgentServer
MLflow AgentServer
Asynchroniczny serwer FastAPI, który obsługuje żądania agenta z wbudowanym śledzeniem i obserwacją.
AgentServer udostępnia /responses punkt końcowy do wykonywania zapytań dotyczących agenta i automatycznie zarządza routingiem żądań, rejestrowaniem i obsługą błędów.

ResponsesAgent Interfejs
Usługa Databricks zaleca platformę MLflow ResponsesAgent do kompilowania agentów.
ResponsesAgent umożliwia tworzenie agentów z dowolnym frameworkiem innej firmy, a następnie integrację go z funkcjami sztucznej inteligencji Databricks dla niezawodnych możliwości rejestrowania, śledzenia, oceny, wdrażania i monitorowania.

Aby dowiedzieć się, jak utworzyć obiekt ResponsesAgent, zobacz przykłady w dokumentacji platformy MLflow — ResponsesAgent for Model Serving.
ResponsesAgent zapewnia następujące korzyści:
Zaawansowane możliwości agenta
- Obsługa wielu agentów
- Streaming danych wyjściowych: Przesyłaj dane wyjściowe w mniejszych fragmentach.
- Kompleksowa historia komunikatów wywołujących narzędzia: Zwracanie wielu wiadomości, w tym pośrednich komunikatów wywołujących narzędzia, dla lepszej jakości obsługi i zarządzania przebiegiem rozmów.
- obsługa potwierdzenia wywołania narzędzi
- Obsługa długotrwałych narzędzi
Usprawnione programowanie, wdrażanie i monitorowanie
-
Tworzenie agentów przy użyciu dowolnej platformy: Opakuj dowolnego istniejącego agenta przy użyciu interfejsu
ResponsesAgent, aby uzyskać wbudowaną zgodność z narzędziami AI Playground, Agent Evaluation i Agent Monitoring. - Typizowane interfejsy tworzenia: Pisanie kodu agenta z użyciem typizowanych klas języka Python, korzystając z zalet automatycznego uzupełniania w IDE oraz notebookach.
- Automatyczne śledzenie: narzędzie MLflow automatycznie agreguje przesyłane strumieniowo odpowiedzi w śladach w celu łatwiejszej oceny i wyświetlania.
-
Zgodne ze schematem OpenAI
Responses: zobacz OpenAI: Responses vs. ChatCompletion (Odpowiedzi vs. ChatCompletion).
-
Tworzenie agentów przy użyciu dowolnej platformy: Opakuj dowolnego istniejącego agenta przy użyciu interfejsu
 Zestaw SDK agentów OpenAI
Zestaw SDK agentów OpenAI
Szablon używa OpenAI Agents SDK jako frameworka agentów do zarządzania konwersacjami i orkiestracji narzędzi. Agentów można tworzyć przy użyciu dowolnej platformy. Kluczem jest opakowanie agenta przy użyciu interfejsu MLflow ResponsesAgent.
 Serwery MCP (Model Context Protocol)
Serwery MCP (Model Context Protocol)
Szablon łączy się z serwerami MCP usługi Databricks w celu udzielenia agentom dostępu do narzędzi i źródeł danych. Zobacz Protokół MCP (Model Context Protocol) w usłudze Databricks.
Tworzenie agentów przy użyciu asystentów kodowania wspomaganych przez sztuczną inteligencję
Usługa Databricks zaleca używanie asystentów kodowania sztucznej inteligencji, takich jak Claude, Cursor i Copilot do tworzenia agentów. Skorzystaj z podanych umiejętności agenta w pliku /.claude/skillsi AGENTS.md , aby pomóc asystentom sztucznej inteligencji zrozumieć strukturę projektu, dostępne narzędzia i najlepsze rozwiązania. Agenci mogą automatycznie odczytywać te pliki w celu tworzenia i wdrażania aplikacji usługi Databricks.
Krok 3. Dodawanie narzędzi do agenta
Nadaj agentowi możliwości, takie jak wykonywanie zapytań dotyczących baz danych, wyszukiwanie dokumentów lub wywoływanie zewnętrznych interfejsów API, łącząc je z serwerami MCP. Szablon agenta zawiera domyślne połączenie z serwerem MCP. Aby dodać więcej narzędzi, skonfiguruj dodatkowe serwery MCP w kodzie agenta i przyznaj wymagane uprawnienia w programie databricks.yml.
Zobacz Narzędzia agenta sztucznej inteligencji , aby zapoznać się z obsługiwanymi typami narzędzi i przykładami kodu.
Define lokalne narzędzia funkcji Python
W przypadku operacji, które nie wymagają zewnętrznych źródeł danych ani interfejsów API, zdefiniuj narzędzia bezpośrednio w kodzie agenta. Te narzędzia działają w tym samym procesie co agent i są przydatne w przypadku przekształceń danych, obliczeń lub operacji narzędziowych.
Zestaw SDK agentów OpenAI
Użyj dekoratora @function_tool z zestawu SDK agentów OpenAI:
from agents import Agent, function_tool
@function_tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = Agent(
name="My agent",
instructions="You are a helpful assistant.",
model="databricks-claude-sonnet-4-5",
tools=[get_current_time],
)
LangGraph
Użyj dekoratora @tool z langchain:
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
@tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = create_react_agent(
ChatDatabricks(endpoint="databricks-claude-sonnet-4-5"),
tools=[get_current_time],
)
Lokalne narzędzia funkcjonalne nie wymagają udzielania zasobów w databricks.yml, ponieważ działają w ramach procesu agenta.
Krok 4. Zarządzanie użyciem usługi LLM przez agentów w aplikacjach usługi Databricks za pomocą usługi Unity AI Gateway
Skieruj wywołania LLM agenta przez AI Gateway (Beta), aby każde żądanie było objęte tymi samymi mechanizmami kontroli, niezależnie od tego, który dostawca na nie odpowiada. Za pomocą bramy w ścieżce żądania można scentralizować uprawnienia, przypisać koszt na aplikację, zmieniać modele, przeanalizować lub odtworzyć ruch bez modyfikowania kodu agenta lub zmiany poświadczeń dostawcy.
Important
Ta funkcja jest dostępna w wersji beta. Administratorzy obszaru roboczego mogą kontrolować dostęp do tej funkcji ze strony Podglądy . Zobacz Zarządzanie wersjami zapoznawczami usługi Azure Databricks.
Włącz bramę AI w przestrzeni roboczej. Bramę sztucznej inteligencji można aktywować podczas fazy Beta programu. Administrator konta musi włączyć tę funkcję na stronie Podglądy w konsoli konta, zanim będzie można utworzyć lub wykonywać zapytania względem punktów końcowych bramy. Zobacz Zarządzanie wersjami zapoznawczami usługi Azure Databricks.
Wskaż agenta na punkt końcowy bramy AI. W kodzie agenta przekaż nazwę punktu końcowego bramy AI jako argument
modeli ustawuse_ai_gateway=Truena kliencie Azure Databricks LLM. Klient kieruje ruch przez bramę i automatycznie obsługuje uwierzytelnianie.OpenAI
from agents import Agent, set_default_openai_api, set_default_openai_client from databricks_openai import AsyncDatabricksOpenAI set_default_openai_client(AsyncDatabricksOpenAI(use_ai_gateway=True)) set_default_openai_api("chat_completions") agent = Agent( name="Agent", instructions="You are a helpful assistant.", model="<ai-gateway-endpoint>", )LangGraph
from databricks_langchain import ChatDatabricks llm = ChatDatabricks( model="<ai-gateway-endpoint>", use_ai_gateway=True, )Aby uzyskać dodatkowe interfejsy API (interfejs API odpowiedzi OpenAI, interfejs API komunikatów Anthropic, Google Gemini) i przykłady REST, zobacz Query Unity AI Gateway endpoints.
Zaawansowane tematy autorstwa
Odpowiedzi przesyłania strumieniowego
Odpowiedzi przesyłania strumieniowego
Przesyłanie strumieniowe umożliwia agentom wysyłanie odpowiedzi we fragmentach w czasie rzeczywistym zamiast czekać na pełną odpowiedź. Aby zaimplementować przesyłanie strumieniowe za pomocą ResponsesAgent, emituj serię zdarzeń różnicowych, po których następuje końcowe zdarzenie ukończenia.
-
Emituj zdarzenia różnicowe: wysyłaj wiele
output_text.deltazdarzeń o tym samymitem_idrozmiarze, aby przesyłać strumieniowo fragmenty tekstu w czasie rzeczywistym. -
Zakończ z gotowym zdarzeniem: wyślij ostateczne
response.output_item.donezdarzenie z takim samymitem_id, jak zdarzenia różnicowe zawierające pełny końcowy tekst wyjściowy.
Każde zdarzenie różnicowe przesyła strumieniowo fragment tekstu do klienta. Ostateczne gotowe zdarzenie zawiera pełny tekst odpowiedzi i sygnały usługi Databricks w celu wykonania następujących czynności:
- Śledź dane wyjściowe agenta przy użyciu śledzenia MLflow
- Agregowanie odpowiedzi przesyłanych strumieniowo w tabelach wnioskowania Gateway AI
- Wyświetlanie pełnych danych wyjściowych w interfejsie użytkownika platformy AI Playground
Propagacja błędów przesyłania strumieniowego
Mozaika AI propaguje wszelkie błędy napotkane podczas przesyłania strumieniowego przy użyciu ostatniego tokenu w obszarze databricks_output.error. Klient wywołujący musi prawidłowo obsłużyć i wyświetlić ten błąd.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Niestandardowe dane wejściowe i wyjściowe
Niestandardowe dane wejściowe i wyjściowe
W niektórych scenariuszach mogą być wymagane dodatkowe dane wejściowe agenta, takie jak client_type, lub dane wyjściowe, takie jak linki źródeł pobierania session_id, które nie powinny być uwzględniane w historii czatów na potrzeby przyszłych interakcji.
W przypadku tych scenariuszy platforma MLflow ResponsesAgent natywnie obsługuje pola custom_inputs i custom_outputs. Dostęp do niestandardowych danych wejściowych można uzyskać, korzystając z request.custom_inputs w powyższych przykładach frameworku.
Aplikacja oceny agenta nie obsługuje renderowania śladów dla agentów z dodatkowymi polami wejściowymi.
Podaj custom_inputs w środowisku zabaw dla sztucznej inteligencji i przejrzyj aplikację
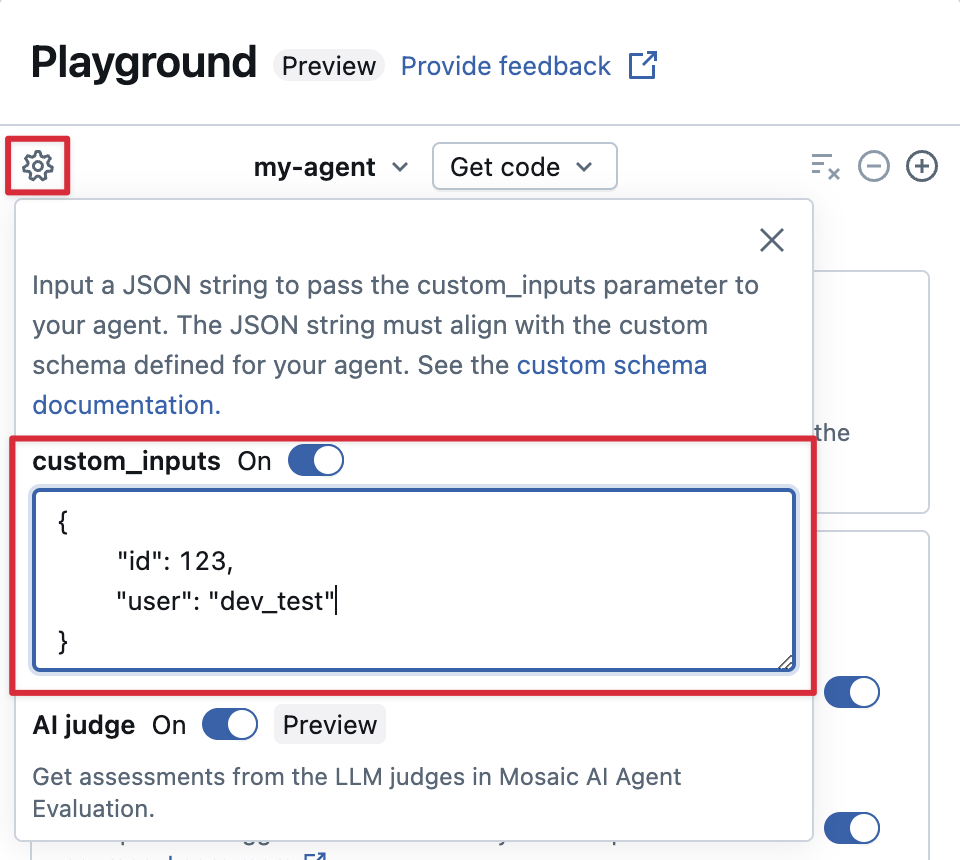
Jeśli agent akceptuje dodatkowe dane wejściowe przy użyciu custom_inputs pola, możesz ręcznie podać te dane wejściowe zarówno w środowisku zabaw dla sztucznej inteligencji, jak i w aplikacji do przeglądu.
W aplikacji Plac Zabaw AI lub Aplikacja Przegląd Agenta wybierz ikonę koła zębatego

Włącz custom_inputs.
Podaj obiekt JSON zgodny ze zdefiniowanym schematem wejściowym agenta.
Krok 5. Uruchamianie aplikacji agenta lokalnie
Konfigurowanie środowiska lokalnego:
Zainstaluj
uv(menedżer pakietów Python),nvm(Menedżer wersji środowiska Node) i interfejs wiersza polecenia usługi Databricks:-
uvInstalacja -
nvmInstalacja - Uruchom następujące, aby użyć Node 20 LTS:
nvm use 20 -
databricks CLIInstalacja
-
Zmień katalog na
agent-openai-agents-sdkfolder .Uruchom podane skrypty szybkiego startu, aby zainstalować zależności, skonfigurować środowisko i uruchomić aplikację.
uv run quickstart uv run start-app
W przeglądarce przejdź do http://localhost:8000 aby otworzyć wbudowany interfejs użytkownika czatu i rozpocząć rozmowę z agentem.
Krok 6. Konfigurowanie uwierzytelniania
Agent wymaga uwierzytelniania, aby uzyskać dostęp do zasobów Azure Databricks. Usługa Databricks Apps udostępnia dwie metody uwierzytelniania: autoryzację aplikacji (jednostkę usługi) i autoryzację użytkownika (w imieniu użytkownika). Możesz skonfigurować jedną z tych opcji za pomocą interfejsu użytkownika obszaru roboczego lub deklaratywnie w databricks.yml, używając pakietów automatyzacji deklaratywnej. Szablony agentów są dostarczane z elementem databricks.yml, dzięki czemu ścieżka ta staje się domyślna, gdy zaczynasz od szablonu.
Aby uzyskać pełną dokumentację, łącznie ze wszystkimi obsługiwanymi typami zasobów, wartościami uprawnień i kompletnym databricks.yml przewodnikiem, zobacz Authentication for AI agents (Uwierzytelnianie agentów sztucznej inteligencji).
Autoryzacja aplikacji (ustawienie domyślne)
Autoryzacja aplikacji wykorzystuje główną jednostkę usługi, którą Azure Databricks automatycznie tworzy dla Twojej aplikacji. Wszyscy użytkownicy mają te same uprawnienia.
Zadeklaruj każdy zasób używany przez agenta pod elementem resources.apps.<app>.resources w databricks.yml. Wdróż pakiet, aby przyznać jednostce usługi zadeklarowane uprawnienia:
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
config:
command: ['uv', 'run', 'start-app']
env:
- name: MLFLOW_TRACKING_URI
value: 'databricks'
- name: MLFLOW_REGISTRY_URI
value: 'databricks-uc'
- name: MLFLOW_EXPERIMENT_ID
value_from: 'experiment'
resources:
- name: 'experiment'
experiment:
experiment_id: '<experiment-id>'
permission: 'CAN_EDIT'
- name: 'llm'
serving_endpoint:
name: 'databricks-claude-sonnet-4-5'
permission: 'CAN_QUERY'
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
Aby uzyskać pełną listę typów zasobów, zobacz Autoryzacja aplikacji.
Autoryzacja użytkownika
Autoryzacja użytkownika umożliwia agentowi działanie z poszczególnymi uprawnieniami poszczególnych użytkowników. Użyj tej opcji, gdy potrzebujesz kontroli dostępu dla poszczególnych użytkowników lub dzienników inspekcji.
Dodaj ten kod do agenta:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Important
Zainicjuj get_user_workspace_client() wewnątrz funkcji @invoke lub @stream , a nie podczas uruchamiania aplikacji. Poświadczenia użytkownika istnieją tylko w przypadku obsługi żądania.
Skonfiguruj API Azure Databricks, które agent może wywołać w imieniu użytkownika, dodając zakresy uprawnień w ramach user_api_scopes w aplikacji databricks.yml.
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
user_api_scopes:
- sql
- dashboards.genie
- serving.serving-endpoints
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
Aby uzyskać listę dostępnych zakresów i wykonać instrukcje dotyczące konfiguracji, zobacz Autoryzacja użytkownika.
Krok 7. Ocenić agenta
Szablon zawiera kod oceny agenta. Aby uzyskać więcej informacji, zobacz agent_server/evaluate_agent.py. Oceń istotność i bezpieczeństwo odpowiedzi agenta, uruchamiając następujące polecenie w terminalu:
uv run agent-evaluate
Krok 8. Wdróż agenta do Databricks Apps
Po skonfigurowaniu uwierzytelniania wdróż agenta w Azure Databricks. Szablony agentów używają pakietów zasobów usługi Databricks (DAB) do wdrożenia. Plik databricks.yml w szablonie definiuje konfigurację aplikacji i uprawnienia zasobów. Upewnij się, że masz zainstalowany i skonfigurowany interfejs wiersza polecenia usługi Databricks .
Notatka
Jeśli utworzyłeś swoją aplikację za pomocą interfejsu użytkownika Workspace w kroku 1, uruchom polecenie databricks bundle deployment bind agent_openai_agents_sdk <app-name> --auto-approve przed wdrożeniem, aby powiązać istniejącą aplikację z pakietem. W przeciwnym razie databricks bundle deploy kończy się niepowodzeniem z komunikatem "Aplikacja o tej samej nazwie już istnieje".
Zweryfikuj konfigurację pakietu, aby przechwycić błędy przed wdrożeniem:
databricks bundle validateWdróż pakiet. Spowoduje to przekazanie kodu i skonfigurowanie zasobów (eksperyment MLflow, obsługa punktów końcowych itd.) zdefiniowanych w pliku
databricks.yml:databricks bundle deployUruchom lub uruchom ponownie aplikację:
databricks bundle run agent_openai_agents_sdkNotatka
bundle deployprzekazuje tylko pliki i konfiguruje zasoby.bundle runjest wymagane do uruchomienia lub ponownego uruchomienia aplikacji z nowym kodem.
W przypadku przyszłych aktualizacji uruchom databricks bundle deploy, a następnie databricks bundle run agent_openai_agents_sdk w celu wdrożenia.
Krok 9. Zapytaj wdrożonego agenta
W poniższym przykładzie użyto szybkiego curl żądania z tokenem OAuth. Osobiste tokeny dostępu (PAT) nie są obsługiwane w przypadku usługi Databricks Apps.
Aby uzyskać pełną listę metod zapytań, w tym klienta OpenAI usługi Databricks i interfejsu API REST, zobacz Zapytanie agenta wdrożonego na platformie Azure Databricks.
Wygeneruj token OAuth przy użyciu interfejsu wiersza polecenia usługi Databricks:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Użyj tokenu, aby wysłać zapytanie do agenta:
curl -X POST <app-url.databricksapps.com>/responses \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Ograniczenia
- Obsługiwane są tylko średnie i duże rozmiary obliczeniowe. Zobacz Konfigurowanie zasobów obliczeniowych dla aplikacji usługi Databricks.
- Interfejs użytkownika czatu aplikacji MLflow Review nie obsługuje obecnie agentów wdrożonych w aplikacjach Databricks. Aby ocenić istniejące ślady, użyj sesji etykietowania, które działają niezależnie od metody wdrażania. Databricks implementuje wsparcie recenzji i opinii bezpośrednio w szablon czatbota.