Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Skompiluj i wdróż pierwszego agenta sztucznej inteligencji przy użyciu szablonów usługi Databricks Apps. W tym samouczku nauczysz się:
- Kompilowanie i wdrażanie agenta z poziomu interfejsu użytkownika aplikacji usługi Databricks.
- Rozmowa z agentem przy użyciu wstępnie utworzonego interfejsu czatu.
Wymagania wstępne
Włącz aplikacje usługi Databricks w obszarze roboczym. Zobacz Konfigurowanie obszaru roboczego usługi Databricks Apps i środowiska programistycznego.
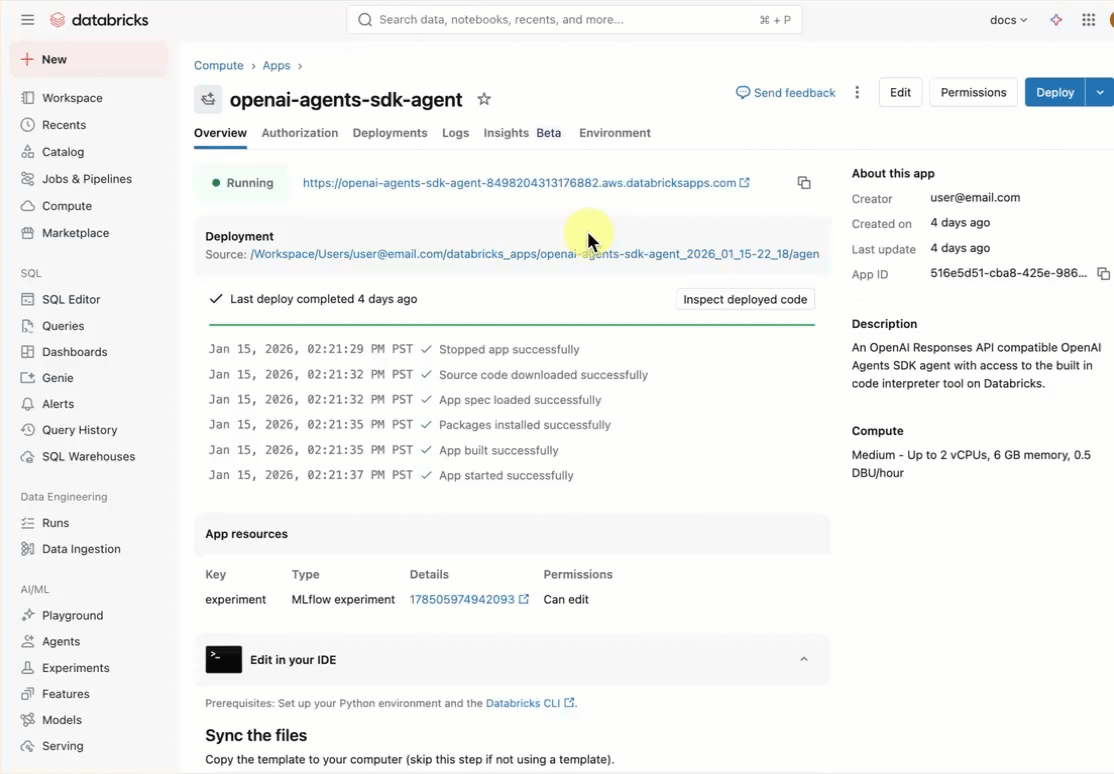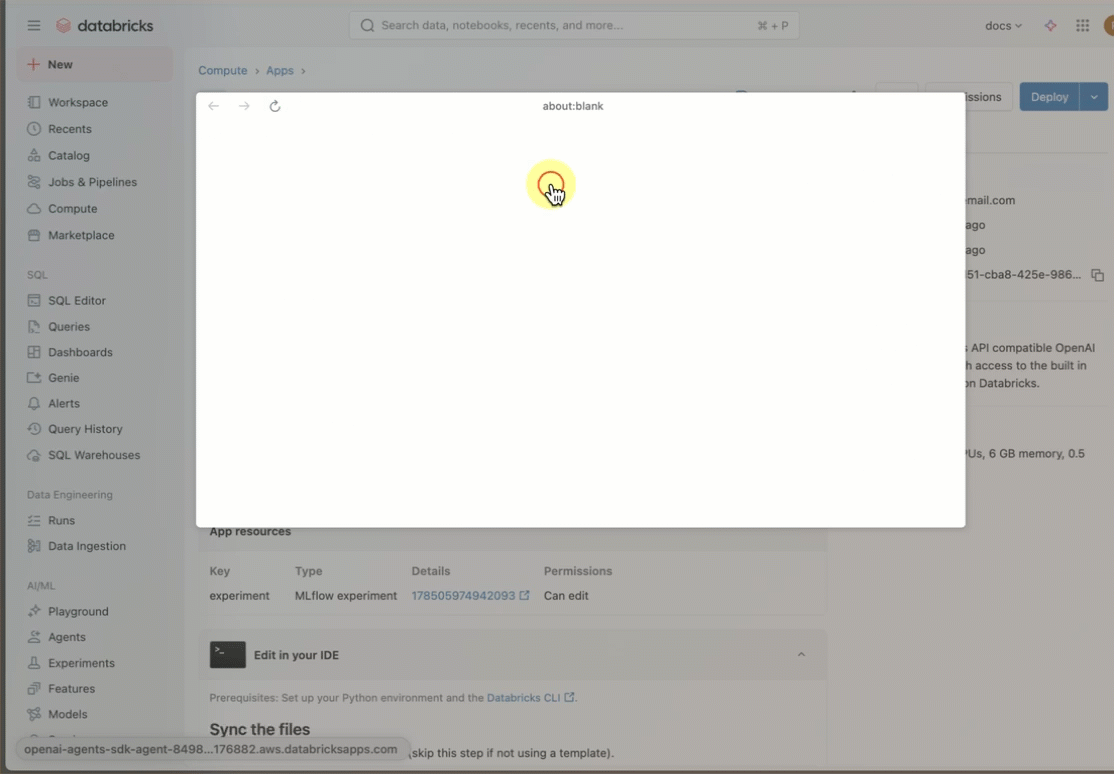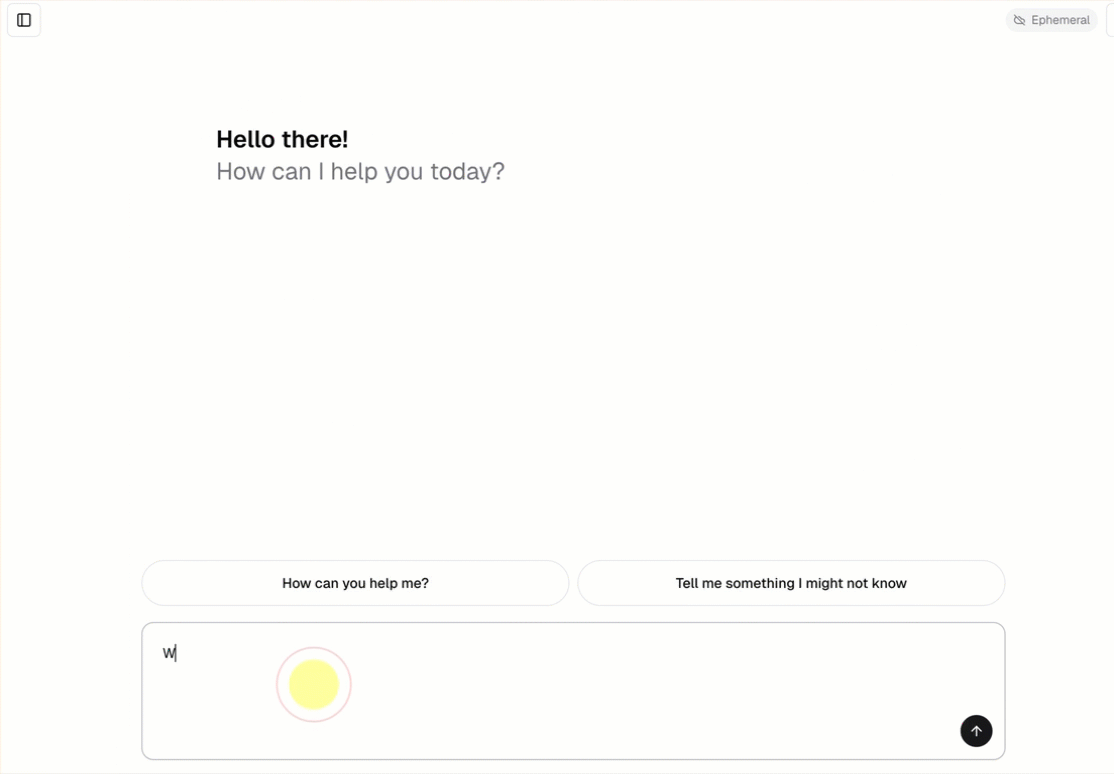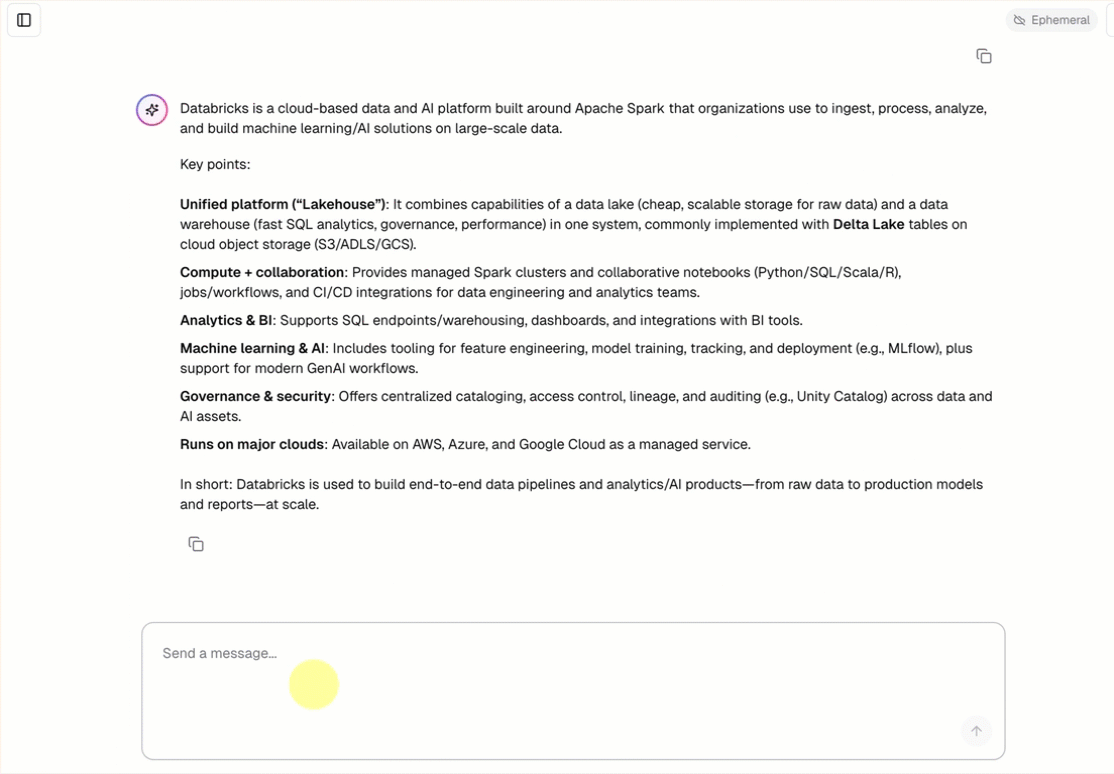
Wdrażanie szablonu agenta
Rozpocznij pracę przy użyciu wstępnie utworzonego szablonu agenta z repozytorium szablonów aplikacji usługi Databricks.
Ten samouczek używa szablonu agent-openai-agents-sdk, który obejmuje:
- Agent utworzony przy użyciu zestawu SDK agenta OpenAI
- Kod początkowy dla aplikacji agenta z interfejsem API REST konwersacji i interaktywnym interfejsem użytkownika czatu
- Kod do oceny agenta przy użyciu biblioteki MLflow
Zainstaluj szablon aplikacji przy użyciu interfejsu użytkownika obszaru roboczego. To instaluje aplikację i wdraża ją do zasobu obliczeniowego w twoim obszarze roboczym.
W obszarze roboczym usługi Databricks kliknij pozycję + Nowa>aplikacja.
Kliknij Agenci>Agent – SDK Agentów OpenAI.
Utwórz nowy eksperyment MLflow o nazwie
openai-agents-templatei ukończ resztę konfiguracji w celu zainstalowania szablonu.Po utworzeniu aplikacji kliknij adres URL aplikacji, aby otworzyć interfejs użytkownika czatu.
Omówienie aplikacji agenta
Szablon agenta przedstawia architekturę gotową do produkcji z następującymi kluczowymi składnikami:
MLflow AgentServer: asynchroniczny serwer FastAPI obsługujący żądania agenta z wbudowanym śledzeniem i obserwacją. AgentServer udostępnia /invocations punkt końcowy do wykonywania zapytań dotyczących agenta i automatycznie zarządza routingiem żądań, rejestrowaniem i obsługą błędów.
Zestaw SDK agentów OpenAI: szablon używa zestawu SDK agentów OpenAI jako struktury agentów do zarządzania konwersacjami i organizowania narzędzi. Agentów można tworzyć przy użyciu dowolnej platformy. Kluczem jest opakowanie agenta przy użyciu interfejsu MLflow ResponsesAgent.
ResponsesAgent interfejs: ten interfejs zapewnia, że agent działa w różnych strukturach i integruje się z narzędziami usługi Databricks. Skompiluj agenta przy użyciu zestawu OpenAI SDK, LangGraph, LangChain lub czystego języka Python, a następnie opakuj go, aby uzyskać automatyczną zgodność z narzędziami ResponsesAgent AI Playground, Agent Evaluation i Databricks Apps.
Serwery MCP (Model Context Protocol): szablon łączy się z serwerami MCP usługi Databricks w celu uzyskania dostępu do agentów do narzędzi i źródeł danych. Zobacz Protokół MCP (Model Context Protocol) w usłudze Databricks.

Dalsze kroki
Dowiedz się, jak utworzyć agenta niestandardowego: tworzenie agenta sztucznej inteligencji i wdrażanie go w usłudze Databricks Apps