Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Łącznik programu Microsoft SQL Server jest w publicznej wersji zapoznawczej.
Na tej stronie opisano sposób pozyskiwania danych z programu SQL Server i ładowania ich do usługi Azure Databricks przy użyciu usługi Lakeflow Connect. Łącznik programu SQL Server obsługuje bazy danych SQL Azure SQL i Amazon RDS SQL. Obejmuje to program SQL Server uruchomiony na maszynach wirtualnych platformy Azure i w usłudze Amazon EC2. Łącznik obsługuje również SQL Server w lokalnym środowisku, korzystając z sieci Azure ExpressRoute i AWS Direct Connect.
Zanim rozpoczniesz
Aby utworzyć kanał danych wejściowych, musisz spełnić następujące wymagania:
Twoje środowisko pracy ma włączoną funkcję Unity Catalog.
W twoim obszarze roboczym włączono bezserwerowe obliczenia. Zobacz Włączanie przetwarzania bezserwerowego.
Jeśli planujesz utworzyć połączenie: masz uprawnienia
CREATE CONNECTIONw metastore.Jeśli łącznik obsługuje tworzenie potoków opartych na interfejsie użytkownika, możesz utworzyć połączenie i potok w tym samym czasie, wykonując kroki na tej stronie. Jeśli jednak używasz tworzenia potoku za pomocą interfejsu API, przed wykonaniem kroków na tej stronie należy utworzyć połączenie w Eksploratorze Katalogu. Zobacz Połączenie z zarządzanymi źródłami pozyskiwania danych.
Jeśli planujesz użyć istniejącego połączenia, musisz mieć
USE CONNECTIONuprawnienia lubALL PRIVILEGESdo połączenia.Masz uprawnienia
USE CATALOGw katalogu docelowym.Masz uprawnienia
USE SCHEMA,CREATE TABLE, iCREATE VOLUMEw odniesieniu do istniejącego schematu lub masz uprawnieniaCREATE SCHEMAw katalogu docelowym.
Masz dostęp do podstawowego wystąpienia programu SQL Server. Funkcje śledzenia zmian i przechwytywania danych o zmianach nie są obsługiwane w replikach do odczytu ani w wystąpieniach pomocniczych.
Nieograniczone uprawnienia do tworzenia klastrów lub zasad niestandardowych. Polityka niestandardowa musi spełniać następujące wymagania:
Rodzina: Obliczenia zadań
Przesłonięcia zestawów polityk:
{ "cluster_type": { "type": "fixed", "value": "dlt" }, "num_workers": { "type": "unlimited", "defaultValue": 1, "isOptional": true }, "runtime_engine": { "type": "fixed", "value": "STANDARD", "hidden": true } }Usługa Databricks zaleca określenie najmniejszych możliwych węzłów roboczych dla bram zarządzania danymi, ze względu na to, że nie mają wpływu na wydajność bramy.
"driver_node_type_id": { "type": "unlimited", "defaultValue": "r5.xlarge", "isOptional": true }, "node_type_id": { "type": "unlimited", "defaultValue": "m4.large", "isOptional": true }
Aby uzyskać więcej informacji na temat zasad klastra, zobacz Wybieranie zasad klastra.
Aby przetwarzać dane z SQL Server, należy również ukończyć konfigurację źródłową.
Opcja 1. Interfejs użytkownika usługi Azure Databricks
Użytkownicy administracyjni mogą utworzyć połączenie i potok w tym samym czasie w interfejsie użytkownika. Jest to najprostszy sposób zaprojektowania zarządzanych potoków wprowadzania danych.
Na pasku bocznym obszaru roboczego usługi Azure Databricks kliknij pozycję Pozyskiwanie danych.
Na stronie Dodawanie danych w obszarze Łączniki usługi Databricks kliknij pozycję SQL Server.
Otwiera się kreator importowania.
Na stronie kreatora Brama wprowadzania wprowadź unikatową nazwę bramy.
Wybierz wykaz i schemat dla danych pozyskiwania przejściowego, a następnie kliknij przycisk Dalej.
Na stronie Potok pozyskiwania wprowadź unikatową nazwę potoku.
W obszarze Katalog docelowy wybierz katalog do przechowywania pozyskanych danych.
Wybierz połączenie Unity Catalog, które przechowuje poświadczenia wymagane do uzyskania dostępu do danych źródłowych.
Jeśli nie ma istniejących połączeń ze źródłem, kliknij przycisk Utwórz połączenie i wprowadź szczegóły uwierzytelniania uzyskane z konfiguracji źródłowej. Musisz mieć uprawnienia
CREATE CONNECTIONw metastore.Kliknij Utwórz kanał i kontynuuj.
Na stronie Źródło wybierz tabele do importowania.
Opcjonalnie zmień domyślne ustawienie śledzenia historii. Aby uzyskać więcej informacji, zobacz Śledzenie historii.
Kliknij przycisk Dalej.
Na stronie docelowej wybierz katalog Unity Catalog i schemat, do którego chcesz zapisać.
Jeśli nie chcesz używać istniejącego schematu, kliknij przycisk Utwórz schemat. Musisz mieć uprawnienia
USE CATALOGiCREATE SCHEMAw katalogu nadrzędnym.Kliknij przycisk Zapisz i kontynuuj.
(Opcjonalnie) Na stronie Ustawienia kliknij pozycję Utwórz harmonogram. Ustaw częstotliwość odświeżania tabel docelowych.
(Opcjonalnie) Ustaw powiadomienia e-mail dotyczące powodzenia lub niepowodzenia działania potoku.
Kliknij Zapisz i uruchom potok.
Opcja 2. Inne interfejsy
Przed importowaniem za pomocą Databricks Asset Bundles, interfejsów API, zestawów SDK lub interfejsu wiersza polecenia Databricks, musisz mieć dostęp do istniejącego połączenia Unity Catalog. Aby uzyskać instrukcje, zobacz Połącz się z zarządzanymi źródłami pozyskiwania.
Utwórz katalog przejściowy i schemat
Katalog i schemat tymczasowy mogą być takie same jak katalog i schemat docelowy. Katalog przejściowy nie może być katalogiem obcym.
CLI
export CONNECTION_NAME="my_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_sqlserver_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="cdc-connector.database.windows.net"
export DB_USER="..."
export DB_PASSWORD="..."
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "SQLSERVER",
"options": {
"host": "'"$DB_HOST"'",
"port": "1433",
"trustServerCertificate": "false",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
Tworzenie bramy dostępu i potoku danych
Brama pobierania wyodrębnia dane migawkowe i zmiany ze źródłowej bazy danych i przechowuje je w woluminie przejściowym Unity Catalog. Bramę należy uruchomić jako ciągły proces. Pomaga to uwzględnić wszelkie zasady przechowywania dzienników zmian, które masz w źródłowej bazie danych.
Potok pozyskiwania stosuje migawkę i zmienia dane z woluminu przejściowego na docelowe tabele przesyłania strumieniowego.
Uwaga / Notatka
Każdy potok pozyskiwania musi być skojarzony z dokładnie jedną bramą pozyskiwania.
Potok przetwarzania danych nie obsługuje więcej niż jednego katalogu docelowego ani schematu. Jeśli musisz zapisać w wielu katalogach docelowych lub schematach, utwórz wiele par brama-potok.
Pakiety zasobów Databricks
Na tej karcie opisano sposób wdrażania potoku przetwarzania danych przy użyciu Databricks Asset Bundles. Pakiety mogą zawierać definicje YAML dotyczące prac i zadań, są zarządzane przy użyciu interfejsu wiersza polecenia usługi Databricks i mogą być udostępniane oraz uruchamiane w różnych docelowych obszarach roboczych (takich jak rozwój, środowisko testowe i produkcja). Aby uzyskać więcej informacji, zobacz Pakiety zasobów Databricks.
Utwórz nowy pakiet przy użyciu interfejsu wiersza polecenia usługi Databricks:
databricks bundle initDodaj dwa nowe pliki zasobów do pakietu:
- Plik definicji potoku danych (
resources/sqlserver_pipeline.yml). - Plik przepływu pracy, który kontroluje częstotliwość pozyskiwania danych (
resources/sqlserver.yml).
Oto przykładowy
resources/sqlserver_pipeline.ymlplik:variables: # Common variables used multiple places in the DAB definition. gateway_name: default: sqlserver-gateway dest_catalog: default: main dest_schema: default: ingest-destination-schema resources: pipelines: gateway: name: ${var.gateway_name} gateway_definition: connection_name: <sqlserver-connection> gateway_storage_catalog: main gateway_storage_schema: ${var.dest_schema} gateway_storage_name: ${var.gateway_name} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEW pipeline_sqlserver: name: sqlserver-ingestion-pipeline ingestion_definition: ingestion_gateway_id: ${resources.pipelines.gateway.id} objects: # Modify this with your tables! - table: # Ingest the table test.ingestion_demo_lineitem to dest_catalog.dest_schema.ingestion_demo_line_item. source_catalog: test source_schema: ingestion_demo source_table: lineitem destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} - schema: # Ingest all tables in the test.ingestion_whole_schema schema to dest_catalog.dest_schema. The destination # table name will be the same as it is on the source. source_catalog: test source_schema: ingestion_whole_schema destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEWOto przykładowy
resources/sqlserver_job.ymlplik:resources: jobs: sqlserver_dab_job: name: sqlserver_dab_job trigger: # Run this job every day, exactly one day from the last run # See https://docs.databricks.com/api/workspace/jobs/create#trigger periodic: interval: 1 unit: DAYS email_notifications: on_failure: - <email-address> tasks: - task_key: refresh_pipeline pipeline_task: pipeline_id: ${resources.pipelines.pipeline_sqlserver.id}- Plik definicji potoku danych (
Wdróż pipeline za pomocą CLI Databricks.
databricks bundle deploy
Notatnik
Zaktualizuj komórkę Configuration w poniższym notesie, używając połączenia źródłowego, oraz katalogu docelowego, schematu docelowego i tabel do pobrania ze źródła.
Tworzenie bramy i potoku pobierania danych
CLI
Aby utworzyć bramę:
output=$(databricks pipelines create --json '{
"name": "'"$GATEWAY_PIPELINE_NAME"'",
"gateway_definition": {
"connection_id": "'"$CONNECTION_ID"'",
"gateway_storage_catalog": "'"$STAGING_CATALOG"'",
"gateway_storage_schema": "'"$STAGING_SCHEMA"'",
"gateway_storage_name": "'"$GATEWAY_PIPELINE_NAME"'"
}
}')
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
Aby utworzyć pipeline importu danych:
databricks pipelines create --json '{
"name": "'"$INGESTION_PIPELINE_NAME"'",
"ingestion_definition": {
"ingestion_gateway_id": "'"$GATEWAY_PIPELINE_ID"'",
"objects": [
{"table": {
"source_catalog": "tpc",
"source_schema": "tpch",
"source_table": "lineitem",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'",
"destination_table": "<YOUR_DATABRICKS_TABLE>",
}},
{"schema": {
"source_catalog": "tpc",
"source_schema": "tpcdi",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'"
}}
]
}
}'
Rozpocznij, zaplanuj i ustaw alerty w swoim rurociągu
Harmonogram przepływu można utworzyć na stronie szczegółów przepływu.
Po utworzeniu potoku ponownie przejdź do obszaru roboczego usługi Azure Databricks, a następnie kliknij pozycję Potoki.
Nowy rurociąg pojawia się na liście rurociągów.
Aby wyświetlić szczegóły kolejki, kliknij jej nazwę.
Na stronie szczegółów potoku możesz zaplanować potok, klikając pozycję Harmonogram.
Aby ustawić powiadomienia dla potoku, kliknij Ustawienia, a następnie dodaj powiadomienie.
Dla każdego harmonogramu, który dodasz do potoku, Lakeflow Connect automatycznie tworzy zadanie dla tego harmonogramu. Potok przetwarzania jest zadaniem w ramach pracy. Opcjonalnie możesz dodać więcej zadań do zadania.
Weryfikowanie pomyślnego pozyskiwania danych
Widok listy na stronie szczegółów potoku przedstawia liczbę rekordów przetworzonych podczas pozyskiwania danych. Te liczby są odświeżane automatycznie.
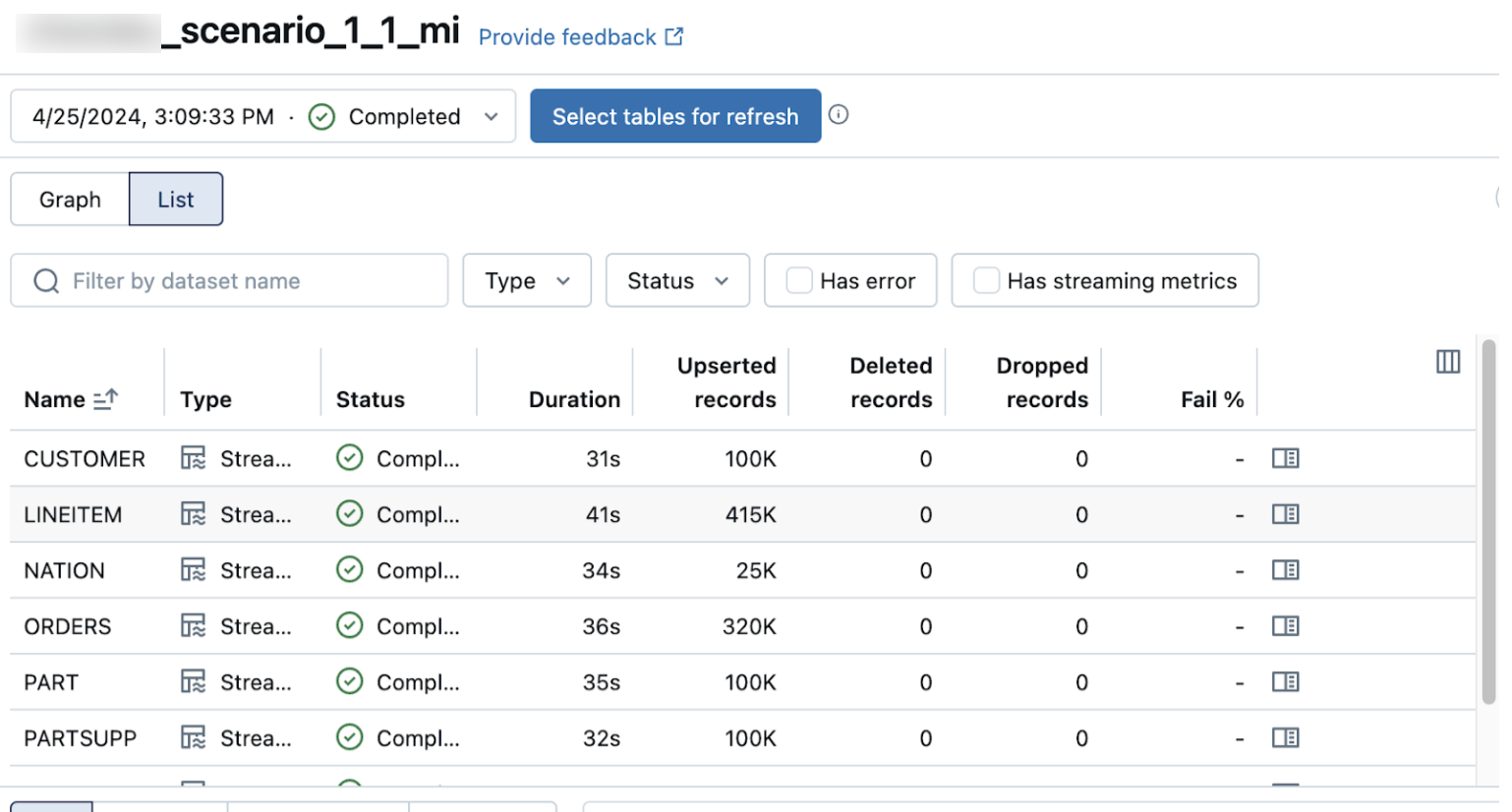
Kolumny Upserted records i Deleted records nie są domyślnie wyświetlane. Możesz je włączyć, klikając przycisk ![]() i wybierając je.
i wybierając je.