Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, czym są deklaratywne potoki Lakeflow Spark (SDP), podstawowe pojęcia (takie jak potoki, tabele strumieniowe i zmaterializowane widoki), relacje między tymi pojęciami oraz korzyści płynące z ich użycia w przepływach pracy przetwarzania danych.
Uwaga / Notatka
Potoki Deklaratywne Lakeflow Spark wymagają planu Premium. Aby uzyskać więcej informacji, skontaktuj się z zespołem ds. kont usługi Databricks.
Co to jest SDP?
Potoki deklaratywne platformy Lakeflow Spark to struktura deklaratywna do tworzenia i uruchamiania potoków danych wsadowych i przesyłanych strumieniowo w usługach SQL i Python. Rozwiązanie Lakeflow SDP rozszerza funkcjonalność i współpracuje z potokami deklaratywnymi Apache Spark, jednocześnie działając na zoptymalizowanym pod kątem wydajności środowisku Databricks Runtime. Interfejs API Lakeflow Spark Declarative Pipelines flows używa tego samego interfejsu API DataFrame co Apache Spark i Structured Streaming. Typowe przypadki użycia SDP obejmują przyrostowe pozyskiwanie danych ze źródeł, takich jak pamięć masowa w chmurze (w tym Amazon S3, Azure ADLS Gen2 i Google Cloud Storage) oraz magistrale komunikatów (takie jak Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure EventHub i Apache Pulsar), przyrostowe transformacje wsadowe i strumieniowe z użyciem operatorów bezstanowych i stanowych oraz przetwarzanie strumieni danych w czasie rzeczywistym między systemami transakcyjnymi, takimi jak magistrale komunikatów i bazy danych.
Aby uzyskać więcej informacji na temat deklaratywnego przetwarzania danych, zobacz Proceduralne a deklaratywne przetwarzanie danych w usłudze Databricks.
Jakie są zalety SDN?
Deklaratywny charakter SDP zapewnia następujące korzyści w porównaniu z opracowywaniem procesów danych przy użyciu interfejsów API Apache Spark i Strukturalne strumieniowanie w Spark oraz uruchamianiem ich za pomocą środowiska Databricks Runtime przy użyciu ręcznej orkiestracji za pośrednictwem zadań Lakeflow Jobs.
- Automatyczna aranżacja: protokół SDP organizuje kroki przetwarzania (nazywane "przepływami") automatycznie w celu zapewnienia prawidłowej kolejności wykonywania i maksymalnego poziomu równoległości w celu uzyskania optymalnej wydajności. Ponadto potoki automatycznie i wydajnie ponawiają próby naprawy przejściowych awarii. Proces ponawiania rozpoczyna się od najbardziej szczegółowej i ekonomicznej jednostki: zadania Spark. Jeśli ponawianie próby na poziomie zadania zakończy się niepowodzeniem, SDP spróbuje ponownie uruchomić przepływ, a następnie w razie potrzeby ponowić cały potok.
- Przetwarzanie deklaratywne: protokół SDP udostępnia funkcje deklaratywne, które mogą zmniejszyć setki lub nawet tysiące wierszy ręcznego kodu Spark i przesyłania strumieniowego ze strukturą tylko do kilku wierszy. Interfejs AUTO CDC API protokołu SDP upraszcza przetwarzanie zdarzeń przechwytywania danych zmian (CDC) z obsługą zarówno dla SCD Type 1, jak i SCD Type 2. Eliminuje to konieczność ręcznego pisania kodu do obsługi zdarzeń odczytywanych poza kolejnością i nie wymaga zrozumienia semantyki przesyłania strumieniowego ani pojęć takich jak znaki wodne.
- Przetwarzanie przyrostowe: protokół SDP udostępnia aparat przetwarzania przyrostowego dla zmaterializowanych widoków. Aby używać tego mechanizmu, należy napisać logikę przekształceń korzystając z semantyki wsadowej, a mechanizm będzie przetwarzać tylko nowe dane oraz zmiany w źródłach danych w miarę możliwości. Przetwarzanie przyrostowe zmniejsza nieefektywne ponowne przetwarzanie, gdy nowe dane lub zmiany występują w źródłach i eliminuje konieczność ręcznego przetwarzania kodu w celu obsługi przetwarzania przyrostowego.
Kluczowe pojęcia
Na poniższym diagramie przedstawiono najważniejsze pojęcia potoków deklaratywnych platformy Spark w usłudze Lakeflow.
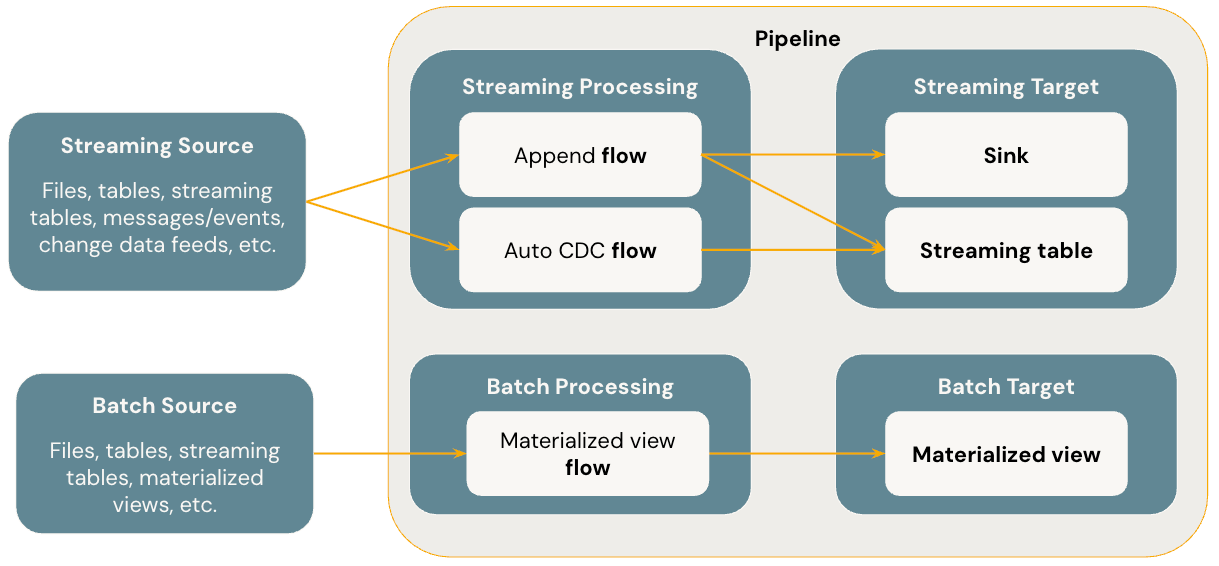
Flows
Przepływ to podstawowe pojęcie przetwarzania danych w SDP, które obsługuje zarówno przetwarzanie strumieniowe, jak i wsadowe. Przepływ odczytuje dane ze źródła, stosuje logikę przetwarzania zdefiniowaną przez użytkownika i zapisuje wynik w miejscu docelowym. Protokół SDP udostępnia ten sam typ przepływu przesyłania strumieniowego (dołączanie, aktualizowanie, uzupełnianie) jako przesyłanie strumieniowe ze strukturą platformy Spark. (Obecnie dostępne są tylko przepływy Append i Update.) Aby uzyskać więcej informacji, zobacz tryby wyjściowe w Structured Streaming.
Deklaratywne potoki Lakeflow Spark udostępniają również dodatkowe typy przepływów.
- AUTO CDC to unikatowy przepływ przesyłania strumieniowego w usłudze Lakeflow SDP, który obsługuje zdarzenia CDC poza kolejnością i obsługuje zarówno typ SCD Type 1, jak i SCD Type 2. Automatyczna usługa CDC nie jest dostępna w potokach deklaratywnych platformy Apache Spark.
- Zmaterializowany widok to przepływ wsadowy w rozwiązaniu SDP, który przetwarza tylko nowe dane i zmiany w tabelach źródłowych, gdy tylko jest to możliwe.
Aby uzyskać więcej informacji, zobacz:
Streamingowe tabele
Tabela strumieniowa to forma tabeli zarządzanej przez Unity Catalog, która jest również docelowym obiektem strumieniowym dla Lakeflow SDP. Tabela przesyłania strumieniowego może mieć jeden lub więcej przepływów przesyłania strumieniowego (Dodawanie, AUTOMATYCZNE CDC) zapisywane do niej. AUTO CDC to unikatowy przepływ przesyłania strumieniowego dostępny tylko dla tabel przesyłania strumieniowego w usłudze Databricks. Przepływy przesyłania strumieniowego można definiować jawnie i oddzielnie od docelowej tabeli przesyłania strumieniowego. Przepływy strumieniowe można również definiować implicitnie w ramach definicji tabeli strumieniowej.
Aby uzyskać więcej informacji, zobacz:
Zmaterializowane widoki
Zmaterializowany widok jest również formą tabeli zarządzanej w Unity Catalog i jest docelowym obiektem wsadowym. Zmaterializowany widok może zawierać co najmniej jeden zmaterializowany przepływ widoku zapisany w nim. Zmaterializowane widoki różnią się od tabel przesyłania strumieniowego, ponieważ zawsze definiujesz przepływy niejawnie w ramach zmaterializowanej definicji widoku.
Aby uzyskać więcej informacji, zobacz:
Sinks
Odbiornik jest docelowym odbiorcą strumienia dla potoku i obsługuje tabele Delta, tematy Apache Kafka, tematy Azure EventHubs oraz niestandardowe źródła danych w Pythonie. Ujście może zawierać co najmniej jeden przepływ przesyłania strumieniowego (dołączanie, aktualizowanie) zapisany w nim.
Aby uzyskać więcej informacji, zobacz:
Pipelines
Potok jest jednostką programowania i wykonywania w potokach deklaratywnych platformy Spark w usłudze Lakeflow. Pipeline może zawierać jeden lub więcej przepływów, tabele strumieniowe, zmaterializowane widoki i ujścia. Używasz SDP, definiując przepływy, tabele strumieniowe, zmaterializowane widoki i sinki w kodzie źródłowym potoku, a następnie uruchamiając potok. Podczas uruchamiania potoku analizuje zależności zdefiniowanych przepływów, tabel przesyłania strumieniowego, zmaterializowane widoki i ujścia oraz automatycznie organizuje kolejność wykonywania i przetwarzania równoległego.
Aby uzyskać więcej informacji, zobacz:
Potoki SQL usługi Databricks
Tabele przesyłania strumieniowego i zmaterializowane widoki to dwie podstawowe funkcje w usłudze Databricks SQL. Możesz użyć standardowego języka SQL do tworzenia i odświeżania tabel przesyłania strumieniowego oraz zmaterializowanych widoków w usłudze Databricks SQL. Tabele przesyłania strumieniowego i zmaterializowane widoki w usłudze Databricks SQL działają w tej samej infrastrukturze usługi Azure Databricks i mają taką samą semantyka przetwarzania, jak w potokach deklaratywnych platformy Spark w usłudze Lakeflow. W przypadku korzystania z tabel przesyłania strumieniowego i zmaterializowanych widoków w usłudze Databricks SQL przepływy są definiowane niejawnie w ramach tabel przesyłania strumieniowego i zmaterializowanej definicji widoków.
Aby uzyskać więcej informacji, zobacz: