Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Potok może zawierać wiele przepływów, które są prawie identyczne, różniące się tylko kilkoma parametrami. Jawne zdefiniowanie tych przepływów jest podatne na błędy, nadmiarowe i trudne do utrzymania. Metaprogramowanie za pomocą Python funkcji wewnętrznych generuje dynamiczne powtarzające się przepływy, a każde wywołanie dostarcza inny zestaw parametrów.
Omówienie programowania metadanych
Metaprogramowanie w potokach Lakeflow wykorzystuje funkcje zagnieżdżone w Pythonie. Ponieważ te funkcje są oceniane w sposób leniwy przez środowisko wykonawcze potoku, można opakowywać @dp.table dekoratory wewnątrz funkcji fabrycznej i wywoływać tę fabrykę wiele razy z różnymi argumentami. Każde wywołanie rejestruje nowy przepływ bez duplikowania kodu.
Aby uzyskać szczegółowe informacje na temat używania pętli for z potokami Lakeflow, zobacz Tworzenie tabel w pętli for.
Przykład: czasy odpowiedzi straży pożarnej
W poniższym przykładzie użyto wbudowanego zestawu danych straży pożarnej, aby znaleźć dzielnice z najszybszym czasem reagowania awaryjnego dla każdego typu połączenia. Bez metaprogramowania należy napisać niemal identyczne definicje tabeli dla każdego typu wywołania (Alarmy, Pożar struktury, Incydent medyczny). W przypadku metaprogramowania pojedyncza funkcja fabryczna generuje wszystkie z nich.
Krok 1. Definiowanie nieprzetworzonej tabeli pozyskiwania
import functools
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name="raw_fire_department",
comment="raw table for fire department response"
)
@dp.expect_or_drop("valid_received", "received IS NOT NULL")
@dp.expect_or_drop("valid_response", "responded IS NOT NULL")
@dp.expect_or_drop("valid_neighborhood", "neighborhood != 'None'")
def get_raw_fire_department():
return (
spark.read.format('csv')
.option('header', 'true')
.option('multiline', 'true')
.load('/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv')
.withColumnRenamed('Call Type', 'call_type')
.withColumnRenamed('Received DtTm', 'received')
.withColumnRenamed('Response DtTm', 'responded')
.withColumnRenamed('Neighborhooods - Analysis Boundaries', 'neighborhood')
.select('call_type', 'received', 'responded', 'neighborhood')
)
Krok 2: Zdefiniuj funkcję fabryki przepływu
generate_tables Funkcja fabryki rejestruje dwie tabele dla każdego typu wywołania: odfiltrowaną tabelę wywołań i sklasyfikowaną tabelę czasu odpowiedzi. Oba są tworzone jako funkcje wewnętrzne oznaczone dekoratorem @dp.table.
all_tables = []
def generate_tables(call_table, response_table, filter):
@dp.table(
name=call_table,
comment="top level tables by call type"
)
def create_call_table():
return spark.sql("""
SELECT
unix_timestamp(received,'M/d/yyyy h:m:s a') as ts_received,
unix_timestamp(responded,'M/d/yyyy h:m:s a') as ts_responded,
neighborhood
FROM raw_fire_department
WHERE call_type = '{filter}'
""".format(filter=filter))
@dp.table(
name=response_table,
comment="top 10 neighborhoods with fastest response time"
)
def create_response_table():
return spark.sql("""
SELECT
neighborhood,
AVG((ts_received - ts_responded)) as response_time
FROM {call_table}
GROUP BY 1
ORDER BY response_time
LIMIT 10
""".format(call_table=call_table))
all_tables.append(response_table)
Krok 3. Wywołanie fabryki i zdefiniowanie tabeli podsumowania
Wywołaj fabrykę raz dla każdego typu wywołania, a następnie zdefiniuj tabelę podsumowania zawierającą wyniki, aby znaleźć dzielnice, które są najczęściej wyświetlane we wszystkich kategoriach.
generate_tables("alarms_table", "alarms_response", "Alarms")
generate_tables("fire_table", "fire_response", "Structure Fire")
generate_tables("medical_table", "medical_response", "Medical Incident")
@dp.table(
name="best_neighborhoods",
comment="which neighbor appears in the best response time list the most"
)
def summary():
target_tables = [dp.read(t) for t in all_tables]
unioned = functools.reduce(lambda x, y: x.union(y), target_tables)
return (
unioned.groupBy(col("neighborhood"))
.agg(count("*").alias("score"))
.orderBy(desc("score"))
)
Po uruchomieniu tego potoku utworzysz zestaw podobnych tabel, jak na tym wykresie:
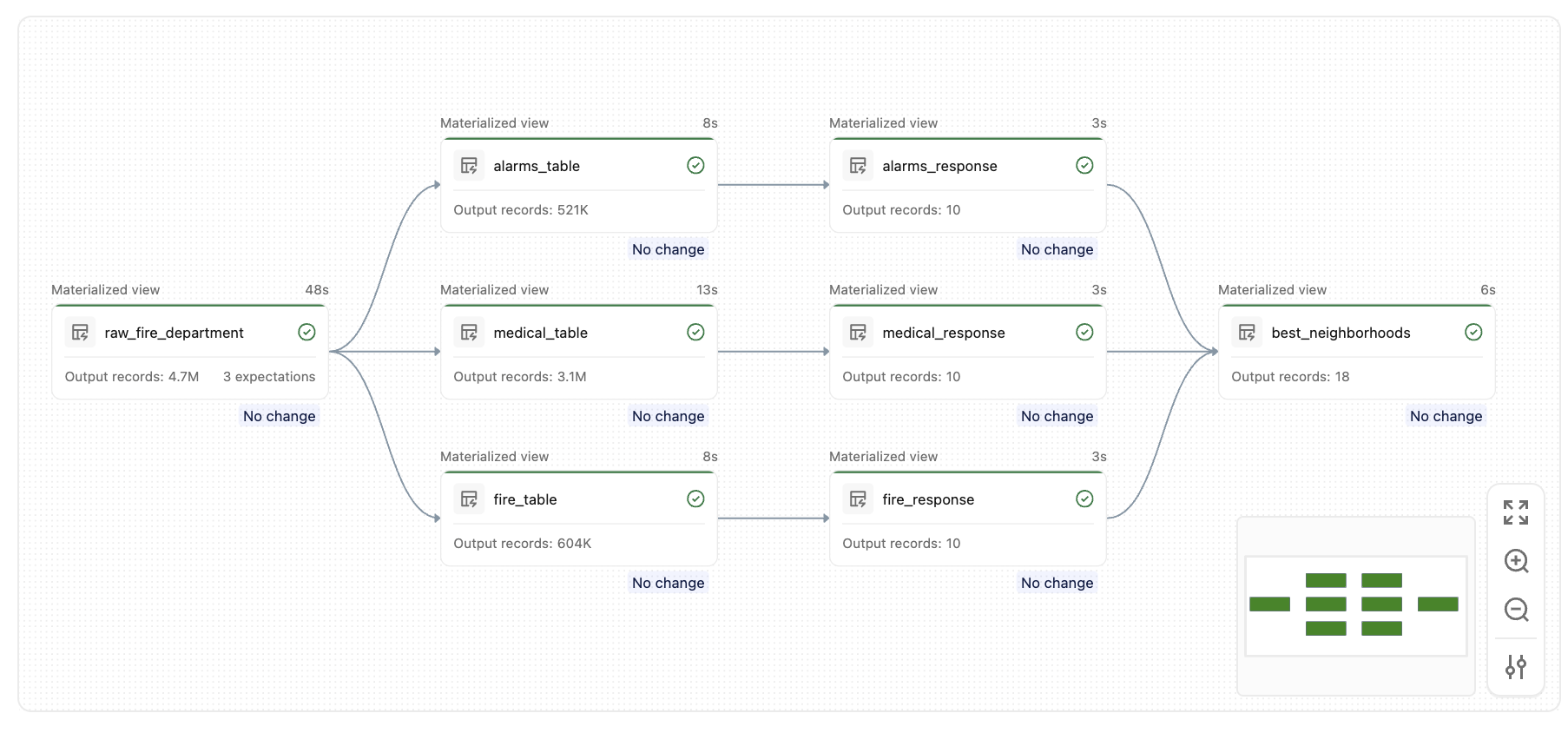
Kluczowe pojęcia
-
Funkcje wewnętrzne są leniwie rejestrowane:
@dp.tabledekorator nie uruchamia funkcji natychmiast. Rejestruje funkcję w środowisku uruchomieniowym potoku, który rozwiązuje pełny wykres przepływu danych przed rozpoczęciem wykonywania. -
Zamknięcia przechwytują parametry: Każda funkcja wewnętrzna zamyka się nad parametrami przekazywanymi do fabryki (
call_table,response_table,filter), więc każdy zarejestrowany przepływ używa własnego izolowanego zestawu wartości. -
Dynamiczne listy tabel: używanie listy, takiej jak
all_tables, do śledzenia programowo wygenerowanych nazw tabel ułatwia późniejsze odwołanie się do nich (na przykład w łączeniu lub sprzężeniu).