Używanie tabel online na potrzeby obsługi funkcji w czasie rzeczywistym
Ważne
Tabele online znajdują się w publicznej wersji zapoznawczej w następujących regionach: westus, , eastuseastus2, northeurope, . westeurope Aby uzyskać informacje o cenach, zobacz Cennik tabel online.
Tabela online to kopia tabeli delta tylko do odczytu, która jest przechowywana w formacie zorientowanym na wiersz zoptymalizowanym pod kątem dostępu online. Tabele online to w pełni bezserwerowe tabele, które umożliwiają automatyczne skalowanie pojemności przepływności z obciążeniem żądania i zapewniają małe opóźnienia i wysoką przepływność dostępu do danych dowolnej skali. Tabele online są przeznaczone do pracy z aplikacjami mozaiki AI Model Serving, Feature Serving i retrieval-augmented generation (RAG), w których są one używane do szybkiego wyszukiwania danych.
Tabele online można również używać w zapytaniach przy użyciu usługi Lakehouse Federation. W przypadku korzystania z usługi Lakehouse Federation należy użyć bezserwerowego magazynu SQL Warehouse, aby uzyskać dostęp do tabel online. Obsługiwane są tylko operacje odczytu (SELECT). Ta funkcja jest przeznaczona tylko do celów interaktywnych lub debugowania i nie powinna być używana w przypadku obciążeń produkcyjnych ani o znaczeniu krytycznym.
Tworzenie tabeli online przy użyciu interfejsu użytkownika usługi Databricks jest procesem jednoetapowym. Po prostu wybierz tabelę delty w Eksploratorze wykazu i wybierz pozycję Utwórz tabelę online. Możesz również użyć interfejsu API REST lub zestawu SDK usługi Databricks do tworzenia tabel online i zarządzania nimi. Zobacz Praca z tabelami online przy użyciu interfejsów API.
Wymagania
- Obszar roboczy musi być włączony dla wykazu aparatu Unity. Postępuj zgodnie z dokumentacją, aby utworzyć magazyn metadanych wykazu aparatu Unity, włączyć go w obszarze roboczym i utworzyć wykaz.
- Aby uzyskać dostęp do tabel online, należy zarejestrować model w wykazie aparatu Unity.
Praca z tabelami online przy użyciu interfejsu użytkownika
W tej sekcji opisano sposób tworzenia i usuwania tabel online oraz sprawdzania stanu i wyzwalania aktualizacji tabel online.
Tworzenie tabeli online przy użyciu interfejsu użytkownika
Tabelę online można utworzyć przy użyciu Eksploratora wykazu. Aby uzyskać informacje o wymaganych uprawnieniach, zobacz Uprawnienia użytkownika.
Aby utworzyć tabelę online, źródłowa tabela delty musi mieć klucz podstawowy. Jeśli tabela delty, której chcesz użyć, nie ma klucza podstawowego, utwórz go, wykonując następujące instrukcje: Użyj istniejącej tabeli delty w wykazie aparatu Unity jako tabeli funkcji.
W Eksploratorze wykazu przejdź do tabeli źródłowej, którą chcesz zsynchronizować z tabelą online. Z menu Utwórz wybierz pozycję Tabela online.
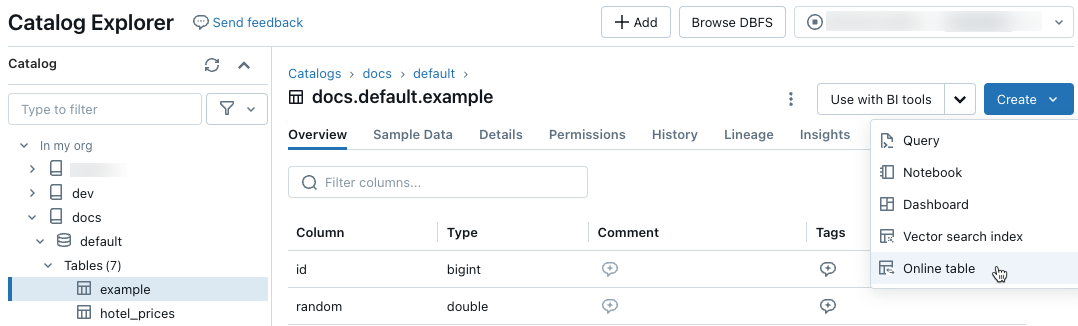
Użyj selektorów w oknie dialogowym, aby skonfigurować tabelę online.
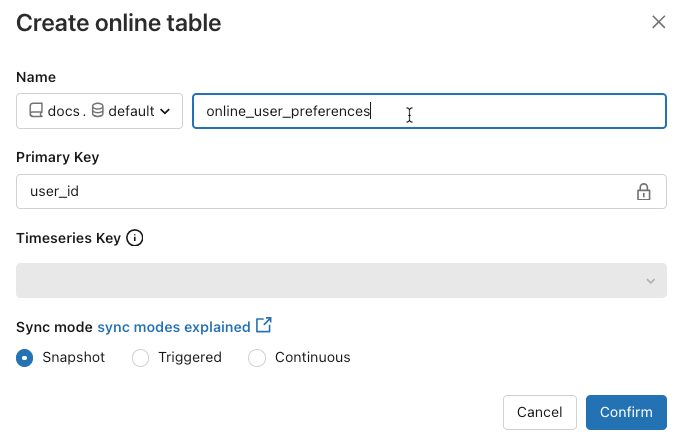
Nazwa: nazwa do użycia dla tabeli online w wykazie aparatu Unity.
Klucz podstawowy: kolumny w tabeli źródłowej do użycia jako klucze podstawowe w tabeli online.
Klucz czasowników: (opcjonalnie). Kolumna w tabeli źródłowej do użycia jako klucz czasowników. Po określeniu tabela online zawiera tylko wiersz z najnowszą wartością klucza czasownika dla każdego klucza podstawowego.
Tryb synchronizacji: określa, jak potok synchronizacji aktualizuje tabelę online. Wybierz jedną z pozycji Migawka, Wyzwolona lub Ciągła.
Zasada opis Snapshot Potok jest uruchamiany raz, aby utworzyć migawkę tabeli źródłowej i skopiować ją do tabeli online. Kolejne zmiany w tabeli źródłowej są automatycznie odzwierciedlane w tabeli online przez utworzenie nowej migawki źródła i utworzenie nowej kopii. Zawartość tabeli online jest aktualizowana niepodziecznie. Wyzwolone Potok jest uruchamiany raz, aby utworzyć początkową kopię migawki tabeli źródłowej w tabeli online. W przeciwieństwie do trybu synchronizacji migawki, gdy tabela online jest odświeżona, tylko zmiany od czasu ostatniego wykonania potoku są pobierane i stosowane do tabeli online. Odświeżanie przyrostowe może być wyzwalane ręcznie lub automatycznie wyzwalane zgodnie z harmonogramem. Ciągłe Potok jest uruchamiany w sposób ciągły. Kolejne zmiany w tabeli źródłowej są przyrostowo stosowane do tabeli online w trybie przesyłania strumieniowego w czasie rzeczywistym. Nie jest konieczne ręczne odświeżanie.
Uwaga
Aby obsługiwać tryb wyzwalania lub ciągłej synchronizacji, tabela źródłowa musi mieć włączoną opcję Zmień źródło danych.
- Po zakończeniu kliknij przycisk Potwierdź. Zostanie wyświetlona strona tabeli online.
- Nowa tabela online jest tworzona w katalogu, schemacie i nazwie określonej w oknie dialogowym tworzenia. W Eksploratorze wykazu tabela online jest wskazywana przez polecenie
 .
.
Pobieranie aktualizacji stanu i wyzwalania przy użyciu interfejsu użytkownika
Aby sprawdzić stan tabeli online, kliknij nazwę tabeli w wykazie, aby ją otworzyć. Zostanie wyświetlona strona tabeli online z otwartą kartą Przegląd . W sekcji Pozyskiwanie danych jest wyświetlany stan najnowszej aktualizacji. Aby wyzwolić aktualizację, kliknij pozycję Synchronizuj teraz. Sekcja Pozyskiwanie danych zawiera również link do potoku Delta Live Tables, który aktualizuje tabelę.
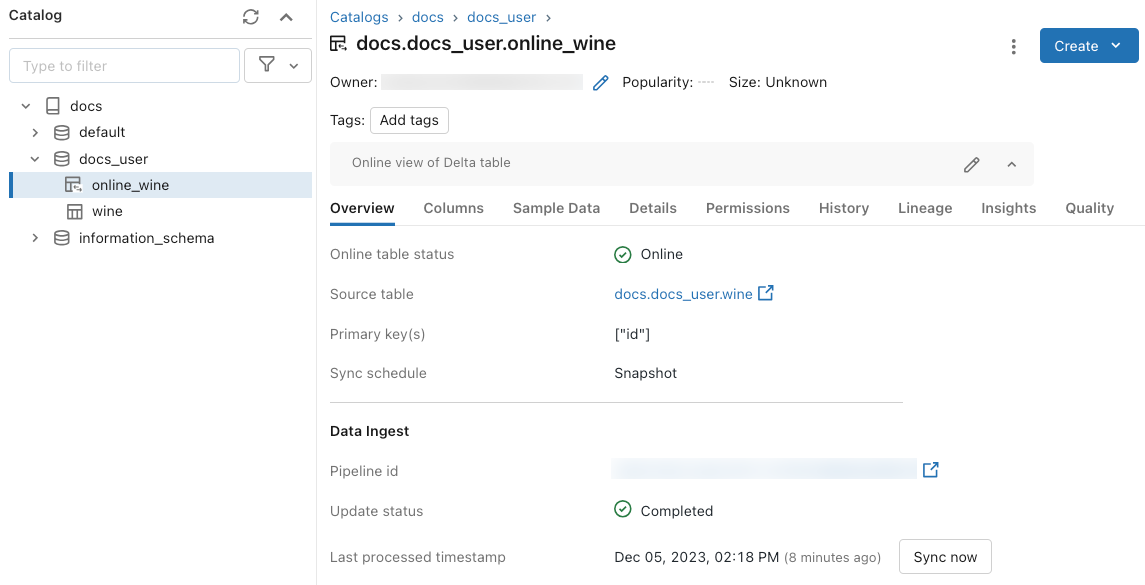
Planowanie okresowych aktualizacji
W przypadku tabel online z trybem synchronizacji Migawka lub Wyzwalana można zaplanować automatyczne okresowe aktualizacje. Harmonogram aktualizacji jest zarządzany przez potok Delta Live Tables, który aktualizuje tabelę.
- W Eksploratorze wykazu przejdź do tabeli online.
- W sekcji Pozyskiwanie danych kliknij link do potoku.
- W prawym górnym rogu kliknij pozycję Harmonogram i dodaj nowy harmonogram lub zaktualizuj istniejące harmonogramy.
Usuwanie tabeli online przy użyciu interfejsu użytkownika
Na stronie tabeli online wybierz pozycję Usuń z ![]() menu kebab.
menu kebab.
Praca z tabelami online przy użyciu interfejsów API
Możesz również użyć zestawu SDK usługi Databricks lub interfejsu API REST do tworzenia tabel online i zarządzania nimi.
Aby uzyskać informacje referencyjne, zobacz dokumentację referencyjną zestawu SDK usługi Databricks dla języka Python lub interfejsu API REST.
Wymagania
Zestaw SDK usługi Databricks w wersji 0.20 lub nowszej.
Tworzenie tabeli online przy użyciu interfejsów API
Zestaw SDK usługi Databricks — Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
Interfejs API REST
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
Tabela online automatycznie rozpoczyna synchronizację po jej utworzeniu.
Uzyskiwanie stanu i odświeżanie wyzwalacza przy użyciu interfejsów API
Stan i specyfikację tabeli online można wyświetlić, wykonując poniższy przykład. Jeśli tabela online nie jest ciągła i chcesz wyzwolić ręczne odświeżanie danych, możesz użyć interfejsu API potoku, aby to zrobić.
Użyj identyfikatora potoku skojarzonego z tabelą online w specyfikacji tabeli online i uruchom nową aktualizację potoku, aby wyzwolić odświeżanie. Jest to równoważne kliknięciu pozycji Synchronizuj teraz w interfejsie użytkownika tabeli online w Eksploratorze wykazu.
Zestaw SDK usługi Databricks — Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
Interfejs API REST
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Usuwanie tabeli online przy użyciu interfejsów API
Zestaw SDK usługi Databricks — Python
w.online_tables.delete('main.default.my_online_table')
Interfejs API REST
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
Usunięcie tabeli online zatrzymuje bieżącą synchronizację danych i zwalnia wszystkie jej zasoby.
Udostępnianie danych tabeli online przy użyciu punktu końcowego obsługującego funkcję
W przypadku modeli i aplikacji hostowanych poza usługą Databricks można utworzyć punkt końcowy obsługujący funkcję, aby obsługiwać funkcje z tabel online. Punkt końcowy udostępnia funkcje przy małych opóźnieniach przy użyciu interfejsu API REST.
Utwórz specyfikację funkcji.
Podczas tworzenia specyfikacji funkcji należy określić źródłową tabelę delty. Dzięki temu specyfikacja funkcji może być używana zarówno w scenariuszach offline, jak i online. W przypadku wyszukiwania w trybie online punkt końcowy obsługujący automatycznie używa tabeli online do wykonywania odnośników funkcji o małych opóźnieniach.
Źródłowa tabela delty i tabela online muszą używać tego samego klucza podstawowego.
Specyfikację funkcji można wyświetlić na karcie Funkcja w Eksploratorze wykazu.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Utwórz punkt końcowy obsługujący funkcję.
W tym kroku założono, że utworzono tabelę online o nazwie
user_preferences_online_table, która synchronizuje dane z tabeli deltyuser_preferences. Użyj specyfikacji funkcji, aby utworzyć punkt końcowy obsługujący funkcję. Punkt końcowy udostępnia dane za pośrednictwem interfejsu API REST przy użyciu skojarzonej tabeli online.Uwaga
Użytkownik wykonujący tę operację musi być właścicielem zarówno tabeli offline, jak i tabeli online.
Zestaw SDK usługi Databricks — Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )Interfejs API języka Python
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Pobieranie danych z punktu końcowego obsługującego funkcję.
Aby uzyskać dostęp do punktu końcowego interfejsu API, wyślij żądanie GET HTTP do adresu URL punktu końcowego. W przykładzie pokazano, jak to zrobić przy użyciu interfejsów API języka Python. Aby zapoznać się z innymi językami i narzędziami, zobacz Obsługa funkcji.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Używanie tabel online z aplikacjami RAG
Aplikacje RAG to typowy przypadek użycia tabel online. Utworzysz tabelę online dla danych strukturalnych, których potrzebuje aplikacja RAG i hostujesz ją w punkcie końcowym obsługującym funkcję. Aplikacja RAG używa punktu końcowego obsługującego funkcję, aby wyszukać odpowiednie dane z tabeli online.
Typowe kroki są następujące:
- Utwórz punkt końcowy obsługujący funkcję.
- Utwórz narzędzie przy użyciu pakietu LangChain lub dowolnego podobnego pakietu, który używa punktu końcowego do wyszukiwania odpowiednich danych.
- Użyj narzędzia w agencie LangChain lub podobnym agencie, aby pobrać odpowiednie dane.
- Utwórz model obsługujący punkt końcowy do hostowania aplikacji.
Aby uzyskać instrukcje krok po kroku i przykładowy notes, zobacz Przykład inżynierii funkcji: ustrukturyzowana aplikacja RAG.
Przykłady notesów
Poniższy notes ilustruje sposób publikowania funkcji w tabelach online na potrzeby wyszukiwania funkcji w czasie rzeczywistym i automatycznego wyszukiwania funkcji.
Notes demonstracyjny tabel online
Korzystanie z tabel online z obsługą modelu mozaiki sztucznej inteligencji
Tabele online umożliwiają wyszukiwanie funkcji obsługi modelu sztucznej inteligencji mozaiki. Podczas synchronizowania tabeli funkcji z tabelą online modele trenowane przy użyciu funkcji z tej tabeli funkcji automatycznie wyszukują wartości funkcji z tabeli online podczas wnioskowania. Nie jest wymagana dodatkowa konfiguracja.
Użyj polecenia ,
FeatureLookupaby wytrenować model.W przypadku trenowania modelu użyj funkcji z tabeli funkcji offline w zestawie trenowania modelu, jak pokazano w poniższym przykładzie:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Obsługa modelu za pomocą usługi Mozaika AI Model Serve. Model automatycznie wyszukuje funkcje z tabeli online. Aby uzyskać szczegółowe informacje, zobacz Wyszukiwanie funkcji automatycznych za pomocą usługi Databricks Model Serving .
Uprawnienia użytkownika
Aby utworzyć tabelę online, musisz mieć następujące uprawnienia:
-
SELECTuprawnienia w tabeli źródłowej. -
USE_CATALOGuprawnienia do katalogu docelowego. -
USE_SCHEMAiCREATE_TABLEuprawnienia w schemacie docelowym.
Aby zarządzać potokiem synchronizacji danych tabeli online, musisz być właścicielem tabeli online lub mieć uprawnienie REFRESH w tabeli online. Użytkownicy, którzy nie mają uprawnień USE_CATALOG i USE_SCHEMA w wykazie, nie zobaczą tabeli online w Eksploratorze wykazu.
Magazyn metadanych wykazu aparatu Unity musi mieć model uprawnień w wersji 1.0.
Model uprawnień punktu końcowego
Unikatowa jednostka usługi jest tworzona automatycznie dla funkcji obsługującej lub modelu obsługującego punkt końcowy z ograniczonymi uprawnieniami wymaganymi do wykonywania zapytań dotyczących danych z tabel online. Ta jednostka usługi umożliwia punktom końcowym uzyskiwanie dostępu do danych niezależnie od użytkownika, który utworzył zasób, i zapewnia, że punkt końcowy może nadal działać, jeśli twórca opuści obszar roboczy.
Okres istnienia tej jednostki usługi to okres istnienia punktu końcowego. Dzienniki inspekcji mogą wskazywać na wygenerowane przez system rekordy dla właściciela katalogu wykazu aparatu Unity, udzielając niezbędnych uprawnień do tej jednostki usługi.
Ograniczenia
- Tylko jedna tabela online jest obsługiwana dla tabeli źródłowej.
- Tabela online i jej tabela źródłowa mogą zawierać co najwyżej 1000 kolumn.
- Kolumny typów danych ARRAY, MAP lub STRUCT nie mogą być używane jako klucze podstawowe w tabeli online.
- Jeśli kolumna jest używana jako klucz podstawowy w tabeli online, wszystkie wiersze w tabeli źródłowej, w których kolumna zawiera wartości null, są ignorowane.
- Tabele obce, systemowe i wewnętrzne nie są obsługiwane jako tabele źródłowe.
- Tabele źródłowe bez włączonego źródła danych zmiany różnicowej obsługują tylko tryb synchronizacji migawki .
- Tabele udostępniania różnicowego są obsługiwane tylko w trybie synchronizacji migawek .
- Nazwy wykazu, schematu i tabeli w tabeli online mogą zawierać tylko znaki alfanumeryczne i podkreślenia i nie mogą rozpoczynać się od liczb. Kreski (
-) są niedozwolone. - Kolumny typu Ciąg są ograniczone do długości 64 KB.
- Nazwy kolumn są ograniczone do 64 znaków.
- Maksymalny rozmiar wiersza to 2 MB.
- Łączny rozmiar wszystkich tabel online w magazynie metadanych wykazu aparatu Unity w publicznej wersji zapoznawczej to 2 TB nieskompresowanych danych użytkownika.
- Maksymalna liczba zapytań na sekundę (QPS) wynosi 12 000. Skontaktuj się z zespołem konta usługi Databricks, aby zwiększyć limit.
Rozwiązywanie problemów
Nie widzę opcji Utwórz tabelę online
Przyczyną jest zwykle to, że tabela, z której próbujesz przeprowadzić synchronizację (tabela źródłowa), nie jest obsługiwanym typem. Upewnij się, że rodzaj zabezpieczania tabeli źródłowej (pokazany na karcie Szczegóły eksploratora wykazu) jest jedną z poniższych obsługiwanych opcji:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
Nie mogę wybrać trybów wyzwalanej lub ciągłej synchronizacji podczas tworzenia tabeli online
Dzieje się tak, jeśli tabela źródłowa nie ma włączonego źródła danych zmiany różnicowej lub jeśli jest to widok lub zmaterializowany widok. Aby użyć trybu synchronizacji przyrostowej , włącz źródło danych zmian w tabeli źródłowej lub użyj tabeli innej niż widok.
Aktualizacja tabeli online kończy się niepowodzeniem lub stan jest wyświetlany w trybie offline
Aby rozpocząć rozwiązywanie problemów z tym błędem, kliknij identyfikator potoku wyświetlany na karcie Przegląd tabeli online w Eksploratorze wykazu.
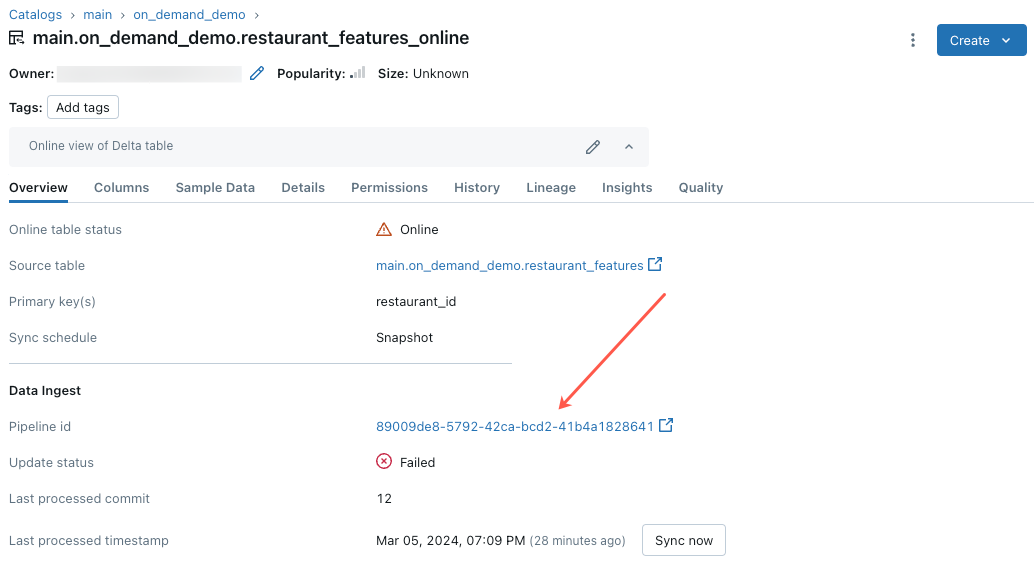
Na wyświetlonej stronie interfejsu użytkownika potoku kliknij wpis "Nie można rozpoznać przepływu "__online_table".
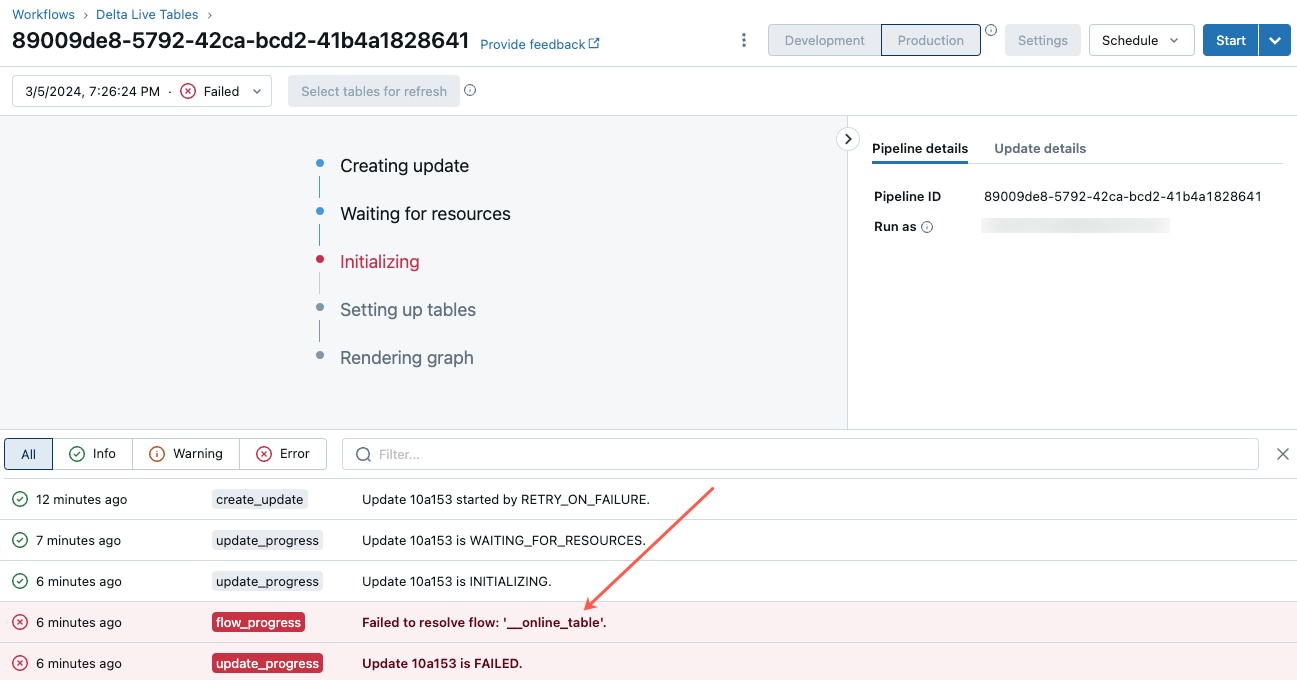
Zostanie wyświetlone okno podręczne ze szczegółami w sekcji Szczegóły błędu.
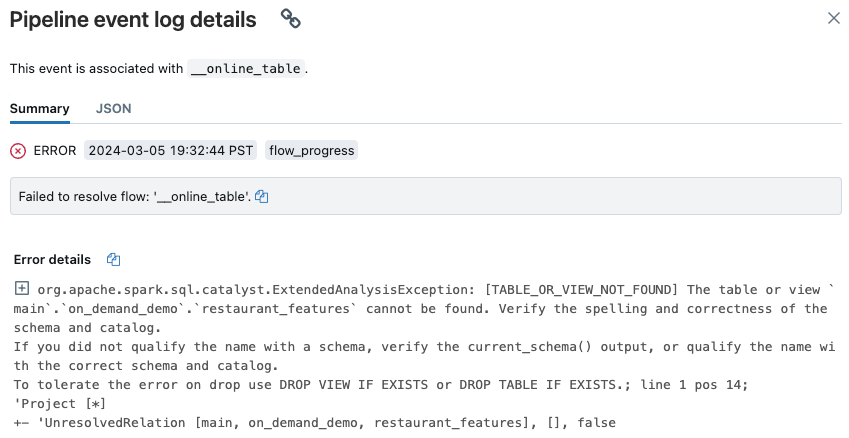
Typowe przyczyny błędów obejmują następujące elementy:
Tabela źródłowa została usunięta lub usunięta i utworzona ponownie o tej samej nazwie, podczas gdy tabela online była synchronizowana. Jest to szczególnie powszechne w przypadku ciągłych tabel online, ponieważ są one stale synchronizowane.
Nie można uzyskać dostępu do tabeli źródłowej za pośrednictwem obliczeń bezserwerowych ze względu na ustawienia zapory. W takiej sytuacji w sekcji Szczegóły błędu może zostać wyświetlony komunikat o błędzie "Nie można uruchomić usługi DLT w klastrze xxx...".
Łączny rozmiar tabel online przekracza limit 2 TB (rozmiar nieskompresowany) magazynu metadanych. Limit 2 TB odnosi się do nieskompresowanego rozmiaru po rozwinięciu tabeli delty w formacie zorientowanym na wiersz. Rozmiar tabeli w formacie wiersza może być znacznie większy niż rozmiar tabeli delty pokazanej w Eksploratorze wykazu, który odnosi się do skompresowanego rozmiaru tabeli w formacie zorientowanym na kolumnę. Różnica może być tak duża, jak 100x, w zależności od zawartości tabeli.
Aby oszacować nieskompresowany, rozszerzony przez wiersz rozmiar tabeli delty, użyj następującego zapytania z bezserwerowej usługi SQL Warehouse. Zapytanie zwraca szacowany rozszerzony rozmiar tabeli w bajtach. Pomyślnie wykonanie tego zapytania potwierdza również, że bezserwerowe obliczenia mogą uzyskać dostęp do tabeli źródłowej.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;