Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano, jak tworzyć punkty końcowe obsługi modeli, które serwują modele niestandardowe przy użyciu usługi Databricks Model Serving.
Obsługa modelu udostępnia następujące opcje obsługi tworzenia punktu końcowego:
- Interfejs obsługi serwera
- interfejs API REST
- Zestaw SDK wdrożeń MLflow
Aby utworzyć punkty końcowe obsługujące generowanie modeli sztucznej inteligencji, zobacz Tworzenie podstawowego modelu obsługującego punkty końcowe.
Wymagania
- Obszar roboczy musi znajdować się w obsługiwanym regionie.
- Jeśli używasz niestandardowych bibliotek lub bibliotek z prywatnego serwera lustrzanego z modelem, zobacz Używanie niestandardowych bibliotek języka Python z serwerem modeli przed utworzeniem punktu końcowego modelu.
- Aby utworzyć punkty końcowe przy użyciu zestawu SDK wdrożeń MLflow, należy zainstalować klienta wdrażania MLflow. Aby go zainstalować, uruchom polecenie:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Kontrola dostępu
Aby poznać opcje kontroli dostępu dla punktów końcowych obsługujących model na potrzeby zarządzania punktami końcowymi, zobacz Zarządzanie uprawnieniami w punkcie końcowym obsługującym model.
Tożsamość, w ramach której działa model obsługujący punkt końcowy, jest powiązana z oryginalnym twórcą punktu końcowego. Po utworzeniu punktu końcowego nie można zmienić ani zaktualizować skojarzonej tożsamości w punkcie końcowym. Ta tożsamość i skojarzone z nią uprawnienia są używane do dostępu do zasobów Unity Catalog na potrzeby implementacji. Jeśli tożsamość nie ma odpowiednich uprawnień dostępu do wymaganych zasobów Unity Catalog, musisz usunąć punkt końcowy i utworzyć go ponownie w ramach użytkownika lub jednostki usługi, która może uzyskać dostęp do tych zasobów Unity Catalog.
Możesz również dodać zmienne środowiskowe do przechowywania poświadczeń dla obsługi modelu. Zobacz Konfigurowanie dostępu do zasobów z punktów końcowych obsługujących model
Tworzenie punktu końcowego
Obsługa interfejsu użytkownika
Możesz utworzyć punkt końcowy do obsługi modelu za pomocą interfejsu użytkownika
Kliknij pozycję Obsługa na pasku bocznym, aby wyświetlić interfejs użytkownika Serving.
Kliknij pozycję Utwórz obsługujący punkt końcowy.
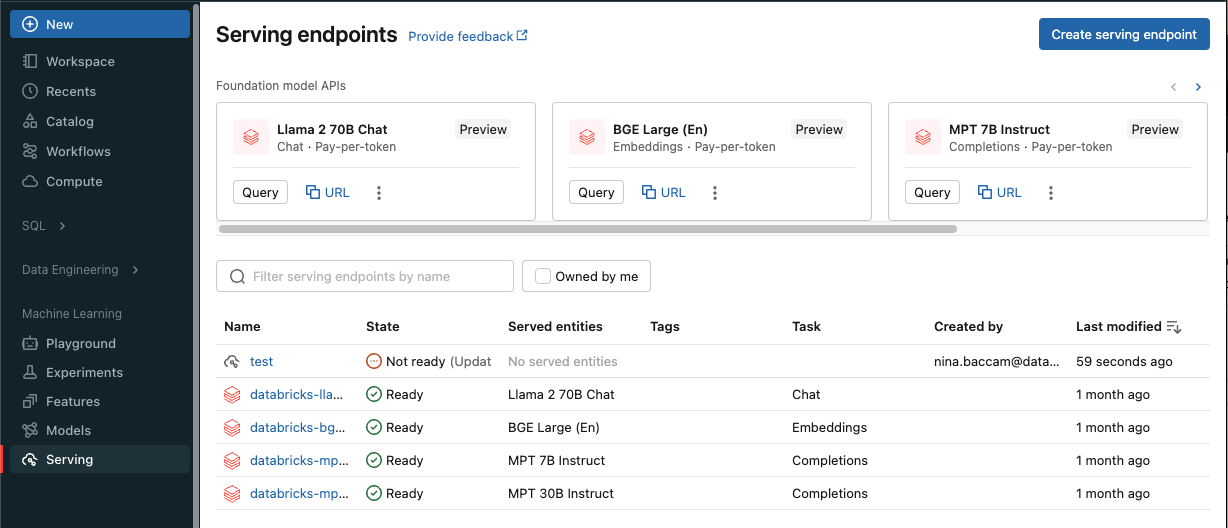
W przypadku modeli zarejestrowanych w rejestrze modeli obszaru roboczego lub modeli zarejestrowanych w katalogu Unity Catalog:
W polu Nazwa podaj nazwę punktu końcowego.
- Nazwy punktów końcowych nie mogą używać prefiksu
databricks-. Ten prefiks jest zarezerwowany dla wstępnie skonfigurowanych punktów końcowych usługi Databricks.
- Nazwy punktów końcowych nie mogą używać prefiksu
W sekcji Obsługiwane jednostki
- Kliknij pole Jednostka , aby otworzyć formularz Wybierz obsługiwaną jednostkę .
- Wybierz pozycję Moje modele—Unity Catalog lub Moje modele—Model Registry na podstawie miejsca zarejestrowania modelu. Formularz jest dynamicznie aktualizowany na podstawie wybranego wyboru.
- Nie wszystkie modele są modelami dostosowanymi. Modele mogą być podstawowymi modelami lub funkcjami obsługującymi funkcje.
- Wybierz model i wersję modelu, którą chcesz obsłużyć.
- Wybierz procent ruchu, który ma być kierowany do obsługiwanego modelu.
- Wybierz rozmiar obliczeniowy do użycia. Na potrzeby obciążeń można użyć procesora CPU lub procesora GPU. Aby uzyskać więcej informacji na temat dostępnych obliczeń procesora GPU, zobacz Typy obciążeń procesora GPU .
- W obszarze Skalowanie obliczeń w poziomie wybierz rozmiar skalowania zasobów obliczeniowych w poziomie, który odpowiada liczbie żądań, które może przetwarzać ten obsługiwany model w tym samym czasie. Ta liczba powinna być w przybliżeniu równa czasowi wykonywania modelu QPS x. W przypadku ustawień obliczeniowych zdefiniowanych przez klienta zobacz Limity obsługi modelu.
- Dostępne rozmiary są małe dla 0–4 żądań, średnich 8-16 żądań i dużych dla 16-64 żądań.
- Określ, czy punkt końcowy powinien być skalowany do zera, gdy nie jest używany. Skalowanie do zera nie jest zalecane w przypadku punktów końcowych produkcyjnych, ponieważ pojemność nie jest gwarantowana w przypadku skalowania do zera. Gdy punkt końcowy jest skalowany do zera, występuje dodatkowe opóźnienie, nazywane również zimnym startem, gdy punkt końcowy skaluje się w górę w celu obsługi żądań.
- W obszarze Konfiguracja zaawansowana można wykonywać następujące czynności:
- Zmień nazwę obsługiwanej jednostki, aby dostosować jej wygląd w punkcie końcowym.
- Dodaj zmienne środowiskowe, aby połączyć się z zasobami z punktu końcowego lub zaloguj swoją ramkę danych wyszukiwania funkcji do tabeli wnioskowania na punkcie końcowym. Rejestrowanie ramki danych wyszukiwania funkcji wymaga biblioteki MLflow 2.14.0 lub nowszej.
- (Opcjonalnie) Aby dodać dodatkowe obsługiwane jednostki do punktu końcowego, kliknij pozycję Dodaj obsługiwaną jednostkę i powtórz powyższe kroki konfiguracji. Można obsługiwać wiele modeli lub wersji modelu z jednego punktu końcowego i kontrolować podział ruchu między nimi. Aby uzyskać więcej informacji, zobacz Obsługa wielu modeli .
W sekcji Optymalizacja tras możesz włączyć optymalizację tras dla punktu końcowego. Optymalizacja tras jest zalecana w przypadku punktów końcowych z wysokimi wymaganiami dotyczącymi QPS i przepływności. Zobacz Optymalizacja tras w przypadku obsługi punktów końcowych.
W sekcji AI Gateway możesz wybrać funkcje zarządzania, które mają być uruchomione na punkcie końcowym. Zobacz Bramę AI Unity.
Kliknij pozycję Utwórz. Strona Obsługa punktów końcowych pojawia się ze stanem punktu końcowego wyświetlanym jako Nie gotowe.
interfejs API REST
Punkty końcowe można tworzyć przy użyciu interfejsu API REST. Zobacz POST /api/2.0/serving-endpoints , aby uzyskać parametry konfiguracji punktu końcowego.
Poniższy przykład tworzy punkt końcowy, który obsługuje trzecią wersję modelu my-ads-model zarejestrowanego w katalogu modeli Unity Catalog. Aby określić model z katalogu Unity Catalog, podaj pełną nazwę modelu, w tym katalog nadrzędny i schemat, taki jak catalog.schema.example-model. W tym przykładzie użyto niestandardowo zdefiniowanej współbieżności z elementami min_provisioned_concurrency i max_provisioned_concurrency. Wartości współbieżności muszą być wielokrotnościami 4.
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false
}
]
}
}
Poniżej znajduje się przykładowa odpowiedź. Stan punktu końcowego config_update to NOT_UPDATING, a obsługiwany model jest w stanie READY.
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
Zestaw SDK wdrożeń MLflow
MLflow Deployments udostępniają interfejs API do zadań tworzenia, aktualizowania i usuwania. Interfejsy API dla tych zadań akceptują te same parametry co interfejs API REST na potrzeby obsługi punktów końcowych. Zobacz POST /api/2.0/serving-endpoints , aby uzyskać parametry konfiguracji punktu końcowego.
Poniższy przykład tworzy punkt końcowy, który obsługuje trzecią wersję modelu my-ads-model zarejestrowanego w katalogu modeli Unity Catalog. Musisz podać pełną nazwę modelu, w tym katalog nadrzędny i schemat, taki jak catalog.schema.example-model. W tym przykładzie użyto niestandardowo zdefiniowanej współbieżności z elementami min_provisioned_concurrency i max_provisioned_concurrency. Wartości współbieżności muszą być wielokrotnościami 4.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": False
}
]
}
)
Klient przestrzeni roboczej
W poniższym przykładzie pokazano, jak utworzyć punkt końcowy przy użyciu zestawu SDK klienta obszaru roboczego usługi Databricks.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="uc-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
name="ads-entity",
entity_name="catalog.schema.my-ads-model",
entity_version="3",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
Możesz również wykonać następujące czynności:
- Włącz tabele wnioskowania , aby automatycznie przechwytywać żądania przychodzące i wychodzące odpowiedzi do modelu obsługującego punkty końcowe.
- Jeśli w punkcie końcowym są włączone tabele wnioskowania, możesz zarejestrować ramkę danych wyszukiwania funkcji w tabeli wnioskowania.
Typy obciążeń procesora GPU
Wdrożenie procesora GPU jest zgodne z następującymi wersjami pakietów:
- PyTorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 i nowsze
W poniższych przykładach pokazano, jak utworzyć punkty końcowe procesora GPU przy użyciu różnych metod.
Obsługa interfejsu użytkownika
Aby skonfigurować punkt końcowy dla obciążeń procesora GPU za pomocą interfejsu użytkownika obsługującego , wybierz żądany typ procesora GPU z listy rozwijanej Typ obliczeniowy podczas tworzenia punktu końcowego. Wykonaj te same kroki w sekcji Tworzenie punktu końcowego, ale wybierz typ obciążenia procesora GPU zamiast procesora CPU.
interfejs API REST
Aby wdrożyć modele przy użyciu procesorów GPU, uwzględnij workload_type pole w konfiguracji punktu końcowego.
POST /api/2.0/serving-endpoints
{
"name": "gpu-model-endpoint",
"config": {
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": false
}]
}
}
Zestaw SDK wdrożeń MLflow
W poniższym przykładzie pokazano, jak utworzyć punkt końcowy procesora GPU przy użyciu zestawu SDK wdrożeń MLflow.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="gpu-model-endpoint",
config={
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": False
}]
}
)
Klient przestrzeni roboczej
W poniższym przykładzie pokazano, jak utworzyć punkt końcowy procesora GPU przy użyciu zestawu SDK klienta obszaru roboczego usługi Databricks.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="gpu-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="catalog.schema.my-gpu-model",
entity_version="1",
workload_type="GPU_SMALL",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
Poniższa tabela zawiera podsumowanie obsługiwanych typów obciążeń procesora GPU.
| Typ obciążenia procesora GPU | Instancja GPU | Pamięć procesora GPU |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80 GB |
GPU_LARGE_2 |
2xA100 | 160 GB |
Modyfikowanie niestandardowego punktu końcowego modelu
Po włączeniu niestandardowego punktu końcowego modelu można zaktualizować konfigurację obliczeniową zgodnie z potrzebami. Ta konfiguracja jest szczególnie przydatna, jeśli potrzebujesz dodatkowych zasobów dla modelu. Rozmiar obciążenia i konfiguracja obliczeniowa odgrywają kluczową rolę w zasobach przydzielonych do obsługi modelu.
Uwaga / Notatka
Aktualizacje konfiguracji punktu końcowego mogą zakończyć się niepowodzeniem. Gdy wystąpią błędy, istniejąca aktywna konfiguracja pozostaje skuteczna, tak jakby aktualizacja nie miała miejsce.
Sprawdź, czy aktualizacja została pomyślnie zastosowana, przeglądając stan punktu końcowego.
Dopóki nowa konfiguracja nie będzie gotowa, stara konfiguracja będzie obsługiwać ruch predykcyjny. Chociaż trwa aktualizacja, nie można wprowadzić innej aktualizacji. Można jednak anulować aktualizację w toku z poziomu Interfejsu Użytkownika Serwisu.
Obsługa interfejsu użytkownika
Po włączeniu punktu końcowego modelu wybierz pozycję Edytuj punkt końcowy , aby zmodyfikować konfigurację obliczeniową punktu końcowego.
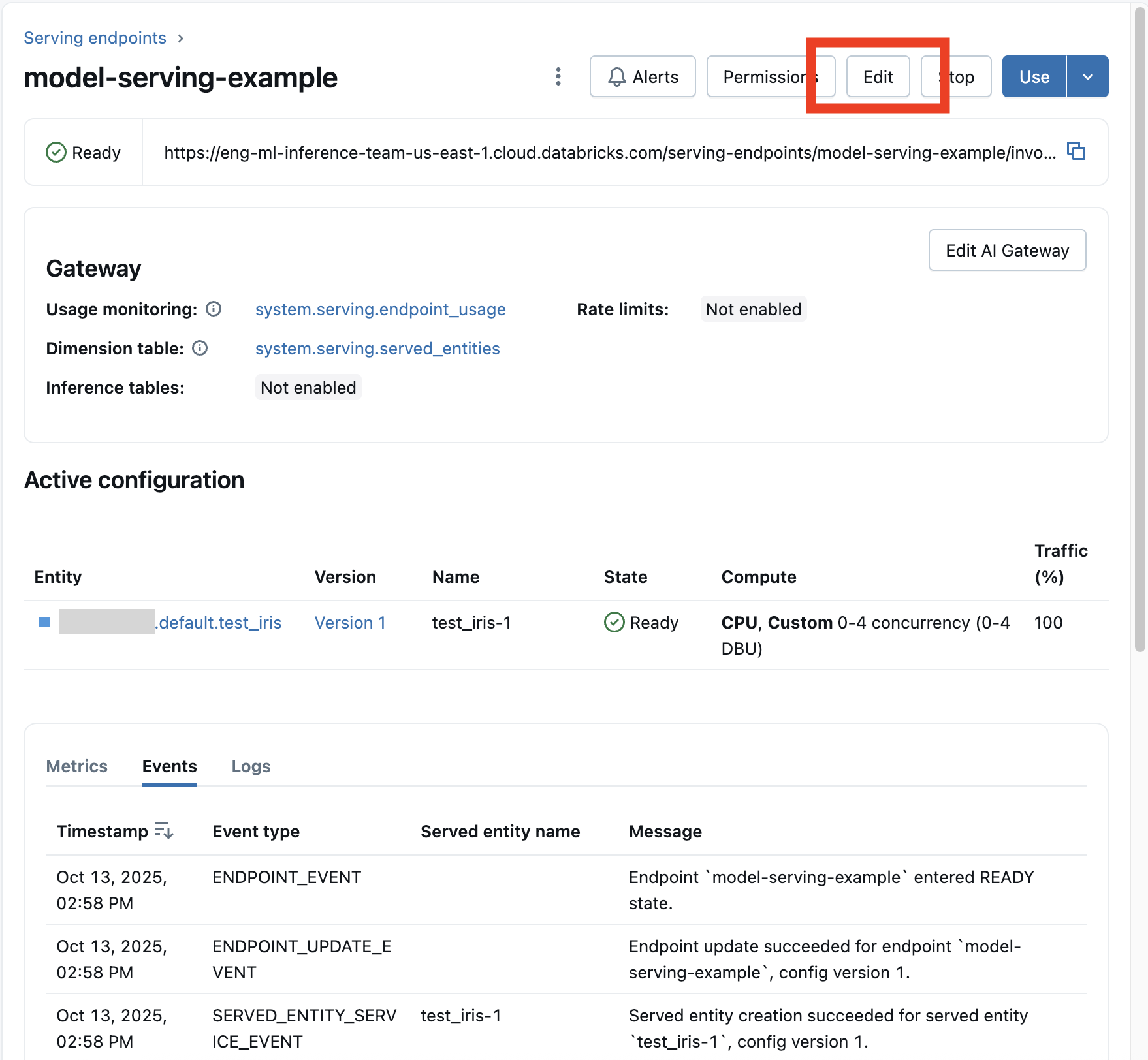
Większość aspektów konfiguracji punktu końcowego można zmienić, z wyjątkiem nazwy punktu końcowego i niektórych niezmiennych właściwości.
Możesz anulować aktualizację konfiguracji w toku, wybierając pozycję Anuluj aktualizację na stronie szczegółów punktu końcowego.
interfejs API REST
Poniżej przedstawiono przykład aktualizacji konfiguracji punktu końcowego przy użyciu interfejsu API REST. Zobacz PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
Zestaw SDK wdrożeń MLflow
Zestaw MLflow Deployments SDK używa tych samych parametrów co interfejs API REST, zobacz PUT /api/2.0/serving-endpoints/{name}/config , aby uzyskać szczegóły schematu żądania i odpowiedzi.
Poniższy przykład kodu używa modelu z rejestru Unity Catalog.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Ocenianie punktu końcowego modelu
Aby ocenić model, wyślij żądania do punktu końcowego obsługującego model.
- Zobacz Punkty końcowe obsługujące zapytania dla modeli niestandardowych.
- Zobacz Korzystanie z modeli podstawowych.
Dodatkowe zasoby
- Zarządzanie modelami obsługującymi punkty końcowe.
- Modele zewnętrzne w narzędziu Mosaic AI Model Serving.
- Jeśli wolisz używać języka Python, możesz skorzystać z zestawu SDK usługi Databricks w czasie rzeczywistym dla języka Python.
Przykłady notatników
Poniższe notesy obejmują różne zarejestrowane modele Databricks, których można użyć do rozpoczęcia pracy z punktami końcowymi obsługiwania modeli. Aby uzyskać dodatkowe przykłady, zobacz Samouczek: wdrażanie i wykonywanie zapytań względem modelu niestandardowego.
Przykłady modeli można zaimportować do obszaru roboczego, postępując zgodnie z instrukcjami w temacie Importowanie notesu. Po wybraniu i utworzeniu modelu na podstawie jednego z przykładów zarejestruj go w Unity Catalog, a następnie wykonaj kroki przepływu pracy interfejsu użytkownika dla obsługi modelu.