Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano sposób konfigurowania dostępu do zasobów zewnętrznych i prywatnych z poziomu punktów końcowych obsługujących model. Obsługa modelu umożliwia obsługę zmiennych środowiskowych zwykłego tekstu i zmiennych środowiskowych opartych na wpisach tajnych przy użyciu tajnych danych usługi Databricks.
Wymagania
W przypadku zmiennych środowiskowych opartych na wpisach tajnych,
- Twórca punktu końcowego musi mieć dostęp do odczytu do tajemnic Databricks, do których odwołują się konfiguracje.
- Musisz przechowywać poświadczenia, takie jak klucz interfejsu API lub inne tokeny, jako tajny zasób Databricks.
Dodawanie zmiennych środowiskowych zwykłego tekstu
Użyj zmiennych środowiskowych zwykłego tekstu, aby ustawić zmienne, które nie muszą być ukryte. Zmienne można ustawić w interfejsie użytkownika usługi, interfejsie API REST lub zestawie SDK podczas tworzenia lub aktualizowania punktu końcowego.
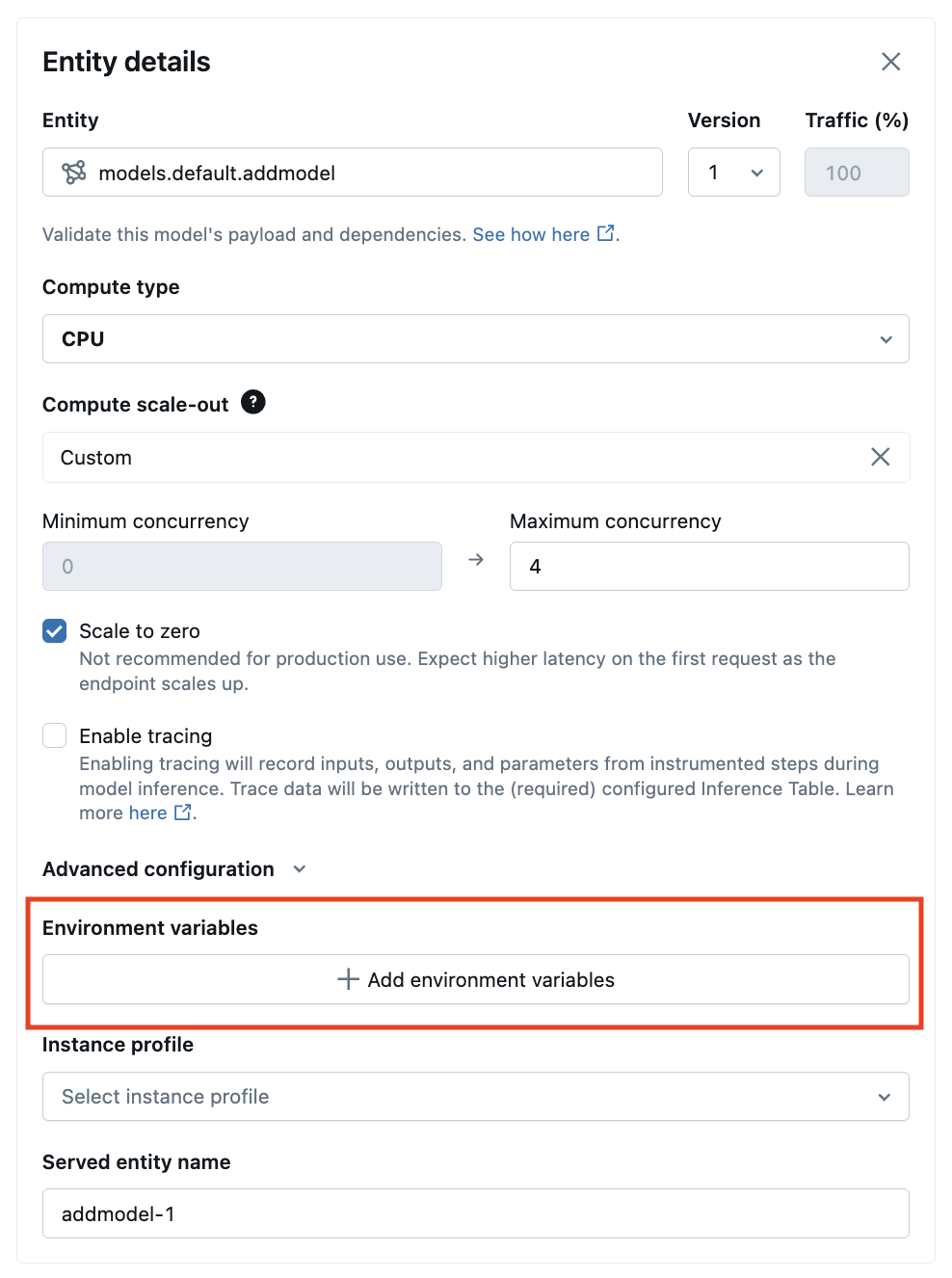
Dostarczanie interfejsu użytkownika
Z poziomu interfejsu użytkownika obsługującego można dodać zmienną środowiskową w konfiguracjach zaawansowanych:
interfejs API REST
Poniżej przedstawiono przykład tworzenia punktu końcowego usługi przy użyciu interfejsu POST /api/2.0/serving-endpoints API REST i pola environment_vars aby skonfigurować zmienną środowiskową.
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"TEXT_ENV_VAR_NAME": "plain-text-env-value"
}
}
]
}
}
WorkspaceClient SDK
Poniżej przedstawiono przykład tworzenia punktu końcowego typu "serving" przy użyciu SDK WorkspaceClient oraz pola environment_vars do konfigurowania zmiennej środowiskowej.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"MY_ENV_VAR": "value_to_be_injected",
"ADS_TOKEN": "abcdefg-1234"
}
)
]
)
)
Zestaw SDK wdrożeń MLflow
Poniżej przedstawiono przykład tworzenia punktu końcowego usługi przy użyciu zestawu SDK do wdrożeń MLflow i pola environment_vars, w celu skonfigurowania zmiennej środowiskowej.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"MY_ENV_VAR": "value_to_be_injected",
"ADS_TOKEN": "abcdefg-1234"
}
}
]
}
)
przeszukiwanie ramek danych funkcji dziennika w tabelach wnioskowania
Jeśli w punkcie końcowym masz włączone tabele wnioskowania, możesz zarejestrować ramkę danych do automatycznego wyszukiwania funkcji w tej tabeli wnioskowania, używając ENABLE_FEATURE_TRACING. Wymaga to środowiska MLflow 2.14.0 lub nowszego.
Ustaw ENABLE_FEATURE_TRACING jako zmienną środowiskową w interfejsie użytkownika obsługującym, interfejsie API REST lub zestawie SDK podczas tworzenia lub aktualizowania punktu końcowego.
Dostarczanie interfejsu użytkownika
- W konfiguracjach zaawansowanychwybierz ** + Dodaj zmienne środowiskowe**.
- Wpisz
ENABLE_FEATURE_TRACINGjako nazwę środowiska. - W polu z prawej strony wpisz
true.
interfejs API REST
Poniżej przedstawiono przykład tworzenia punktu końcowego obsługującego przy użyciu interfejsu API REST POST /api/2.0/serving-endpoints i pola environment_vars w celu skonfigurowania zmiennej środowiskowej ENABLE_FEATURE_TRACING.
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"ENABLE_FEATURE_TRACING": "true"
}
}
]
}
}
WorkspaceClient SDK
Poniżej przedstawiono przykład tworzenia punktu końcowego usługi przy użyciu zestawu SDK WorkspaceClient i pola environment_vars do skonfigurowania zmiennej środowiskowej ENABLE_FEATURE_TRACING.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"ENABLE_FEATURE_TRACING": "true"
}
)
]
)
)
Zestaw SDK wdrożeń MLflow
Poniżej przedstawiono przykład tworzenia punktu końcowego usługi za pomocą MLflow Deployments SDK i pola environment_vars w celu skonfigurowania zmiennej środowiskowej ENABLE_FEATURE_TRACING.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"ENABLE_FEATURE_TRACING": "true"
}
}
]
}
)
Dodaj zmienne środowiskowe oparte na sekretach
Poświadczenia można bezpiecznie przechowywać przy użyciu wpisów tajnych usługi Databricks i odwoływać się do tych wpisów tajnych podczas obsługi modelu, korzystając ze zmiennych środowiskowych bazujących na tajnych wpisach. Dzięki temu poświadczenia mogą być pobierane z modelu obsługującego punkty końcowe w czasie obsługi.
Na przykład, można przekazać poświadczenia do wywołania usług OpenAI i innych zewnętrznych punktów końcowych modelu lub uzyskać dostęp do zewnętrznych lokalizacji przechowywania danych bezpośrednio z obsługi modelu.
Usługa Databricks zaleca tę funkcję do wdrażania odmian modeli OpenAI i LangChain MLflow do obsługi. Dotyczy to również innych modeli SaaS wymagających poświadczeń ze zrozumieniem, że wzorzec dostępu jest oparty na korzystaniu ze zmiennych środowiskowych i kluczy interfejsu API i tokenów.
Krok 1: Utwórz zakres tajny
Podczas obsługi modelu tajemnice są pobierane z usługi Databricks za pomocą zakresu i klucza. Są one przypisywane do tajnych nazw zmiennych środowiskowych, które mogą być używane w modelu.
Najpierw utwórz zakres tajny. Zobacz Zarządzanie tajnymi obszarami.
Poniżej przedstawiono polecenia CLI:
databricks secrets create-scope my_secret_scope
Następnie możesz dodać swoją tajną informację do żądanego zakresu tajemnic i klucza, jak pokazano poniżej:
databricks secrets put-secret my_secret_scope my_secret_key
Informacje tajne i nazwa zmiennej środowiskowej można następnie przekazać do konfiguracji punktu końcowego podczas tworzenia punktu końcowego lub jako aktualizację konfiguracji istniejącego punktu końcowego.
Krok 2: Dodaj zakresy tajne do konfiguracji punktów końcowych
Zakres sekretu można dodać do zmiennej środowiskowej i przekazać ją do punktu końcowego podczas tworzenia punktu końcowego lub aktualizacji konfiguracji. Zobacz Tworzenie niestandardowych punktów końcowych dla obsługi modelu.
Dostarczanie interfejsu użytkownika
W interfejsie użytkownika obsługującego można dodać zmienną środowiskową w konfiguracjach zaawansowanych. Zmienna środowiskowa oparta na tajnych danych musi być podana przy użyciu następującej składni: {{secrets/scope/key}}. W przeciwnym razie zmienna środowiskowa jest uznawana za zmienną środowiskową w postaci zwykłego tekstu.
interfejs API REST
Poniżej przedstawiono przykład tworzenia punktu końcowego obsługującego przy użyciu interfejsu API REST. Podczas tworzenia i aktualizowania konfiguracji punktu końcowego modelu można podać listę specyfikacji tajnych zmiennych środowiskowych dla każdego obsługiwanego modelu w żądaniu interfejsu API, przy użyciu pola environment_vars.
Poniższy przykład przypisuje wartość z sekretu utworzonego w podanym kodzie do zmiennej środowiskowej OPENAI_API_KEY.
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
}
Możesz również zaktualizować punkt końcowy obsługujący, tak jak w poniższym PUT /api/2.0/serving-endpoints/{name}/config przykładzie interfejsu API REST:
{
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "2",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
WorkspaceClient SDK
Poniżej przedstawiono przykład tworzenia punktu końcowego obsługującego przy użyciu zestawu WORKSPACEClient SDK. Podczas tworzenia i aktualizowania konfiguracji punktu końcowego modelu można podać listę specyfikacji tajnych zmiennych środowiskowych dla każdego obsługiwanego modelu w żądaniu interfejsu API, przy użyciu pola environment_vars.
Poniższy przykład przypisuje wartość z sekretu utworzonego w podanym kodzie do zmiennej środowiskowej OPENAI_API_KEY.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
)
]
)
)
Zestaw SDK wdrożeń MLflow
Poniżej przedstawiono przykład tworzenia punktu końcowego obsługującego przy użyciu zestawu MLflow Deployments SDK. Podczas tworzenia i aktualizowania konfiguracji punktu końcowego modelu można podać listę specyfikacji tajnych zmiennych środowiskowych dla każdego obsługiwanego modelu w żądaniu interfejsu API, przy użyciu pola environment_vars.
Poniższy przykład przypisuje wartość z sekretu utworzonego w podanym kodzie do zmiennej środowiskowej OPENAI_API_KEY.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
)
Po utworzeniu lub zaktualizowaniu punktu końcowego serwowanie modelu automatycznie pobiera klucz tajny z zakresu tajemnic Databricks i wypełnia zmienną środowiskową dla kodu wnioskowania modelu.
Przykład notatnika
Zobacz poniższy notebook, aby zapoznać się z przykładem konfigurowania klucza API OpenAI dla LangChain Retrieval QA Chain wdrożonego za punktami końcowymi serwującymi modele, z wykorzystaniem zmiennych środowiskowych opartych na kluczach tajnych.