Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł zawiera podstawowe kroki wdrażania i wykonywania zapytań dotyczących modelu niestandardowego, czyli tradycyjnego modelu uczenia maszynowego przy użyciu obsługi modelu. Model musi być zarejestrowany w katalogu Unity lub w rejestrze modeli obszaru roboczego.
Aby dowiedzieć się więcej o obsłudze i wdrażaniu modeli generatywnej sztucznej inteligencji, zobacz następujące artykuły:
Krok 1. Rejestrowanie modelu
Istnieją różne sposoby rejestrowania modelu na potrzeby obsługi modeli:
| Technika rejestrowania | opis |
|---|---|
| Automatyczne rejestrowanie | Ta opcja jest automatycznie włączana w przypadku korzystania z środowiska Databricks Runtime na potrzeby uczenia maszynowego. Jest to najprostszy sposób, ale daje ci mniejszą kontrolę. |
| Rejestrowanie przy użyciu wbudowanych modułów MLflow | Możesz ręcznie zalogować model za pomocą wbudowanych wariantów modelu MLflow. |
Rejestrowanie niestandardowe za pomocą pyfunc |
Użyj tej opcji, jeśli masz model niestandardowy lub jeśli potrzebujesz dodatkowych kroków przed lub po wnioskowaniu. |
W poniższym przykładzie pokazano, jak zarejestrować model MLflow przy użyciu wariantu transformer oraz określić potrzebne parametry dla twojego modelu.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Po zalogowaniu swojego modelu upewnij się, że model jest zarejestrowany w Unity Catalog lub Model Registry MLflow.
Krok 2: Tworzenie punktu końcowego przy użyciu interfejsu użytkownika Serving
Po zarejestrowaniu modelu i przygotowaniu go do obsługi, możesz utworzyć punkt końcowy obsługujący model przy użyciu interfejsu użytkownika Serving.
Kliknij Obsługa na pasku bocznym, aby wyświetlić interfejs użytkownika Obsługa.
Kliknij Utwórz punkt końcowy obsługi.
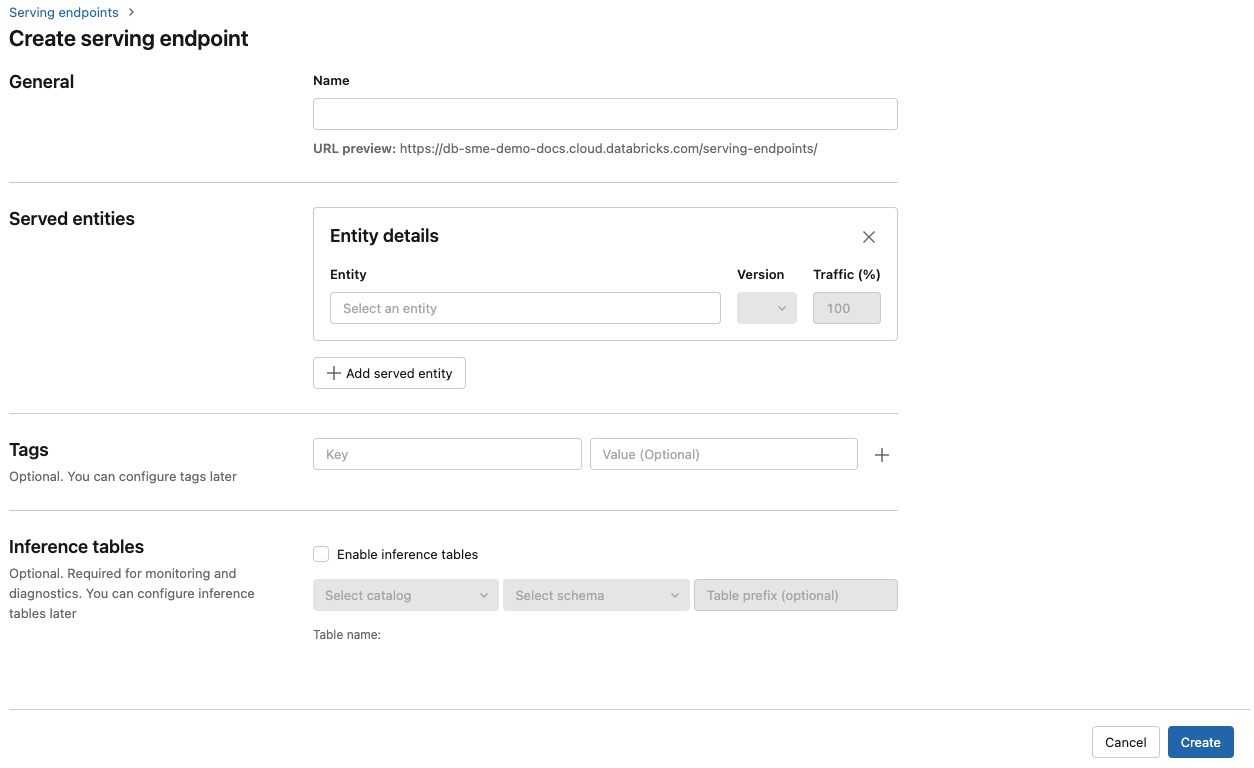
W polu Nazwa podaj nazwę punktu końcowego.
W sekcji Obsługiwane jednostki
- Kliknij pole Jednostka , aby otworzyć formularz Wybierz obsługiwaną jednostkę .
- Wybierz typ modelu, który chcesz obsłużyć. Formularz jest dynamicznie aktualizowany na podstawie wybranego wyboru.
- Wybierz model i wersję modelu, którą chcesz obsłużyć.
- Wybierz procent ruchu, który ma być kierowany do obsługiwanego modelu.
- Wybierz rozmiar obliczeniowy do użycia.
- W obszarze Skalowanie obliczeń w poziomie wybierz rozmiar skalowania zasobów obliczeniowych w poziomie, który odpowiada liczbie żądań, które może przetwarzać ten obsługiwany model w tym samym czasie. Ta liczba powinna być w przybliżeniu równa czasowi wykonywania modelu QPS x.
- Dostępne rozmiary są małe dla 0–4 żądań, średnich 8-16 żądań i dużych dla 16-64 żądań.
- Określ, czy punkt końcowy powinien być skalowany do zera, gdy nie jest używany.
Kliknij pozycję Utwórz. Wyświetlana jest strona Obsługa punktów końcowych z stanem punktu końcowego wyświetlanym jako Niegotowy.
Jeśli wolisz programowo utworzyć punkt końcowy za pomocą interfejsu API obsługującego usługę Databricks, zobacz Tworzenie niestandardowych punktów końcowych obsługujących model.
Krok 3. Wykonywanie zapytań względem punktu końcowego
Najprostszym i najszybszym sposobem testowania i wysyłania żądań skoringu do obsługiwanego modelu jest użycie interfejsu użytkownika Serving
Na stronie Obsługa punktu końcowego wybierz pozycję Punkt końcowy zapytania.
Wstaw dane wejściowe modelu w formacie JSON i kliknij pozycję Wyślij żądanie. Jeśli model został zarejestrowany przy użyciu przykładu danych wejściowych, kliknij pozycję Pokaż przykład , aby załadować przykład danych wejściowych.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Aby wysyłać żądania oceniania, skonstruuj kod JSON przy użyciu jednego z obsługiwanych kluczy i obiektu JSON odpowiadającego formatowi wejściowemu. Zobacz Tworzenie zapytań obsługujących punkty końcowe dla modeli niestandardowych , aby uzyskać obsługiwane formaty i wskazówki dotyczące wysyłania żądań oceniania przy użyciu interfejsu API.
Jeśli planujesz uzyskać dostęp do punktu końcowego obsługującego usługę poza interfejsem użytkownika usługi Azure Databricks, potrzebujesz elementu DATABRICKS_API_TOKEN.
Ważne
Jako najlepszą praktykę w zakresie bezpieczeństwa w scenariuszach produkcyjnych, Databricks zaleca używanie tokenów OAuth do komunikacji maszyna-maszyna do uwierzytelniania w środowisku produkcyjnym.
W przypadku testowania i rozwoju firma Databricks zaleca używanie osobistego tokenu dostępu należącego do głównych podmiotów usługi
Przykładowe zeszyty
Zapoznaj się z poniższym notatnikiem służącym do serwowania modelu MLflow transformers korzystając z obsługi modelu.
Wdrażanie notatnika modelu transformerów Hugging Face
Zapoznaj się z poniższym notatnikiem służącym do serwowania modelu MLflow pyfunc korzystając z obsługi modelu. Aby uzyskać dodatkowe informacje na temat dostosowywania wdrożeń modelu, zobacz Wdrażanie kodu w języku Python przy użyciu obsługi modelu.