Przykład rejestru modeli obszaru roboczego
Uwaga
Ta dokumentacja obejmuje rejestr modeli obszarów roboczych. Usługa Azure Databricks zaleca używanie modeli w wykazie aparatu Unity. Modele w wykazie aparatu Unity zapewniają scentralizowany nadzór nad modelami, dostęp między obszarami roboczymi, pochodzenie i wdrażanie. Rejestr modeli obszaru roboczego zostanie wycofany w przyszłości.
W tym przykładzie pokazano, jak za pomocą rejestru modeli obszaru roboczego utworzyć aplikację uczenia maszynowego, która prognozuje dzienne dane wyjściowe zasilania farmy wiatrowej. W przykładzie pokazano, jak:
- Śledzenie i rejestrowanie modeli za pomocą biblioteki MLflow
- Rejestrowanie modeli w rejestrze modeli
- Opisywanie modeli i przechodzenie etapu wersji modelu
- Integrowanie zarejestrowanych modeli z aplikacjami produkcyjnymi
- Wyszukiwanie i odnajdywanie modeli w rejestrze modeli
- Archiwizowanie i usuwanie modeli
W tym artykule opisano sposób wykonywania tych kroków przy użyciu interfejsów użytkownika i interfejsów API rejestru modeli MLflow i MLflow.
Aby zapoznać się z notesem wykonującym wszystkie te kroki przy użyciu interfejsów API śledzenia I rejestru MLflow, zobacz przykładowy notes rejestru modeli.
Ładowanie zestawu danych, trenowanie modelu i śledzenie za pomocą śledzenia MLflow
Przed zarejestrowaniem modelu w rejestrze modeli należy najpierw wytrenować i zarejestrować model podczas przebiegu eksperymentu. W tej sekcji pokazano, jak załadować zestaw danych farmy wiatrowej, wytrenować model i zarejestrować przebieg trenowania w usłudze MLflow.
Ładowanie zestawu danych
Poniższy kod ładuje zestaw danych zawierający dane pogodowe i dane wyjściowe zasilania dla farmy wiatrowej w Stany Zjednoczone. Zestaw danych zawiera wind directionfunkcje , wind speedi air temperature próbkowane co sześć godzin (raz w , raz w 00:00, i raz w 08:0016:00), a także dzienne zagregowane dane wyjściowe zasilania (power), w ciągu kilku lat.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Trenowanie modelu
Poniższy kod szkoli sieć neuronową przy użyciu protokołu TensorFlow Keras w celu przewidywania danych wyjściowych mocy na podstawie funkcji pogodowych w zestawie danych. Platforma MLflow służy do śledzenia hiperparametrów modelu, metryk wydajności, kodu źródłowego i artefaktów.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Rejestrowanie modelu i zarządzanie nim przy użyciu interfejsu użytkownika platformy MLflow
W tej sekcji:
- Tworzenie nowego zarejestrowanego modelu
- Eksplorowanie interfejsu użytkownika rejestru modeli
- Dodawanie opisów modelu
- Przenoszenie wersji modelu
Tworzenie nowego zarejestrowanego modelu
Przejdź do paska bocznego Przebiegi eksperymentów MLflow, klikając
 na pasku bocznym notesu usługi Azure Databricks.
na pasku bocznym notesu usługi Azure Databricks.
Znajdź przebieg platformy MLflow odpowiadający sesji trenowania modelu TensorFlow Keras i otwórz go w interfejsie użytkownika przebiegu platformy MLflow, klikając ikonę Wyświetl szczegóły przebiegu .
W interfejsie użytkownika platformy MLflow przewiń w dół do sekcji Artefakty i kliknij katalog o nazwie model. Kliknij wyświetlony przycisk Zarejestruj model .

Wybierz pozycję Utwórz nowy model z menu rozwijanego i wprowadź następującą nazwę modelu:
power-forecasting-model.Kliknij pozycję Zarejestruj. Spowoduje to zarejestrowanie nowego modelu o nazwie
power-forecasting-modeli utworzenie nowej wersji modelu:Version 1.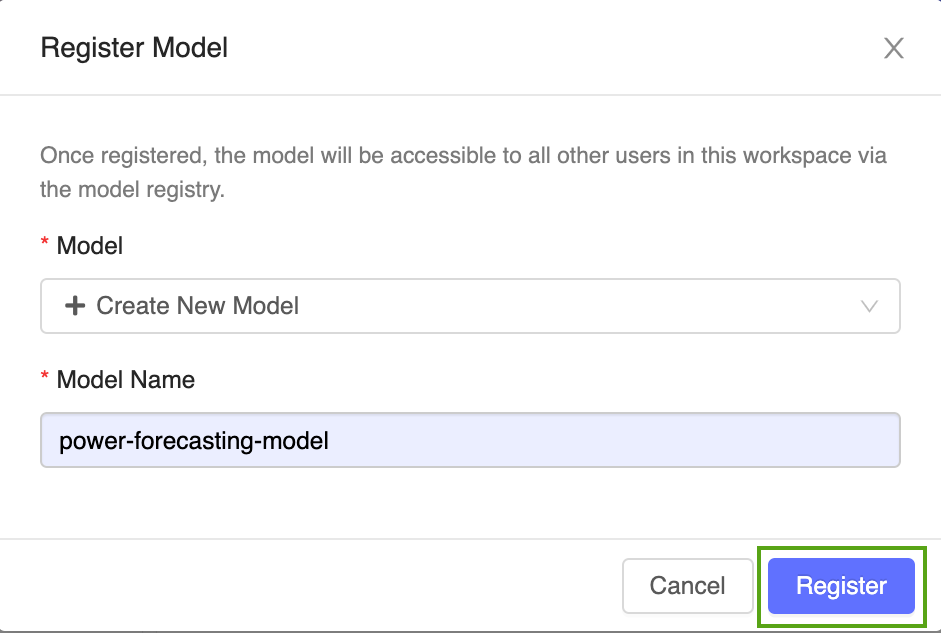
Po kilku chwilach interfejs użytkownika platformy MLflow wyświetla link do nowego zarejestrowanego modelu. Użyj tego linku, aby otworzyć nową wersję modelu w interfejsie użytkownika rejestru modeli MLflow.
Eksplorowanie interfejsu użytkownika rejestru modeli
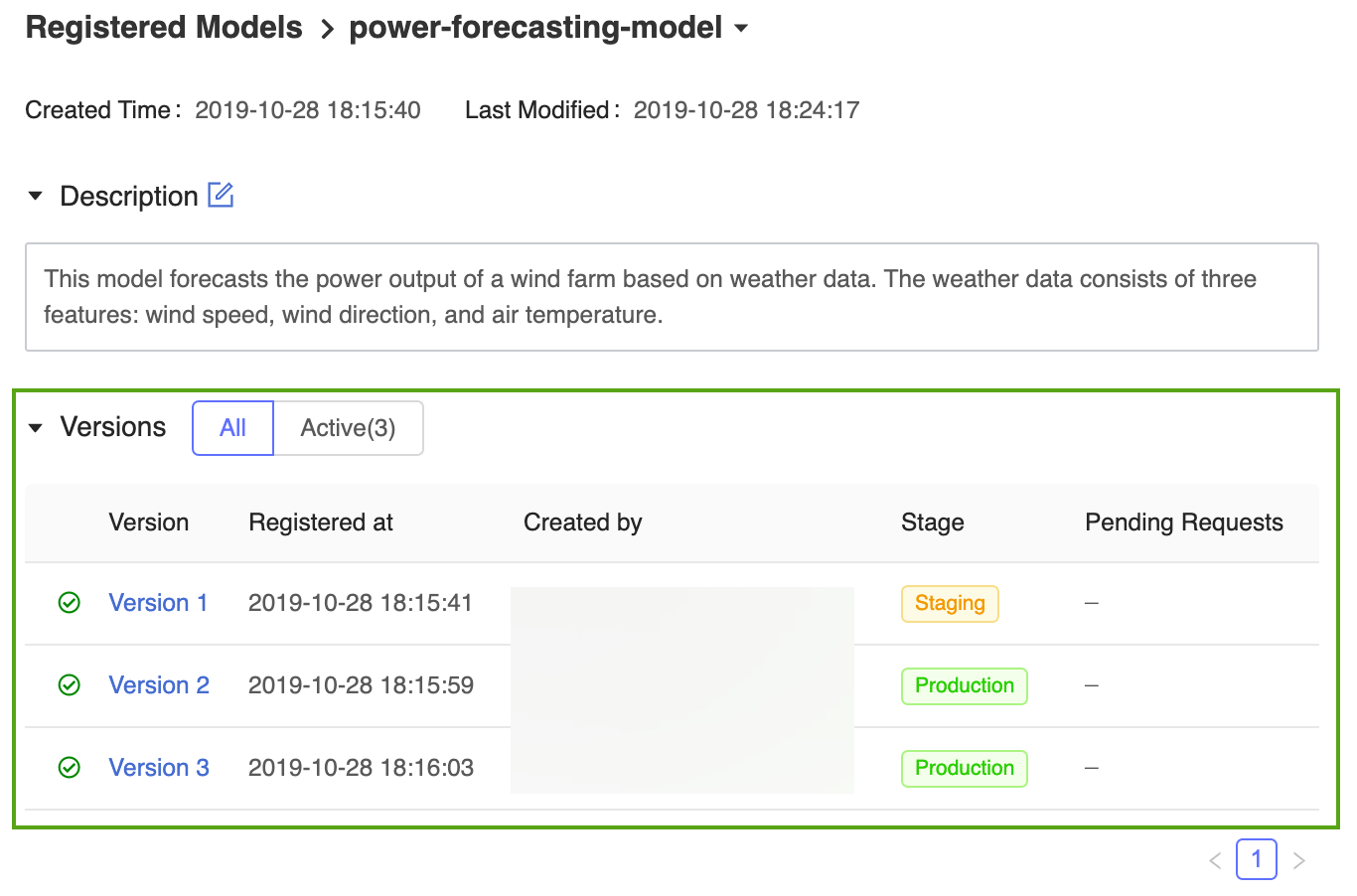
Strona wersji modelu w interfejsie użytkownika rejestru modeli MLflow zawiera informacje o zarejestrowanym modelu prognozowania, w tym o Version 1 jego autorze, czasie tworzenia i bieżącym etapie.
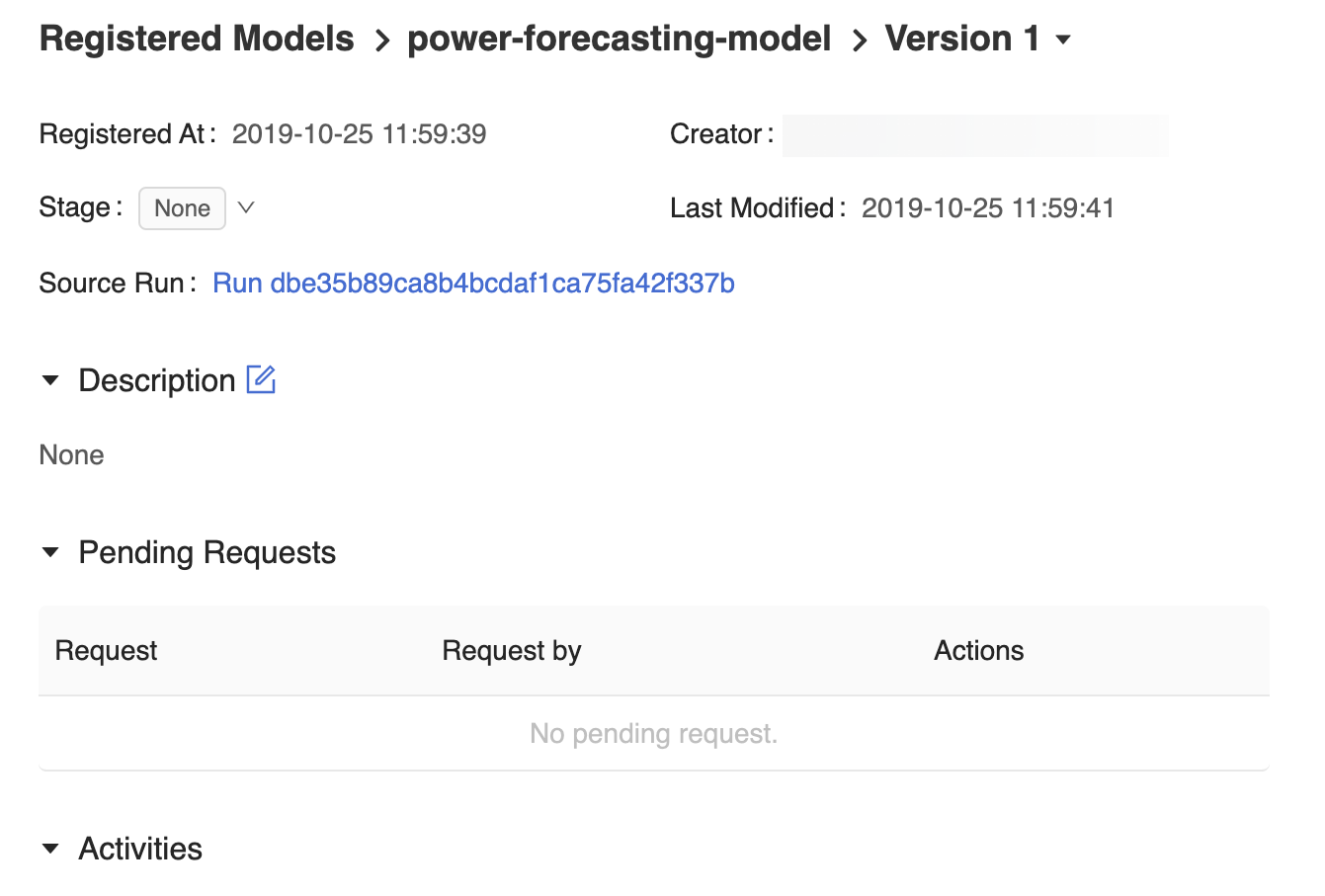
Strona wersji modelu udostępnia również link Uruchomienia źródła , który otwiera przebieg platformy MLflow, który został użyty do utworzenia modelu w interfejsie użytkownika przebiegu platformy MLflow. Z poziomu interfejsu użytkownika przebiegu platformy MLflow możesz uzyskać dostęp do linku Notes źródłowy , aby wyświetlić migawkę notesu usługi Azure Databricks używanego do trenowania modelu.


Aby wrócić do rejestru modeli MLflow, kliknij pozycję ![]() na pasku bocznym.
na pasku bocznym.
Na wyświetlonej stronie głównej rejestru modeli MLflow zostanie wyświetlona lista wszystkich zarejestrowanych modeli w obszarze roboczym usługi Azure Databricks, w tym ich wersje i etapy.
Kliknij link power-forecasting-model (Model prognozowania zasilania), aby otworzyć stronę zarejestrowanego modelu, która wyświetla wszystkie wersje modelu prognozowania.
Dodawanie opisów modelu
Opisy można dodawać do zarejestrowanych modeli i wersji modelu. Zarejestrowane opisy modeli są przydatne do rejestrowania informacji dotyczących wielu wersji modelu (np. ogólne omówienie problemu z modelowaniem i zestawu danych). Opisy wersji modelu są przydatne do opisywania unikatowych atrybutów określonej wersji modelu (np. metodologii i algorytmu używanego do opracowywania modelu).
Dodaj ogólny opis do zarejestrowanego modelu prognozowania zasilania. Kliknij ikonę
 wprowadź następujący opis:
wprowadź następujący opis:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.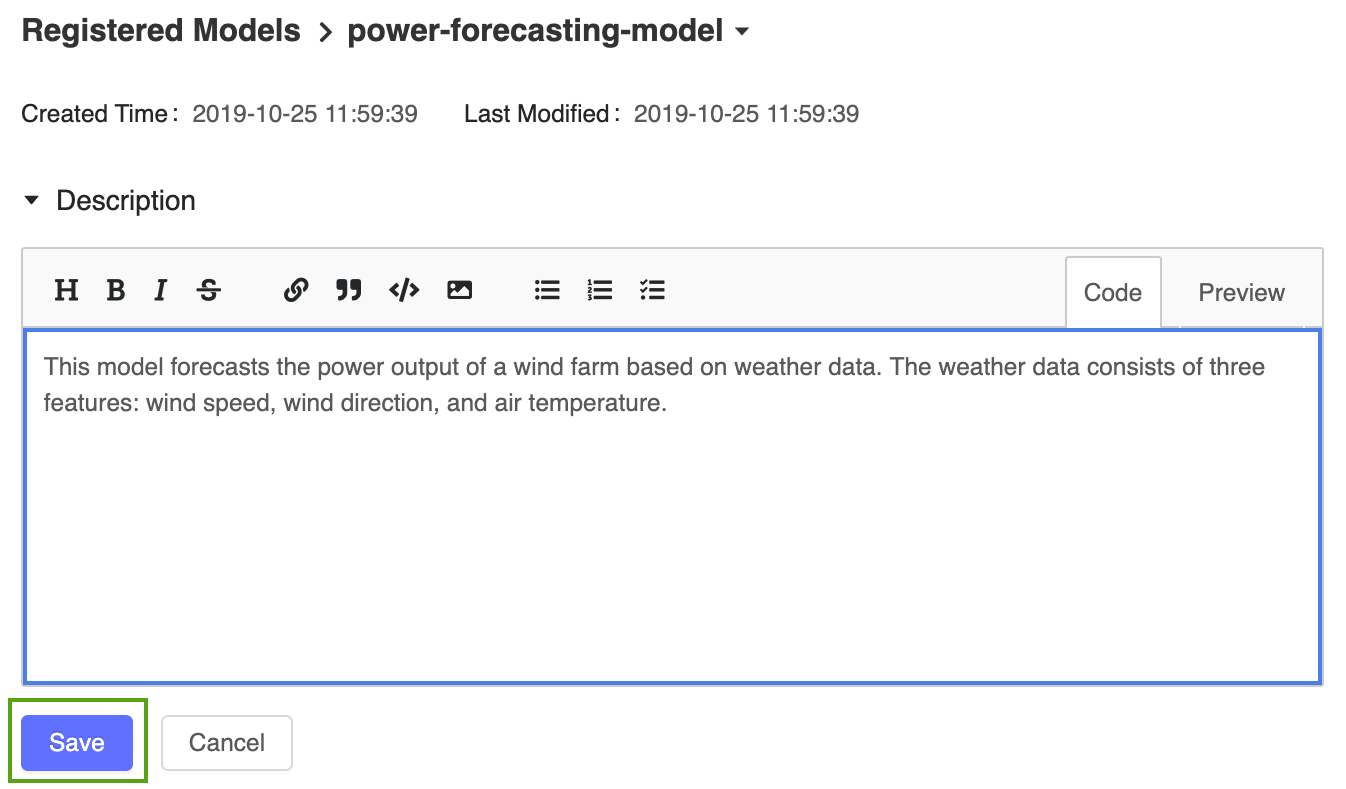
Kliknij przycisk Zapisz.
Kliknij link Wersja 1 ze strony zarejestrowanego modelu, aby wrócić do strony wersji modelu.
Kliknij ikonę
wprowadź następujący opis:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.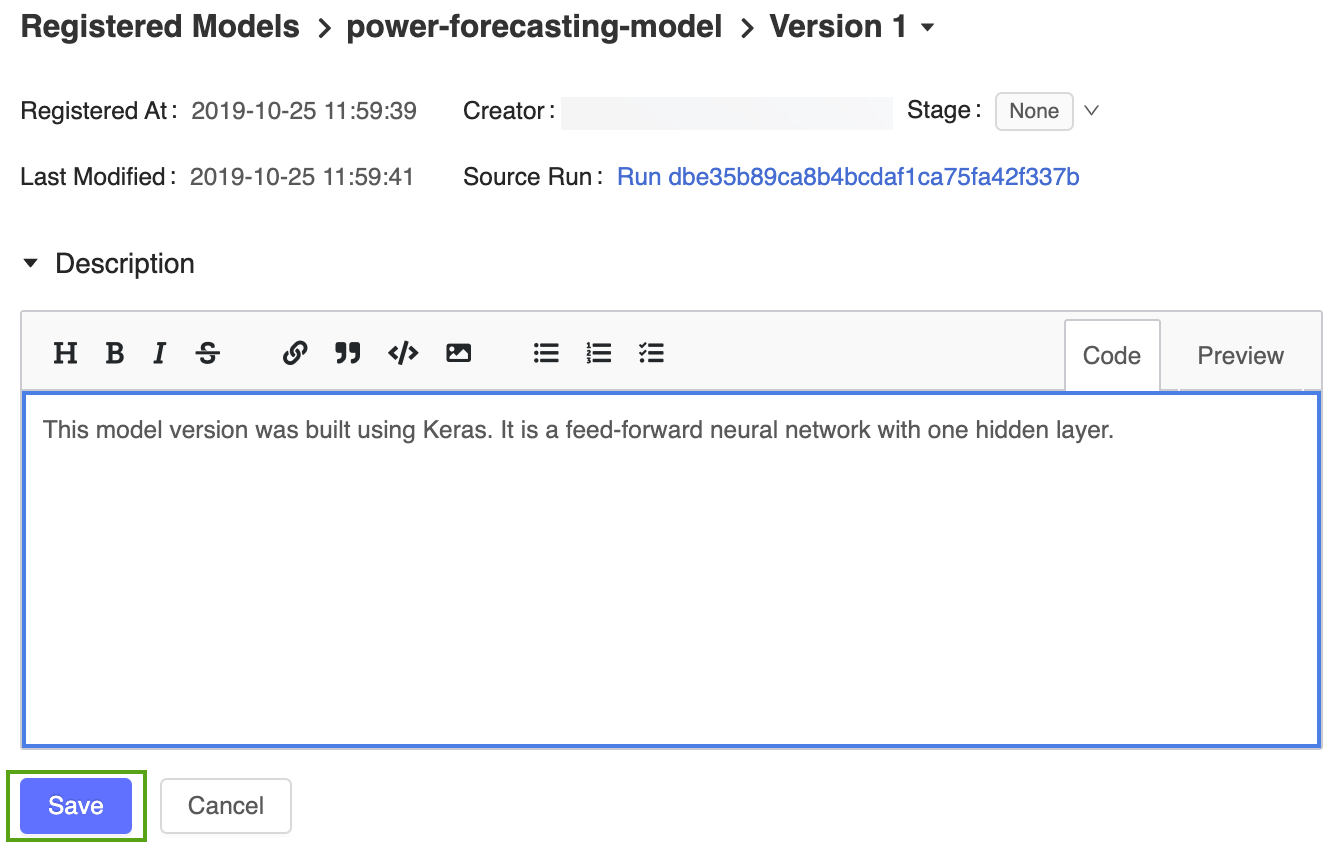
Kliknij przycisk Zapisz.
Przenoszenie wersji modelu
Rejestr modeli MLflow definiuje kilka etapów: None, Staging, Production i Archived. Każdy etap ma unikatowe znaczenie. Na przykład etap przejściowy jest przeznaczony do testowania modelu, podczas gdy produkcja jest przeznaczona dla modeli, które ukończyły procesy testowania lub przeglądu i zostały wdrożone w aplikacjach.
Kliknij przycisk Etap , aby wyświetlić listę dostępnych etapów modelu i dostępne opcje przejścia etapu.
Wybierz pozycję Przejście do —> produkcja i naciśnij przycisk OK w oknie potwierdzenia przejścia etapu, aby przenieść model do środowiska produkcyjnego.
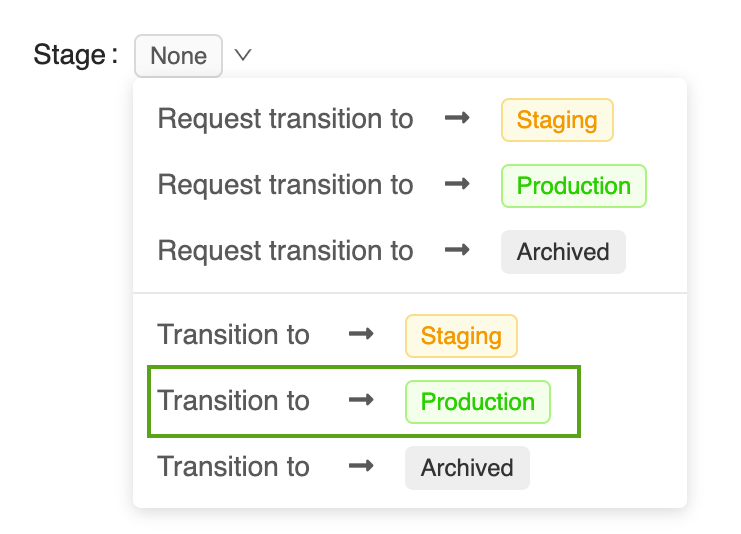
Po przejściu wersji modelu do środowiska produkcyjnego bieżący etap jest wyświetlany w interfejsie użytkownika, a wpis zostanie dodany do dziennika aktywności, aby odzwierciedlić przejście.


Rejestr modeli MLflow umożliwia wielu wersji modelu współużytkowania tego samego etapu. Podczas odwoływania się do modelu według etapu rejestr modeli używa najnowszej wersji modelu (wersja modelu z największym identyfikatorem wersji). Na stronie zarejestrowanego modelu są wyświetlane wszystkie wersje określonego modelu.
Rejestrowanie modelu i zarządzanie nim przy użyciu interfejsu API platformy MLflow
W tej sekcji:
- Programowe definiowanie nazwy modelu
- Rejestrowanie modelu
- Dodawanie opisów wersji modelu i modelu przy użyciu interfejsu API
- Przenoszenie wersji modelu i pobieranie szczegółów przy użyciu interfejsu API
Programowe definiowanie nazwy modelu
Teraz, gdy model został zarejestrowany i przeniesiony do środowiska produkcyjnego, możesz odwoływać się do niego przy użyciu interfejsów API programowych MLflow. Zdefiniuj nazwę zarejestrowanego modelu w następujący sposób:
model_name = "power-forecasting-model"
Rejestrowanie modelu
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Dodawanie opisów wersji modelu i modelu przy użyciu interfejsu API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Przenoszenie wersji modelu i pobieranie szczegółów przy użyciu interfejsu API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Ładowanie wersji zarejestrowanego modelu przy użyciu interfejsu API
Składnik MLflow Models definiuje funkcje ładowania modeli z kilku platform uczenia maszynowego. Na przykład mlflow.tensorflow.load_model() służy do ładowania modeli TensorFlow zapisanych w formacie MLflow i mlflow.sklearn.load_model() służy do ładowania modeli scikit-learn zapisanych w formacie MLflow.
Te funkcje mogą ładować modele z rejestru modeli MLflow.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Prognozowanie danych wyjściowych zasilania przy użyciu modelu produkcyjnego
W tej sekcji model produkcji służy do oceny danych prognozy pogody dla farmy wiatrowej. Aplikacja forecast_power() ładuje najnowszą wersję modelu prognozowania z określonego etapu i używa jej do prognozowania produkcji energii w ciągu najbliższych pięciu dni.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Tworzenie nowej wersji modelu
Klasyczne techniki uczenia maszynowego są również skuteczne w przypadku prognozowania mocy. Poniższy kod szkoli losowy model lasu przy użyciu biblioteki scikit-learn i rejestruje go w rejestrze mlflow.sklearn.log_model() modeli MLflow za pośrednictwem funkcji .
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Pobieranie identyfikatora nowej wersji modelu przy użyciu wyszukiwania rejestru modeli MLflow
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Dodawanie opisu do nowej wersji modelu
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Przenoszenie nowej wersji modelu do przejściowej i testowanie modelu
Przed wdrożeniem modelu w aplikacji produkcyjnej najlepszym rozwiązaniem jest przetestowanie go w środowisku przejściowym. Poniższy kod przenosi nową wersję modelu do warstwy Staging i ocenia jej wydajność.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Wdrażanie nowej wersji modelu w środowisku produkcyjnym
Po sprawdzeniu, czy nowa wersja modelu działa dobrze w środowisku przejściowym, poniższy kod przenosi model do środowiska produkcyjnego i używa dokładnie tego samego kodu aplikacji z sekcji Prognozowana moc wyjściowa z modelu produkcyjnego w celu utworzenia prognozy zużycia energii.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Istnieją teraz dwie wersje modelu prognozowania na etapie produkcji : wersja modelu wytrenowana w modelu Keras i wersja wytrenowana w środowisku scikit-learn.
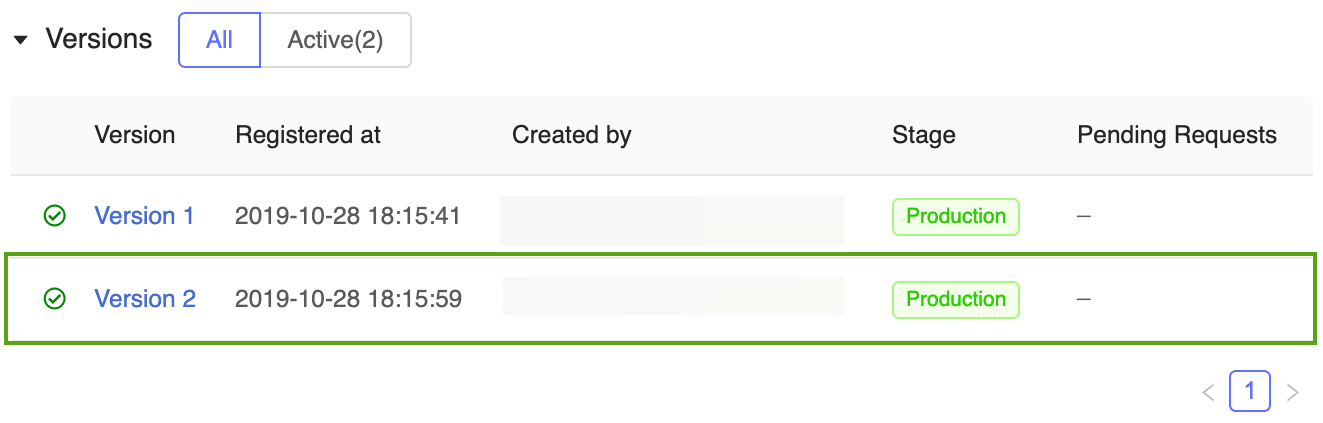
Uwaga
Podczas odwoływania się do modelu według etapu rejestr modeli MLflow automatycznie używa najnowszej wersji produkcyjnej. Dzięki temu można aktualizować modele produkcyjne bez zmieniania kodu aplikacji.
Archiwizowanie i usuwanie modeli
Gdy wersja modelu nie jest już używana, możesz ją zarchiwizować lub usunąć. Można również usunąć cały zarejestrowany model; Spowoduje to usunięcie wszystkich skojarzonych wersji modelu.
Archiwum Version 1 modelu prognozowania zasilania
Archiwum Version 1 modelu prognozowania zasilania, ponieważ nie jest już używane. Modele można archiwizować w interfejsie użytkownika rejestru modeli MLflow lub za pośrednictwem interfejsu API platformy MLflow.
Archiwum Version 1 w interfejsie użytkownika platformy MLflow
Aby zarchiwizować Version 1 model prognozowania zasilania:
Otwórz odpowiednią stronę wersji modelu w interfejsie użytkownika rejestru modeli MLflow:
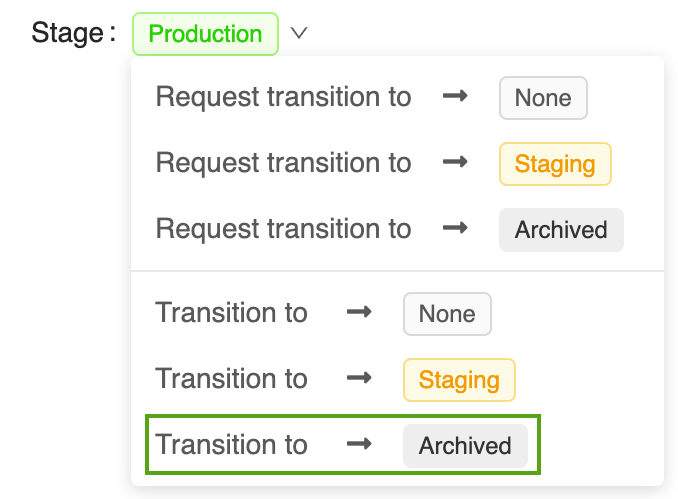
Kliknij przycisk Etap , wybierz pozycję Przejdź do —> zarchiwizowane:
Naciśnij przycisk OK w oknie potwierdzenia przejścia etapu.

Archiwizowanie Version 1 przy użyciu interfejsu API MLflow
Poniższy kod używa MlflowClient.update_model_version() funkcji do archiwizowania Version 1 modelu prognozowania zasilania.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Usuwanie Version 1 modelu prognozowania zasilania
Możesz również użyć interfejsu użytkownika platformy MLflow lub interfejsu API platformy MLflow do usunięcia wersji modelu.
Ostrzeżenie
Usuwanie wersji modelu jest trwałe i nie można go cofnąć.
Usuwanie Version 1 w interfejsie użytkownika platformy MLflow
Aby usunąć Version 1 model prognozowania zasilania:
Otwórz odpowiednią stronę wersji modelu w interfejsie użytkownika rejestru modeli MLflow.
Wybierz strzałkę listy rozwijanej obok identyfikatora wersji i kliknij przycisk Usuń.
Usuwanie Version 1 przy użyciu interfejsu API MLflow
client.delete_model_version(
name=model_name,
version=1,
)
Usuwanie modelu przy użyciu interfejsu API MLflow
Najpierw należy przenieść wszystkie pozostałe etapy wersji modelu do elementu Brak lub Zarchiwizowane.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)