Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Skalowanie automatyczne bazy danych Lakebase znajduje się w wersji beta w następujących regionach: eastus2, westeurope, westus.
Autoskalowanie bazy danych Lakebase to najnowsza wersja bazy danych Lakebase z automatycznym skalowaniem obliczeniowym, skalowaniem do zera, rozgałęzianiem i natychmiastowym przywracaniem. Aby zapoznać się z porównaniem funkcji z aprowizowaną usługą Lakebase, zobacz wybieranie między wersjami.
Pulpit nawigacyjny Metryki w interfejsie użytkownika usługi Lakebase udostępnia grafy do monitorowania metryk systemu i bazy danych. Dostęp do pulpitu nawigacyjnego Metryki można uzyskać na pasku bocznym w aplikacji Lakebase. Widoczne metryki obejmują użycie pamięci RAM, użycie procesora CPU, liczniki połączeń, rozmiar bazy danych, zakleszczenia, operacje wierszy, opóźnienia replikacji, wydajność pamięci podręcznej i rozmiar zestawu roboczego.
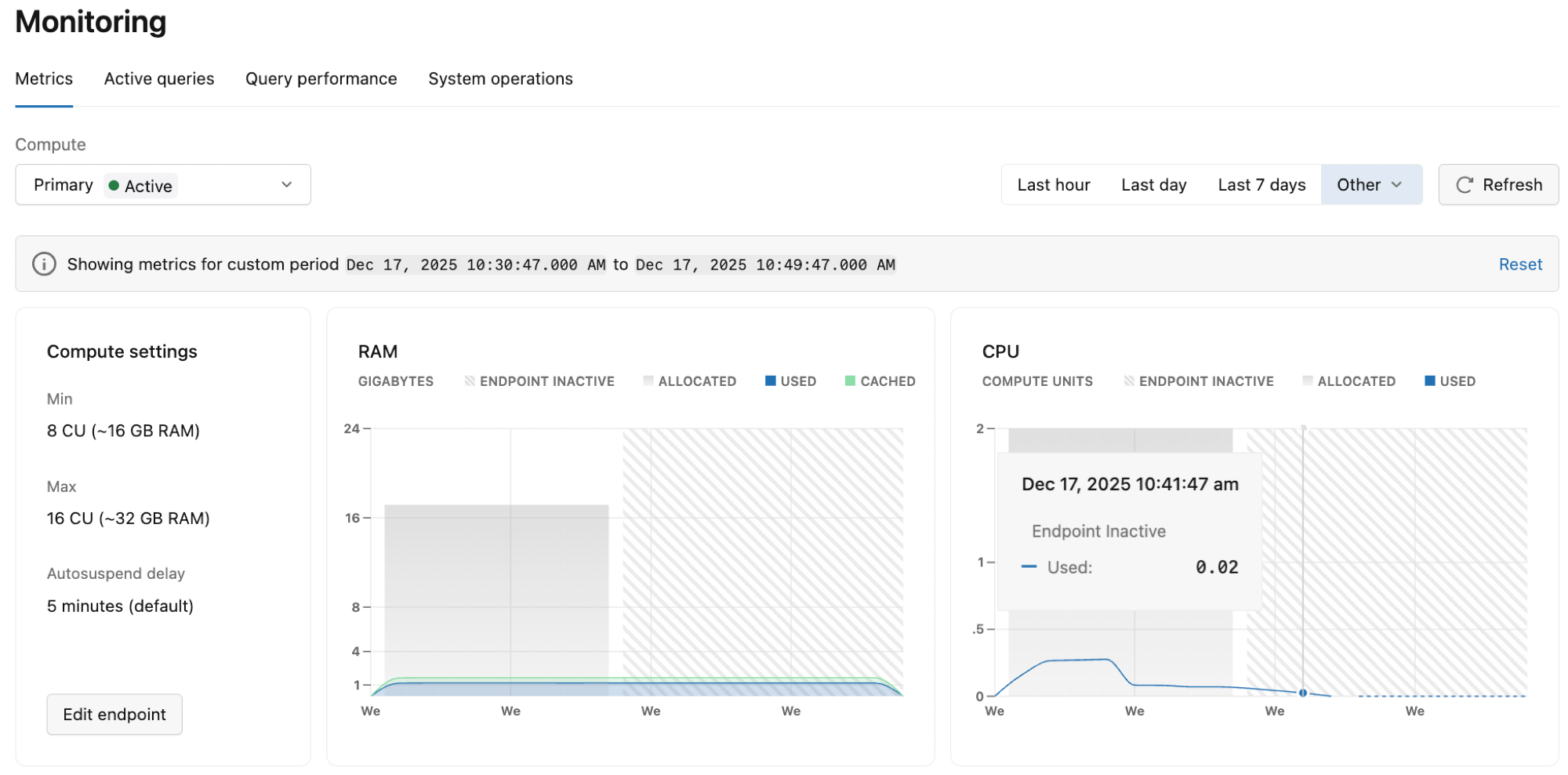
Na panelu zarządzania są wyświetlane wskaźniki dla wybranej gałęzi i zasobu obliczeniowego. Użyj menu rozwijanych, aby wyświetlić metryki dla innej gałęzi lub obliczeń. Możesz wybrać spośród wstępnie zdefiniowanych okresów czasu (Ostatnia godzina, Ostatni dzień, Ostatnie 7 dni) lub wybrać pozycję Inne dla dodatkowych opcji (Ostatnie 3 godziny, Ostatnie6 godzin, Ostatnie 12 godzin, Ostatnie 2 dni lub Niestandardowy). Użyj przycisku Odśwież , aby zaktualizować wyświetlane metryki.
Informacje o nieaktywnych obliczeniach
Jeśli wykresy nie wyświetlają żadnych danych, obliczenia mogą być nieaktywne z powodu skalowania do zera.
Gdy obliczenia są nieaktywne, wartości metryk spadną do 0, ponieważ do raportowania danych wymagane jest aktywne obliczenie. Okresy nieaktywne są wyświetlane jako wzorzec linii ukośnej na wykresach.
Jeśli wykresy nie wyświetlają żadnych danych, spróbuj wybrać inny okres lub spróbuj ponownie później po zebraniu większej ilości danych użycia.
RAM
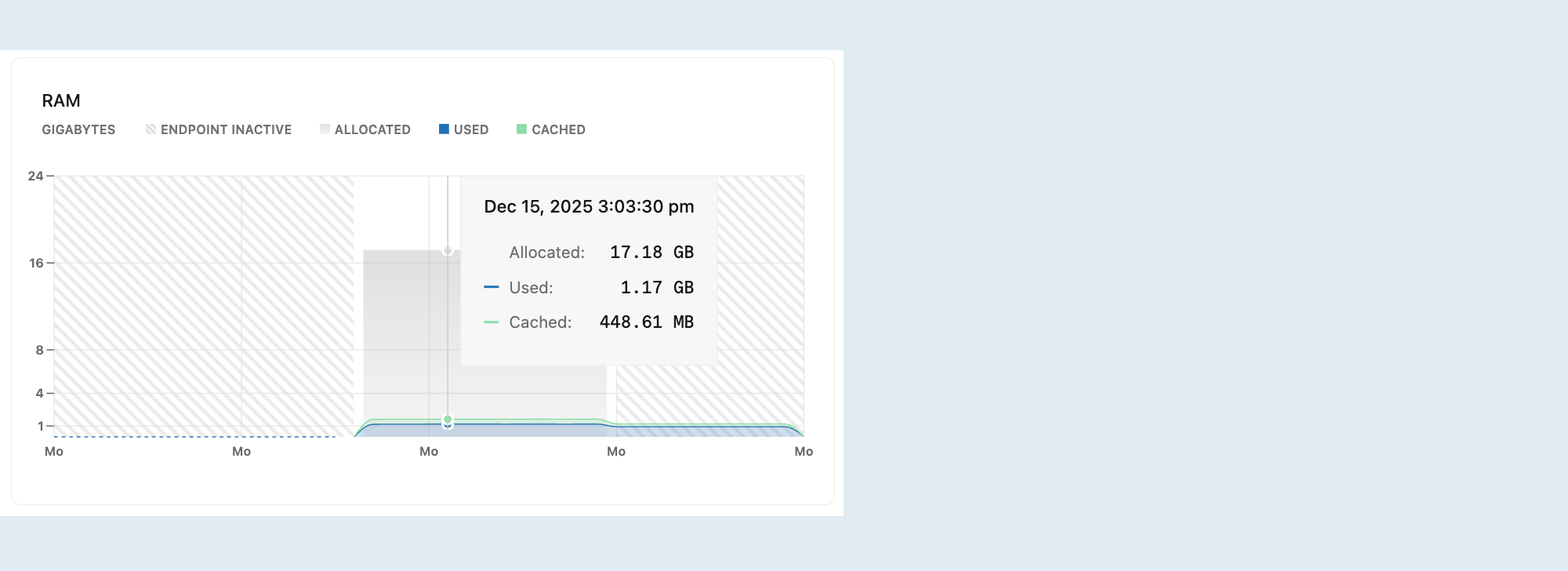
Ten wykres przedstawia przydzieloną pamięć RAM i użycie w czasie dla wybranego obliczenia.
Zawiera ona następujące metryki:
Przydzielone: ilość przydzielonej pamięci RAM.
Pamięć RAM jest przydzielana zgodnie z rozmiarem obliczeń lub konfiguracją skalowania automatycznego . Dzięki skalowaniu automatycznemu przydzielona pamięć RAM zwiększa się i zmniejsza w miarę skalowania obliczeń w górę i w dół w odpowiedzi na obciążenie. Jeśli skalowanie do zera jest włączone, a obliczenia przechodzą do stanu bezczynności po braku aktywności, przydzielona pamięć RAM spadnie do 0.
Używane: ilość używanej pamięci RAM.
Wykres kresuje linię pokazującą użycie pamięci RAM. Jeśli linia regularnie osiąga maksymalną przydzieloną pamięć RAM, rozważ zwiększenie rozmiaru obliczeń. Aby uzyskać informacje na temat opcji rozmiaru zasobów obliczeniowych, zobacz Ustalanie rozmiaru zasobów obliczeniowych.
Buforowane: ilość danych buforowanych w pamięci przez poprzednie zapytania i operacje.
CPU
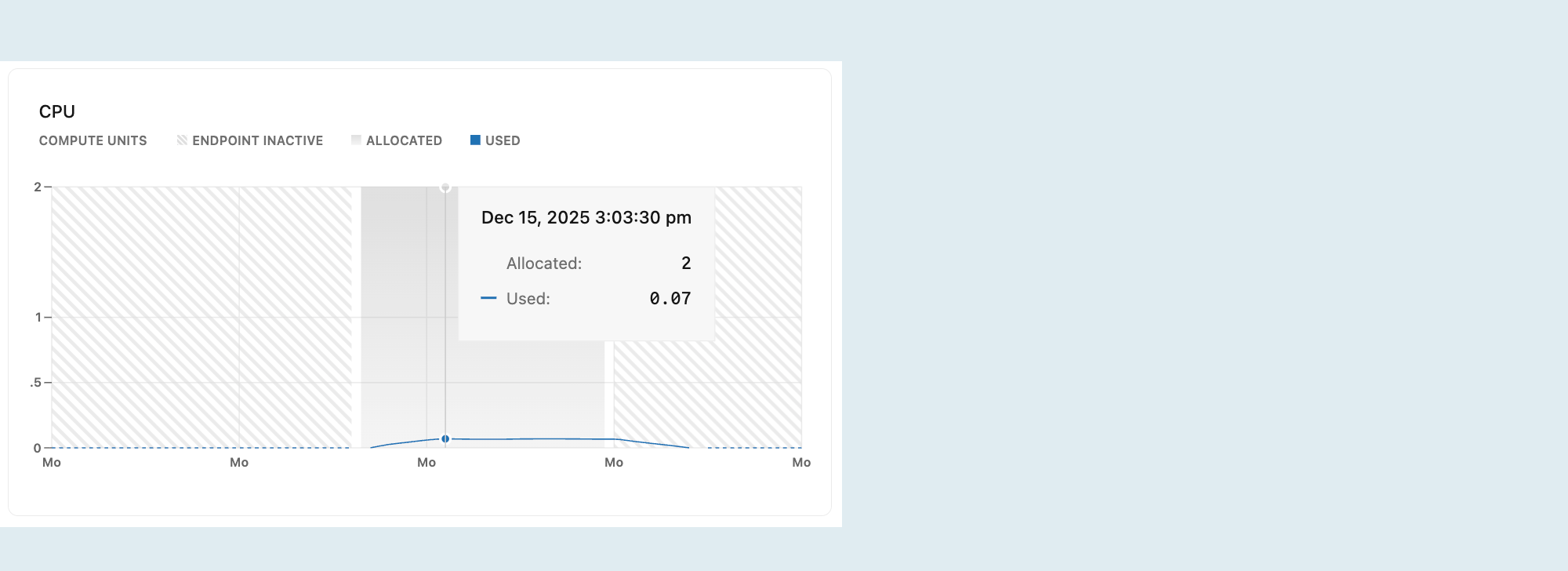
Na tym wykresie przedstawiono przydzielony procesor CPU i jego użycie w czasie dla wybranej jednostki obliczeniowej.
Przydzielone: przydzielona moc CPU.
CPU jest przydzielany zgodnie z rozmiarem twojego obciążenia obliczeniowego lub konfiguracją skalowania automatycznego. Dzięki skalowaniu automatycznemu przydzielona moc CPU zwiększa się i zmniejsza w miarę skalowania mocy obliczeniowej w odpowiedzi na zmieniające się obciążenie. Jeśli skalowanie do zera jest włączone, a obliczenia przechodzą do stanu bezczynności po braku aktywności, przydzielone użycie procesora CPU spadnie do 0.
Używane: ilość używanego procesora CPU w jednostkach obliczeniowych (CU).
Jeśli nakreślona linia regularnie osiąga maksymalny przydzielony procesor CPU, rozważ zwiększenie rozmiaru obliczeń. Aby uzyskać informacje na temat opcji rozmiaru zasobów obliczeniowych, zobacz Ustalanie rozmiaru zasobów obliczeniowych.
Liczba połączeń
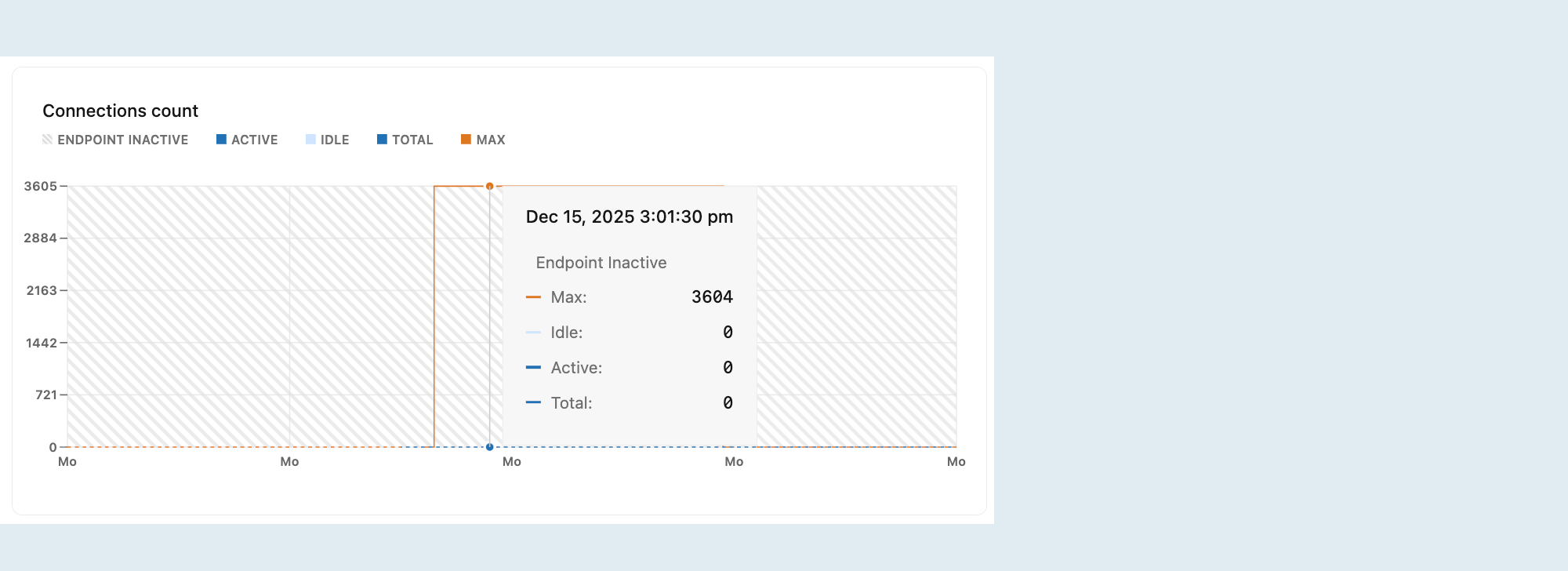
Wykres Liczba połączeń przedstawia maksymalną liczbę połączeń, liczbę bezczynnych połączeń, liczbę aktywnych połączeń i łączną liczbę połączeń w czasie dla wybranego obliczenia.
Aktywne: liczba aktywnych połączeń dla wybranego obliczenia.
Monitorowanie aktywnych połączeń ułatwia zrozumienie obciążenia bazy danych. Jeśli liczba aktywnych połączeń jest stale wysoka, baza danych może być obciążona dużym obciążeniem, co może prowadzić do problemów z wydajnością, takich jak powolne czasy odpowiedzi na zapytania.
Bezczynność: liczba bezczynnych połączeń dla wybranego obliczenia.
Bezczynne połączenia są otwarte, ale nie są obecnie używane. Chociaż kilka bezczynnych połączeń jest zwykle nieszkodliwe, duża liczba może zużywać niepotrzebne zasoby, pozostawiając mniej miejsca na aktywne połączenia i potencjalnie wpływające na wydajność. Identyfikowanie i zamykanie niepotrzebnych bezczynnych połączeń może pomóc zwolnić zasoby.
Suma: suma aktywnych i bezczynnych połączeń dla wybranego obliczenia.
Maksymalna: maksymalna liczba równoczesnych połączeń dozwolonych dla rozmiaru obliczeniowego.
Linia Max pomaga wizualizować, jak blisko jesteś do osiągnięcia limitu połączenia. Jeśli łączna liczba połączeń zbliża się do linii Maksymalna, rozważ:
- Zwiększanie rozmiaru obliczeniowego w celu umożliwienia większej liczby połączeń
- Optymalizacja zarządzania połączeniami aplikacji (przy użyciu buforowania połączeń, natychmiastowe zamykanie nieużywanych połączeń i unikanie długotrwałych bezczynnych połączeń)
Limit połączenia jest definiowany przez ustawienie Postgres max_connections i jest określany przez konfigurację rozmiaru obliczeniowego. Aby uzyskać pełną listę maksymalnej liczby połączeń według rozmiaru obliczeniowego, zobacz Specyfikacje obliczeniowe.
Rozmiar bazy danych
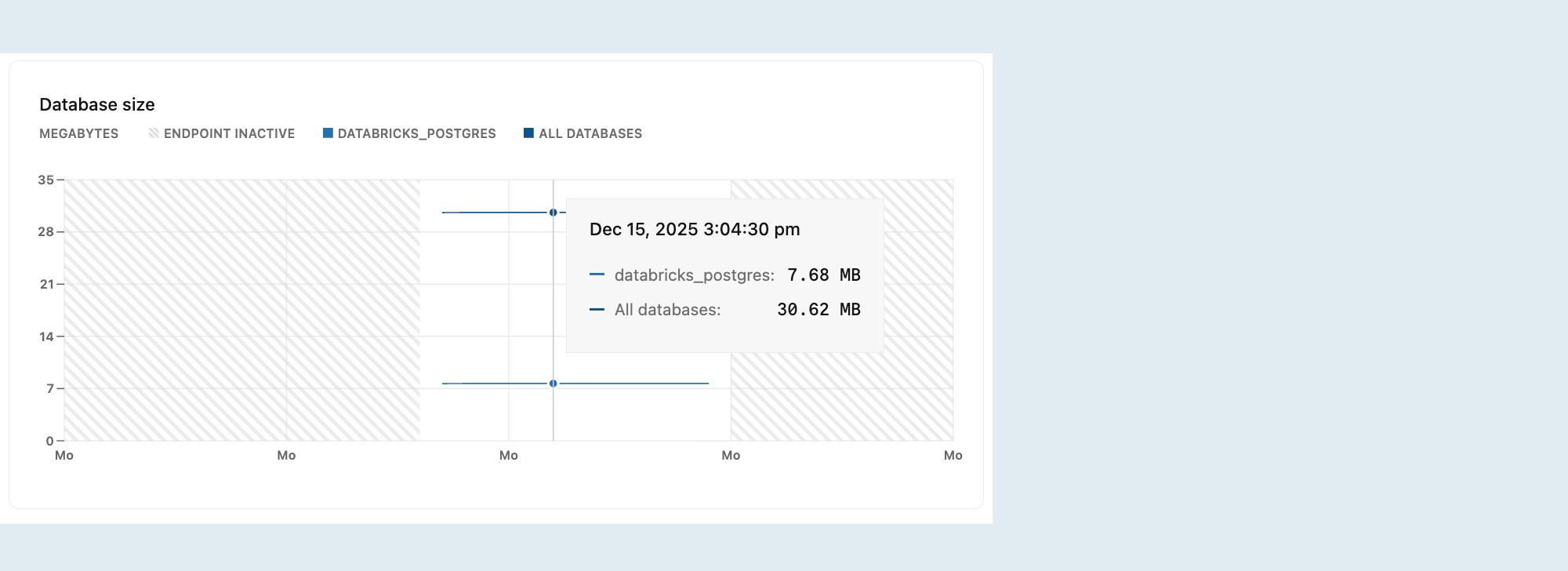
Wykres Rozmiar bazy danych przedstawia rozmiar danych logicznych (rozmiar rzeczywistych danych) dla wybranej bazy danych lub wszystkich baz danych w wybranej gałęzi.
Uwaga / Notatka
Rozmiar logiczny reprezentuje rozmiar danych zgłoszony przez usługę Postgres, w tym tabele i indeksy.
Uwaga / Notatka
Metryki rozmiaru bazy danych są wyświetlane tylko wtedy, gdy obliczenia są aktywne. Gdy obliczenia są bezczynne, wartości rozmiaru bazy danych nie są zgłaszane, a wykres pokazuje zero, mimo że dane mogą być obecne.
Zakleszczenia
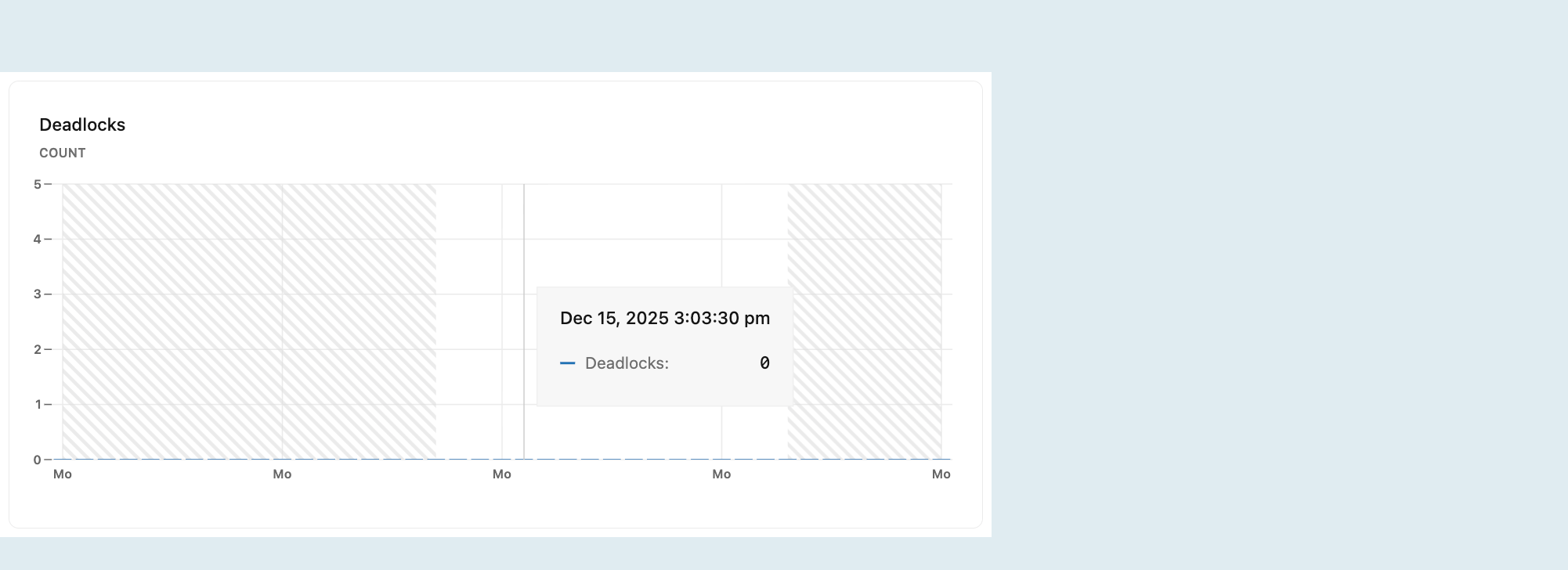
Wykres zakleszczeń pokazuje liczbę zakleszczeń w miarę upływu czasu.
Zakleszczenia występują, gdy co najmniej dwie transakcje jednocześnie blokują się, przechowując zasoby, których potrzebują inne transakcje, tworząc cykl zależności, który uniemożliwia kontynuowanie jakiejkolwiek transakcji. Może to prowadzić do problemów z wydajnością lub błędów aplikacji. Aby dowiedzieć się więcej o zakleszczeniach w usłudze Postgres, zapoznaj się z dokumentacją bazy danych PostgreSQL dotyczącą zakleszczeń.
Wiersze
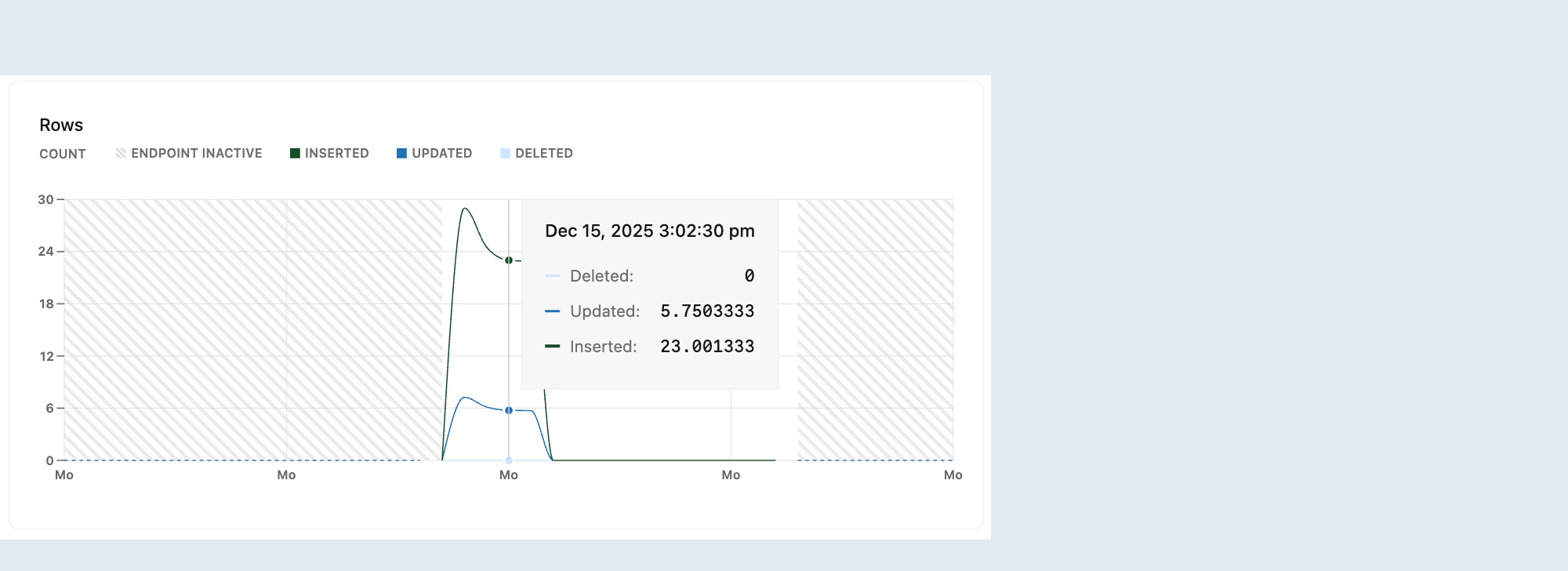
Wykres wierszy pokazuje liczbę wierszy usuniętych, zaktualizowanych i wstawionych w czasie. Metryki wierszy są resetowane do zera przy każdym ponownym uruchomieniu obliczeń.
Śledzenie wstawionych, zaktualizowanych i usuniętych wierszy w czasie zapewnia wgląd w wzorce aktywności bazy danych. Te dane umożliwiają identyfikowanie trendów lub nieprawidłowości, takich jak nagłe wzrosty wstawień lub nietypowa liczba usunięć.
Uwaga / Notatka
Metryki wierszy przechwytują tylko zmiany na poziomie wiersza (INSERT, , DELETE) i wykluczają operacje na poziomie tabeli, UPDATEtakie jak TRUNCATE.
Bajty związane z opóźnieniem replikacji
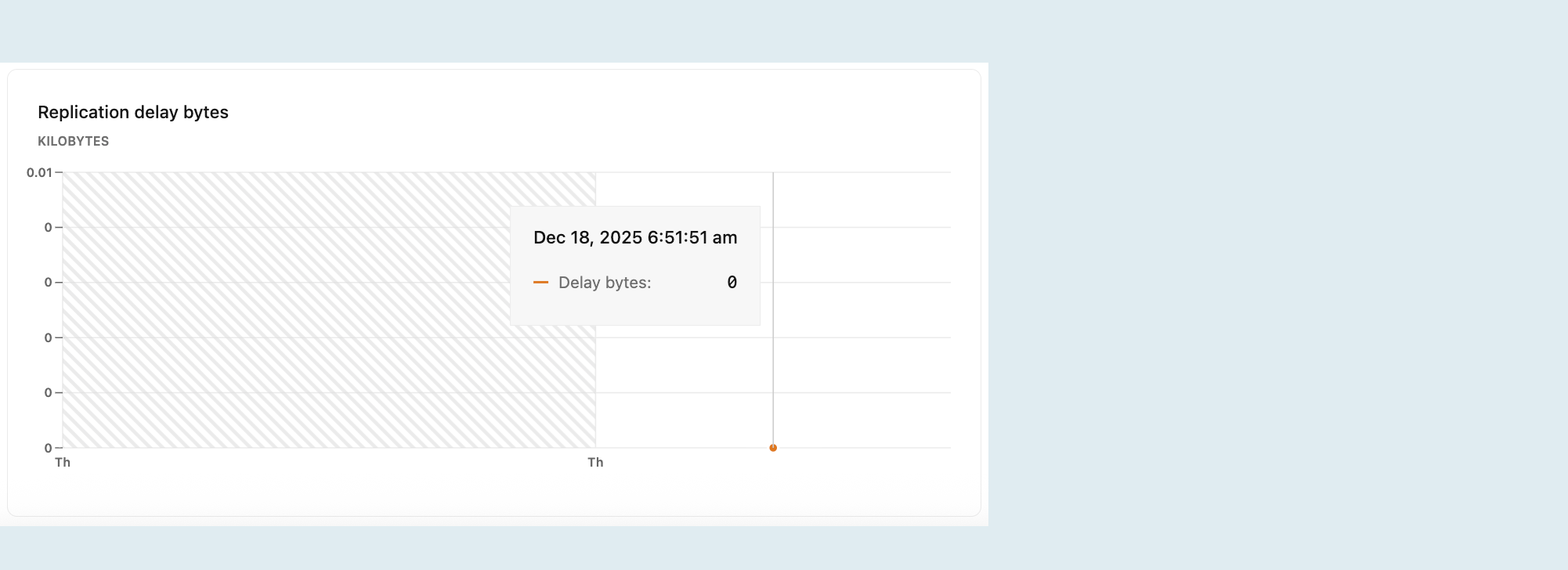
Wykres opóźnienia replikacji w bajtach przedstawia całkowity rozmiar danych, w bajtach, które zostały wysłane z głównych zasobów obliczeniowych, ale nie zostały jeszcze zastosowane na repliki. Większa wartość wskazuje na wyższe zaległości danych oczekujących na replikację, co może sugerować problemy z wydajnością replikacji lub dostępnością zasobów na replikach.
Uwaga / Notatka
Ten wykres jest widoczny tylko podczas wybierania procesora repliki do odczytu z menu rozwijanego 'Obliczenia'. Aby uzyskać więcej informacji na temat replik do odczytu, zobacz Repliki do odczytu.
Opóźnienie replikacji w sekundach
Wykres Opóźnienie replikacji (sekundy) pokazuje opóźnienie czasu (w sekundach) między ostatnią transakcją zatwierdzoną w ramach obliczeń podstawowych a zastosowaniem tej transakcji w repliki. Wyższa wartość sugeruje, że replika znajduje się za repliką podstawową, potencjalnie ze względu na opóźnienie sieci, duże obciążenie replikacji lub ograniczenia zasobów w repliki.
Uwaga / Notatka
Ten graf jest widoczny tylko podczas wybierania obliczeń repliki do odczytu z menu rozwijanego Obliczenia. Aby uzyskać więcej informacji na temat replik do odczytu, zobacz Repliki do odczytu.
Szybkość trafień lokalnej pamięci podręcznej plików
Wykres współczynnika trafień lokalnej pamięci podręcznej plików przedstawia odsetek żądań odczytu realizowanych przez lokalną pamięć podręczną plików. Zapytania, które nie są obsługiwane z buforów udostępnionych Postgres ani z lokalnej pamięci podręcznej plików, pobierają dane z magazynu, co jest bardziej kosztowne i może spowodować wolniejsze działanie zapytań.
W przypadku obciążeń OLTP należy dążyć do osiągnięcia szybkości trafień pamięci podręcznej wynoszącej 99% lub lepszej. Jeśli szybkość jest niższa niż 99%, zestaw roboczy może nie mieścić się w pamięci, co skutkuje niższą wydajnością. Aby zwiększyć szybkość trafień pamięci podręcznej, zwiększ rozmiar obliczeniowy, aby rozszerzyć lokalną pamięć podręczną plików. Idealny stosunek zależy od obciążenia — obciążenia z sekwencyjnymi skanowaniami dużych tabel mogą działać z nieco niższym współczynnikiem.
:::info — informacje o lokalnej pamięci podręcznej plików
Lokalna pamięć podręczna plików (LFC) to warstwa buforowania, która przechowuje często używane dane w pamięci lokalnej obliczeń. Po zażądaniu danych usługa Postgres najpierw sprawdza udostępnione bufory, a następnie LFC, a w razie potrzeby pobiera dane z magazynu. Rozmiar LFC dostosowuje się do zasobów obliczeniowych Twojego komputera — może używać do 75% pamięci RAM komputera. Na przykład obliczenia z 8 GB pamięci RAM mają lokalną pamięć podręczną plików o rozmiarze 6 GB. Aby uzyskać optymalną wydajność, dostosuj zasoby obliczeniowe tak, aby zestaw roboczy mieścił się w lokalnej pamięci podręcznej plików.
:::
Rozmiar zestawu roboczego
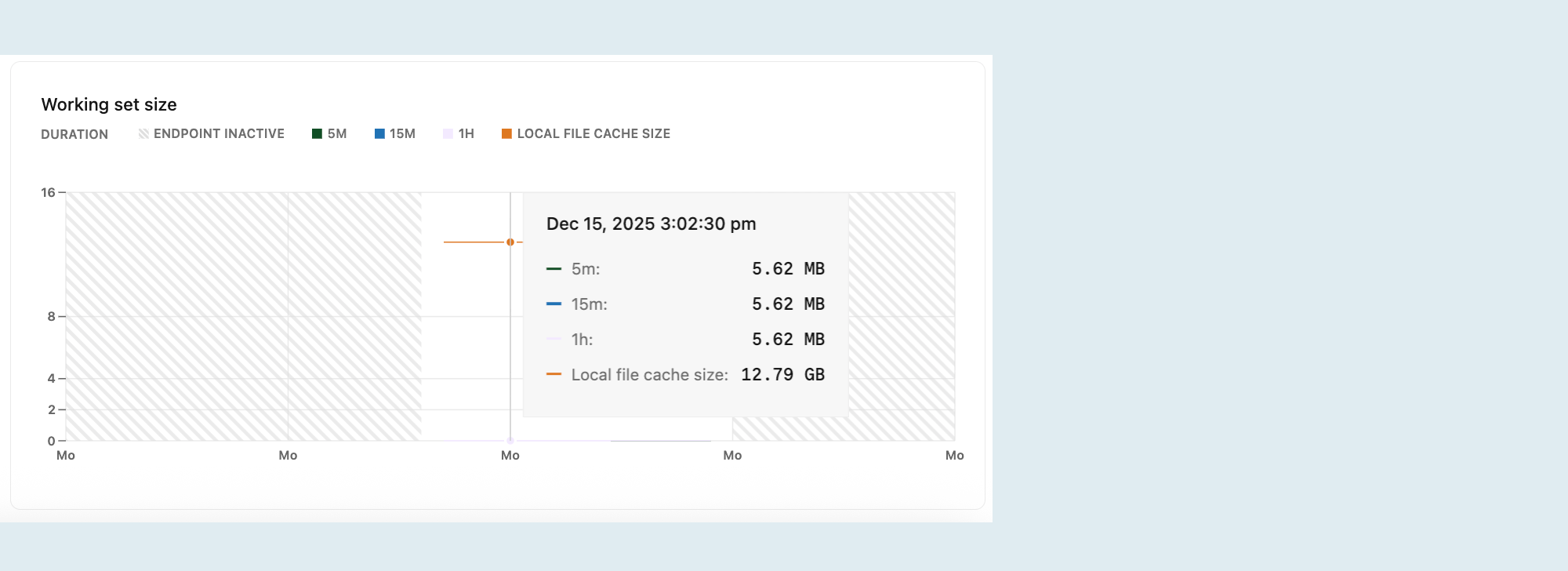
Zestaw roboczy jest rozmiarem odrębnego zestawu stron Postgres (danych relacyjnych i indeksów) używanych w danym interwale czasu. Aby uzyskać optymalną wydajność i spójne opóźnienie, należy określić rozmiar zasobów obliczeniowych, tak aby zestaw roboczy mieścił się w lokalnej pamięci podręcznej plików w celu uzyskania szybkiego dostępu.
Wykres przedstawiający wielkość zestawu roboczego wizualizuje ilość danych, do których uzyskano dostęp (obliczana jako liczba unikatowych stron pomnożona przez rozmiar strony) w danym interwale. Na wykresie są wyświetlane następujące elementy:
5 mln (5 minut): dane, do których uzyskiwano dostęp w ciągu ostatnich 5 minut.
15 m (15 minut): dane dostępne w ciągu ostatnich 15 minut.
1h (1 godzina): dane dostępne w ciągu ostatniej godziny.
Rozmiar lokalnej pamięci podręcznej plików: rozmiar lokalnej pamięci podręcznej plików określony przez rozmiar obliczeniowy. Większe komputery mają większe pamięci podręczne.
Aby uzyskać optymalną wydajność, lokalna pamięć podręczna plików powinna być większa niż rozmiar zestawu roboczego dla danego interwału czasu. Jeśli rozmiar zestawu roboczego jest większy niż rozmiar lokalnej pamięci podręcznej plików, zwiększ maksymalny rozmiar zasobów obliczeniowych, aby zwiększyć szybkość trafień pamięci podręcznej i osiągnąć lepszą wydajność. Aby uzyskać informacje na temat opcji ustalania rozmiaru i specyfikacji obliczeń, zobacz Specyfikacje obliczeniowe.
Jeśli wzorzec obciążenia nie zmienia się znacznie w czasie, porównaj rozmiar zestawu roboczego 1-godzinny z lokalnym rozmiarem pamięci podręcznej plików i upewnij się, że rozmiar zestawu roboczego jest mniejszy niż rozmiar lokalnej pamięci podręcznej plików.
Informacje pokrewne
- Aktywne zapytania
- Wydajność zapytania
- Operacje systemowe
- Skalowanie automatyczne
- Skalowanie do zera