Luki między zadaniami platformy Spark
W związku z tym widać luki na osi czasu zadań, takie jak następujące:
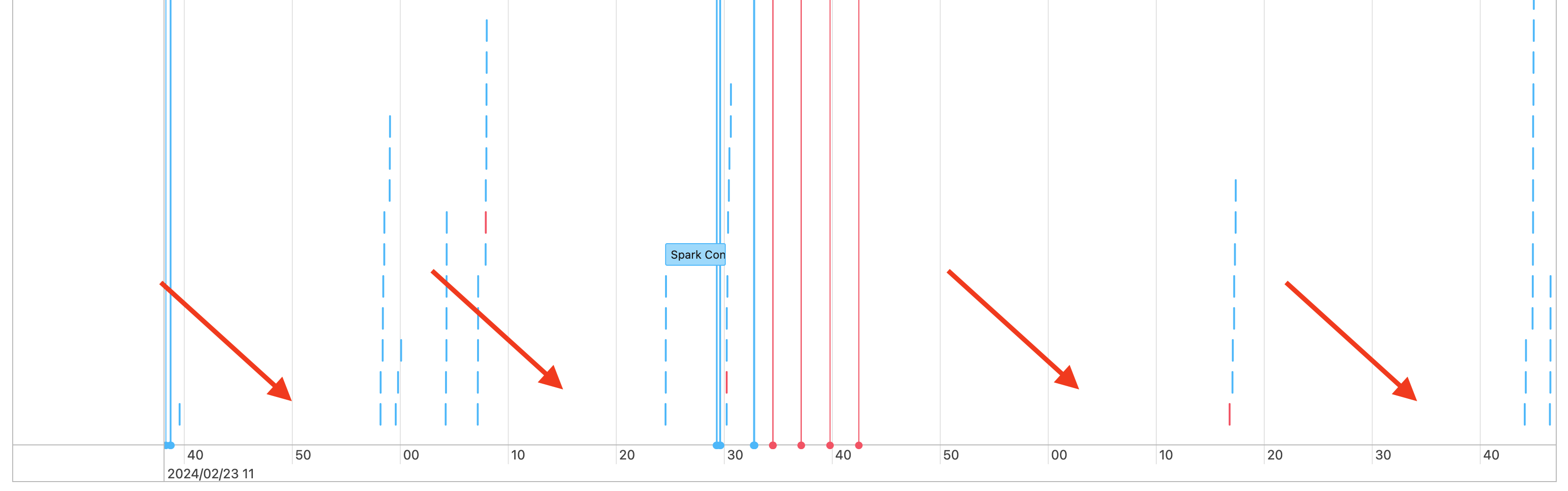
Istnieje kilka powodów, dla których może się to wydarzyć. Jeśli luki stanowią dużą część czasu spędzonego na obciążeniu, musisz ustalić, co powoduje te luki i czy jest to oczekiwane, czy nie. Istnieje kilka rzeczy, które mogą wystąpić podczas przerw:
- Nie ma do zrobienia żadnej pracy
- Sterownik kompiluje złożony plan wykonywania
- Wykonywanie kodu innego niż spark
- Sterownik jest przeciążony
- Klaster działa nieprawidłowo
Brak pracy
W przypadku obliczeń wszystkich celów nie trzeba wykonywać żadnych czynności, jest najbardziej prawdopodobnym wyjaśnieniem luk. Ponieważ klaster jest uruchomiony, a użytkownicy przesyłają zapytania, oczekiwane są luki. Te luki to czas między przesyłaniem zapytań.
Złożony plan wykonania
Na przykład jeśli używasz withColumn() w pętli, tworzy bardzo kosztowny plan do przetworzenia. Luki mogą być czasem, w jaki czynnik wydaje po prostu budowanie i przetwarzanie planu. Jeśli tak jest, spróbuj uprościć kod. Użyj selectExpr() polecenia , aby połączyć wiele withColumn() wywołań w jedno wyrażenie lub przekonwertować kod na język SQL. Nadal możesz osadzić kod SQL w kodzie języka Python, używając języka Python do manipulowania zapytaniem za pomocą funkcji ciągów. To często rozwiązuje ten typ problemu.
Wykonywanie kodu innego niż Spark
Kod platformy Spark jest napisany w języku SQL lub przy użyciu interfejsu API platformy Spark, takiego jak PySpark. Każde wykonanie kodu, które nie jest platformą Spark, będzie wyświetlane na osi czasu jako luki. Możesz na przykład mieć pętlę w języku Python, która wywołuje natywne funkcje języka Python. Ten kod nie jest wykonywany na platformie Spark i może być widoczny jako luka na osi czasu. Jeśli nie masz pewności, czy kod jest uruchomiony na platformie Spark, spróbuj uruchomić go interaktywnie w notesie. Jeśli kod używa platformy Spark, zadania platformy Spark będą widoczne w komórce:

Możesz również rozwinąć listę rozwijaną Zadania platformy Spark w komórce, aby sprawdzić, czy zadania są aktywnie wykonywane (w przypadku, gdy platforma Spark jest teraz bezczynna). Jeśli nie używasz platformy Spark, nie zobaczysz zadań platformy Spark w komórce lub zobaczysz, że żadna z nich nie jest aktywna. Jeśli nie możesz uruchomić kodu interaktywnie, możesz spróbować zalogować się w kodzie i sprawdzić, czy możesz dopasować luki do sekcji kodu według sygnatury czasowej, ale może to być trudne.
Jeśli widzisz luki na osi czasu spowodowane uruchomieniem kodu innego niż Spark, oznacza to, że wszyscy pracownicy są bezczynni i prawdopodobnie marnują pieniądze podczas przerw. Być może jest to celowe i nieuniknione, ale jeśli możesz napisać ten kod, aby użyć platformy Spark, w pełni wykorzystasz klaster. Zacznij od tego samouczka , aby dowiedzieć się, jak pracować z platformą Spark.
Sterownik jest przeciążony
Aby określić, czy sterownik jest przeciążony, należy przyjrzeć się metryce klastra.
Jeśli klaster znajduje się w wersji DBR 13.0 lub nowszej, kliknij pozycję Metryki wyróżnione na tym zrzucie ekranu:
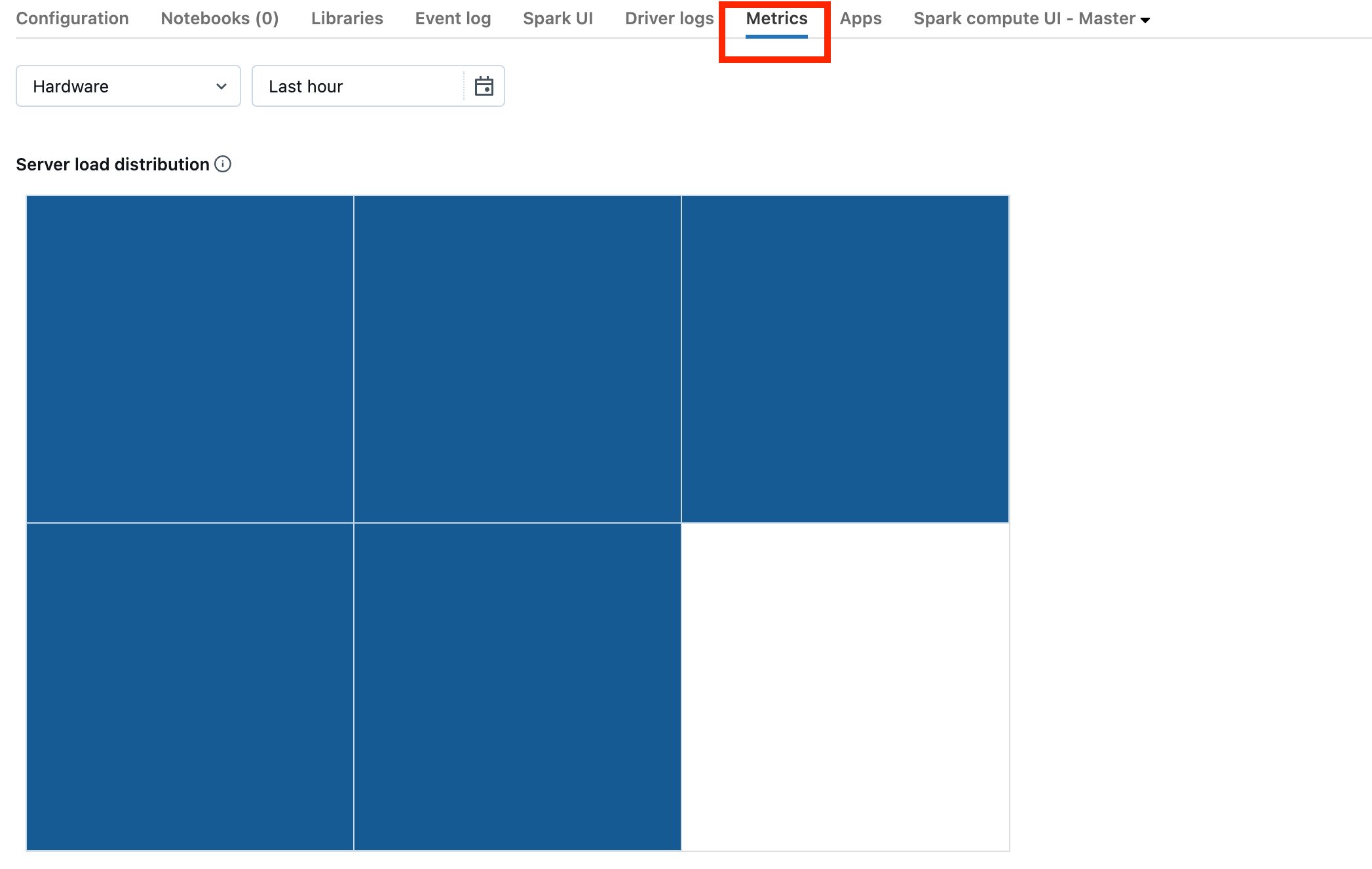
Zwróć uwagę na wizualizację rozkładu obciążenia serwera. Należy sprawdzić, czy sterownik jest mocno załadowany. Ta wizualizacja ma blok koloru dla każdej maszyny w klastrze. Czerwony oznacza mocno obciążone, a niebieski oznacza, że w ogóle nie załadowano.
Na poprzednim zrzucie ekranu przedstawiono zasadniczo bezczynny klaster. Jeśli sterownik jest przeciążony, wyglądałoby to następująco:
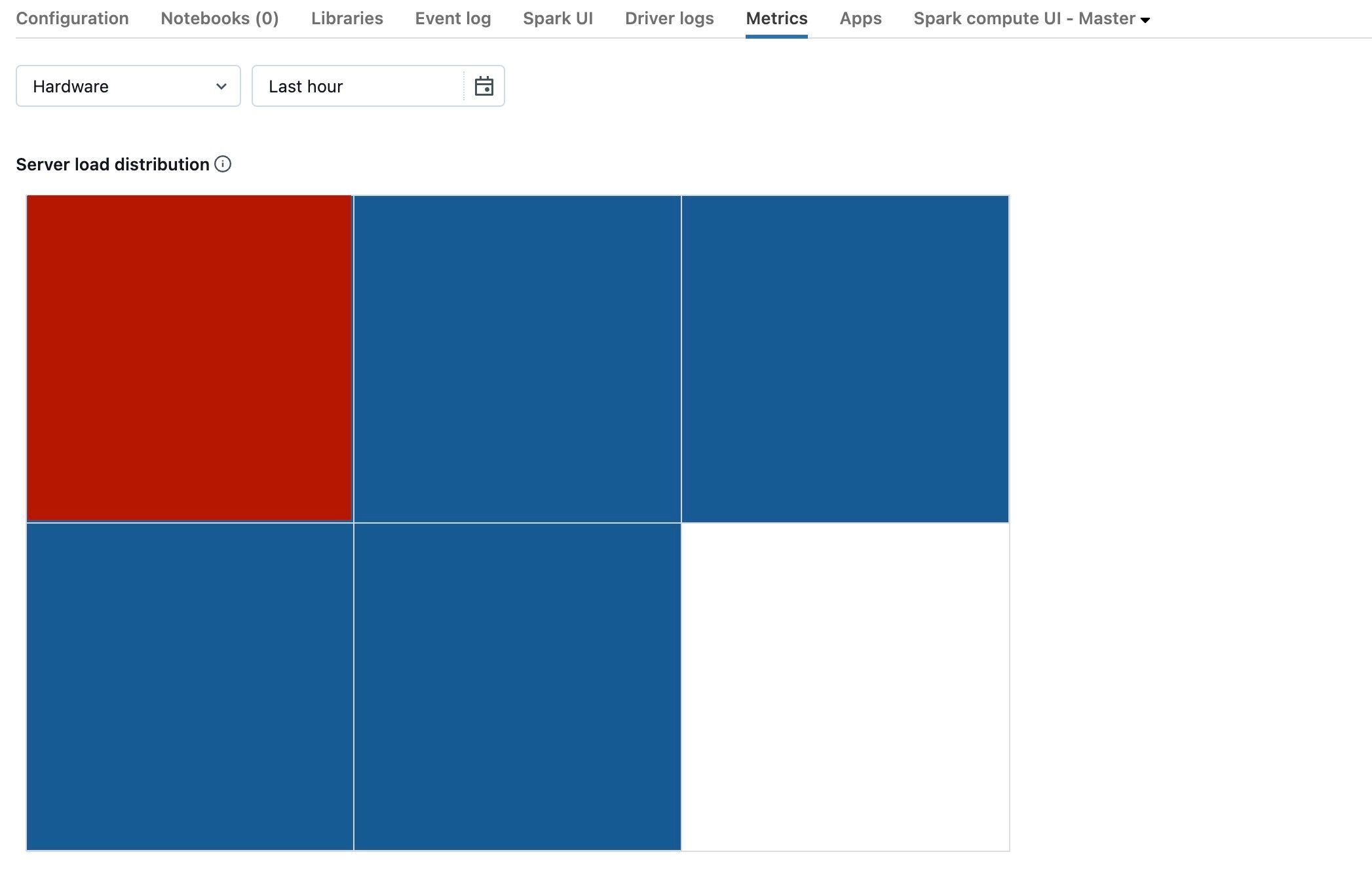
Widzimy, że jeden kwadrat jest czerwony, podczas gdy pozostałe są niebieskie. Przerzuć mysz na czerwony kwadrat, aby upewnić się, że czerwony blok reprezentuje twój sterownik.
Aby naprawić przeciążony sterownik, zobacz Przeciążony sterownik platformy Spark.
Wyświetlanie dystrybucji przy użyciu starszych metryk Ganglia
Jeśli klaster znajduje się w wersji DBR 12.x lub starszej, kliknij pozycję Metryki i interfejs użytkownika Ganglia, jak wyróżniono na tym zrzucie ekranu:
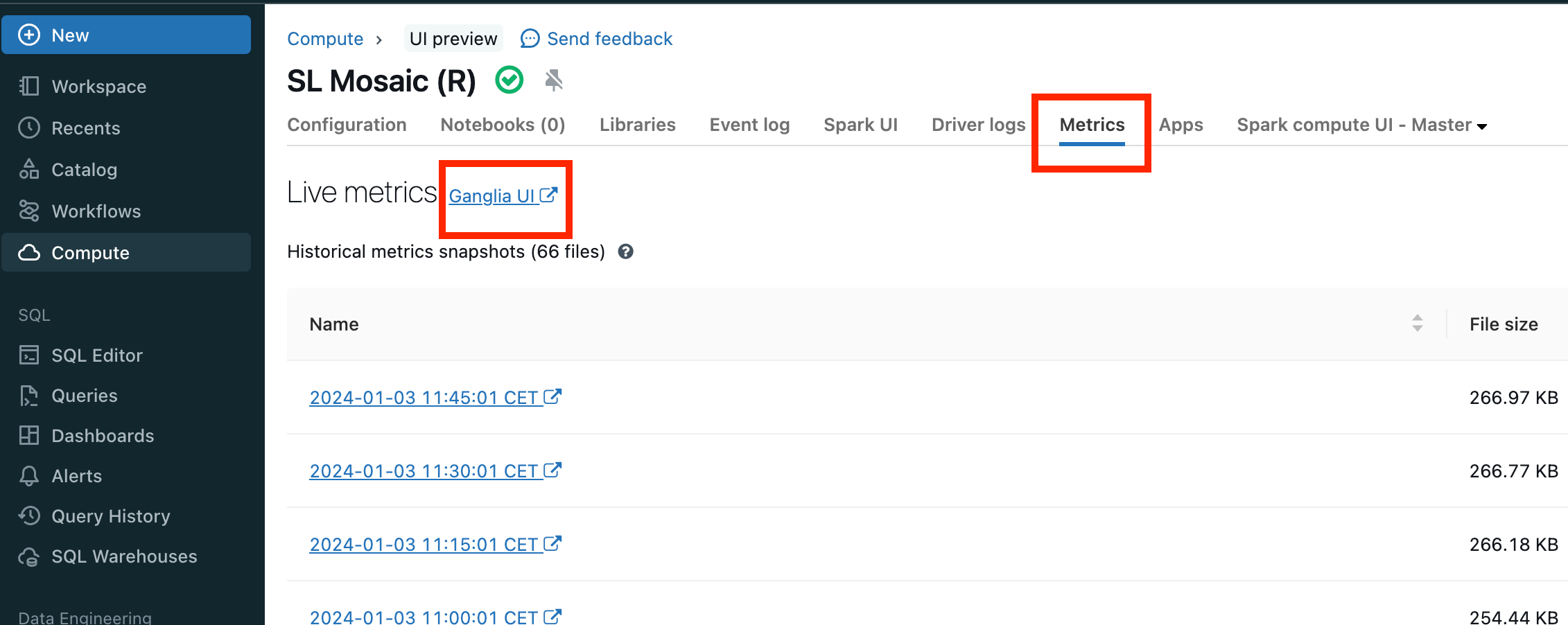
Jeśli klaster nie jest już uruchomiony, możesz otworzyć jedną z historycznych migawek. Spójrz na wizualizację Rozkład obciążenia serwera, która jest wyróżniona tutaj na czerwono:
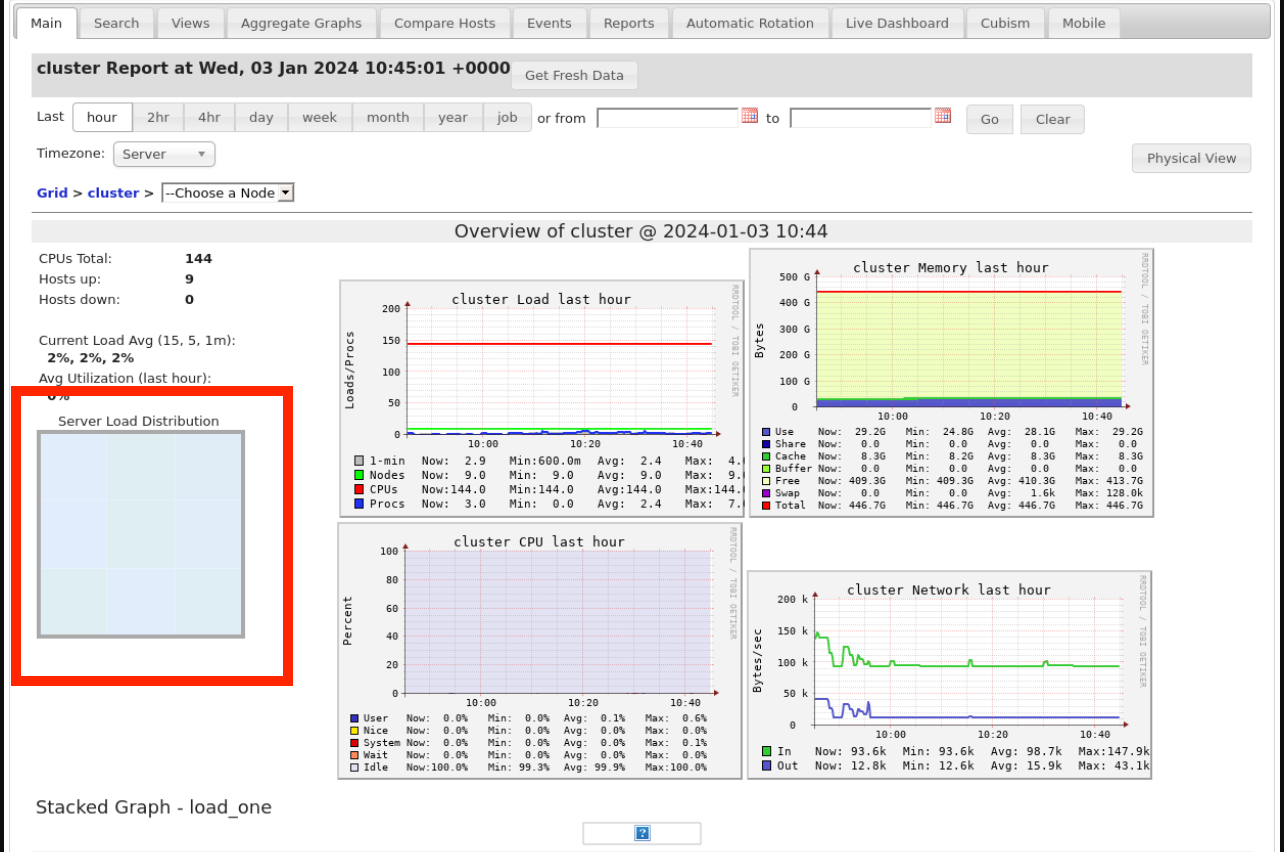
Należy sprawdzić, czy sterownik jest mocno załadowany. Ta wizualizacja ma blok koloru dla każdej maszyny w klastrze. Czerwony oznacza mocno obciążone, a niebieski oznacza, że w ogóle nie załadowano. Powyższa dystrybucja pokazuje zasadniczo bezczynny klaster. Jeśli sterownik jest przeciążony, wyglądałoby to następująco:
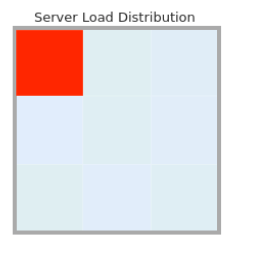
Widzimy, że jeden kwadrat jest czerwony, podczas gdy pozostałe są niebieskie. Zachowaj ostrożność, jeśli masz tylko jednego pracownika. Musisz upewnić się, że czerwony blok jest sterownikiem, a nie pracownikiem.
Aby naprawić przeciążony sterownik, zobacz Przeciążony sterownik platformy Spark.
Klaster działa nieprawidłowo
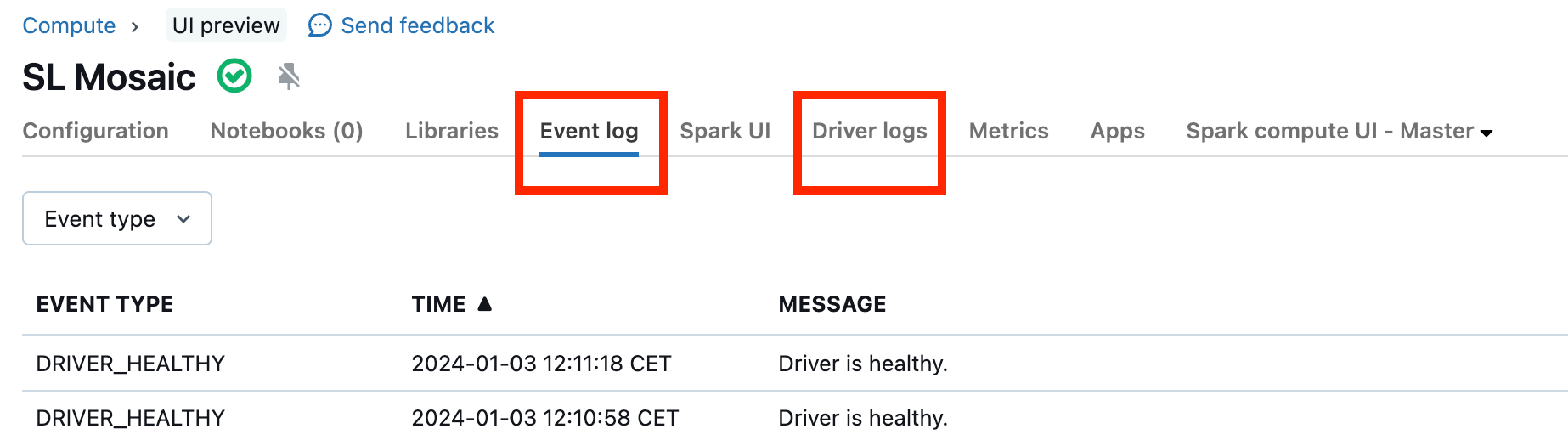
Nieprawidłowe działanie klastrów jest rzadkie, ale jeśli tak jest, może być trudno ustalić, co się stało. Możesz po prostu chcieć ponownie uruchomić klaster, aby sprawdzić, czy to rozwiąże problem. Możesz również przyjrzeć się dziennikom, aby sprawdzić, czy istnieje coś podejrzanego. Karta Dziennik zdarzeń i karty Dzienniki sterowników wyróżnione na poniższym zrzucie ekranu będą miejscami do wyszukania:
Aby uzyskać dostęp do dzienników procesów roboczych, możesz włączyć dostarczanie dziennika klastra. Możesz również zmienić poziom dziennika, ale może być konieczne skontaktowanie się z zespołem ds. kont usługi Databricks, aby uzyskać pomoc.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla