Lipiec 2019
Te funkcje i ulepszenia platformy Azure Databricks zostały wydane w lipcu 2019 r.
Uwaga
Wydania są etapowe. Twoje konto usługi Azure Databricks może nie zostać zaktualizowane do tygodnia po początkowej dacie wydania.
Wkrótce: usługa Databricks 6.0 nie będzie obsługiwać języka Python 2
W oczekiwaniu na zbliżający się koniec życia języka Python 2 ogłoszony na 2020 r. środowisko Python 2 nie będzie obsługiwane w środowisku Databricks Runtime 6.0. Wcześniejsze wersje środowiska Databricks Runtime będą nadal obsługiwać język Python 2. Spodziewamy się wydania środowiska Databricks Runtime 6.0 w wersji nowszej w 2019 roku.
Wstępne ładowanie wersji środowiska Databricks Runtime w bezczynnych wystąpieniach puli
30 lipca — 6 sierpnia 2019 r.: Wersja 2.103
Teraz możesz przyspieszyć uruchamianie klastra opartego na puli, wybierając wersję środowiska Databricks Runtime do załadowania w przypadku bezczynnych wystąpień w puli. Pole w interfejsie użytkownika puli jest nazywane wstępnie załadowaną wersją platformy Spark.

Niestandardowe tagi klastrów i tagi puli lepiej współdziałają
30 lipca — 6 sierpnia 2019 r.: Wersja 2.103
Wcześniej w tym miesiącu usługa Azure Databricks wprowadziła pule, zestaw bezczynnych wystąpień, które ułatwiają szybkie uruchamianie klastrów. W oryginalnej wersji klastry oparte na puli dziedziczyły domyślne i niestandardowe tagi z konfiguracji puli i nie można modyfikować tych tagów na poziomie klastra. Teraz można skonfigurować tagi niestandardowe specyficzne dla klastra opartego na puli i będzie stosować wszystkie tagi niestandardowe, niezależnie od tego, czy dziedziczone z puli, czy przypisane do tego klastra. Nie można dodać tagu niestandardowego specyficznego dla klastra o tej samej nazwie klucza co tag niestandardowy dziedziczony z puli (czyli nie można zastąpić tagu niestandardowego dziedziczonego z puli). Aby uzyskać szczegółowe informacje, zobacz Tagi puli.
Platforma MLflow 1.1 oferuje kilka ulepszeń interfejsu użytkownika i interfejsu API
30 lipca — 6 sierpnia 2019 r.: Wersja 2.103
MLflow 1.1 wprowadza kilka nowych funkcji w celu zwiększenia użyteczności interfejsu użytkownika i interfejsu API:
Interfejs użytkownika przeglądu przebiegów umożliwia teraz przeglądanie wielu stron przebiegów, jeśli liczba przebiegów przekracza 100. Po uruchomieniu 100 kliknij przycisk Załaduj więcej , aby załadować kolejne 100 przebiegów.
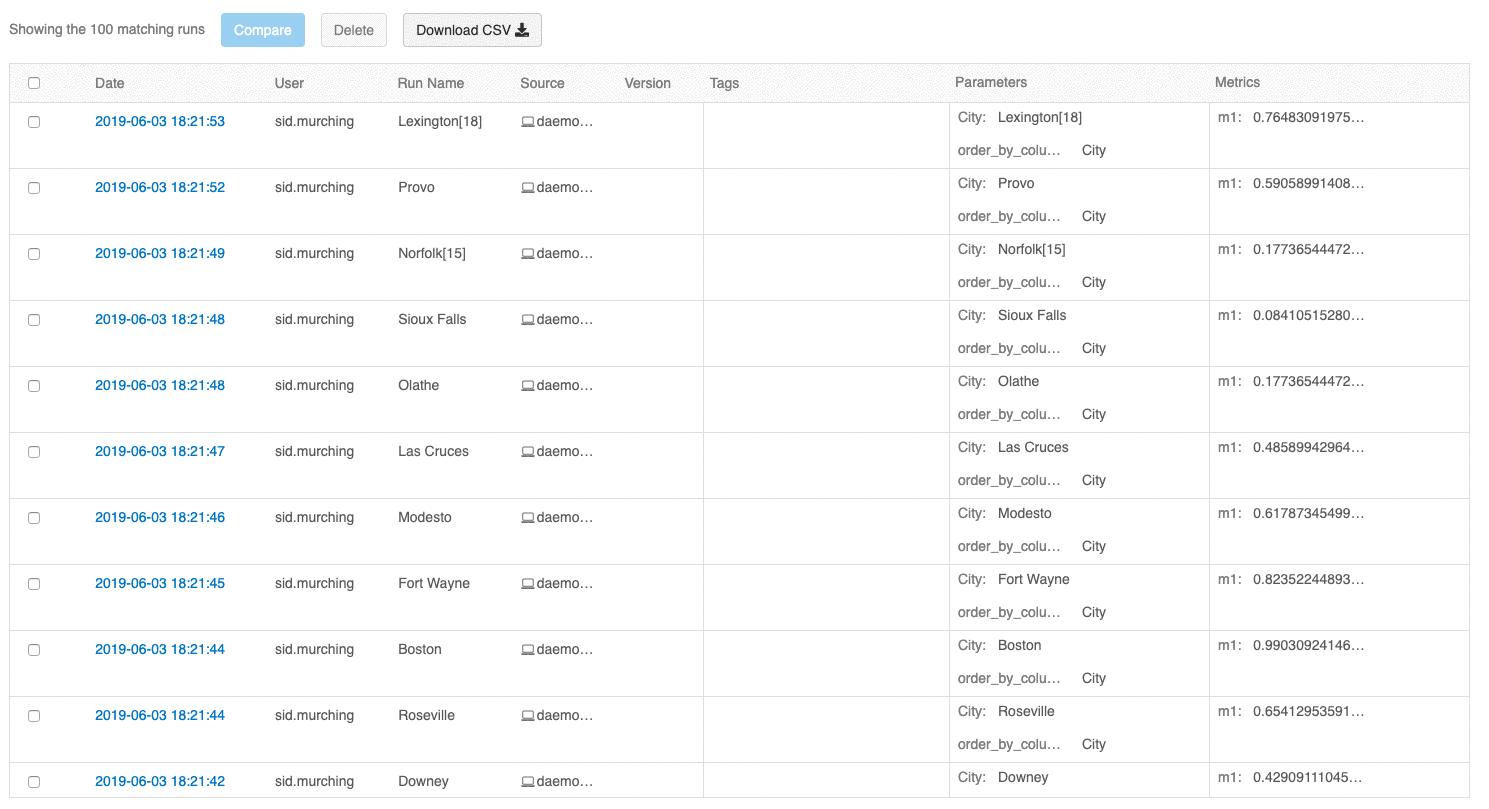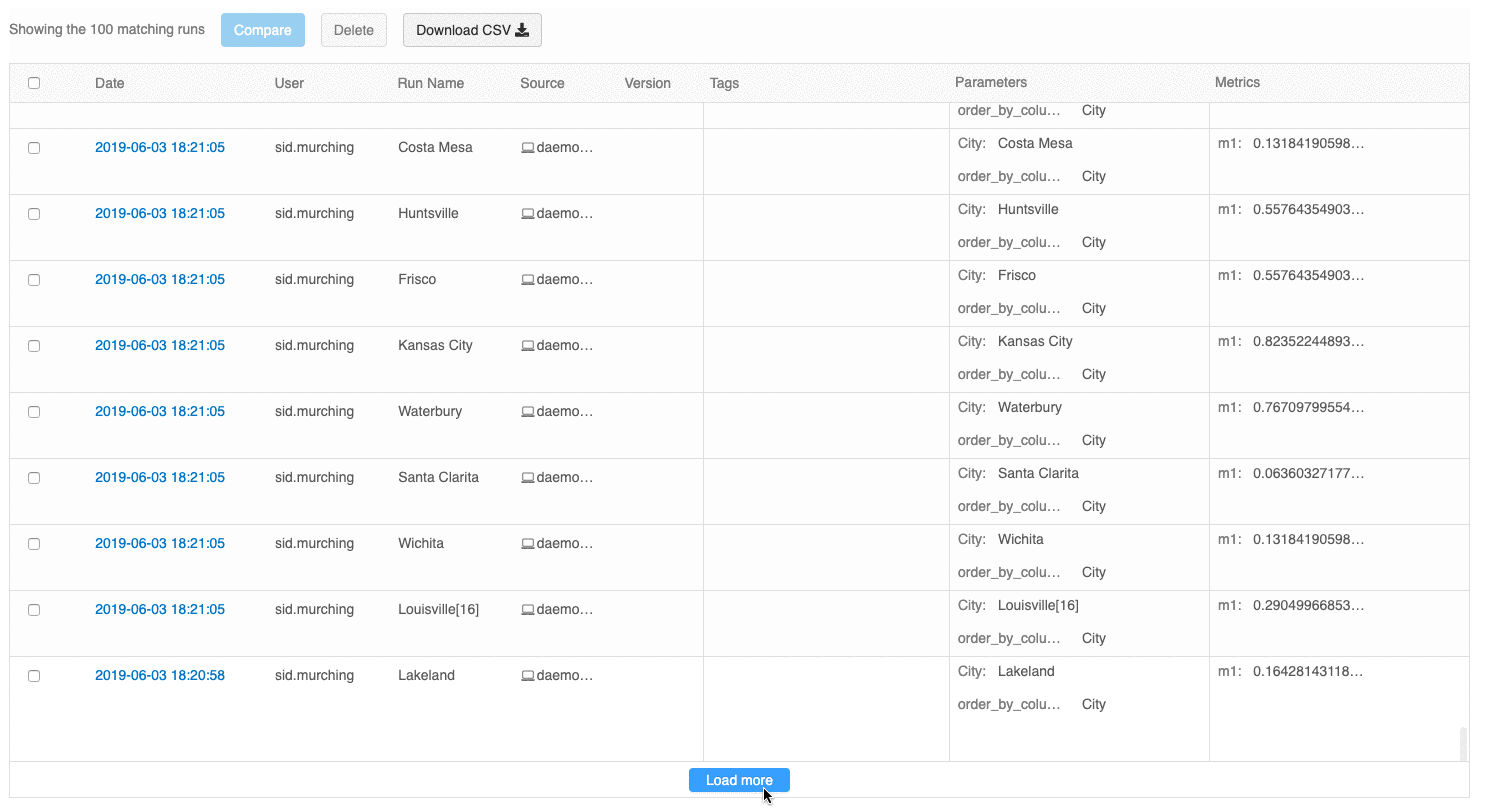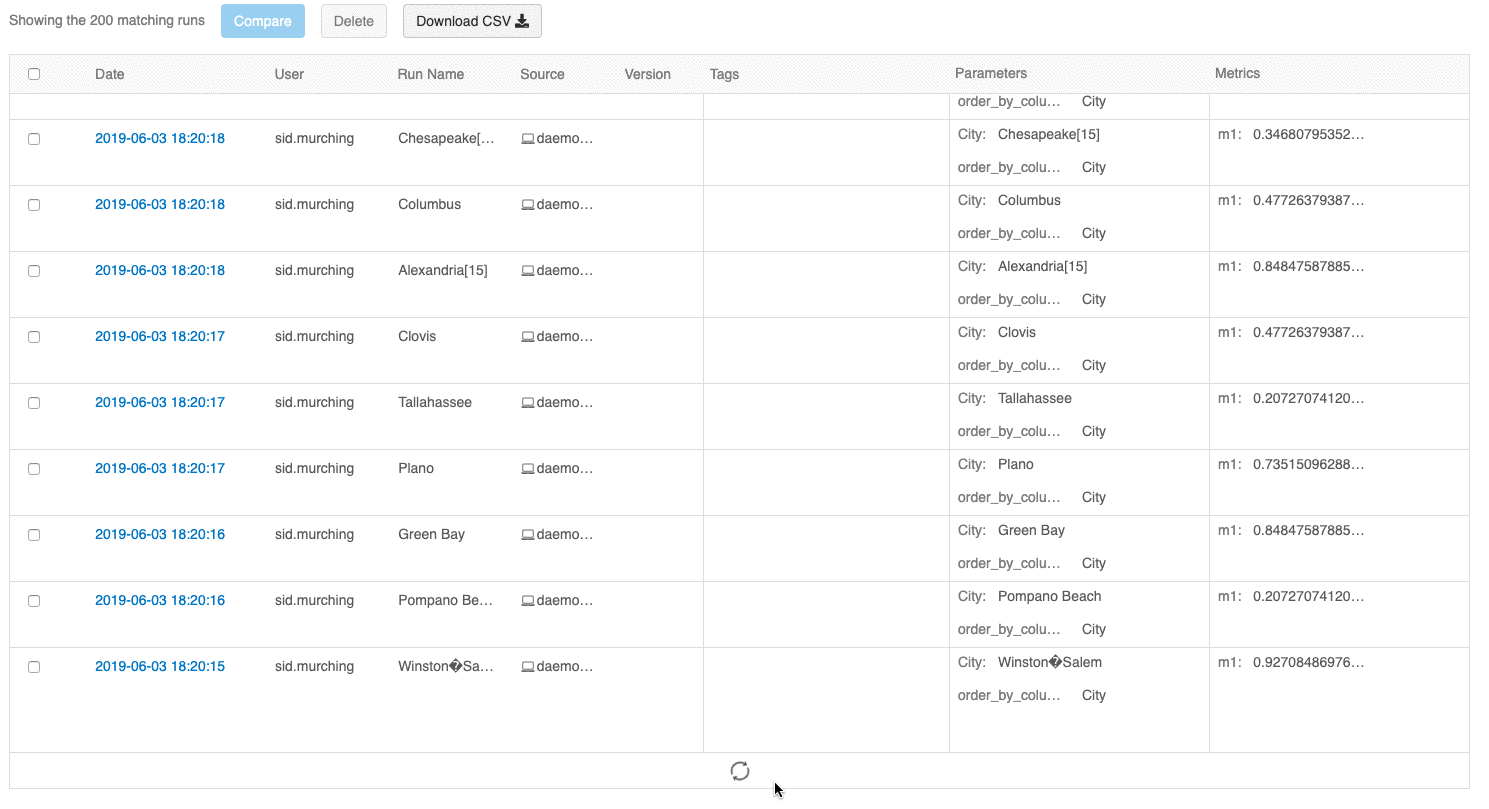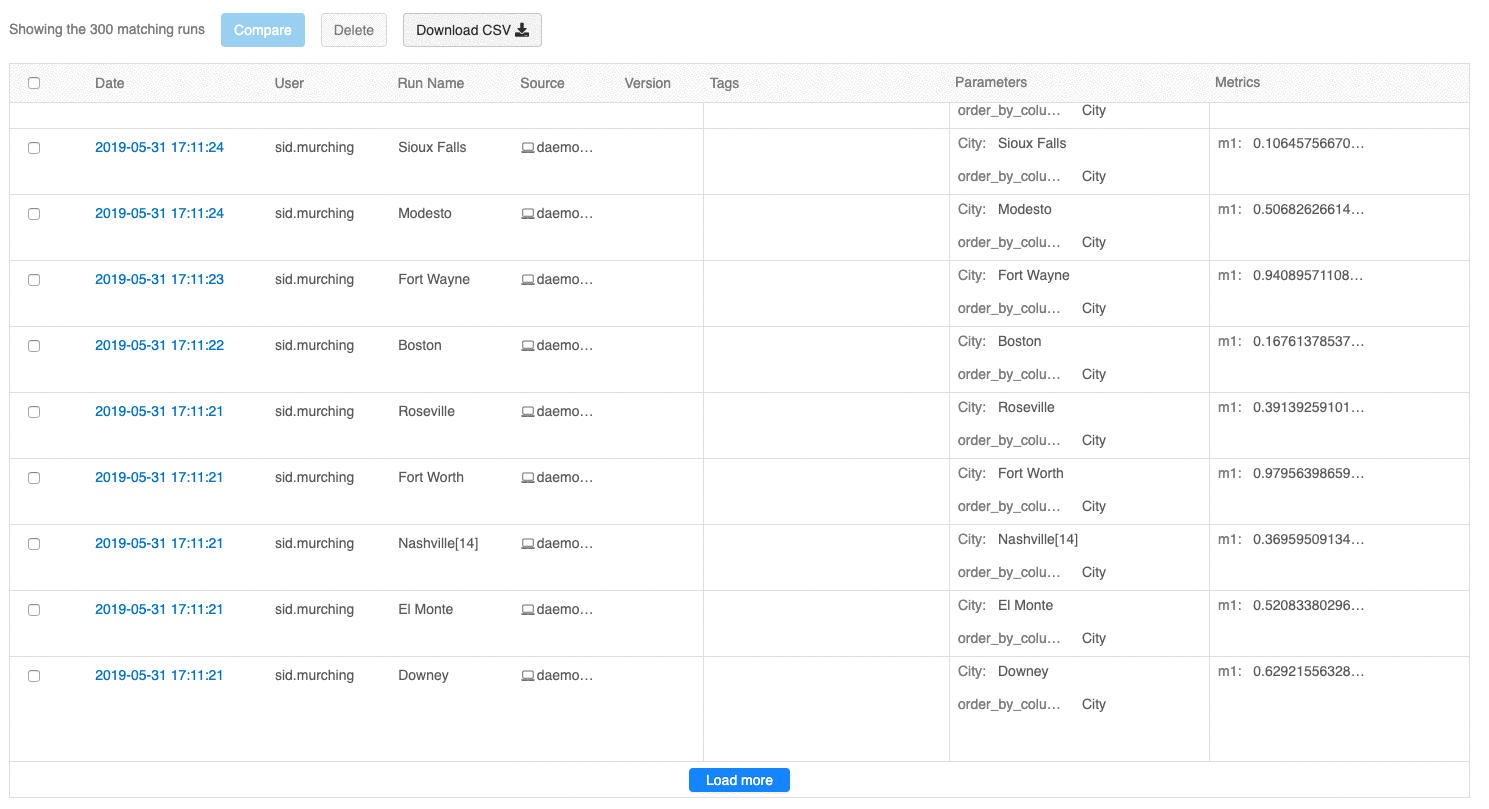
Interfejs użytkownika przebiegów porównania udostępnia teraz wykres współrzędnych równoległych. Wykres umożliwia obserwowanie relacji między nwymiarowym zestawem parametrów i metryk. Wizualizuje wszystkie przebiegi jako linie, które są oznaczone kolorem na podstawie wartości metryki (na przykład dokładności) i pokazuje wartości parametrów, na których uruchomiono każde uruchomienie.

Teraz możesz dodawać i edytować tagi z poziomu interfejsu użytkownika przeglądu przebiegu i wyświetlać tagi w widoku wyszukiwania eksperymentów.
Nowy interfejs API MLflowContext umożliwia tworzenie i rejestrowanie przebiegów w sposób podobny do interfejsu API języka Python. Ten interfejs API kontrastuje z istniejącym interfejsem API niskiego poziomu
MlflowClient, który po prostu opakowuje interfejsy API REST.Teraz można usuwać tagi z przebiegów MLflow przy użyciu interfejsu API DeleteTag.
Aby uzyskać szczegółowe informacje, zobacz wpis w blogu MLflow 1.1. Aby uzyskać pełną listę funkcji i poprawek, zobacz dziennik zmian MLflow.
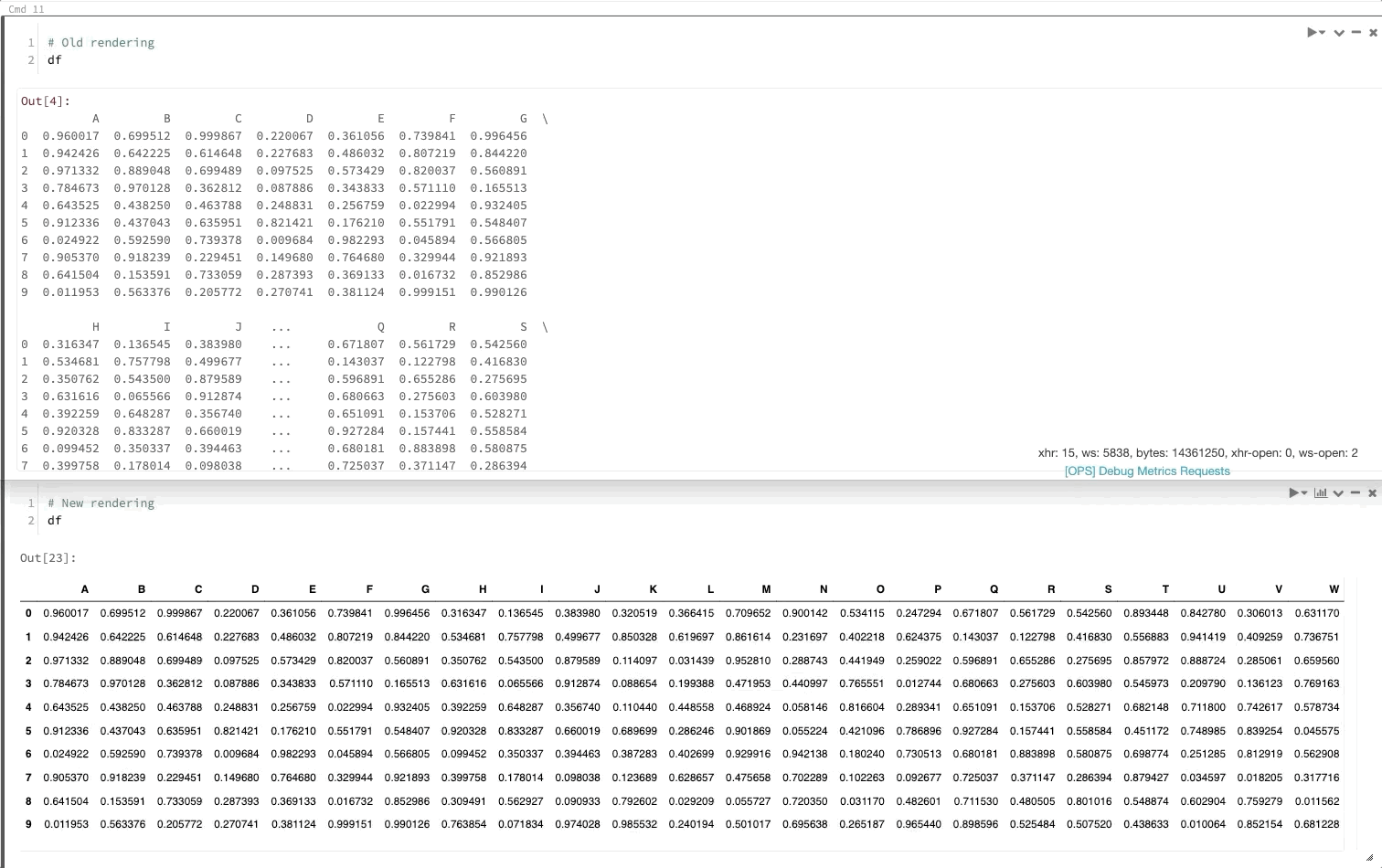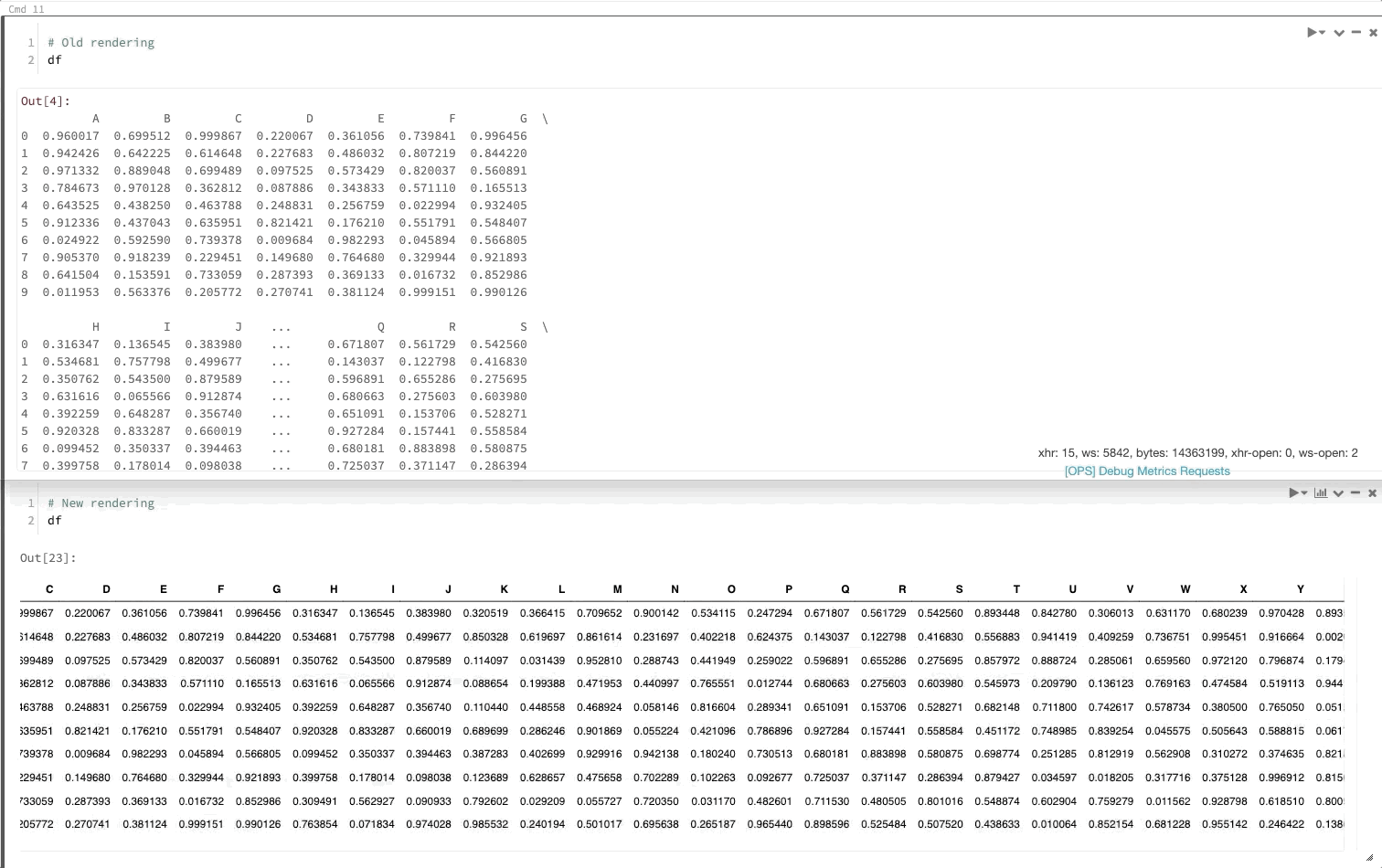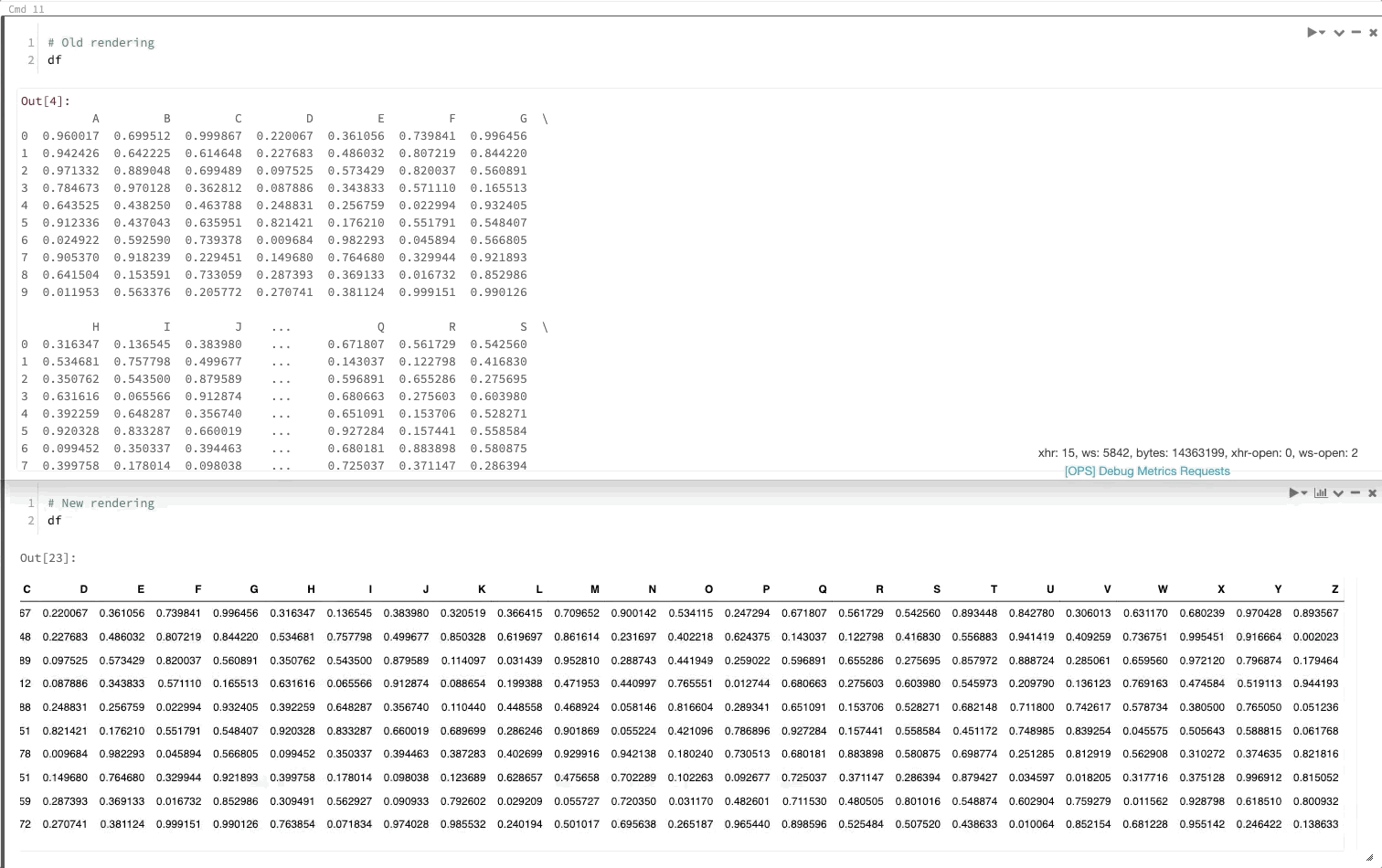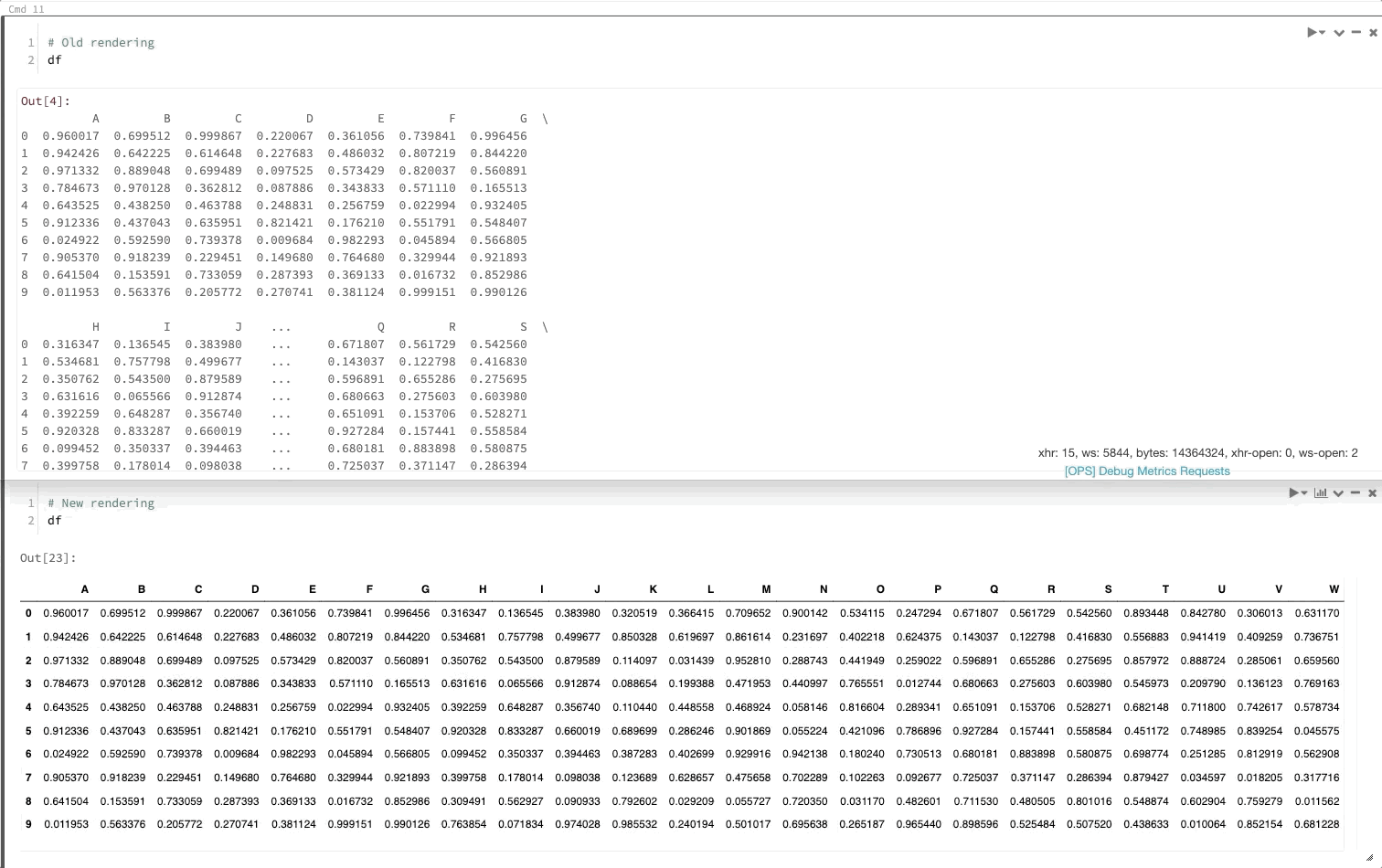
Ramka danych biblioteki Pandas jest renderowana tak jak w środowisku Jupyter
30 lipca — 6 sierpnia 2019 r.: Wersja 2.103
Teraz, gdy wywołasz ramkę danych biblioteki pandas, będzie ona renderowana tak samo jak w programie Jupyter.
Nowe regiony
30 lipca 2019 r.
Usługa Azure Databricks jest teraz dostępna w następujących dodatkowych regionach:
- Korea Środkowa
- Północna Republika Południowej Afryki
Databricks Runtime 5.5 ze środowiskiem Conda (wersja beta)
23 lipca 2019 r.
Ważne
Środowisko Databricks Runtime z aplikacją Conda jest w wersji beta. Zawartość obsługiwanych środowisk może ulec zmianie w nadchodzących wersjach beta. Zmiany mogą obejmować listę pakietów lub wersji zainstalowanych pakietów. Środowisko Databricks Runtime 5.5 z aplikacją Conda jest oparte na środowisku Databricks Runtime 5.5 LTS (nieobsługiwane).
Środowisko Databricks Runtime 5.5 z aplikacją Conda dodaje nowy interfejs API biblioteki o zakresie notesu w celu obsługi aktualizowania środowiska Conda notesu przy użyciu specyfikacji YAML (zobacz dokumentację Conda).
Zobacz pełne informacje o wersji w środowisku Databricks Runtime 5.5 z funkcją Conda (nieobsługiwane).
Zaktualizowano limit połączeń magazynu metadanych
16 lipca – 23, 2019: Wersja 2.102
Nowe obszary robocze usługi Azure Databricks w regionie eastus, eastus2, centralus, westus2, westeurope, northeurope będą miały wyższy limit połączenia magazynu metadanych o wartości 250. Istniejące obszary robocze będą nadal używać bieżącego magazynu metadanych bez zakłóceń i nadal mają limit połączeń 100.
Ustawianie uprawnień do pul (publiczna wersja zapoznawcza)
16 lipca – 23, 2019: Wersja 2.102
Interfejs użytkownika puli obsługuje teraz ustawianie uprawnień do tego, kto może zarządzać pulami i kto może dołączać klastry do pul.
Aby uzyskać szczegółowe informacje, zobacz Uprawnienia puli.
Databricks Runtime 5.5 na potrzeby uczenia maszynowego
15 lipca 2019 r.
Środowisko Databricks Runtime 5.5 ML jest oparte na środowisku Databricks Runtime 5.5 LTS (nieobsługiwane). Zawiera wiele popularnych bibliotek uczenia maszynowego, w tym TensorFlow, PyTorch, Keras i XGBoost oraz zapewnia rozproszone trenowanie Biblioteki TensorFlow przy użyciu struktury Horovod.
Ta wersja zawiera następujące nowe funkcje i ulepszenia:
- Dodano pakiet języka Python MLflow 1.0
- Uaktualnione biblioteki uczenia maszynowego
- TensorFlow uaktualniono z wersji 1.12.0 do 1.13.1
- Program PyTorch został uaktualniony z wersji 0.4.1 do wersji 1.1.0
- Program scikit-learn został uaktualniony z wersji 0.19.1 do wersji 0.20.3
- Operacja z jednym węzłem dla modułu HorovodRunner
Aby uzyskać szczegółowe informacje, zobacz Databricks Runtime 5.5 LTS for ML (nieobsługiwane).
Databricks Runtime 5.5
15 lipca 2019 r.
Środowisko Databricks Runtime 5.5 jest teraz dostępne. Środowisko Databricks Runtime 5.5 obejmuje platformę Apache Spark 2.4.3, uaktualnione biblioteki Python, R, Java i Scala oraz następujące nowe funkcje:
- Usługa Delta Lake w usłudze Azure Databricks auto optimize (ogólna dostępność)
- Usługa Delta Lake w usłudze Azure Databricks poprawiła wydajność zapytań agregacji min, maksimum i liczby
- Szybsze potoki wnioskowania modelu dzięki ulepszonemu źródle danych plików binarnych i funkcji zdefiniowanej przez użytkownika iteratora skalarnego biblioteki pandas (publiczna wersja zapoznawcza)
- Interfejs API wpisów tajnych w notesach języka R
Aby uzyskać szczegółowe informacje, zobacz Databricks Runtime 5.5 LTS (nieobsługiwane).
Utrzymywanie podręcznej puli wystąpień na potrzeby szybkiego uruchamiania klastra (publiczna wersja zapoznawcza)
9 lipca 2019 r. — 11 lipca 2019 r.: Wersja 2.101
Aby skrócić czas uruchamiania klastra, usługa Azure Databricks obsługuje teraz dołączanie klastra do wstępnie zdefiniowanej puli bezczynnych wystąpień. Po dołączeniu do puli klaster przydziela jego węzły sterowników i procesów roboczych z puli. Jeśli pula nie ma wystarczających zasobów bezczynnych, aby obsłużyć żądanie klastra, pula rozszerza się, przydzielając nowe wystąpienia od dostawcy chmury. Po zakończeniu działania dołączonego klastra używane wystąpienia są zwracane do puli i mogą być ponownie używane przez inny klaster.
Usługa Azure Databricks nie nalicza opłat za jednostki usługi Databricks, gdy wystąpienia są bezczynne w puli. Rozliczenia dostawcy wystąpień mają zastosowanie. Zobacz cennik.
Aby uzyskać szczegółowe informacje, zobacz Dokumentacja konfiguracji puli.
Metryki Ganglia
9 lipca 2019 r. — 11 lipca 2019 r.: Wersja 2.101
Ganglia to skalowalny rozproszony system monitorowania, który jest teraz dostępny w klastrach usługi Azure Databricks. Metryki Ganglia ułatwiają monitorowanie wydajności i kondycji klastra. Metryki Ganglia można uzyskać na stronie szczegółów klastra:
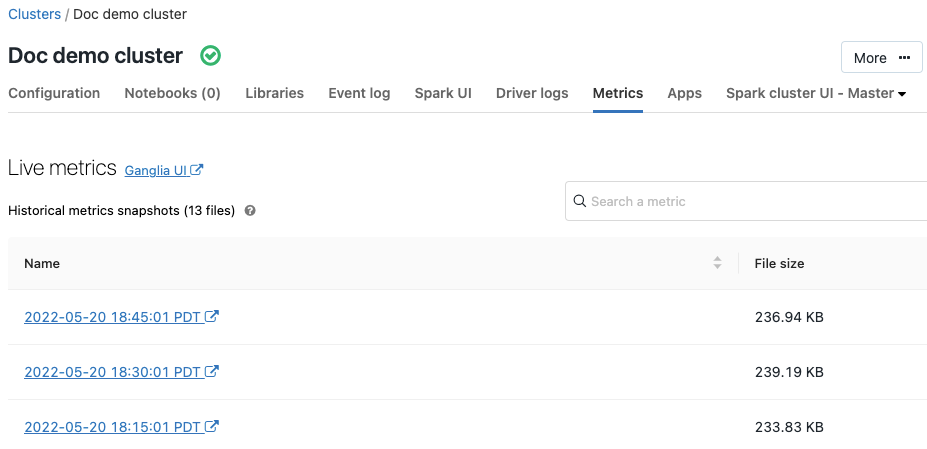
Aby uzyskać szczegółowe informacje na temat używania i konfigurowania metryk, zobacz Ganglia metrics (Metryki Ganglia).
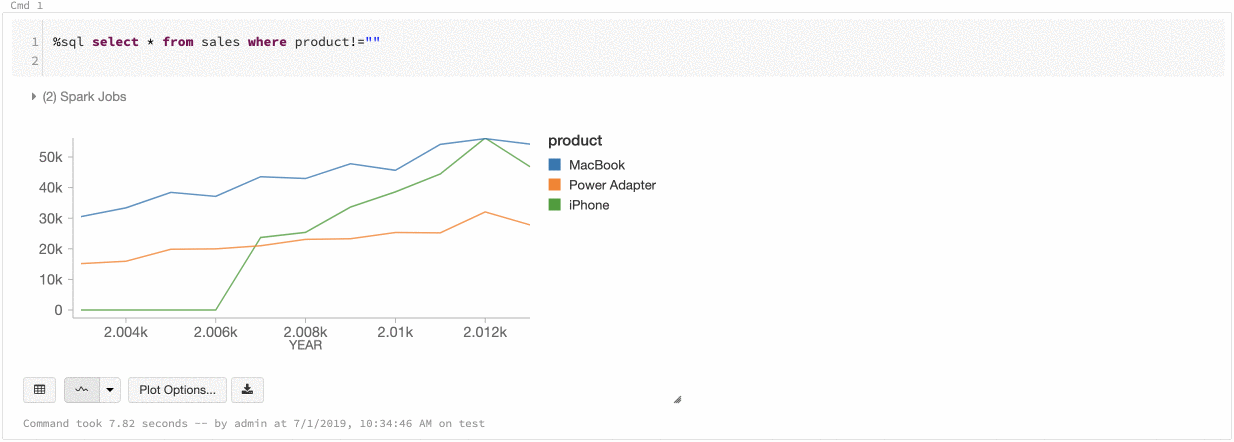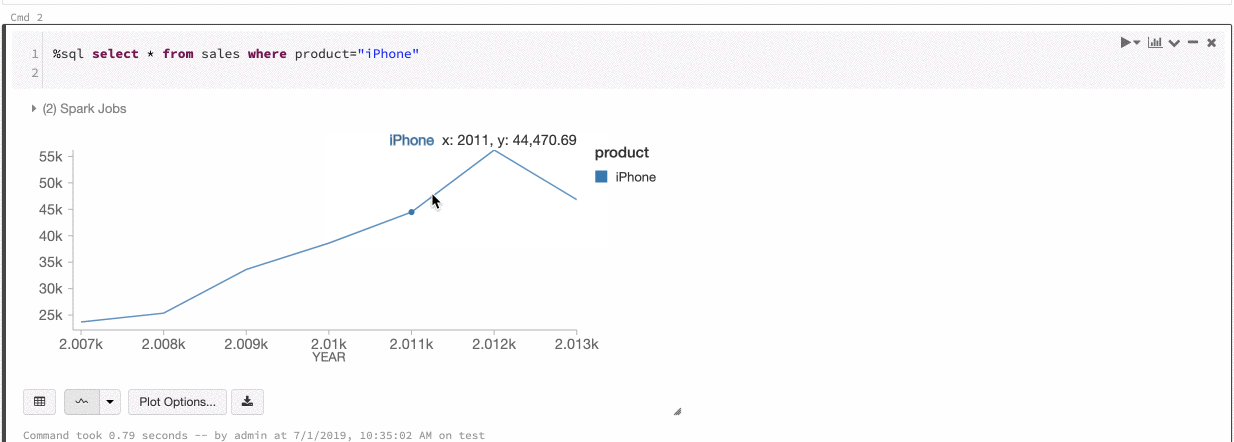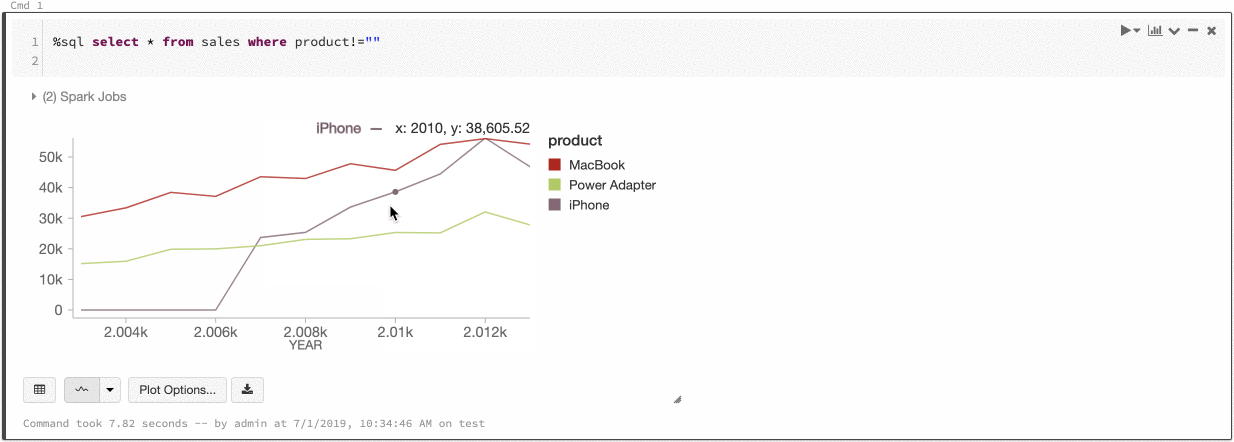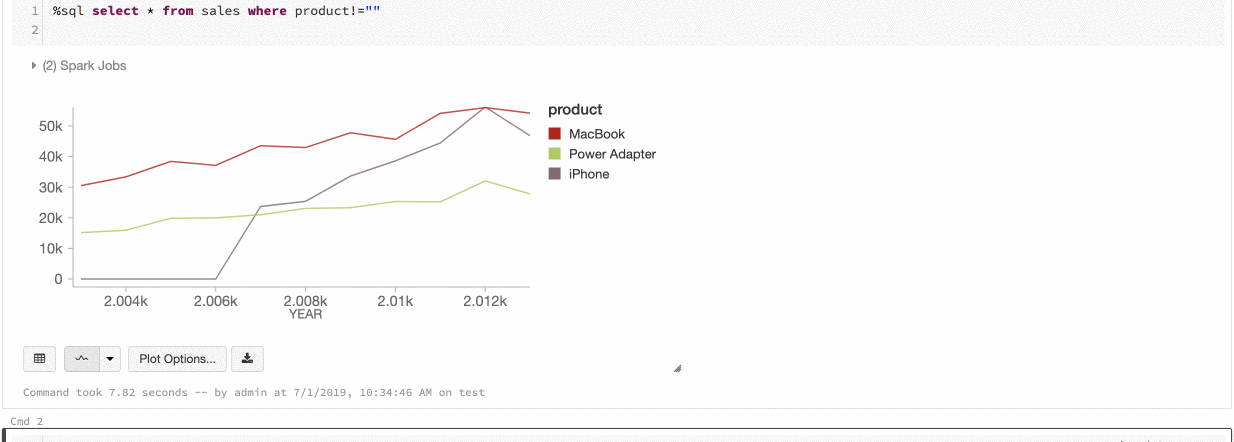
Kolor serii globalnej
9 lipca 2019 r. — 11 lipca 2019 r.: Wersja 2.101
Teraz możesz określić, że kolory serii powinny być spójne we wszystkich wykresach w notesie. Zobacz Spójność kolorów na wykresach.