Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano starsze wizualizacje usługi Azure Databricks. Zobacz Wizualizacje w notesach usługi Databricks i edytorze SQL, aby uzyskać bieżącą obsługę wizualizacji podczas tworzenia wizualizacji w edytorze SQL lub notesie. Aby uzyskać informacje na temat pracy z wizualizacjami na pulpitach nawigacyjnych sztucznej inteligencji/analizy biznesowej, zobacz Typy wizualizacji pulpitu nawigacyjnego AI/BI.
Usługa Azure Databricks również natywnie obsługuje biblioteki wizualizacji w języku Python i języku R oraz umożliwia instalowanie bibliotek innych firm i korzystanie z nich.
Utwórz wizualizację dziedzictwa
Aby utworzyć wizualizację dziedzictwa na podstawie komórki wyników, kliknij + i wybierz opcję Wizualizacja dziedzictwa.
Starsze wizualizacje obsługują bogaty zestaw typów wykresów:
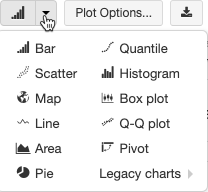
Wybieranie i konfigurowanie starszego typu wykresu
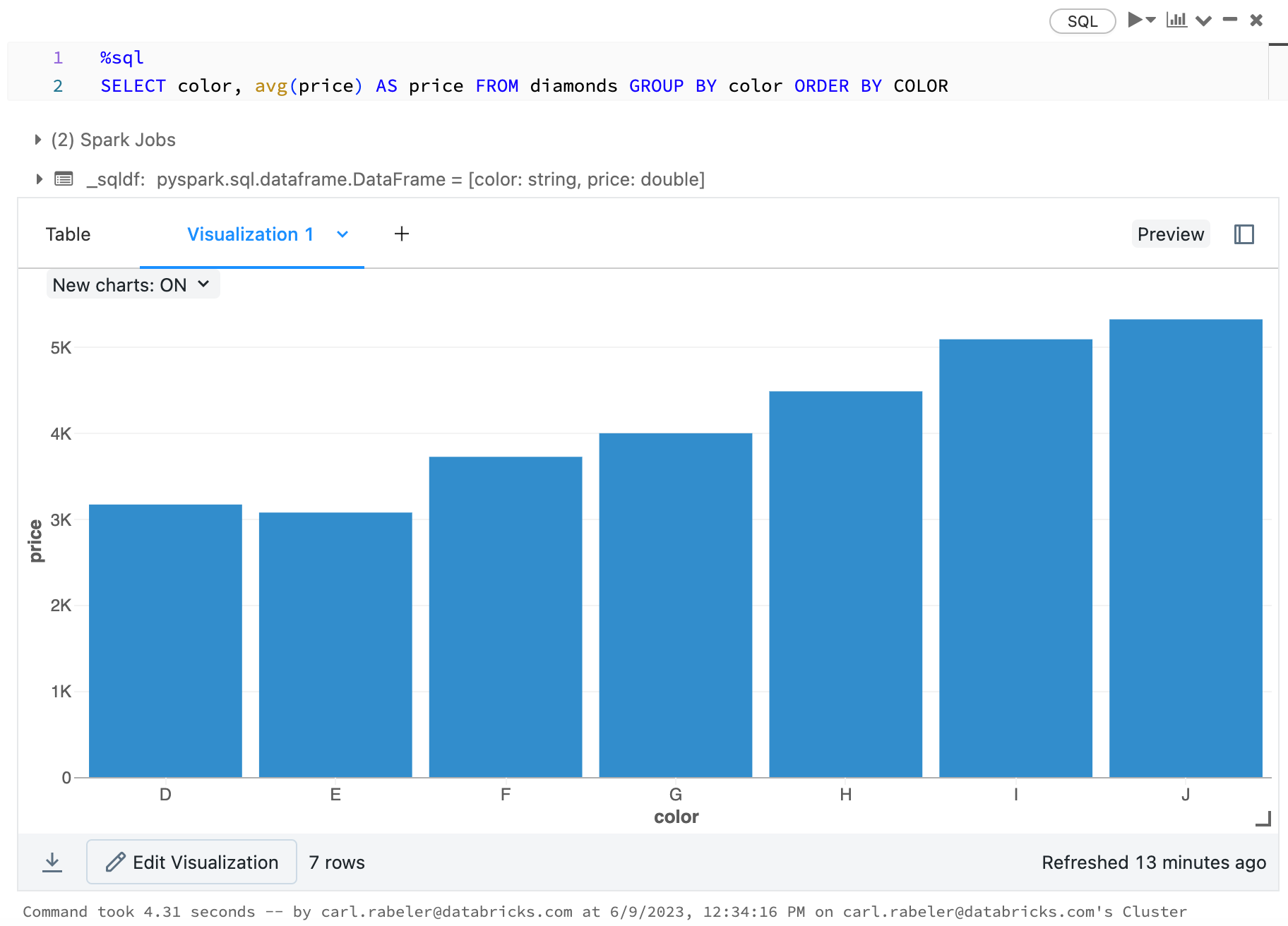
Aby wybrać wykres słupkowy, kliknij ikonę  :
:
Aby wybrać inny typ wykresu, kliknij ![]() po prawej stronie wykresu słupkowego i wybierz typ wykresu.
po prawej stronie wykresu słupkowego i wybierz typ wykresu.
Pasek narzędzi starszego wykresu
Oba wykresy liniowe i słupkowy mają wbudowany pasek narzędzi, który obsługuje bogaty zestaw interakcji po stronie klienta.
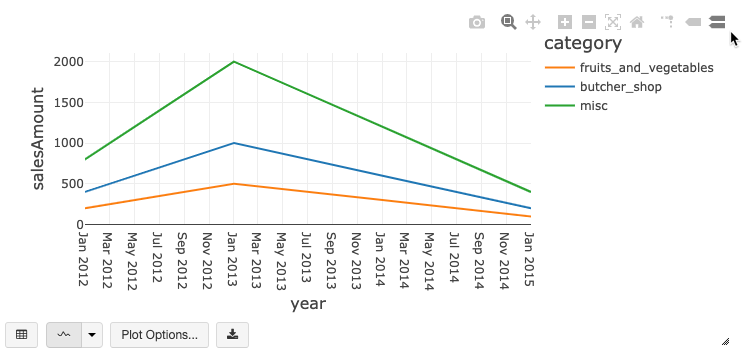
Aby skonfigurować wykres, kliknij przycisk Opcje wykresu....
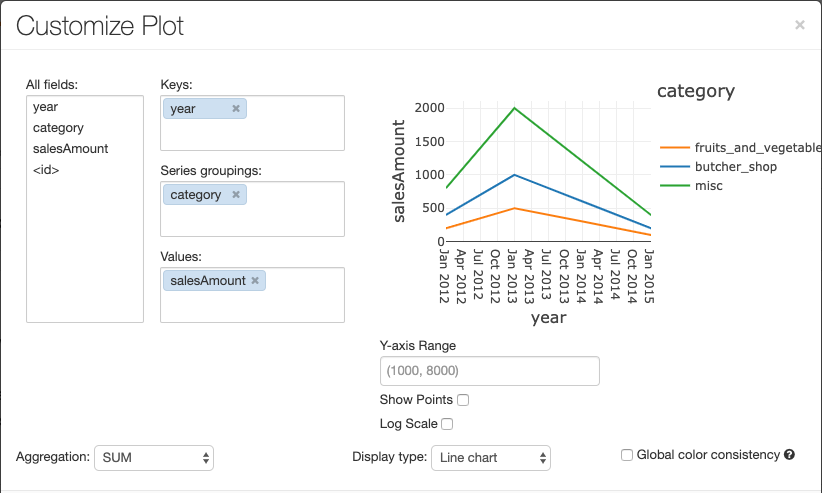
Wykres liniowy ma kilka niestandardowych opcji wykresu: ustawienie zakresu osi Y, pokazywanie i ukrywanie punktów oraz wyświetlanie osi Y przy użyciu skali logarytmicznej.
Aby uzyskać informacje o starszych typach wykresów, zobacz:
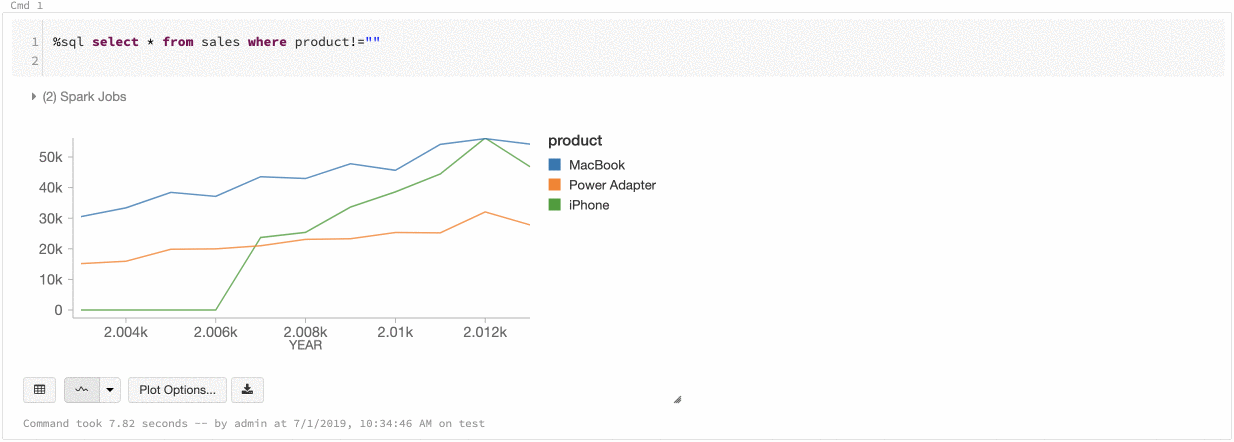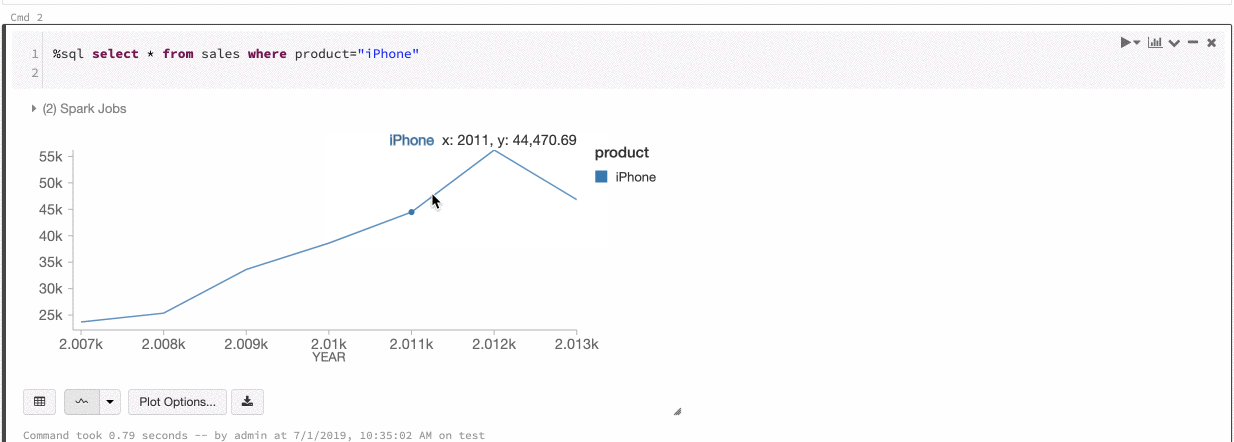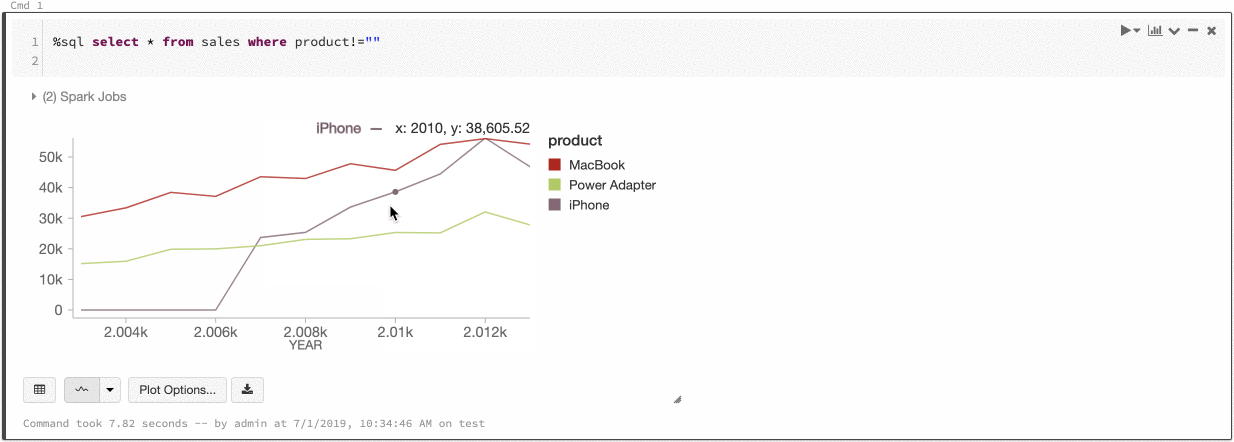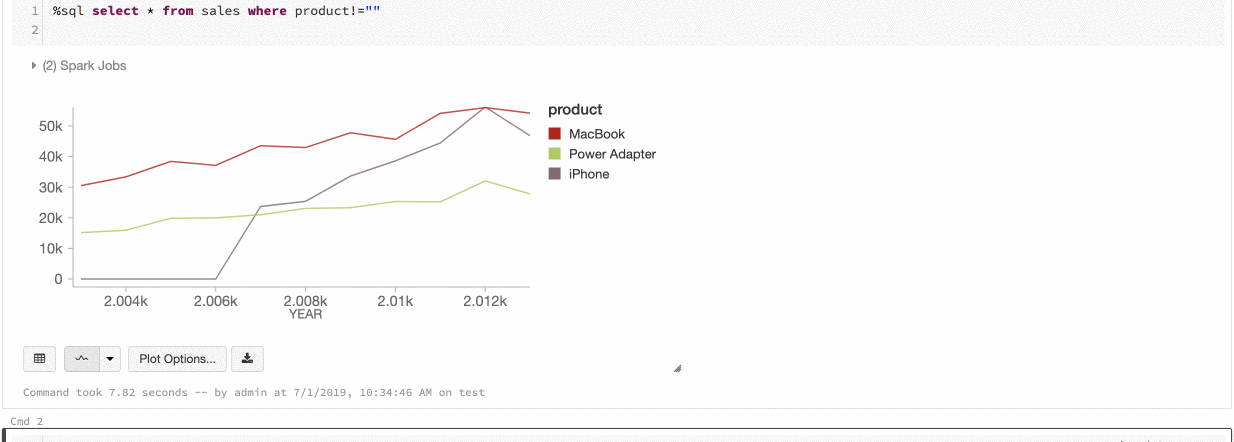
Spójność kolorów między wykresami
Usługa Azure Databricks obsługuje dwa rodzaje spójności kolorów na starszych wykresach: zestaw serii i globalny.
Ustawienie spójności kolorów przypisuje ten sam kolor do tej samej wartości, jeśli masz serie o tych samych wartościach, ale w różnej kolejności (na przykład A = ["Apple", "Orange", "Banana"] i B = ["Orange", "Banana", "Apple"]). Wartości są sortowane przed wykreśleniem, więc obie legendy są sortowane w taki sam sposób (["Apple", "Banana", "Orange"]), a te same wartości mają te same kolory. Jeśli jednak masz serię C = ["Orange", "Banana"], kolor nie będzie zgodny z zestawem A, ponieważ zestaw nie jest taki sam. Algorytm sortowania przypisze pierwszy kolor do "Banana" w zestawie C, ale drugi kolor na "Banana" w zestawie A. Jeśli chcesz, aby te serie były spójne na poziomie kolorów, możesz określić, że wykresy powinny mieć globalną spójność kolorów.
W globalnej spójności kolorów każda wartość jest zawsze mapowana na ten sam kolor niezależnie od wartości, które mają serie. Aby włączyć tę opcję dla każdego wykresu, zaznacz pole wyboru Globalnej spójności kolorów.
Uwaga
Aby osiągnąć tę spójność, Azure Databricks stosuje hashowanie bezpośrednio zamieniając wartości na kolory. Aby uniknąć kolizji (sytuacji, gdzie dwie wartości przypisane są do tego samego koloru), haszowanie odbywa się na dużym zestawie kolorów, co powoduje, że nie można zagwarantować ładnych lub łatwo rozróżnialnych kolorów; wśród wielu kolorów z pewnością znajdą się takie, które są do siebie bardzo podobne.
Wizualizacje uczenia maszynowego
Oprócz standardowych typów wykresów starsze wizualizacje obsługują następujące parametry i wyniki trenowania uczenia maszynowego:
Reszty
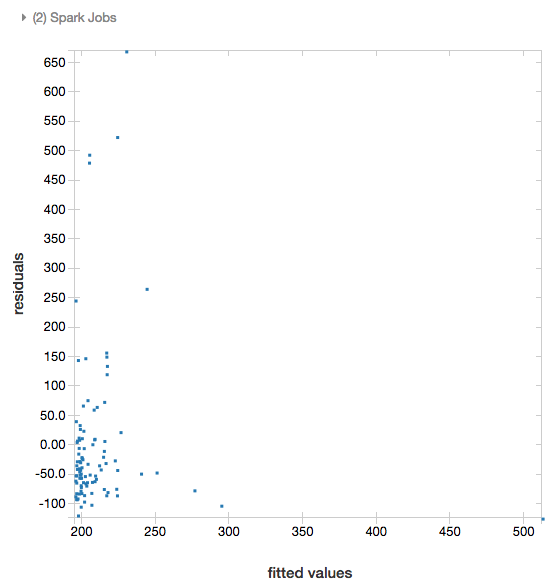
W przypadku regresji liniowej i logistycznej można wygenerować wykres dopasowania w stosunku do reszt. Aby uzyskać ten wykres, podaj model i ramkę danych.
W poniższym przykładzie przeprowadzono regresję liniową na danych dotyczących populacji miast w odniesieniu do cen sprzedaży domów, a następnie wyświetlono wartości resztkowe w porównaniu z dopasowanymi danymi.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
Krzywe ROC
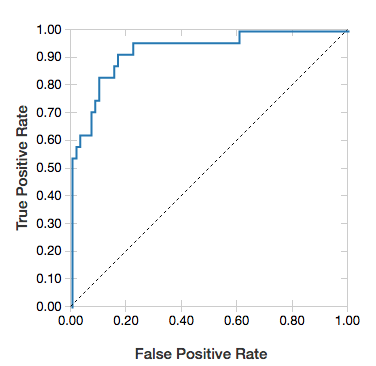
W przypadku regresji logistycznej można renderować krzywą ROC . Aby uzyskać ten wykres, podaj model, wstępnie wprowadzone dane dla metody fit i parametr "ROC".
Poniższy przykład opracowuje klasyfikator, który przewiduje, czy dana osoba zarabia <=50K lub >50 tys. rocznie z różnych atrybutów danej osoby. Zestaw danych o osobach dorosłych pochodzi ze spisu i składa się z informacji na temat 48 842 osób i ich rocznych dochodów.
W przykładowym kodzie w tej sekcji używane jest kodowanie one-hot.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
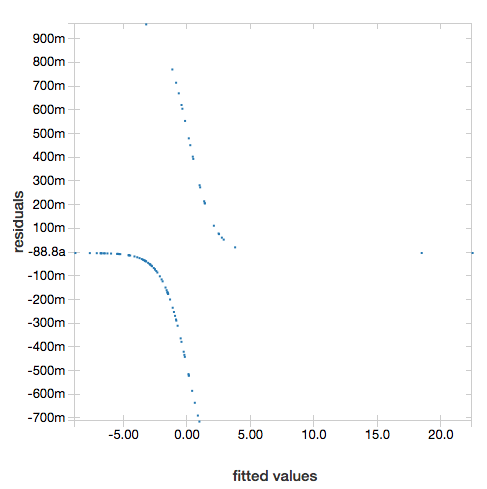
Aby wyświetlić wartości resztkowe, pomiń parametr "ROC":
display(lrModel, preppedDataDF)
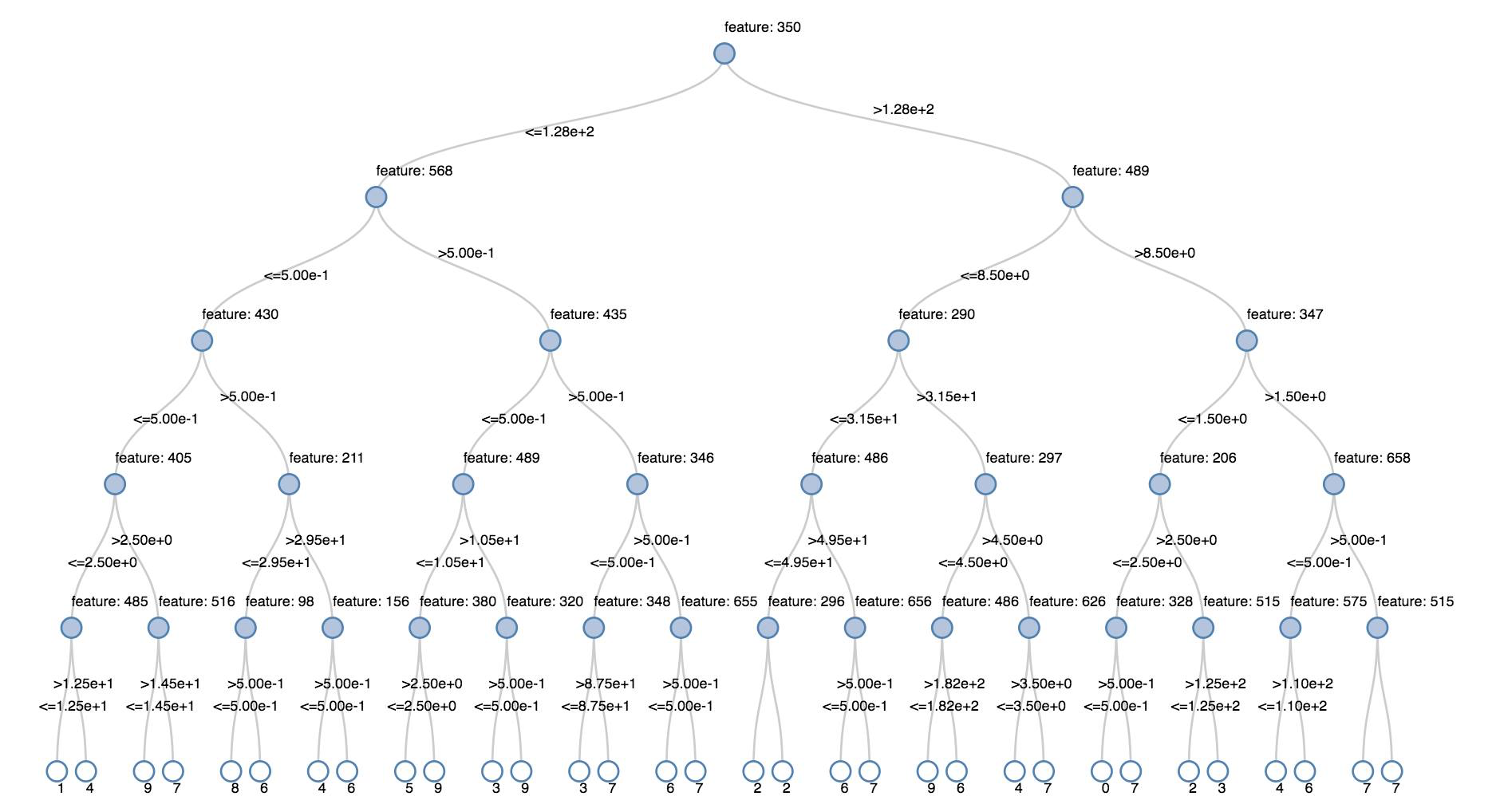
drzewa decyzyjne
Starsze wizualizacje wspierają renderowanie drzewa decyzyjnego.
Aby uzyskać tę wizualizację, podaj model drzewa decyzyjnego.
Poniższe przykłady trenują drzewo do rozpoznawania cyfr (0–9) z zestawu danych MNIST obrazów cyfr zapisanych ręcznie, a następnie wyświetlania drzewa.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Skala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
Ramki danych przesyłania strumieniowego ze strukturą
Aby zwizualizować wynik zapytania przesyłania strumieniowego w czasie rzeczywistym, można użyć funkcji display na ramce danych Structured Streaming w Scala i Python.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Skala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display obsługuje następujące parametry opcjonalne:
-
streamName: nazwa zapytania streamingu. -
trigger(Scala) iprocessingTime(Python): określa, jak często jest uruchamiane zapytanie przesyłania strumieniowego. Jeśli nie zostanie to określone, system sprawdzi dostępność nowych danych zaraz po zakończeniu poprzedniego przetwarzania. Aby zmniejszyć koszty w środowisku produkcyjnym, usługa Databricks zaleca, aby zawsze ustawiać wyzwalacz w stałych odstępach czasu. Domyślny interwał wyzwalacza to 500 ms. -
checkpointLocation: lokalizacja, w której system zapisuje wszystkie informacje o punkcie kontrolnym. Jeśli nie zostanie to określone, system automatycznie generuje tymczasową lokalizację punktów kontrolnych w systemie DBFS. Aby strumień kontynuował przetwarzanie danych z miejsca, w którym został przerwany, należy podać lokalizację punktu kontrolnego. W usłudze Databricks zalecane jest, aby w środowisku produkcyjnym zawsze określić opcjęcheckpointLocation.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Skala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Aby uzyskać więcej informacji na temat tych parametrów, zobacz Uruchamianie zapytań przesyłania strumieniowego.
Funkcja displayHTML
Notesy języka programowania (Python, R i Scala) w usłudze Azure Databricks obsługują grafiki HTML przy użyciu funkcji displayHTML. Można przekazać funkcję dowolnego kodu HTML, CSS lub JavaScript. Ta funkcja obsługuje interaktywne grafiki przy użyciu bibliotek JavaScript, takich jak D3.
Aby poznać przykłady korzystania z funkcji displayHTML, zobacz:
Uwaga
Element iframe displayHTML jest obsługiwany z poziomu domeny databricksusercontent.com, a piaskownica iframe zawiera atrybut allow-same-origin. Domena databricksusercontent.com musi być dostępna z poziomu przeglądarki. Jeśli sieć firmowa blokuje ją obecnie, musi zostać dodana do listy dozwolonych.
Obrazy
Kolumny zawierające typy danych obrazu są renderowane jako sformatowany kod HTML. Usługa Azure Databricks próbuje renderować miniatury obrazów dla kolumn DataFrame pasujących do Spark ImageSchema.
Renderowanie miniatur działa dla wszystkich obrazów pomyślnie odczytanych przez funkcję spark.read.format('image'). W przypadku wartości obrazów generowanych za pomocą innych środków usługa Azure Databricks obsługuje renderowanie obrazów 1, 3 lub 4 kanałów (gdzie każdy kanał składa się z jednego bajtu), z następującymi ograniczeniami:
-
Obrazy z jednym kanałem: pole
modemusi być równe 0. Polaheight,widthinChannelsmuszą precyzyjnie opisywać dane obrazu binarnego w poludata. -
Obrazy z trzema kanałami: pole
modemusi być równe 16. Polaheight,widthinChannelsmuszą precyzyjnie opisywać dane obrazu binarnego w poludata. Poledatamusi zawierać dane pikseli w trójbajtowych fragmentach, z porządkiem kanałów(blue, green, red)dla każdego piksela. -
Obrazy z czterema kanałami: pole
modemusi być równe 24. Polaheight,widthinChannelsmuszą precyzyjnie opisywać dane obrazu binarnego w poludata. Poledatamusi zawierać dane pikseli w czterobajtowych fragmentach, z zachowaniem kolejności kanałów(blue, green, red, alpha)dla każdego piksela.
Przykład
Załóżmy, że masz folder zawierający obrazy:

Jeśli odczytujesz obrazy w ramce danych, a następnie wyświetlisz ramkę danych, usługa Azure Databricks renderuje miniatury obrazów:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Wizualizacje w języku Python
W tej sekcji:
Seaborn
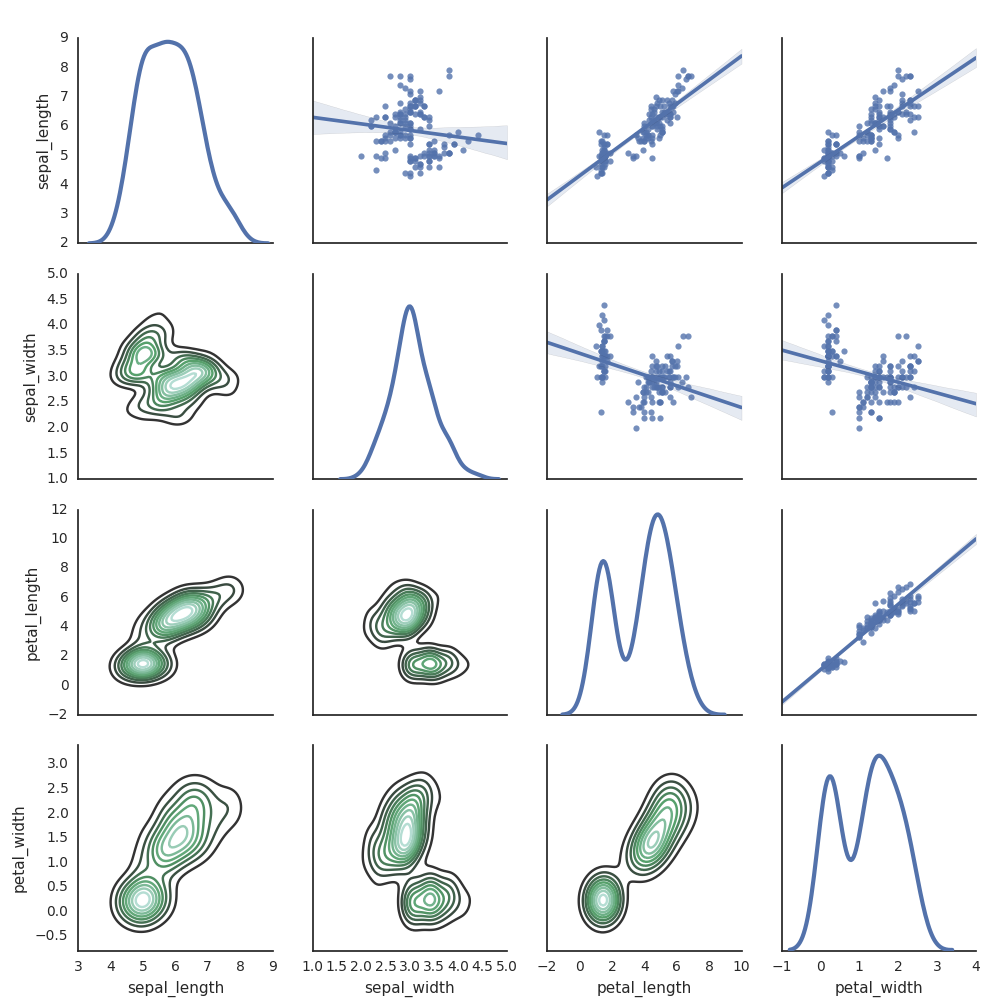
Do generowania wykresów można również użyć innych bibliotek języka Python. Środowisko Databricks Runtime zawiera bibliotekę wizualizacji seaborn. Aby utworzyć wykres seaborn, zaimportuj bibliotekę, utwórz wykres i przekaż wykres do funkcji display.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Inne biblioteki języka Python
Wizualizacje w języku R
Aby utworzyć wykres danych w języku R, użyj funkcji display w następujący sposób:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Możesz użyć domyślnej funkcji wykresu języka R.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
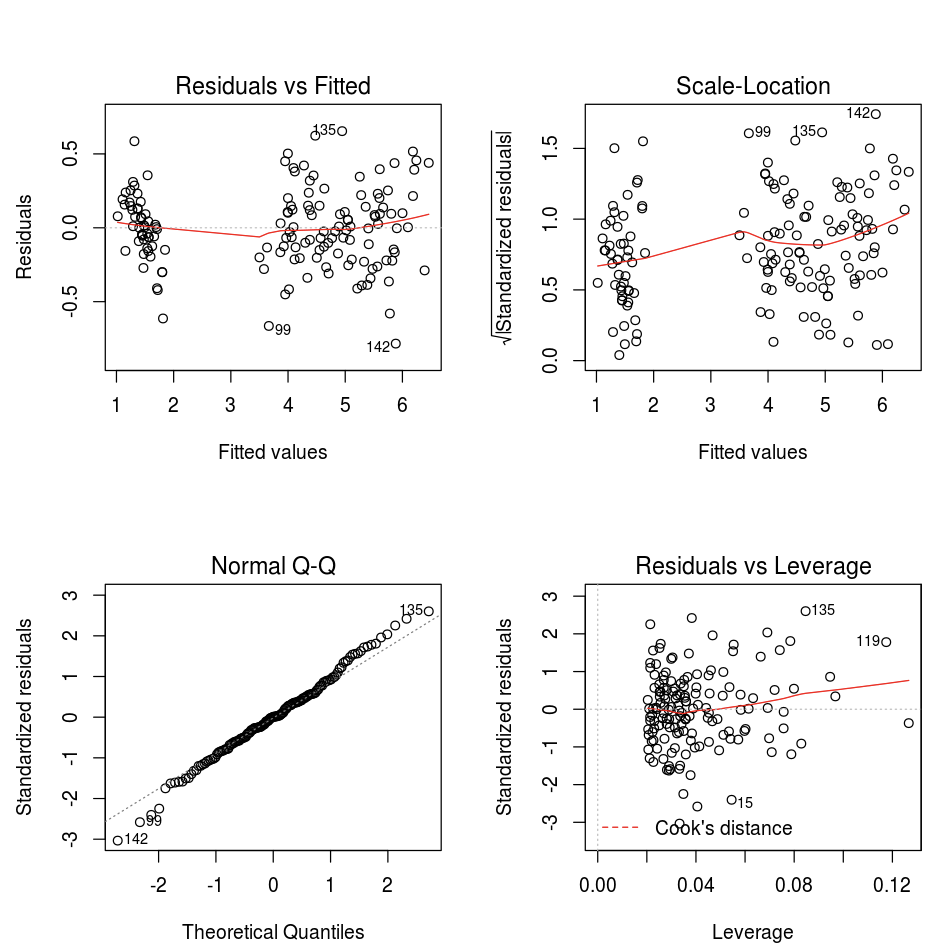
Możesz również użyć dowolnego pakietu wizualizacji języka R. Notebook R przechwytuje powstający wykres jako .png i wyświetla go w linii.
W tej sekcji:
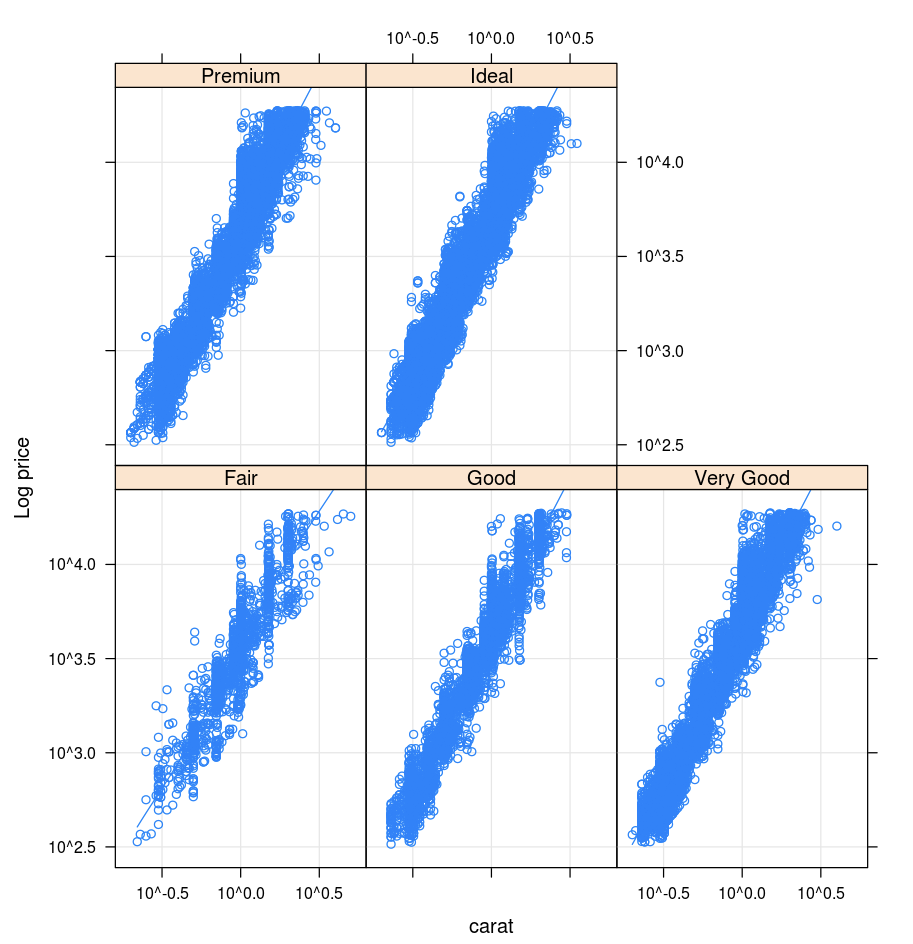
Krata
Pakiet Lattice obsługuje wykresy Trellis — wykresy, które pokazują zmienną lub relację między zmiennymi, warunkowane jedną lub więcej innymi zmiennymi.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
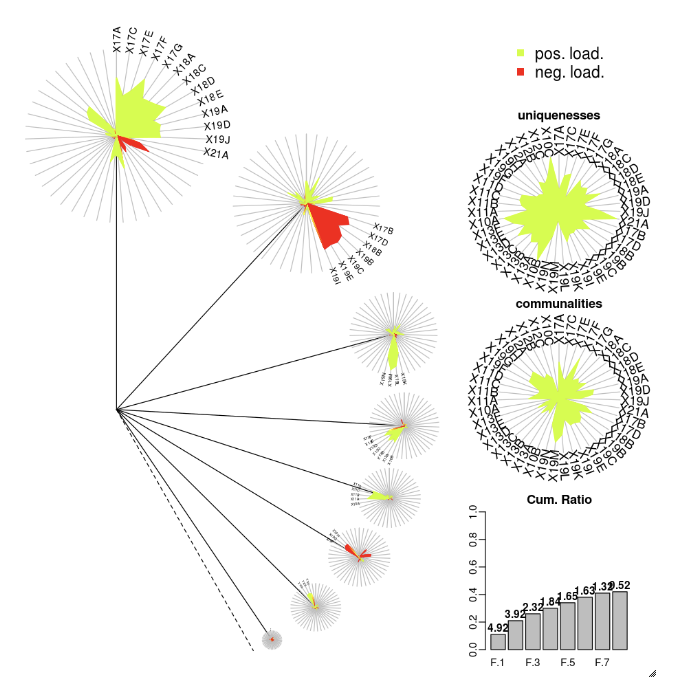
DandEFA
Pakiet DandEFA obsługuje wykresy Dandelion.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Plotly
Pakiet Plotly R opiera się na htmlwidgets dla języka R. Aby uzyskać instrukcje dotyczące instalacji i notes, zobacz htmlwidgets.
Inne biblioteki języka R
Wizualizacje w języku Scala
Aby utworzyć wykres danych w języku Scala, użyj funkcji display w następujący sposób:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Dogłębne notatniki dla języków Python i Scala
Szczegółowe informacje na temat wizualizacji języka Python można znaleźć w notesie:
Szczegółowe informacje na temat wizualizacji języka Scala można znaleźć w notesie: