Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Foldery Git w Databricks mogą być używane w procesach CI/CD. Konfigurując foldery Git usługi Databricks w obszarze roboczym, możesz użyć kontroli źródła do pracy w repozytoriach Git i zintegrować je z przepływami pracy inżynierii danych. Aby uzyskać bardziej kompleksowe omówienie ciągłej integracji/ciągłego wdrażania w usłudze Azure Databricks, zobacz Ciągła integracja/ciągłe wdrażanie w usłudze Azure Databricks.
Przepływy użycia
Większość prac nad automatyzacją folderów Git polega na początkowej konfiguracji folderów oraz zrozumieniu interfejsu API REST usługi Azure Databricks Repos, wykorzystywanego do automatyzacji operacji Git w zadaniach Azure Databricks. Przed rozpoczęciem tworzenia automatyzacji i konfigurowania folderów przejrzyj zdalne repozytoria Git, które zostaną włączone do przepływów automatyzacji, i wybierz odpowiednie dla różnych etapów automatyzacji, w tym programowania, integracji, przemieszczania i produkcji.
- Przepływ administracyjny: w przypadku przepływów produkcyjnych administrator obszaru roboczego usługi Azure Databricks konfiguruje foldery najwyższego poziomu w obszarze roboczym w celu hostowania produkcyjnych folderów git. Administrator klonuje repozytorium Git i gałąź podczas ich tworzenia i może nadać tym folderom znaczące nazwy, takie jak "Production", "Test" lub "Staging", które odpowiadają celom zdalnych repozytoriów Git w przepływach programistycznych. Aby uzyskać więcej informacji, zobacz Folder Production Git (Produkcyjny folder Git).
-
Przepływ użytkownika: użytkownik może utworzyć folder Git na podstawie zdalnego repozytorium, umieszczając go w
/Workspace/Users/<email>/. Użytkownik tworzy lokalną gałąź specyficzną dla siebie, na którą zatwierdzi swoją pracę i wypchnie ją do zdalnego repozytorium. Aby uzyskać informacje na temat współpracy w folderach Git specyficznych dla użytkownika, zobacz Współpraca przy użyciu folderów Git. - Przepływ scalania: użytkownicy mogą tworzyć pull requesty po przesłaniu z folderu Git. Po scaleniu żądania ściągnięcia automatyzacja może ściągnąć zmiany do produkcyjnych folderów Git przy użyciu interfejsu API usługi Azure Databricks Repos.
Współpraca przy użyciu folderów Git
Możesz łatwo współpracować z innymi osobami przy użyciu folderów Git, ściągać aktualizacje i wypychać zmiany bezpośrednio z interfejsu użytkownika usługi Azure Databricks. Na przykład użyj funkcji lub gałęzi programistycznej, aby zagregować zmiany wprowadzone w wielu gałęziach.
W poniższym przepływie opisano sposób współpracy przy użyciu gałęzi funkcji:
- Sklonuj istniejące repozytorium Git do obszaru roboczego usługi Databricks.
- Użyj interfejsu użytkownika folderów Git, aby utworzyć gałąź funkcji z gałęzi głównej. Aby wykonać swoją pracę, możesz utworzyć i użyć wielu gałęzi funkcji.
- Wprowadź zmiany w notesach usługi Azure Databricks i innych plikach w repozytorium.
- Zatwierdź i wypchnij zmiany do zdalnego repozytorium Git.
- Współautorzy mogą teraz sklonować repozytorium Git do własnego folderu użytkownika.
- Pracując nad nową gałęzią, współpracownik wprowadza zmiany w notesach i innych plikach w folderze Git.
- Kontrybutor zatwierdza i wypycha swoje zmiany do zdalnego repozytorium Git.
- Gdy ty lub inni współautorzy będą gotowi scalić kod, utwórz żądanie scalenia na stronie dostawcy Gita. Przed scaleniem zmian w gałęzi wdrażania przejrzyj kod z zespołem.
Uwaga / Notatka
Databricks zaleca, aby każdy deweloper pracował na własnej gałęzi. Aby uzyskać informacje na temat rozwiązywania konfliktów scalania, zobacz Rozwiązywanie konfliktów scalania.
Wybierz podejście do CI/CD
Databricks zaleca używanie Databricks Asset Bundles do pakowania i wdrażania przepływów pracy CI/CD. Jeśli wolisz wdrożyć tylko kod kontrolowany przez źródło w obszarze roboczym, możesz skonfigurować produkcyjny folder Git. Aby uzyskać bardziej kompleksowe omówienie ciągłej integracji/ciągłego wdrażania w usłudze Azure Databricks, zobacz Ciągła integracja/ciągłe wdrażanie w usłudze Azure Databricks.
Wskazówka
Zdefiniuj zasoby, takie jak zadania i potoki, w plikach źródłowych przy użyciu pakietów, a następnie utwórz, wdrażaj i zarządzaj pakietami w folderach Git obszaru roboczego. Zobacz Współpraca nad pakietami w obszarze roboczym.
Folder Git produkcyjny
Produkcyjne foldery Git mają inny cel niż foldery Git na poziomie użytkownika znajdujące się w folderze użytkownika w /Workspace/Users/. Katalogi Git na poziomie użytkownika działają jako lokalne kopie robocze, w których użytkownicy tworzą i wypychają zmiany w kodzie. Natomiast produkcyjne foldery Git są tworzone przez administratorów usługi Databricks poza folderami użytkowników i zawierają gałęzie wdrożenia produkcyjnego. Foldery produkcyjne Git zawierają źródło zautomatyzowanych przepływów pracy i powinny być aktualizowane programowo tylko wtedy, gdy pull requesty są scalane z gałęziami wdrożeniowymi. W przypadku produkcyjnych folderów Git ogranicz dostęp użytkowników tylko do uruchamiania i zezwalaj tylko administratorom i jednostkom usługi Azure Databricks na edycję.
Aby utworzyć folder produkcyjny dla Git:
Wybierz repozytorium Git i gałąź do wdrożenia.
Uzyskaj jednostkę usługi i skonfiguruj poświadczenia git dla jednostki usługi w celu uzyskania dostępu do tego repozytorium Git.
Utwórz folder Azure Databricks Git dla repozytorium Git i gałęzi w podfolderze dedykowanym pod
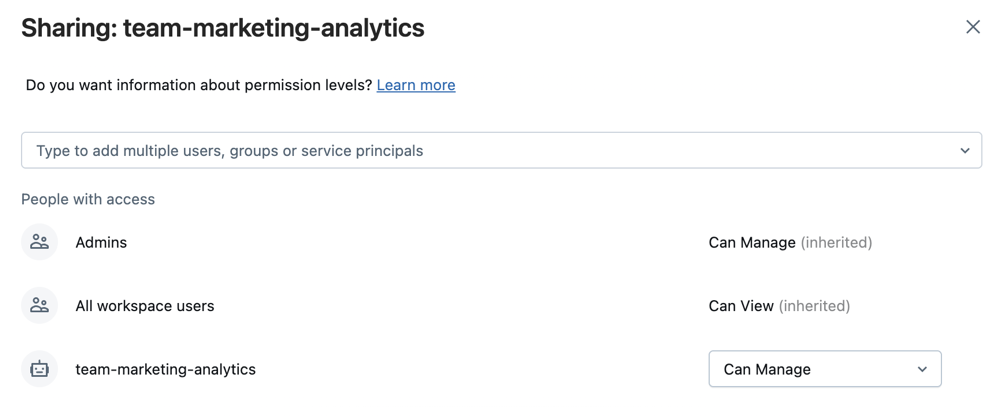
Workspace, przeznaczonym dla projektu, zespołu i etapu rozwoju.Wybierz pozycję Udostępnij po wybraniu folderu lub Udostępnij (uprawnienia), klikając prawym przyciskiem myszy folder w drzewie Obszaru roboczego . Skonfiguruj folder Git z następującymi uprawnieniami:
- Set Can Run for any project users (Ustawianie możliwości uruchamiania dla dowolnego użytkownika projektu)
- Ustaw opcję Można uruchomić dla dowolnego konta jednostki usługi Azure Databricks, które będą uruchamiać automatyzację.
- Jeśli jest to odpowiednie dla Twojego projektu, ustaw opcję Może wyświetlać dla wszystkich użytkowników w przestrzeni roboczej, aby zachęcić do odkrywania i udostępniania.
Wybierz Dodaj.
Konfigurowanie automatycznych aktualizacji folderów Git usługi Databricks. Możesz użyć automatyzacji, aby zachować produkcyjny folder Git zsynchronizowany z gałęzią zdalną, wykonując jedną z następujących czynności:
- Użyj zewnętrznych narzędzi CI/CD, takich jak GitHub Actions, aby automatycznie ściągnąć najnowsze zatwierdzenia do produkcyjnego folderu Git, gdy pull request scala się z gałęzią wdrażania. Aby zapoznać się z przykładem funkcji GitHub Actions, zobacz Uruchom przepływ pracy CI/CD, który aktualizuje folder Git w środowisku produkcyjnym.
- Jeśli nie masz dostępu do zewnętrznych narzędzi CI/CD, utwórz zadanie zaplanowane do zaktualizowania folderu Git w obszarze roboczym na podstawie zdalnej gałęzi. Zaplanuj okresowe uruchamianie prostego notesu przy użyciu następującego kodu:
from databricks.sdk import WorkspaceClient w = WorkspaceClient() w.repos.update(w.workspace.get_status(path=”<git-folder-workspace-full-path>”).object_id, branch=”<branch-name>”)
Aby uzyskać więcej informacji na temat automatyzacji za pomocą interfejsu API repozytoriów usługi Azure Databricks, zobacz dokumentację interfejsu API REST usługi Databricks dla repozytoriów.