Uruchamianie zadania usługi Azure Databricks z bezserwerowym obliczeniami dla przepływów pracy
Ważne
Bezserwerowe obliczenia dla przepływów pracy są w publicznej wersji zapoznawczej. Aby uzyskać informacje na temat uprawnień i włączania, zobacz Włączanie bezserwerowej publicznej wersji zapoznawczej obliczeń.
Ważne
Ważne
Ponieważ publiczna wersja zapoznawcza bezserwerowych obliczeń dla przepływów pracy nie obsługuje kontrolowania ruchu wychodzącego, zadania mają pełny dostęp do Internetu.
Bezserwerowe obliczenia dla przepływów pracy umożliwiają uruchamianie zadania usługi Azure Databricks bez konfigurowania i wdrażania infrastruktury. W przypadku bezserwerowych zasobów obliczeniowych koncentrujesz się na implementowaniu potoków przetwarzania i analizy danych, a usługa Azure Databricks efektywnie zarządza zasobami obliczeniowymi, w tym optymalizowanie i skalowanie zasobów obliczeniowych dla obciążeń. Skalowanie automatyczne i narzędzie Photon są automatycznie włączone dla zasobów obliczeniowych, które uruchamiają zadanie.
Bezserwerowe obliczenia dla przepływów pracy automatycznej optymalizacji automatycznie optymalizują zasoby obliczeniowe, wybierając odpowiednie zasoby, takie jak typy wystąpień, pamięć i aparaty przetwarzania na podstawie obciążenia. Automatyczna optymalizacja również automatycznie ponawia próby zadań, które zakończyły się niepowodzeniem.
Usługa Databricks automatycznie uaktualnia wersję środowiska Databricks Runtime w celu obsługi ulepszeń i uaktualnień platformy przy jednoczesnym zapewnieniu stabilności zadań usługi Azure Databricks. Aby wyświetlić bieżącą wersję środowiska Databricks Runtime używaną przez bezserwerowe obliczenia dla przepływów pracy, zobacz Informacje o wersji obliczeniowej bezserwerowej.
Ponieważ uprawnienia do tworzenia klastra nie są wymagane, wszyscy użytkownicy obszaru roboczego mogą używać bezserwerowych obliczeń do uruchamiania przepływów pracy.
W tym artykule opisano używanie interfejsu użytkownika zadań usługi Azure Databricks do tworzenia i uruchamiania zadań, które używają bezserwerowych obliczeń. Można również zautomatyzować tworzenie i uruchamianie zadań, które używają bezserwerowych obliczeń przy użyciu interfejsu API zadań, pakietów zasobów usługi Databricks i zestawu SDK usługi Databricks dla języka Python.
- Aby dowiedzieć się więcej o używaniu interfejsu API zadań do tworzenia i uruchamiania zadań korzystających z bezserwerowych obliczeń, zobacz Zadania w dokumentacji interfejsu API REST.
- Aby dowiedzieć się więcej o używaniu pakietów zasobów usługi Databricks do tworzenia i uruchamiania zadań korzystających z bezserwerowych obliczeń, zobacz Tworzenie zadania w usłudze Azure Databricks przy użyciu pakietów zasobów usługi Databricks.
- Aby dowiedzieć się więcej na temat używania zestawu SDK usługi Databricks dla języka Python do tworzenia i uruchamiania zadań korzystających z bezserwerowych obliczeń, zobacz Zestaw SDK usługi Databricks dla języka Python.
Wymagania
- Obszar roboczy usługi Azure Databricks musi mieć włączony wykaz aparatu Unity.
- Ponieważ przetwarzanie bezserwerowe dla przepływów pracy korzysta z trybu dostępu współdzielonego, obciążenia muszą obsługiwać ten tryb dostępu.
- Obszar roboczy usługi Azure Databricks musi znajdować się w obsługiwanym regionie. Zobacz Regiony usługi Azure Databricks.
Tworzenie zadania przy użyciu obliczeń bezserwerowych
Przetwarzanie bezserwerowe jest obsługiwane w przypadku typów zadań notebook, skryptów języka Python, dbt i python wheel. Domyślnie obliczenia bezserwerowe są wybierane jako typ obliczeniowy podczas tworzenia nowego zadania i dodawania jednego z tych obsługiwanych typów zadań.
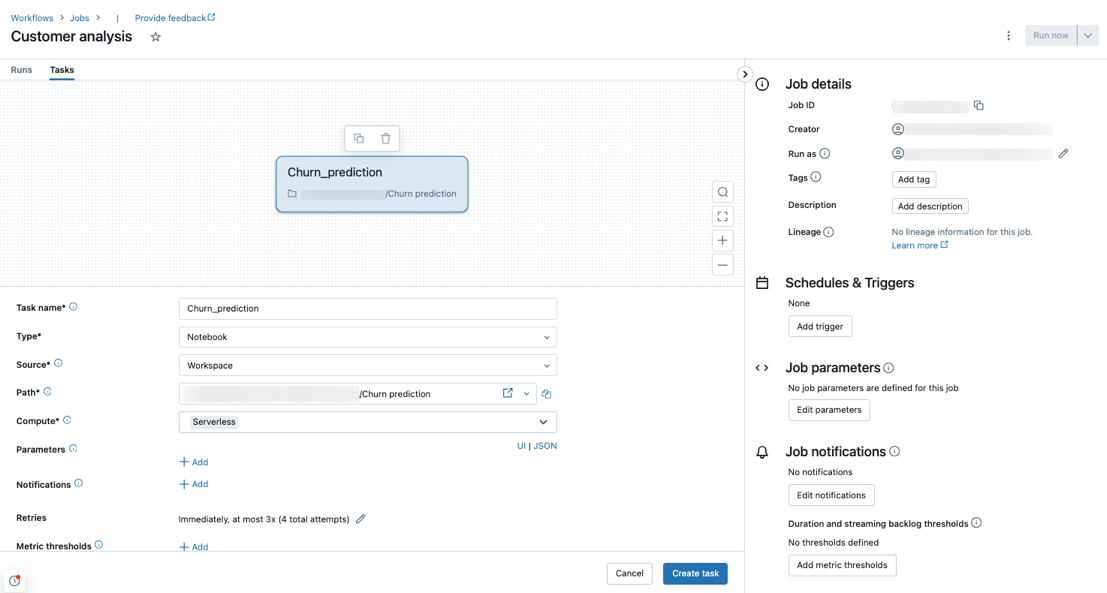
Usługa Databricks zaleca używanie bezserwerowych obliczeń dla wszystkich zadań podrzędnych zadań. Można również określić różne typy zasobów obliczeniowych dla zadań w zadaniu, które mogą być wymagane, jeśli typ zadania nie jest obsługiwany przez bezserwerowe obliczenia dla przepływów pracy.
Konfigurowanie istniejącego zadania do używania bezserwerowych obliczeń
Istniejące zadanie można przełączyć, aby używać bezserwerowych obliczeń dla obsługiwanych typów zadań podczas edytowania zadania. Aby przełączyć się na obliczenia bezserwerowe, wykonaj jedną z następujących czynności:
- W panelu bocznym Szczegóły zadania kliknij pozycję Zamień w obszarze Obliczenia, kliknij pozycję Nowy, wprowadź lub zaktualizuj dowolne ustawienia, a następnie kliknij przycisk Aktualizuj.
- Kliknij
 menu rozwijane Obliczenia i wybierz pozycję Bezserwerowa.
menu rozwijane Obliczenia i wybierz pozycję Bezserwerowa.

Planowanie notesu przy użyciu obliczeń bezserwerowych
Oprócz używania interfejsu użytkownika zadań do tworzenia i planowania zadania przy użyciu obliczeń bezserwerowych można utworzyć i uruchomić zadanie korzystające z bezserwerowych obliczeń bezpośrednio z notesu usługi Databricks. Zobacz Tworzenie zaplanowanych zadań notesu i zarządzanie nimi.
Ustawianie parametrów konfiguracji platformy Spark
Możesz ustawić następujące parametry konfiguracji platformy Spark, ale tylko na poziomie sesji, ustawiając je w notesie, który jest częścią zadania. Zobacz Pobieranie i ustawianie właściwości konfiguracji platformy Apache Spark w notesie.
spark.sql.legacy.timeParserPolicyspark.sql.session.timeZone
Konfigurowanie środowisk i zależności notesu
Aby zarządzać zależnościami biblioteki i konfiguracją środowiska dla zadania notesu, dodaj konfigurację do komórki w notesie. W poniższym przykładzie biblioteki języka Python są instalowane z pip install plików obszaru roboczego oraz z plikiem requirements.txt i ustawiają zmienną spark.sql.session.timeZone sesji:
%pip install -r ./requirements.txt
%pip install simplejson
%pip install /Volumes/my/python.whl
%pip install /Workspace/my/python.whl
%pip install https://some-distro.net/popular.whl
spark.conf.set('spark.sql.session.timeZone', 'Europe/Amsterdam')
Aby ustawić to samo środowisko w wielu notesach, możesz użyć jednego notesu do skonfigurowania środowiska, a następnie użyć %run polecenia magic, aby uruchomić ten notes z dowolnego notesu, który wymaga konfiguracji środowiska. Zobacz Importowanie notesu przy użyciu narzędzia %run.
Konfigurowanie środowisk i zależności dla zadań innych niż notes
W przypadku innych obsługiwanych typów zadań, takich jak skrypt języka Python, koło języka Python lub zadania dbt, domyślne środowisko zawiera zainstalowane biblioteki języka Python. Aby wyświetlić listę zainstalowanych bibliotek, zobacz sekcję Zainstalowane biblioteki języka Python w informacjach o wersji środowiska Databricks Runtime, na której bazuje bezserwerowe zasoby obliczeniowe dla wdrożeń przepływów pracy. Aby wyświetlić bieżącą wersję środowiska Databricks Runtime używaną przez bezserwerowe obliczenia dla przepływów pracy, zobacz Informacje o wersji obliczeniowej bezserwerowej. Biblioteki języka Python można również zainstalować, jeśli zadanie wymaga biblioteki, która nie jest zainstalowana. Biblioteki języka Python można zainstalować z plików obszaru roboczego, woluminów wykazu aparatu Unity lub repozytoriów pakietów publicznych. Aby dodać bibliotekę podczas tworzenia lub edytowania zadania:
W menu rozwijanym Środowisko i biblioteki kliknij
 obok środowiska domyślnego lub kliknij pozycję + Dodaj nowe środowisko.
obok środowiska domyślnego lub kliknij pozycję + Dodaj nowe środowisko.
W oknie dialogowym Konfigurowanie środowiska kliknij pozycję + Dodaj bibliotekę.
Wybierz typ zależności z menu rozwijanego w obszarze Biblioteki.
W polu tekstowym Ścieżka pliku wprowadź ścieżkę do biblioteki.
W przypadku koła języka Python w pliku obszaru roboczego ścieżka powinna być bezwzględna i zaczynać się od
/Workspace/.W przypadku koła języka Python w woluminie wykazu aparatu Unity ścieżka powinna być
/Volumes/<catalog>/<schema>/<volume>/<path>.whlnastępująca: .requirements.txtW przypadku pliku wybierz pozycję PyPi i wprowadź .-r /path/to/requirements.txt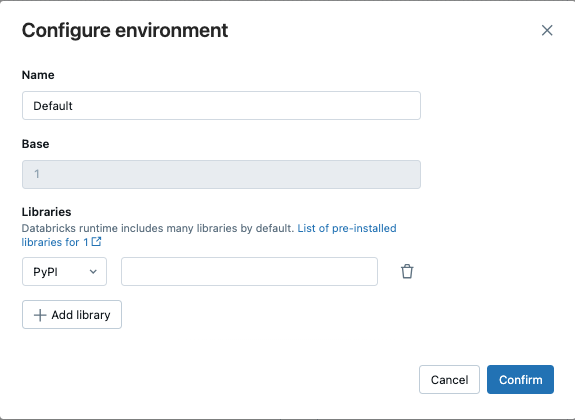
- Kliknij pozycję Potwierdź lub + Dodaj bibliotekę, aby dodać kolejną bibliotekę .
- Jeśli dodajesz zadanie, kliknij pozycję Utwórz zadanie. Jeśli edytujesz zadanie, kliknij pozycję Zapisz zadanie.
Konfigurowanie automatycznej optymalizacji obliczeń bezserwerowych w celu uniemożliwiania ponawiania prób
Bezserwerowe obliczenia dla przepływów pracy automatycznej optymalizacji automatycznie optymalizuje obliczenia używane do uruchamiania zadań i ponawiania prób zadań, które zakończyły się niepowodzeniem. Automatyczna optymalizacja jest domyślnie włączona, a usługa Databricks zaleca pozostawienie go włączonego w celu zapewnienia pomyślnego uruchomienia co najmniej raz krytycznych obciążeń. Jeśli jednak masz obciążenia, które muszą być wykonywane co najwyżej raz, na przykład zadania, które nie są idempotentne, możesz wyłączyć automatyczną optymalizację podczas dodawania lub edytowania zadania:
- Obok pozycji Ponawianie prób kliknij przycisk Dodaj (lub jeśli już istnieją zasady ponawiania).
- W oknie dialogowym Zasady ponawiania próby usuń zaznaczenie pola wyboru Włącz automatyczną optymalizację bezserwerową (może obejmować dodatkowe ponawianie prób).
- Kliknij przycisk Potwierdź.
- Jeśli dodajesz zadanie, kliknij pozycję Utwórz zadanie. Jeśli edytujesz zadanie, kliknij pozycję Zapisz zadanie.
Monitorowanie kosztów zadań, które używają bezserwerowych obliczeń dla przepływów pracy
Koszt zadań, które używają bezserwerowych obliczeń dla przepływów pracy, można monitorować, wykonując zapytanie względem tabeli systemu użycia rozliczanego. Ta tabela jest aktualizowana w celu uwzględnienia atrybutów użytkownika i obciążenia dotyczących kosztów bezserwerowych. Zobacz Informacje o tabelach systemu użycia rozliczanego.
Wyświetlanie szczegółów zapytań platformy Spark
Bezserwerowe obliczenia dla przepływów pracy mają nowy interfejs do wyświetlania szczegółowych informacji o środowisku uruchomieniowym dla instrukcji platformy Spark, takich jak metryki i plany zapytań. Aby wyświetlić szczegółowe informacje o zapytaniach dla instrukcji platformy Spark zawartych w zadaniach uruchamianych w obliczeniach bezserwerowych:
- Kliknij pozycję
 Przepływy pracy na pasku bocznym.
Przepływy pracy na pasku bocznym. - W kolumnie Nazwa kliknij nazwę zadania, dla którego chcesz wyświetlić szczegółowe informacje.
- Kliknij konkretny przebieg, dla którego chcesz wyświetlić szczegółowe informacje.
- W sekcji Obliczenia panelu bocznego Uruchomienia zadania kliknij pozycję Historia zapytań.
- Nastąpi przekierowanie do historii zapytań wstępnie przefiltrowanych na podstawie identyfikatora uruchomienia zadania, w którym znajdowało się zadanie.
Aby uzyskać informacje na temat korzystania z historii zapytań, zobacz Historia zapytań.
Ograniczenia
Aby uzyskać listę bezserwerowych obliczeń dotyczących ograniczeń przepływów pracy, zobacz Ograniczenia obliczeń bezserwerowych w informacjach o wersji obliczeniowej bezserwerowej.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla