Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano pobieranie rozszerzonej generacji (RAG) i elementy, których deweloperzy potrzebują do utworzenia gotowego do produkcji rozwiązania RAG.
Aby dowiedzieć się więcej o dwóch sposobach tworzenia aplikacji "czatu za pośrednictwem danych" — jednego z najważniejszych przypadków użycia sztucznej inteligencji dla firm — zobacz Rozszerzanie llms za pomocą funkcji RAG lub dostrajanie.
Na poniższym diagramie przedstawiono główne kroki programu RAG:
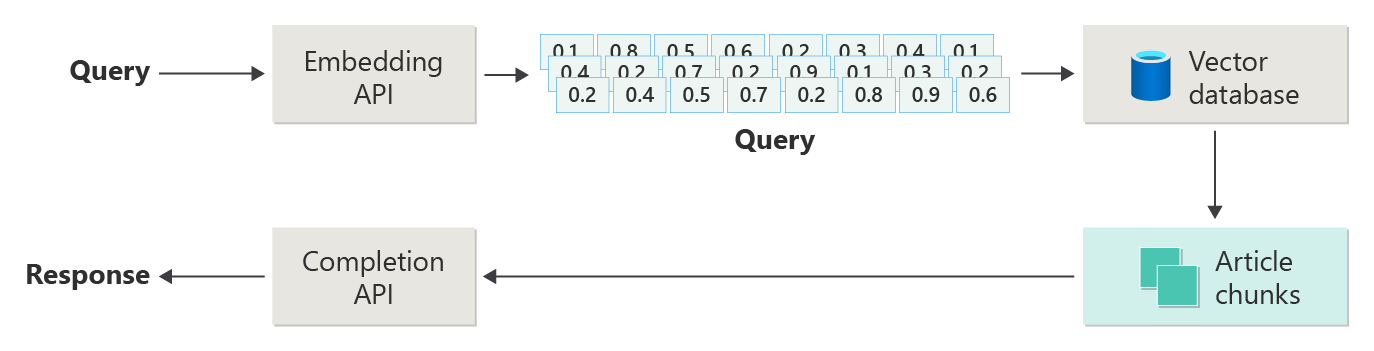
Ten proces jest nazywany naiwnym RAG. Pomaga to zrozumieć podstawowe części i role w systemie czatów opartym na programie RAG.
Rzeczywiste systemy RAG wymagają więcej wstępnego przetwarzania i przetwarzania końcowego w celu obsługi artykułów, zapytań i odpowiedzi. Na następnym diagramie przedstawiono bardziej realistyczną konfigurację o nazwie advanced RAG:

Ten artykuł zawiera prostą strukturę, która pozwala zrozumieć główne fazy w rzeczywistym systemie czatów opartym na systemie RAG:
- Faza pozyskiwania
- Faza przetwarzania wnioskowania
- Faza oceny
Pozyskiwanie danych
Pozyskiwanie oznacza zapisanie dokumentów organizacji, dzięki czemu można szybko znaleźć odpowiedzi dla użytkowników. Głównym wyzwaniem jest znalezienie i użycie części dokumentów, które najlepiej pasują do każdego pytania. Większość systemów używa osadzania wektorów i wyszukiwania podobieństwa cosinus, aby dopasować pytania do zawartości. Uzyskasz lepsze wyniki, gdy rozumiesz typ zawartości (na przykład wzorce i format) i porządkuj dane w bazie danych wektorów.
Podczas konfigurowania pozyskiwania skoncentruj się na następujących krokach:
- Wstępne przetwarzanie i wyodrębnianie zawartości
- Strategia fragmentowania
- Organizacja fragmentowania
- Strategia aktualizacji
Wstępne przetwarzanie i wyodrębnianie zawartości
Pierwszym krokiem fazy pozyskiwania jest wstępne przetwarzanie i wyodrębnianie zawartości z dokumentów. Ten krok ma kluczowe znaczenie, ponieważ gwarantuje, że tekst jest czysty, ustrukturyzowany i gotowy do indeksowania i pobierania.
Czysta i dokładna zawartość sprawia, że system czatów oparty na rag działa lepiej. Zacznij od przyjrzenia się kształtowi i stylowi dokumentów, które chcesz indeksować. Czy są one zgodne ze wzorcem zestawu, na przykład dokumentacją? Jeśli nie, jakie pytania mogą odpowiedzieć na te dokumenty?
Skonfiguruj co najmniej potok pozyskiwania w taki sposób, aby:
- Standaryzacja formatów tekstu
- Obsługa znaków specjalnych
- Usuwanie niepowiązanej lub starej zawartości
- Śledzenie różnych wersji zawartości
- Obsługa zawartości za pomocą kart, obrazów lub tabel
- Wyodrębnianie metadanych
Niektóre z tych informacji, takie jak metadane, mogą pomóc podczas pobierania i oceny, jeśli zachowasz go z dokumentem w bazie danych wektorów. Możesz również połączyć go z fragmentem tekstu, aby poprawić osadzanie wektora fragmentu.
Strategia fragmentowania
Jako deweloper zdecyduj, jak podzielić duże dokumenty na mniejsze fragmenty. Fragmentowanie pomaga wysyłać najbardziej odpowiednią zawartość do modułu LLM, dzięki czemu może lepiej odpowiedzieć na pytania użytkowników. Ponadto zastanów się, jak będziesz używać fragmentów po ich otrzymaniu. Wypróbuj typowe metody branżowe i przetestuj strategię fragmentowania w organizacji.
Podczas fragmentowania pomyśl o:
- Optymalizacja rozmiaru fragmentów: wybierz najlepszy rozmiar fragmentu i sposób jego podziału — według sekcji, akapitu lub zdania.
- Nakładające się i przesuwane fragmenty okien: zdecyduj, czy fragmenty powinny być oddzielone lub nakładające się. Można również użyć podejścia do okna przesuwnego.
- Small2Big: Jeśli podzielisz zdanie, zorganizuj zawartość, aby znaleźć pobliskie zdania lub pełny akapit. Nadanie tego dodatkowego kontekstu llm może pomóc mu lepiej odpowiedzieć. Aby uzyskać więcej informacji, zobacz następną sekcję.
Organizacja fragmentowania
W systemie RAG sposób organizowania danych w bazie danych wektorów ułatwia i szybsze znajdowanie odpowiednich informacji. Poniżej przedstawiono kilka sposobów konfigurowania indeksów i wyszukiwań:
- Indeksy hierarchiczne: użyj warstw indeksów. Indeks podsumowania najwyższego poziomu szybko znajduje niewielki zestaw prawdopodobnych fragmentów. Indeks drugiego poziomu wskazuje na dokładne dane. Ta konfiguracja przyspiesza wyszukiwanie, zawężając opcje przed szczegółowym sprawdzeniem.
- Wyspecjalizowane indeksy: wybierz indeksy pasujące do danych. Na przykład użyj indeksów opartych na grafach, jeśli fragmenty łączą się ze sobą, na przykład w sieciach cytatów lub grafach wiedzy. Użyj relacyjnych baz danych, jeśli dane są w tabelach i filtruj je za pomocą zapytań SQL.
- Indeksy hybrydowe: połącz różne metody indeksowania. Na przykład użyj najpierw indeksu podsumowania, a następnie indeksu opartego na grafach, aby eksplorować połączenia między fragmentami.
Optymalizacja wyrównania
Aby pobrać fragmenty bardziej istotne i dokładne, dopasowując je do typów pytań, na które odpowiadają. Jednym ze sposobów jest utworzenie przykładowego pytania dla każdego fragmentu, które pokazuje, na jakie pytanie najlepiej odpowiada. Takie podejście pomaga na kilka sposobów:
- Ulepszone dopasowywanie: podczas pobierania system porównuje pytanie użytkownika z tymi przykładowymi pytaniami, aby znaleźć najlepszy fragment. Ta technika poprawia znaczenie wyników.
- Dane szkoleniowe dotyczące modeli uczenia maszynowego: te pary fragmentów pytań ułatwiają trenowanie modeli uczenia maszynowego w systemie RAG. Modele uczą się, które fragmenty odpowiadają na typy pytań.
- Obsługa zapytań bezpośrednich: jeśli pytanie użytkownika pasuje do przykładowego pytania, system może szybko znaleźć i użyć odpowiedniego fragmentu, przyspieszając odpowiedź.
Przykładowe pytanie każdego fragmentu działa jako etykieta, która kieruje algorytmem pobierania. Wyszukiwanie staje się bardziej skoncentrowane i świadome kontekstu. Ta metoda sprawdza się dobrze, gdy fragmenty obejmują wiele różnych tematów lub typów informacji.
Strategie aktualizacji
Jeśli organizacja często aktualizuje dokumenty, musisz zachować aktualność bazy danych, aby program pobierający zawsze mógł znaleźć najnowsze informacje. Składnik retriever jest częścią systemu, która wyszukuje bazę danych wektorów i zwraca wyniki. Oto kilka sposobów aktualizowania wektorowej bazy danych:
Aktualizacje przyrostowe:
- Regularne interwały: ustaw aktualizacje do uruchamiania zgodnie z harmonogramem (na przykład codziennie lub co tydzień) na podstawie częstotliwości zmiany dokumentów. Ta akcja powoduje, że baza danych jest świeża.
- Aktualizacje oparte na wyzwalaczach: skonfiguruj aktualizacje automatyczne, gdy ktoś dodaje lub zmienia dokument. System ponownie indeksuje tylko objęte części.
aktualizacje częściowe:
- Selektywne ponowne indeksowanie: zaktualizuj tylko części bazy danych, które uległy zmianie, a nie całej. Ta technika pozwala zaoszczędzić czas i zasoby, szczególnie w przypadku dużych zestawów danych.
- Kodowanie różnicowe: przechowuj tylko zmiany między starymi i nowymi dokumentami, co zmniejsza ilość danych do przetworzenia.
wersjonowanie:
- Migawka: zapisz wersje zestawu dokumentów w różnym czasie. Ta akcja umożliwia powrót lub przywrócenie wcześniejszych wersji w razie potrzeby.
- Kontrola wersji dokumentu: użyj systemu kontroli wersji, aby śledzić zmiany i przechowywać historię dokumentów.
aktualizacje w czasie rzeczywistym:
- Przetwarzanie strumienia: użyj przetwarzania strumienia, aby zaktualizować bazę danych wektorów w czasie rzeczywistym w miarę zmiany dokumentów.
- Wykonywanie zapytań na żywo: użyj zapytań na żywo, aby uzyskać up-to-date odpowiedzi, czasami mieszając dane na żywo z buforowanymi wynikami w celu uzyskania szybkości.
techniki optymalizacji:
- Przetwarzanie wsadowe: grupuj zmiany i zastosuj je razem, aby zaoszczędzić zasoby i zmniejszyć obciążenie.
-
Podejścia hybrydowe: Mieszaj różne strategie:
- Używaj aktualizacji przyrostowych w przypadku małych zmian.
- Użyj pełnego ponownego indeksowania dla znaczących aktualizacji.
- Śledzenie i dokumentowanie istotnych zmian w danych.
Wybierz strategię aktualizacji lub wymieszaj, która odpowiada Twoim potrzebom. Pomyśl o:
- Rozmiar korpusu dokumentu
- Częstotliwość aktualizacji
- Wymagania dotyczące danych w czasie rzeczywistym
- Dostępne zasoby
Przejrzyj te czynniki dla aplikacji. Każda metoda ma kompromisy w złożoności, kosztach i sposobie wyświetlania szybkich aktualizacji.
Potok wnioskowania
Artykuły są teraz fragmentowane, wektoryzowane i przechowywane w bazie danych wektorów. Następnie skoncentruj się na uzyskaniu najlepszych odpowiedzi z systemu.
Aby uzyskać dokładne i szybkie wyniki, zastanów się nad tymi kluczowymi pytaniami:
- Czy pytanie użytkownika jest jasne i może uzyskać właściwą odpowiedź?
- Czy pytanie przerywa jakiekolwiek zasady firmy?
- Czy możesz ponownie napisać pytanie, aby ułatwić systemowi znalezienie lepszych dopasowań?
- Czy wyniki z bazy danych są zgodne z pytaniem?
- Czy należy zmienić wyniki przed wysłaniem ich do usługi LLM, aby upewnić się, że odpowiedź jest odpowiednia?
- Czy odpowiedź llM w pełni odpowiada na pytanie użytkownika?
- Czy odpowiedź jest przestrzegana przez reguły organizacji?
Cały potok wnioskowania działa w czasie rzeczywistym. Nie ma jednego właściwego sposobu konfigurowania kroków przetwarzania wstępnego i przetwarzania końcowego. Używasz kombinacji kodu i wywołań LLM. Jednym z największych kompromisów jest równoważenie dokładności i zgodności z kosztami i szybkością.
Przyjrzyjmy się strategiom dla każdego etapu potoku wnioskowania.
Kroki przetwarzania wstępnego zapytań
Wstępne przetwarzanie zapytań rozpoczyna się bezpośrednio po wysłaniu pytania przez użytkownika:

Te kroki pomagają upewnić się, że pytanie użytkownika pasuje do systemu i jest gotowe do znalezienia najlepszych fragmentów artykułu przy użyciu podobieństwa cosinus lub wyszukiwania "najbliższego sąsiada".
Sprawdzanie zasad: Użyj logiki, aby wykryć i usunąć lub oznaczyć niepożądane treści, takie jak dane osobowe, zły język lub próby złamania zasad bezpieczeństwa (nazywanych "jailbreaking").
Ponowne zapisywanie zapytań: w razie potrzeby zmień pytanie — rozwiń akronimy, usuń slang lub przeprojektuj je, aby skupić się na większych pomysłach (monitowanie krok po kroku).
Specjalna wersja monitowania krok po kroku to Hipotetyczne osadzanie dokumentów (HyDE). HyDE ma odpowiedź LLM na pytanie, tworzy osadzanie z tej odpowiedzi, a następnie wyszukuje bazę danych wektorów.
Zapytania podrzędne
Podzapytania przerywają długie lub złożone pytanie na mniejsze, łatwiejsze pytania. System odpowiada na każde małe pytanie, a następnie łączy odpowiedzi.
Jeśli na przykład ktoś: "Kto wniósł ważniejszy wkład w nowoczesną fizykę, Alberta Einsteina lub Nielsa Bohra?", możesz podzielić go na:
- Subquery 1: "Co Albert Einstein przyczynił się do nowoczesnej fizyki?"
- Subquery 2: "Co Niels Bohr przyczynił się do nowoczesnej fizyki?"
Odpowiedzi mogą obejmować:
- Dla Einsteina: teoria względności, efekt fotoelektryczny i E=mc^2.
- Dla Bohr: model atomu wodoru, pracuje nad mechaniką kwantową i zasadą uzupełniania.
Następnie możesz zadać pytania dotyczące kontynuacji:
- Subquery 3: "Jak teorie Einsteina zmieniły nowoczesną fizykę?"
- Subquery 4: "Jak teorie Bohra zmieniły nowoczesną fizykę?"
Te kontynuacje patrzą na efekt każdego naukowca, na przykład:
- Jak praca Einsteina doprowadziła do nowych pomysłów w kosmologii i teorii kwantowej
- Jak praca Bohra pomogła nam zrozumieć atomy i mechanikę kwantową
System łączy odpowiedzi, aby dać pełną odpowiedź na oryginalne pytanie. Ta metoda ułatwia zadawanie złożonych pytań przez podzielenie ich na jasne, mniejsze części.
Router zapytań
Czasami zawartość znajduje się w kilku bazach danych lub systemach wyszukiwania. W takich przypadkach należy użyć routera zapytań. Router zapytań wybiera najlepszą bazę danych lub indeks, aby odpowiedzieć na każde pytanie.
Router zapytań działa po tym, jak użytkownik zadaje pytanie, ale zanim system wyszuka odpowiedzi.
Oto jak działa router zapytań:
- Analiza zapytań: Narzędzie LLM lub inne narzędzie analizuje pytanie, aby dowiedzieć się, jakiego rodzaju odpowiedź jest potrzebna.
- Wybór indeksu: router wybiera co najmniej jeden indeks pasujący do pytania. Niektóre indeksy są lepsze dla faktów, inne dla opinii lub tematów specjalnych.
- Wysyłanie zapytania: router wysyła pytanie do wybranego indeksu lub indeksów.
- Agregacja wyników: system zbiera i łączy odpowiedzi z indeksów.
- Generowanie odpowiedzi: system tworzy wyraźną odpowiedź przy użyciu znalezionych informacji.
Użyj różnych indeksów lub aparatów wyszukiwania dla:
- Specjalizacja typu danych: Niektóre indeksy koncentrują się na wiadomościach, innych na dokumentach akademickich lub na specjalnych bazach danych, takich jak informacje medyczne lub prawne.
- Optymalizacja typów zapytań: niektóre indeksy są szybkie dla prostych faktów (takich jak daty), podczas gdy inne obsługują złożone lub specjalistyczne pytania.
- Różnice algorytmiczne: Różne aparaty wyszukiwania używają różnych metod, takich jak wyszukiwanie wektorów, wyszukiwanie słów kluczowych lub zaawansowane wyszukiwanie semantyczne.
Na przykład w systemie porad medycznych mogą istnieć następujące elementy:
- Indeks dokumentu badawczego dotyczący szczegółów technicznych
- Indeks analizy przypadku dla rzeczywistych przykładów
- Ogólny indeks kondycji dla podstawowych pytań
Jeśli ktoś zapyta o skutki nowego leku, router wysyła pytanie do indeksu papieru badawczego. Jeśli pytanie dotyczy typowych objawów, używa ogólnego indeksu kondycji, aby uzyskać prostą odpowiedź.
Kroki przetwarzania po pobraniu
Przetwarzanie po pobraniu odbywa się po znalezieniu fragmentów zawartości w bazie danych wektorów:

Następnie sprawdź, czy te fragmenty są przydatne w wierszu polecenia LLM przed wysłaniem ich do usługi LLM.
Pamiętaj o następujących kwestiach:
- Dodatkowe informacje mogą ukrywać najważniejsze szczegóły.
- Nieistotne informacje mogą pogorszyć odpowiedź.
Uważaj na igłę w problemie siana : LLMs często zwracają większą uwagę na początek i koniec monitu niż środek.
Należy również pamiętać o maksymalnym oknie kontekstu llM i liczbie tokenów potrzebnych do długich monitów, szczególnie na dużą skalę.
Aby rozwiązać te problemy, użyj potoku przetwarzania po pobraniu z krokami, takimi jak:
- Wyniki filtrowania: zachowaj tylko fragmenty zgodne z zapytaniem. Ignoruj resztę podczas kompilowania monitu LLM.
- Ponowne klasyfikowanie: umieść najbardziej odpowiednie fragmenty na początku i na końcu monitu.
- Kompresja monitu: użyj małego, taniego modelu, aby podsumować i połączyć fragmenty w jeden monit przed wysłaniem go do usługi LLM.
Kroki przetwarzania po zakończeniu
Przetwarzanie po zakończeniu odbywa się po pytaniu użytkownika, a wszystkie fragmenty zawartości przechodzą do modułu LLM:

Po udzieleniu odpowiedzi w programie LLM sprawdź jego dokładność. Potok przetwarzania po zakończeniu może obejmować:
- Sprawdzanie faktów: Poszukaj stwierdzeń w odpowiedzi, które twierdzą, że fakty, a następnie sprawdź, czy są prawdziwe. Jeśli sprawdzanie faktów nie powiedzie się, możesz ponownie poprosić llm lub wyświetlić komunikat o błędzie.
- Sprawdzanie zasad: upewnij się, że odpowiedź nie zawiera szkodliwej zawartości dla użytkownika lub organizacji.
Ocena
Ocena takiego systemu jest bardziej złożona niż uruchamianie regularnych testów jednostkowych lub integracyjnych. Zastanów się nad tymi pytaniami:
- Czy użytkownicy są zadowoleni z odpowiedzi?
- Czy odpowiedzi są dokładne?
- Jak zbierać opinie użytkowników?
- Czy istnieją reguły dotyczące zbieranych danych?
- Czy widzisz każdy krok, jaki system podjął, gdy odpowiedzi są błędne?
- Czy przechowujesz szczegółowe dzienniki na potrzeby analizy głównej przyczyny?
- Jak zaktualizować system bez pogarszania się sytuacji?
Przechwytywanie opinii użytkowników i podejmowanie działań na ich podstawie
Współpracuj z zespołem ds. ochrony prywatności w organizacji, aby zaprojektować narzędzia do przechwytywania opinii, dane systemowe i rejestrowanie na potrzeby śledczego i analizy głównej przyczyny sesji zapytań.
Następnym krokiem jest utworzenie potoku oceny. Potok oceny ułatwia i szybsze przeglądanie opinii oraz dowiedz się, dlaczego sztuczna inteligencja udzieliła pewnych odpowiedzi. Sprawdź każdą odpowiedź, aby zobaczyć, jak sztuczna inteligencja została utworzona, jeśli użyto odpowiednich fragmentów zawartości i jak dokumenty zostały podzielone.
Ponadto poszukaj dodatkowych kroków przetwarzania wstępnego lub po przetwarzaniu, które mogą poprawić wyniki. Ta bliska recenzja często znajduje luki w zawartości, zwłaszcza jeśli nie ma dobrej dokumentacji dla pytania użytkownika.
Do obsługi tych zadań na dużą skalę potrzebny jest potok oceny. Dobry potok używa niestandardowych narzędzi do mierzenia jakości odpowiedzi. Ułatwia to sprawdzenie, dlaczego sztuczna inteligencja dała określoną odpowiedź, które dokumenty były używane i jak dobrze działa potok wnioskowania.
Złoty zestaw danych
Jednym ze sposobów sprawdzenia, jak działa system czatów RAG, jest użycie złotego zestawu danych. Złoty zestaw danych to zestaw pytań z zatwierdzonymi odpowiedziami, przydatne metadane (takie jak temat i typ pytania), linki do dokumentów źródłowych i różne sposoby zadawania pytań przez użytkowników.
Złoty zestaw danych przedstawia "najlepszy scenariusz przypadku". Deweloperzy używają go do sprawdzenia, jak dobrze działa system i jak działają testy podczas dodawania nowych funkcji lub aktualizacji.
Ocenianie szkody
Modelowanie szkód pomaga wykrywać możliwe zagrożenia w produkcie i planować sposoby ich zmniejszenia.
Narzędzie do oceny szkód powinno obejmować następujące kluczowe funkcje:
- Identyfikacja uczestników projektu: ułatwia wyświetlanie listy i grupowanie wszystkich osób, których dotyczy technologia, w tym bezpośrednich użytkowników, osób dotkniętych pośrednio, przyszłych pokoleń, a nawet środowiska.
- Kategorie szkód i opisy: Wyświetla listę możliwych szkód, takich jak utrata prywatności, cierpienie emocjonalne lub szkody ekonomiczne. Przeprowadzi Cię przez przykłady i pomoże Ci myśleć o oczekiwanych i nieoczekiwanych problemach.
- Oceny ważności i prawdopodobieństwa: pomaga ocenić, jak poważna i prawdopodobna jest każda szkoda, dzięki czemu możesz zdecydować, co należy naprawić jako pierwszy. Możesz użyć danych do obsługi wybranych opcji.
- Strategie ograniczania ryzyka: sugeruje sposoby zmniejszania ryzyka, takich jak zmiana projektu systemu, dodawanie zabezpieczeń lub korzystanie z innych technologii.
- Mechanizmy opinii: umożliwia zbieranie opinii od uczestników projektu, dzięki czemu możesz kontynuować ulepszanie procesu w miarę uczenia się więcej.
- Dokumentacja i raportowanie: ułatwia tworzenie raportów, które pokazują znalezione informacje i co zrobiliśmy, aby zmniejszyć ryzyko.
Te funkcje ułatwiają znajdowanie i naprawianie zagrożeń, a także pomagają w tworzeniu bardziej etycznej i odpowiedzialnej sztucznej inteligencji, myśląc o wszystkich możliwych skutkach od samego początku.
Aby uzyskać więcej informacji, zobacz następujące artykuły:
Testowanie i weryfikowanie zabezpieczeń
Red-teaming jest kluczem — oznacza to działanie jak atakujący w celu znalezienia słabych punktów w systemie. Ten krok jest szczególnie ważny, aby zatrzymać jailbreaking. Aby uzyskać wskazówki dotyczące planowania czerwonego tworzenia zespołu dla odpowiedzialnej sztucznej inteligencji i zarządzania nimi, zobacz Planowanie czerwonego tworzenia zespołu dla dużych modeli językowych (LLM) i ich aplikacji.
Deweloperzy powinni przetestować zabezpieczenia systemu RAG w różnych scenariuszach, aby upewnić się, że działają. Ten krok sprawia, że system jest silniejszy, a także pomaga dostosować odpowiedzi w celu przestrzegania standardów i reguł etycznych.
Końcowe zagadnienia dotyczące projektowania aplikacji
Poniżej przedstawiono kilka kluczowych kwestii, które należy zapamiętać w tym artykule, które mogą pomóc w projektowaniu aplikacji:
- Nieprzewidywalność generowania sztucznej inteligencji
- Monit użytkownika o zmiany i ich wpływ na czas i koszty
- Równoległe żądania LLM w celu uzyskania szybszej wydajności
Aby utworzyć generacyjną aplikację sztucznej inteligencji, zapoznaj się z wprowadzeniem do czatu przy użyciu własnego przykładu danych dla języka Python. Samouczek jest również dostępny dla .NET, Javai JavaScript.