Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
Etap to granica logiczna w potoku Azure DevOps. Etapy grupowania akcji w procesie tworzenia oprogramowania, takie jak kompilowanie aplikacji, uruchamianie testów i wdrażanie w środowisku przedprodukcyjnym. Każdy etap zawiera co najmniej jedno zadania.
Podczas definiowania wielu etapów w potoku technologicznego, domyślnie są one uruchamiane jeden po drugim. Etapy mogą również zależeć od siebie. Możesz użyć słowa kluczowego dependsOn , aby zdefiniować zależności. Etapy mogą być również uruchamiane na podstawie wyniku poprzedniego etapu z warunkami.
Aby dowiedzieć się, jak etapy współpracują z zadaniami równoległymi i licencjonowaniem, zobacz Konfigurowanie zadań równoległych i płacenie za nie.
Aby dowiedzieć się, jak etapy odnoszą się do innych części potoku, takich jak zadania, zobacz Kluczowe pojęcia dotyczące potoków.
Możesz również dowiedzieć się więcej o tym, jak fazy są powiązane z elementami potoku w artykule dotyczącym faz schematu YAML.
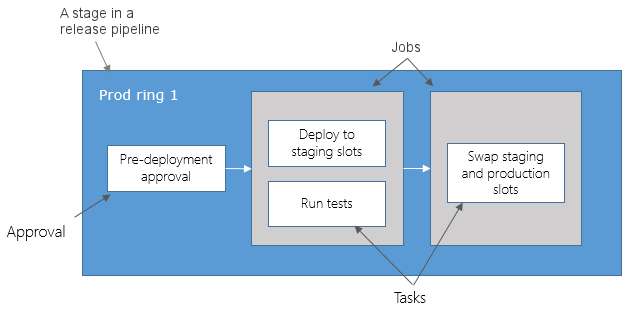
Zadania potoku można uporządkować w etapach. Etapy to główne podziały w potoku: kompilowanie tej aplikacji, uruchamianie tych testów i wdrażanie w środowisku przedprodukcyjnym to dobre przykłady etapów. Są to granice logiczne w potoku, w których można wstrzymać potok i wykonać różne kontrole.
Każda pipelina ma co najmniej jeden etap, nawet jeśli nie zdefiniujesz go w sposób jawny. Etapy można również rozmieścić w grafie zależności, tak aby jeden etap był uruchamiany przed innym. Etap może mieć maksymalnie 256 zadań.
Określanie etapów
W najprostszym przypadku nie potrzebujesz logicznych podziałów w swoim przepływie. W tych scenariuszach można bezpośrednio określić zadania w pliku YAML bez słowa kluczowego stages . Jeśli na przykład masz prosty potok, który kompiluje i testuje małą aplikację bez konieczności oddzielnych środowisk lub kroków wdrażania, możesz zdefiniować wszystkie zadania bezpośrednio bez użycia etapów.
pool:
vmImage: 'ubuntu-latest'
jobs:
- job: BuildAndTest
steps:
- script: echo "Building the application"
- script: echo "Running tests"
Ten proces ma jeden ukryty etap i dwie prace. Słowo stages kluczowe nie jest używane, ponieważ istnieje tylko jeden etap.
jobs:
- job: Build
steps:
- bash: echo "Building"
- job: Test
steps:
- bash: echo "Testing"
Aby zorganizować potok na wielu etapach, użyj słowa kluczowego stages . Ten kod YAML definiuje potok z dwoma etapami, w których każdy etap zawiera wiele zadań, a każde zadanie ma określone kroki do wykonania.
stages:
- stage: A
displayName: "Stage A - Build and Test"
jobs:
- job: A1
displayName: "Job A1 - build"
steps:
- script: echo "Building the application in Job A1"
displayName: "Build step"
- job: A2
displayName: "Job A2 - Test"
steps:
- script: echo "Running tests in Job A2"
displayName: "Test step"
- stage: B
displayName: "Stage B - Deploy"
jobs:
- job: B1
displayName: "Job B1 - Deploy to Staging"
steps:
- script: echo "Deploying to staging in Job B1"
displayName: "Staging deployment step"
- job: B2
displayName: "Job B2 - Deploy to Production"
steps:
- script: echo "Deploying to production in Job B2"
displayName: "Production deployment step"
Jeśli określisz pool na poziomie etapu, wszystkie zadania w tym etapie używają tej puli, o ile pula nie jest określona na poziomie zadania.
stages:
- stage: A
pool: StageAPool
jobs:
- job: A1 # will run on "StageAPool" pool based on the pool defined on the stage
- job: A2 # will run on "JobPool" pool
pool: JobPool
Określanie zależności
Podczas definiowania wielu etapów w potoku są one domyślnie uruchamiane sekwencyjnie w kolejności zdefiniowanej w pliku YAML. Wyjątkiem jest dodanie zależności. W przypadku zależności etapy są uruchamiane w kolejności dependsOn wymagań.
Przepływy muszą zawierać co najmniej jeden etap bez zależności.
Aby uzyskać więcej informacji na temat definiowania etapów, zobacz etapy w schemacie YAML.
Następujące przykładowe etapy są uruchamiane sekwencyjnie. Jeśli nie używasz słowa kluczowego dependsOn , etapy są uruchamiane w kolejności ich definiowania.
stages:
- stage: Build
displayName: "Build Stage"
jobs:
- job: BuildJob
steps:
- script: echo "Building the application"
displayName: "Build Step"
- stage: Test
displayName: "Test Stage"
jobs:
- job: TestJob
steps:
- script: echo "Running tests"
displayName: "Test Step"
Przykładowe etapy, które są uruchamiane równolegle:
stages:
- stage: FunctionalTest
displayName: "Functional Test Stage"
jobs:
- job: FunctionalTestJob
steps:
- script: echo "Running functional tests"
displayName: "Run Functional Tests"
- stage: AcceptanceTest
displayName: "Acceptance Test Stage"
dependsOn: [] # Runs in parallel with FunctionalTest
jobs:
- job: AcceptanceTestJob
steps:
- script: echo "Running acceptance tests"
displayName: "Run Acceptance Tests"
Przykład zachowania "fan-out" i "fan-in":
stages:
- stage: Test
- stage: DeployUS1
dependsOn: Test # stage runs after Test
- stage: DeployUS2
dependsOn: Test # stage runs in parallel with DeployUS1, after Test
- stage: DeployEurope
dependsOn: # stage runs after DeployUS1 and DeployUS2
- DeployUS1
- DeployUS2
Definiowanie warunków
Możesz określić warunki, w których każdy etap jest uruchamiany z wyrażeniami. Domyślnie etap jest uruchamiany, jeśli nie zależy od innego etapu lub jeśli wszystkie etapy, od których zależy, zostały ukończone i zakończyły się pomyślnie. To zachowanie można dostosować, wymuszając uruchomienie etapu, nawet jeśli poprzedni etap zakończy się niepowodzeniem lub przez określenie warunku niestandardowego.
Jeśli dostosujesz domyślny warunek poprzednich kroków dla etapu, usuniesz warunki ukończenia i powodzenia. Dlatego jeśli używasz warunku niestandardowego, często używa się and(succeeded(),custom_condition), aby sprawdzić, czy poprzedni etap został uruchomiony pomyślnie. W przeciwnym razie etap jest uruchamiany niezależnie od wyniku poprzedniego etapu.
Uwaga
Warunki dotyczące niepowodzenia ('JOBNAME/STAGENAME') i powodzenia ('JOBNAME/STAGENAME'), przedstawione w poniższym przykładzie, działają tylko dla potoków YAML.
Przykład uruchamiania etapu na podstawie stanu uruchamiania poprzedniego etapu:
stages:
- stage: A
# stage B runs if A fails
- stage: B
condition: failed()
# stage C runs if B succeeds
- stage: C
dependsOn:
- A
- B
condition: succeeded('B')
Przykład użycia warunku niestandardowego:
stages:
- stage: A
- stage: B
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
Określanie zasad kolejkowania
Potoki YAML nie obsługują zasad kolejkowania. Każde uruchomienie potoku jest niezależne od innych przebiegów. Innymi słowy, dwie kolejne operacje commit mogą wyzwalać dwa procesy, a oba z nich wykonają tę samą sekwencję etapów bez oczekiwania na siebie nawzajem. Mimo że pracujemy nad wprowadzeniem zasad kolejkowania do potoków YAML, zalecamy użycie zatwierdzeń ręcznych w celu ręcznego sekwencjonowania i kontrolowania kolejności wykonywania, jeśli ma to znaczenie.
Określanie zatwierdzeń
Możesz ręcznie kontrolować, kiedy etap powinien być uruchamiany przy użyciu kontroli zatwierdzania. Jest to często używane do kontrolowania wdrożeń w środowiskach produkcyjnych. Kontrole są mechanizmem dostępnym dla właściciela zasobu w celu kontrolowania, czy i kiedy etap w potoku może zużywać zasób. Jako właściciel zasobu, takiego jak środowisko, można zdefiniować kontrole, które muszą być spełnione przed rozpoczęciem etapu zużywania tego zasobu.
Obecnie ręczne kontrole zatwierdzania są obsługiwane w środowiskach. Aby uzyskać więcej informacji, zobacz Zatwierdzenia.
Dodawanie wyzwalacza ręcznego
Ręcznie wyzwalane etapy w pipeline YAML umożliwiają posiadanie zintegrowanego pipeline bez konieczności jego pełnego uruchamiania.
Na przykład pipeline może obejmować etapy tworzenia, testowania, wdrażania w środowisku testowym i wdrażania w środowisku produkcyjnym. Możesz chcieć, aby wszystkie etapy działały automatycznie z wyjątkiem wdrożenia produkcyjnego, które wolisz wyzwalać ręcznie, gdy wszystko będzie gotowe.
Aby użyć tej funkcji, dodaj właściwość trigger: manual do sceny.
W poniższym przykładzie etap programowania jest uruchamiany automatycznie, a etap produkcyjny wymaga ręcznego wyzwalania. Oba etapy uruchamiają skrypt wyjściowy hello world.
stages:
- stage: Development
displayName: Deploy to development
jobs:
- job: DeployJob
steps:
- script: echo 'hello, world'
displayName: 'Run script'
- stage: Production
displayName: Deploy to production
trigger: manual
jobs:
- job: DeployJob
steps:
- script: echo 'hello, world'
displayName: 'Run script'
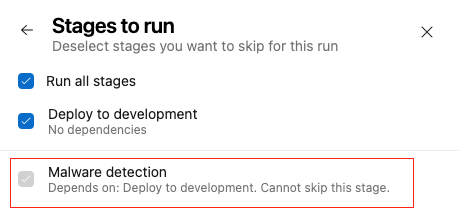
Oznaczanie etapu jako niepomijalnego
Oznacz etap jako isSkippable: false, aby uniemożliwić użytkownikom potoku pomijanie etapów. Na przykład może istnieć szablon YAML, który wprowadza etap, który wykonuje wykrywanie złośliwego oprogramowania we wszystkich potokach. Jeśli ustawisz isSkippable: false dla tego etapu, potok danych nie będzie mógł pominąć wykrywania złośliwego oprogramowania.
W poniższym przykładzie etap wykrywania złośliwego oprogramowania jest oznaczony jako niepomijalny, co oznacza, że musi zostać wykonany podczas uruchamiania potoku.
- stage: malware_detection
displayName: Malware detection
isSkippable: false
jobs:
- job: check_job
...
Gdy etap jest nieskoczalny, wyświetla się pole wyboru, które jest wyłączone w panelu konfiguracji Etapy do uruchomienia.