Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Historia danych to funkcja integracji usługi Azure Digital Twins. Umożliwia ona łączenie wystąpienia usługi Azure Digital Twins z klastrem usługi Azure Data Explorer , dzięki czemu aktualizacje grafu są automatycznie historizowane z usługą Azure Data Explorer. Te zarchiwizowane aktualizacje obejmują aktualizacje właściwości cyfrowego bliźniaka, zdarzenia cyklu życia cyfrowego bliźniaka oraz zdarzenia cyklu życia relacji.
Po zaktualizowaniu wykresu w usłudze Azure Data Explorer można uruchamiać wspólne zapytania przy użyciu wtyczki Azure Digital Twins dla usługi Azure Data Explorer , aby prowadzić analizy między reprezentacjami bliźniaczymi, ich relacjami i danymi szeregów czasowych. Może to służyć do spojrzenia wstecz na wcześniejszy stan grafu lub uzyskania wglądu w sposób działania modelowanych środowisk. Za pomocą tych zapytań można również wspomagać operacyjne pulpity nawigacyjne, wzbogacać aplikacje internetowe 2D i 3D oraz pobudzać doświadczenia immersyjne w rzeczywistości rozszerzonej/mieszanej, aby przekazać bieżący i historyczny stan zasobów, procesów i osób modelowanych w usłudze Azure Digital Twins.
Aby bardziej zapoznać się z wprowadzeniem do historii danych, w tym krótkiej demonstracji, obejrzyj następujący film IoT:
Komunikaty emitowane przez historię danych są mierzone w wymiarze cen komunikatów.
Wymagania wstępne: zasoby i uprawnienia
Historia danych wymaga następujących zasobów:
- Wystąpienie usługi Azure Digital Twins z włączoną tożsamością zarządzaną przypisaną przez system .
- Przestrzeń nazw Event Hubs, która zawiera centrum zdarzeń.
- Klaster usługi Azure Data Explorer zawierający bazę danych. Klaster musi mieć włączony dostęp do sieci publicznej.
Te zasoby są połączone z następującym przepływem:
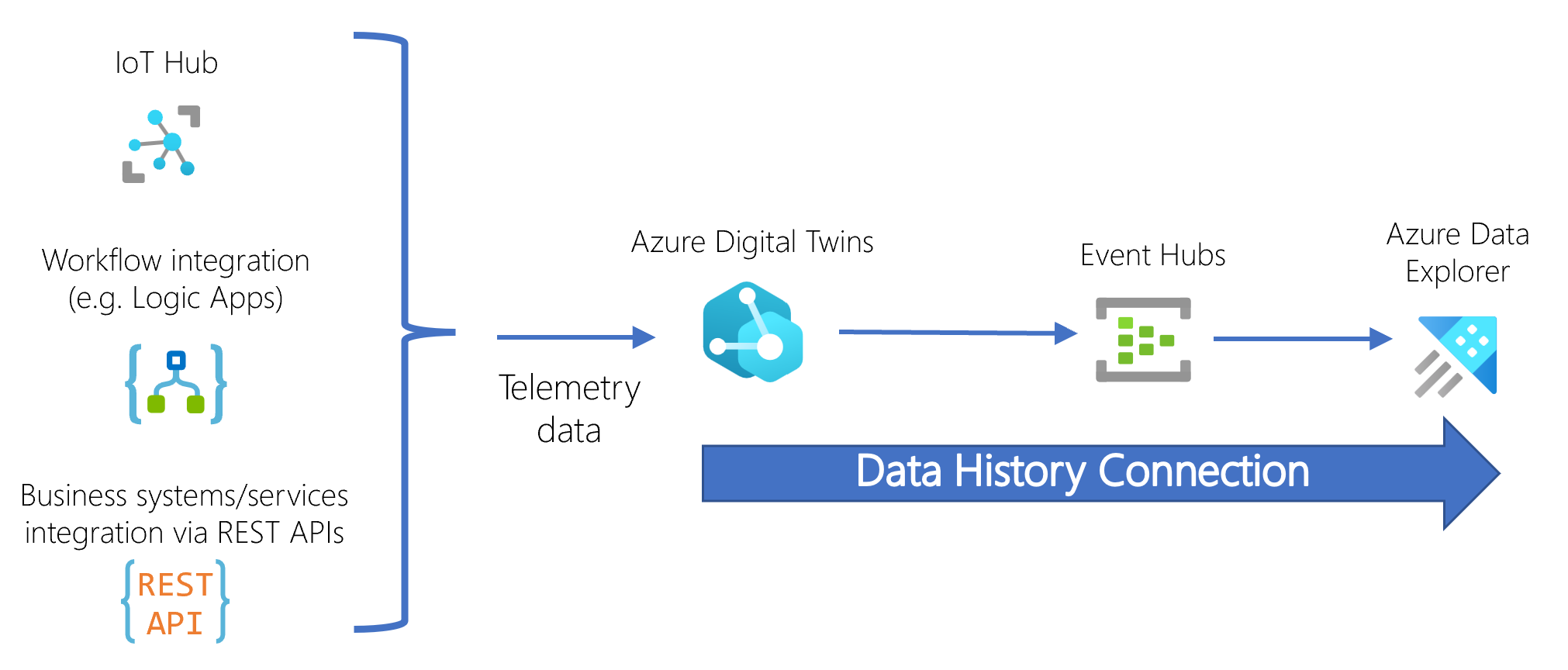
Po zaktualizowaniu grafu cyfrowego bliźniaka informacje są przekazywane przez centrum zdarzeń do docelowego klastra usługi Azure Data Explorer, w którym usługa Azure Data Explorer przechowuje dane jako rekord z sygnaturą czasową w odpowiedniej tabeli.
Podczas pracy z historią danych zaleca się użycie wersji 2023-01-31 lub nowszej interfejsów API. W wersji 2022-05-31 można historizować tylko właściwości bliźniacze (nie cykl życia bliźniaczych ani zdarzenia cyklu życia relacji). W przypadku wcześniejszych wersji historia danych nie jest dostępna.
Wymagane uprawnienia
Aby skonfigurować połączenie historii danych, wystąpienie usługi Azure Digital Twins musi mieć następujące uprawnienia, aby uzyskać dostęp do zasobów usługi Event Hubs i usługi Azure Data Explorer. Te role umożliwiają usłudze Azure Digital Twins konfigurowanie centrum zdarzeń i bazy danych usługi Azure Data Explorer w Twoim imieniu (na przykład tworzenie tabeli w bazie danych). Te uprawnienia można opcjonalnie usunąć po skonfigurowaniu historii danych.
- Zasób usługi Event Hubs: Właściciel danych usługi Azure Event Hubs
- Klaster usługi Azure Data Explorer: współautor (w zakresie całego klastra lub konkretnej bazy danych)
- Przypisanie jednostki bazy danych usługi Azure Data Explorer: administrator (w zakresie używanej bazy danych)
Później wystąpienie usługi Azure Digital Twins musi mieć następujące uprawnienie do zasobu usługi Event Hubs, gdy historia danych jest używana: Nadawca danych usługi Azure Event Hubs (możesz również zdecydować się na zachowanie Właściciela Danych usługi Azure Event Hubs z ustawień konfiguracji historii danych).
Te uprawnienia można przypisać przy użyciu interfejsu wiersza polecenia platformy Azure lub witryny Azure Portal.
Jeśli chcesz ograniczyć dostęp sieciowy do zasobów zaangażowanych w historię danych (wystąpienie usługi Azure Digital Twins, centrum zdarzeń lub klaster usługi Azure Data Explorer), należy ustawić te ograniczenia po skonfigurowaniu połączenia historii danych. Aby uzyskać więcej informacji na temat tego procesu, zobacz Ograniczanie dostępu sieciowego do zasobów historii danych.
Twórz i zarządzaj połączeniem historii danych
Ta sekcja zawiera informacje dotyczące tworzenia, aktualizowania i usuwania połączenia historii danych.
Utwórz połączenie historii danych
Po skonfigurowaniu wszystkich zasobów i uprawnień można użyć interfejsu wiersza polecenia platformy Azure, witryny Azure Portal lub zestawu SDK usługi Azure Digital Twins , aby utworzyć połączenie historii danych między nimi. Zestaw poleceń CLI to az dt data-history.
Polecenie zawsze tworzy tabelę dla zdarzeń dotyczących właściwości historii bliźniaczych, które mogą używać nazwy domyślnej lub nazwy niestandardowej, którą podasz. Usunięcia właściwości bliźniaczych można opcjonalnie uwzględnić w tej tabeli. Można również podać nazwy tabel dla zdarzeń cyklu życia relacji oraz zdarzeń cyklu życia cyfrowych bliźniaków, a polecenie utworzy tabele o tych nazwach, aby rejestrować te typy zdarzeń.
Aby uzyskać instrukcje krok po kroku dotyczące konfigurowania połączenia historii danych, zobacz Tworzenie połączenia historii danych.
Historia z wielu wystąpień usługi Azure Digital Twins
Jeśli chcesz, możesz mieć wiele instancji usługi Azure Digital Twins zapisujących historię aktualizacji do tego samego klastra usługi Azure Data Explorer.
Każde wystąpienie usługi Azure Digital Twins będzie miało własne połączenie historii danych przeznaczone dla tego samego klastra usługi Azure Data Explorer. W klastrze wystąpienia mogą wysyłać dane bliźniaczej reprezentacji do jednego z tych elementów...
- oddzielny zestaw tabel w klastrze usługi Azure Data Explorer.
-
ten sam zestaw tabel w klastrze usługi Azure Data Explorer. W tym celu określ te same nazwy tabel usługi Azure Data Explorer podczas tworzenia połączeń historii danych. W schematach tabeli historii danych kolumna
ServiceIdw każdej tabeli będzie zawierać adres URL źródłowego wystąpienia usługi Azure Digital Twins, dzięki czemu można użyć tego pola, aby rozpoznać, które wystąpienie usługi Azure Digital Twins emituje każdy rekord w tabelach udostępnionych.
Aktualizacja połączenia historii danych dotyczącej wyłącznie właściwości
Przed lutym 2023 r. funkcja historii danych historiowała tylko aktualizacje właściwości bliźniaczych. Jeśli masz połączenie historii danych dotyczących tylko właściwości z tamtego okresu, możesz je zaktualizować, aby zapisywać do historii wszystkie aktualizacje grafu w usłudze Azure Data Explorer (w tym właściwości bliźniaczych reprezentacji, zdarzenia cyklu życia bliźniaczej reprezentacji oraz zdarzenia cyklu życia relacji).
Będzie to wymagało utworzenia nowych tabel w klastrze usługi Azure Data Explorer dla nowych typów zaktualizowanych danych historycznych (zdarzeń cyklu życia bliźniaczych i zdarzeń cyklu życia relacji). W przypadku zdarzeń dotyczących właściwości bliźniaczych możesz zdecydować, czy nowe połączenie ma nadal korzystać z tej samej tabeli z oryginalnego połączenia historii danych do przechowywania aktualizacji właściwości bliźniaczych w przyszłości, czy też chcesz, aby nowe połączenie używało zupełnie nowego zestawu tabel. Następnie postępuj zgodnie z poniższymi instrukcjami, zgodnie ze swoimi preferencjami.
Jeśli chcesz kontynuować korzystanie z istniejącej tabeli do aktualizacji właściwości bliźniaczych: Skorzystaj z instrukcji w sekcji Tworzenie połączenia historii danych, aby utworzyć nowe połączenie historii danych z nowymi funkcjami. Nazwa połączenia historii danych może być taka sama jak oryginalna lub może mieć inną nazwę. Użyj opcji parametrów, aby podać nowe nazwy dla dwóch nowych tabel typów zdarzeń i przekazać oryginalną nazwę tabeli dla tabeli aktualizacji właściwości bliźniaczej reprezentacji. Nowe połączenie zastąpi stare i będzie nadal używać oryginalnej tabeli do przyszłych aktualizacji właściwości bliźniaczej.
Jeśli chcesz użyć wszystkich nowych tabel: Najpierw usuń oryginalne połączenie historii danych. Następnie użyj instrukcji w artykule Tworzenie połączenia historii danych , aby utworzyć nowe połączenie historii danych z nowymi możliwościami. Nazwa połączenia historii danych może być taka sama jak oryginalna lub może mieć inną nazwę. Użyj opcji parametrów, aby podać nowe nazwy dla wszystkich trzech tabel typów zdarzeń.
Usuń połączenie historii danych
Aby usunąć połączenie historii danych, możesz użyć Azure CLI, portal Azure lub API i SDK Azure Digital Twins. Polecenie interfejsu wiersza polecenia to az dt data-history connection delete.
Usunięcie połączenia umożliwia również wyczyszczenie zasobów skojarzonych z połączeniem historii danych (w przypadku polecenia CLI opcjonalny parametr do dodania to --clean true). Jeśli używasz tej opcji, polecenie usunie zasoby w usłudze Azure Data Explorer, które są używane do łączenia klastra z centrum zdarzeń, w tym połączeń danych dla bazy danych i mapowań pozyskiwania skojarzonych z tabelą. Opcja "Czyszczenie zasobów" nie spowoduje usunięcia rzeczywistego centrum zdarzeń i klastra usługi Azure Data Explorer używanego na potrzeby połączenia historii danych.
Oczyszczanie jest próbą najlepszych wysiłków i wymaga, aby konto, które uruchamia polecenie, miało uprawnienia do usuwania tych zasobów.
Uwaga
Jeśli masz wiele połączeń historii danych współdzielących to samo centrum zdarzeń lub klaster Azure Data Explorer, użycie opcji "usuń zasoby" podczas usuwania jednego z tych połączeń może zakłócić działanie innych połączeń historii danych, które polegają na tych zasobach.
Typy danych i schematy
Historia danych rejestruje historię trzech typów zdarzeń z wystąpienia usługi Azure Digital Twins do usługi Azure Data Explorer: zdarzenia cyklu życia relacji, zdarzenia cyklu życia bliźniaków i aktualizacje właściwości bliźniaków (które opcjonalnie mogą obejmować usuwanie właściwości bliźniaków). Każdy z tych typów zdarzeń jest przechowywany we własnej tabeli w bazie danych usługi Azure Data Explorer, co oznacza, że historia danych przechowuje trzy tabele łącznie. Nazwy niestandardowe tabel można określić podczas konfigurowania połączenia historii danych.
W pozostałej części tej sekcji opisano szczegółowo trzy tabele usługi Azure Data Explorer, w tym schemat danych dla każdej tabeli.
Aktualizacje właściwości bliźniaczych
Tabela Azure Data Explorer dla aktualizacji właściwości bliźniaczej ma domyślną nazwę AdtPropertyEvents. Możesz pozostawić domyślną nazwę podczas tworzenia połączenia lub określić niestandardową nazwę tabeli.
Dane szeregów czasowych dotyczące aktualizacji właściwości bliźniaczych są przechowywane w następującym schemacie:
| [No changes needed]) | Typ | Opis |
|---|---|---|
TimeStamp |
Data i Czas | Data/godzina przetworzenia komunikatu aktualizacji właściwości przez usługę Azure Digital Twins. To pole jest ustawiane przez system i nie jest zapisywalne przez użytkowników. |
SourceTimeStamp |
Data i Czas | Opcjonalna, zapisywalna właściwość reprezentująca sygnaturę czasową obserwowanej aktualizacji właściwości w świecie rzeczywistym. Tę właściwość można zdefiniować tylko w wersji Azure Digital Twins APIs/SDKs z 31 maja 2022 r., a wartość musi być zgodna z formatem daty i godziny ISO 8601. Aby uzyskać więcej informacji na temat aktualizowania tej właściwości, zobacz Aktualizowanie właściwości sourceTime. |
ServiceId |
Sznurek | Identyfikator wystąpienia usługi Azure IoT, która rejestruje rekord |
Id |
Sznurek | Identyfikator bliźniaczy |
ModelId |
Sznurek | Identyfikator modelu DTDL (DTMI) |
Key |
Sznurek | Nazwa zaktualizowanej właściwości |
Value |
Dynamiczny | Wartość zaktualizowanej właściwości |
RelationshipId |
Sznurek | Gdy właściwość zdefiniowana w relacji (w przeciwieństwie do bliźniaczych obiektów lub urządzeń) jest aktualizowana, to pole jest wypełniane identyfikatorem relacji. Po zaktualizowaniu właściwości bliźniaczej pole jest puste. |
RelationshipTarget |
Sznurek | Gdy właściwość zdefiniowana na relacji (w przeciwieństwie do bliźniaczek lub urządzeń) jest aktualizowana, to pole jest wypełniane identyfikatorem bliźniaka, który jest celem relacji. Po zaktualizowaniu właściwości bliźniaczej pole jest puste. |
Action |
Sznurek | Ta kolumna istnieje tylko wtedy, gdy zdecydujesz się historizować zdarzenia usuwania właściwości. Jeśli tak, ta kolumna zawiera typ zdarzenia właściwości bliźniaczej (aktualizacja lub usuwanie) |
Poniżej znajduje się przykładowa tabela aktualizacji właściwości bliźniaczych przechowywanych w usłudze Azure Data Explorer.
TimeStamp |
SourceTimeStamp |
ServiceId |
Id |
ModelId |
Key |
Value |
RelationshipTarget |
RelationshipID |
|---|---|---|---|---|---|---|---|---|
| 2022-12-15 20:23:29.8697482 | 2022-12-15 20:22:14.3854859 | dairyadtinstance.api.wcus.digitaltwins.azure.net | MaszynaDoPasteryzacji_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Dane wyjściowe | 130 | ||
| 2022-12-15 20:23:39.3235925 | 2022-12-15 20:22:26.5837559 | dairyadtinstance.api.wcus.digitaltwins.azure.net | MaszynaDoPasteryzacji_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Dane wyjściowe | 140 | ||
| 2022-12-15 20:23:47.078367 | 2022-12-15 20:22:34.9375957 | dairyadtinstance.api.wcus.digitaltwins.azure.net | MaszynaDoPasteryzacji_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Dane wyjściowe | 130 | ||
| 2022-12-15 20:23:57.3794198 | 2022-12-15 20:22:50.1028562 | dairyadtinstance.api.wcus.digitaltwins.azure.net | MaszynaDoPasteryzacji_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Dane wyjściowe | 123 |
Reprezentowanie właściwości z wieloma polami
Może być konieczne przechowywanie właściwości z wieloma polami. Te właściwości są reprezentowane za pomocą obiektu JSON w atrybucie Value schematu.
Jeśli na przykład reprezentujesz właściwość z trzema polami: rzutu, skoku i odchylenia, historia danych będzie przechowywać następujący obiekt JSON jako Value: {"roll": 20, "pitch": 15, "yaw": 45}.
Zdarzenia cyklu życia bliźniaków
Tabela usługi Azure Data Explorer dla zdarzeń cyklu życia bliźniaków ma niestandardową nazwę, którą określisz podczas tworzenia połączenia historii danych.
Dane szeregów czasowych dotyczące zdarzeń cyklu życia bliźniąt są przechowywane zgodnie z następującym schematem:
| [No changes needed]) | Typ | Opis |
|---|---|---|
TwinId |
Sznurek | Identyfikator bliźniaczy |
Action |
Sznurek | Typ zdarzenia w cyklu życia bliźniaczej reprezentacji (utworzenie lub usunięcie) |
TimeStamp |
Data i Czas | Data/godzina przetworzenia zdarzenia dotyczącego cyklu życia bliźniaczej reprezentacji przez usługę Azure Digital Twins. To pole jest ustawiane przez system i nie jest zapisywalne przez użytkowników. |
ServiceId |
Sznurek | Identyfikator wystąpienia usługi Azure IoT, która rejestruje rekord |
ModelId |
Sznurek | Identyfikator modelu DTDL (DTMI) |
Poniżej znajduje się przykładowa tabela aktualizacji cyklu życia bliźniaków przechowywanych w usłudze Azure Data Explorer.
TwinId |
Action |
TimeStamp |
ServiceId |
ModelId |
|---|---|---|---|---|
| MaszynaDoPasteryzacji_A01 | Utwórz | 2022-12-15 07:14:12.4160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| Maszyna do pasteryzacji PasteurizationMachine_A02 | Utwórz | 2022-12-15 07:14:12.4210 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| SaltMachine_C0 | Utwórz | 2022-12-15 07:14:12.5480 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:SaltMachine;1 |
| Maszyna do pasteryzacji PasteurizationMachine_A02 | Usuń | 2022-12-15 07:15:49.6050 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
Zdarzenia cyklu życia relacji
Tabela usługi Azure Data Explorer dla zdarzeń cyklu życia relacji ma niestandardową nazwę, którą określisz podczas tworzenia połączenia historii danych.
Dane szeregów czasowych dla zdarzeń cyklu życia relacji są przechowywane przy użyciu następującego schematu:
| [No changes needed]) | Typ | Opis |
|---|---|---|
RelationshipId |
Sznurek | Identyfikator relacji. To pole jest ustawiane przez system i nie jest zapisywalne przez użytkowników. |
Name |
Sznurek | Nazwa relacji |
Action |
Typ zdarzenia cyklu życia relacji (tworzenie lub usuwanie) | |
TimeStamp |
Data i Czas | Data/godzina przetworzenia zdarzenia cyklu życia relacji przez usługę Azure Digital Twins. To pole jest ustawiane przez system i nie jest zapisywalne przez użytkowników. |
ServiceId |
Identyfikator wystąpienia usługi Azure IoT, która rejestruje rekord | |
Source |
Identyfikator źródłowej instancji bliźniaczej. Jest to identyfikator bliźniaka, z którego pochodzi relacja. | |
Target |
Identyfikator docelowego bliźniaka. Jest to identyfikator bliźniaka, do którego dociera relacja. |
Poniżej znajduje się przykładowa tabela aktualizacji cyklu życia relacji przechowywanych w usłudze Azure Data Explorer.
RelationshipId |
Name |
Action |
TimeStamp |
ServiceId |
Source |
Target |
|---|---|---|---|---|---|---|
| MaszynaDoPasteryzacji_A01_feeds_Relationship0 | Kanały | Utwórz | 2022-12-15 07:16:12.7120 | dairyadtinstance.api.wcus.digitaltwins.azure.net | MaszynaDoPasteryzacji_A01 | SaltMachine_C0 |
| PasteurizationMachine_A02_relacje_dożywiania0 | Kanały | Utwórz | 2022-12-15 07:16:12.7160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | Maszyna do pasteryzacji PasteurizationMachine_A02 | SaltMachine_C0 |
| PasteurizationMachine_A03_feeds_Relationship0 | Kanały | Utwórz | 2022-12-15 07:16:12.7250 | dairyadtinstance.api.wcus.digitaltwins.azure.net | Maszyna Pasteryzacyjna_A03 | SaltMachine_C1 |
| OsloFactory_zawiera_Relationship0 | zawiera | Usuń | 2022-12-15 07:16:13.1780 | dairyadtinstance.api.wcus.digitaltwins.azure.net | OsloFactory | SaltMachine_C0 |
Całkowite opóźnienie przetwarzania danych od początku do końca
Historia danych usługi Azure Digital Twins opiera się na istniejącym mechanizmie pozyskiwania udostępnianym przez usługę Azure Data Explorer. Usługa Azure Digital Twins zapewni, że zdarzenia aktualizacji grafu zostaną udostępnione usłudze Azure Data Explorer w ciągu niecałych dwóch sekund. Dodatkowe opóźnienie może być spowodowane przez usługę Azure Data Explorer podczas pozyskiwania danych.
W usłudze Azure Data Explorer istnieją dwie metody pozyskiwania danych: pozyskiwanie danych wsadowych i pozyskiwanie danych przesyłanych strumieniowo. Te metody pozyskiwania można skonfigurować dla poszczególnych tabel zgodnie z potrzebami i konkretnym scenariuszem pozyskiwania danych.
Przesyłanie strumieniowe charakteryzuje się najmniejszym opóźnieniem. Jednak ze względu na obciążenie związane z przetwarzaniem ten tryb powinien być używany tylko wtedy, gdy mniej niż 4 GB danych jest pozyskiwanych co godzinę. Pozyskiwanie wsadowe działa najlepiej, jeśli oczekiwane są wysokie szybkości pozyskiwania danych. Usługa Azure Data Explorer domyślnie używa wsadowego pozyskiwania. Poniższa tabela zawiera podsumowanie oczekiwanego opóźnienia w najgorszym przypadku end-to-end.
| Konfiguracja usługi Azure Data Explorer | Oczekiwane opóźnienie od końca | Zalecana szybkość danych |
|---|---|---|
| Strumieniowe pobieranie danych | <12 s (<typowe 3 s) | <4 GB/godz. |
| Pozyskiwanie wsadowe | Różni się (12 s-15 m, w zależności od konfiguracji) | >4 GB/godz. |
Pozostała część tej sekcji zawiera szczegółowe informacje dotyczące włączania każdego typu wprowadzenia.
Przetwarzanie wsadowe (ustawienie domyślne)
Jeśli nie skonfigurowano inaczej, usługa Azure Data Explorer będzie używać ładowania wsadowego. Ustawienia domyślne mogą skutkować tym, że dane będą dostępne w zapytaniach dopiero 5–10 minut po aktualizacji cyfrowego bliźniaka. Zasady pozyskiwania można zmienić tak, aby przetwarzanie wsadowe odbywało się co najmniej co 10 sekund lub maksymalnie co 15 minut. Aby zmienić zasady pozyskiwania, w widoku zapytania usługi Azure Data Explorer należy wydać następujące polecenie:
.alter table <table_name> policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
Upewnij się, że <table_name> został zastąpiony nazwą tabeli, która została skonfigurowana dla Ciebie. Parametr MaximumBatchingTimeSpan powinien być ustawiony na preferowany interwał dzielenia na partie. Zastosowanie zasad może potrwać od 5 do 10 minut. Więcej informacji na temat dzielenia na partie pozyskiwania można uzyskać za pomocą następującego linku: Kusto IngestionBatching policy management command (Polecenie zarządzania zasadami Kusto IngestionBatching).
Strumieniowe pobieranie danych
Aktywacja strumieniowego przesyłania to proces dwukrokowy:
- Włącz strumieniowe przetwarzanie danych dla klastra. Tę akcję należy wykonać tylko raz. (Ostrzeżenie: Takie działanie będzie miało wpływ na ilość miejsca dostępnego dla gorącej pamięci podręcznej i może wprowadzić dodatkowe ograniczenia). Aby uzyskać wskazówki, zobacz Konfigurowanie strumieniowego pozyskiwania danych w klastrze usługi Azure Data Explorer.
- Dodaj zasadę pozyskiwania danych strumieniowych dla żądanej tabeli. Więcej informacji na temat włączania pozyskiwania danych z przesyłania strumieniowego dla klastra znajdziesz w dokumentacji Azure Data Explorer: Polecenie zarządzania zasadami Kusto IngestionBatching.
Aby włączyć ingestowanie strumieniowe dla tabeli historii danych usługi Azure Digital Twins, w panelu zapytań Azure Data Explorer należy wydać następujące polecenie:
.alter table <table_name> policy streamingingestion enable
Upewnij się, że <table_name> został zastąpiony nazwą tabeli, która została skonfigurowana dla Ciebie. Zastosowanie zasad może potrwać od 5 do 10 minut.
Wizualizowanie zarchiwizowanych właściwości
Usługa Azure Digital Twins Explorer, narzędzie deweloperskie do wizualizowania danych usługi Azure Digital Twins i interakcji z nimi, oferuje funkcję Eksploratora historii danych do wyświetlania właściwości historizowanych w czasie na wykresie lub w tabeli. Ta funkcja jest również dostępna w programie 3D Scenes Studio, immersywnym środowisku 3D do udostępniania usłudze Azure Digital Twins kontekstu wizualnego zasobów 3D.

Aby uzyskać bardziej szczegółowe informacje na temat korzystania z eksploratora historii danych, zobacz Weryfikacja i eksploracja zhistoryzowanych właściwości.
Uwaga
Jeśli napotkasz problemy z wyborem właściwości w narzędziu eksploratora historii danych wizualnych, może to oznaczać, że w danym wystąpieniu występuje błąd. Na przykład, nieunikalne wartości wyliczeniowe w atrybutach modelu spowodują niedziałanie tej funkcji wizualizacji. Jeśli tak się stanie, przejrzyj definicje modelu i upewnij się, że wszystkie właściwości są prawidłowe.
Następne kroki
Gdy dane bliźniaczej zostaną zarchiwizowane w usłudze Azure Data Explorer, możesz użyć wtyczki zapytań usługi Azure Digital Twins dla usługi Azure Data Explorer, aby uruchamiać zapytania w danych. Przeczytaj więcej na temat wtyczki tutaj: Wykonywanie zapytań za pomocą wtyczki usługi Azure Data Explorer.
Możesz też dokładniej poznać historię danych za pomocą instrukcji tworzenia i przykładowego scenariusza: Tworzenie połączenia historii danych.