Znaczące zmiany wersji w usłudze HDInsight 4.0 i korzyści
Usługa HDInsight 4.0 ma kilka zalet w usłudze HDInsight 3.6. Oto omówienie nowości w usłudze Azure HDInsight 4.0.
| # | Składnik systemu operacyjnego | Wersja usługi HDInsight 4.0 | Wersja usługi HDInsight 3.6 |
|---|---|---|---|
| 1 | Apache Hadoop | 3.1.1 | 2.7.3 |
| 2 | Apache HBase | 2.1.6 | 1.1.2 |
| 3 | Apache Hive | 3.1.0 | 1.2.1, 2.1 (LLAP) |
| 4 | Apache Kafka | 2.1.1, 2.4(GA) | 1,1 |
| 5 | Apache Phoenix | 5 | 4.7.0 |
| 6 | Apache Spark | 2.4.4, 3.0.0 (wersja zapoznawcza) | 2,2 |
| 7 | Apache TEZ | 0.9.1 | 0.7.0 |
| 8 | Apache ZooKeeper | 3.4.6 | 3.4.6 |
| 9 | Apache Kafka | 2.1.1, 2.4.1 (wersja zapoznawcza) | 1,1 |
| 10 | Apache Ranger | 1.1.0 | 0.7.0 |
Obciążenia i funkcje
Hive
- Funkcje zaawansowane
- Zarządzanie obciążeniami LLAP
- Obsługa łączników JDBC, Druid i Kafka
- Lepsze funkcje SQL — ograniczenia i wartości domyślne
- Klucze zastępcze
- Schemat informacji.
- Zaleta wydajności
- Buforowanie wyników — Buforowanie wyniki zapytania umożliwiają ponowne użycie wcześniej obliczonego wyniku zapytania
- Dynamiczne zmaterializowane widoki — wstępne obliczanie podsumowań
- Ulepszenia wydajności ACID V2 zarówno w formacie magazynu, jak i w aparacie wykonywania
- Zabezpieczeń
- Zgodność z RODO włączona w transakcjach apache Hive
- Autoryzacja wykonywania funkcji UDF programu Hive w module ranger
HBase
- Funkcje zaawansowane
- Procedura 2. Procedura V2 lub procv2 to zaktualizowana struktura do wykonywania wieloetapowych operacji administracyjnych bazy danych HBase.
- W pełni wyłączona ścieżka odczytu/zapisu sterty.
- Kompaktowanie w pamięci
- Klaster HBase obsługuje usługę ADLS Gen2 w warstwie Premium
- Zaleta wydajności
- Funkcja przyspieszonych zapisów korzysta z dysków zarządzanych SSD w warstwie Azure Premium w celu zwiększenia wydajności usługi Apache HBase Write Ahead Log (WAL).
- Zabezpieczeń
- Wzmocnienie zabezpieczeń obu indeksów pomocniczych, które obejmują lokalne i globalne
Kafka
- Funkcje zaawansowane
- Dystrybucja partycji platformy Kafka w domenach błędów platformy Azure
- Obsługa kompresji Zstd
- Ponowne równoważenie przyrostowe konsumentów platformy Kafka
- Obsługa mirrormaker 2.0
- Zaleta wydajności
- Ulepszona wydajność agregacji okien na platformie Kafka Strumienie
- Ulepszona odporność brokera dzięki zmniejszeniu zużycia pamięci podczas konwersji komunikatów
- Ulepszenia protokołu replikacji na potrzeby szybkiego przejścia w tryb failover lidera
- Zabezpieczeń
- Kontrola dostępu do tworzenia tematu dla określonych tematów/prefiksu tematu
- Weryfikacja nazwy hosta w celu zapobiegania atakom typu man-in-the-middle konfiguracji protokołu SSL
- Ulepszona obsługa szyfrowania dzięki szybszej implementacji protokołu Transport Layer Security (TLS) i CRC32C
Spark
- Funkcje zaawansowane
- Obsługa przesyłania strumieniowego ze strukturą dla orc
- Możliwość integracji z nową funkcją wykazu magazynu metadanych
- Obsługa przesyłania strumieniowego ze strukturą dla biblioteki przesyłania strumieniowego Hive
- Przezroczyste zapisywanie w magazynie Hive
- Spark Cruise — automatyczny system ponownego użycia obliczeń dla platformy Spark.
- Zaleta wydajności
- Buforowanie wyników — Buforowanie wyniki zapytania umożliwiają ponowne użycie wcześniej obliczonego wyniku zapytania
- Dynamiczne zmaterializowane widoki — wstępne obliczanie podsumowań
- Zabezpieczeń
- Zgodność z RODO włączona dla transakcji platformy Spark
Odnajdywanie i naprawianie partycji Hive
Hive automatycznie odnajduje i synchronizuje metadane partycji w magazynie metadanych Hive.
Właściwość discover.partitions tabeli włącza i wyłącza synchronizację systemu plików z partycjami. W tabelach podzielonych na partycje zewnętrzne ta właściwość jest domyślnie włączona (true).
Gdy usługa magazynu metadanych Hive (HMS) jest uruchamiana w trybie zdalnej usługi, wątek (PartitionManagementTask) w tle jest okresowo uruchamiany co 300 s (konfigurowalny za pośrednictwem metastore.partition.management.task.frequency config), który wyszukuje tabele z właściwością discover.partitions tabeli ustawioną na wartość true i wykonuje naprawę msck w trybie synchronizacji.
Jeśli tabela jest tabelą transakcyjną, funkcja Exclusive Lock jest uzyskiwana dla tej tabeli przed wykonaniem operacji msck repair. Ta właściwość MSCK REPAIR TABLE table_name SYNC PARTITIONS tabeli nie jest już wymagana do ręcznego uruchamiania.
Zakładając, że masz tabelę zewnętrzną utworzoną przy użyciu wersji programu Hive, która nie obsługuje odnajdywania partycji, włącz odnajdywanie partycji dla tabeli.
ALTER TABLE exttbl SET TBLPROPERTIES ('discover.partitions' = 'true');
Ustaw synchronizację partycji, które mają być wykonywane co 10 minut wyrażonych w sekundach: w konfiguracjach Programu Hive > ambari > na set metastore.partition.management.task.frequency 3600 lub więcej.
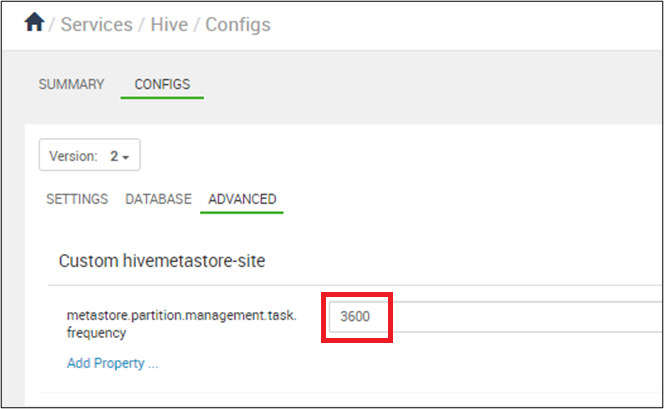
Ostrzeżenie
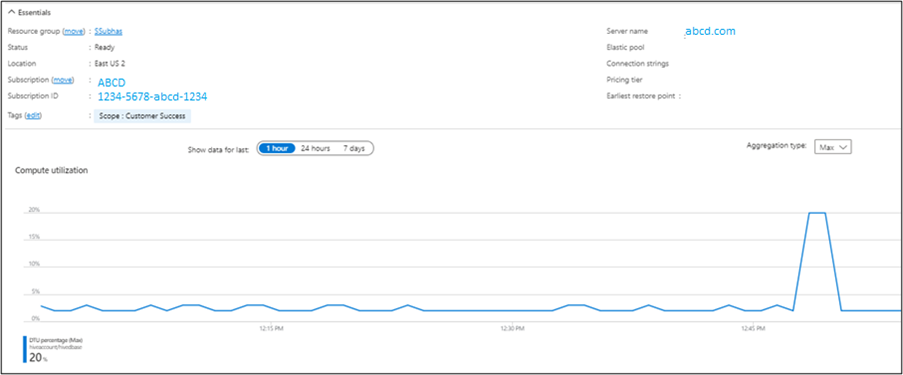
Po uruchomieniu management.task co 10 minut będzie występować presja na jednostki DTU serwera SQL.
Dane wyjściowe można sprawdzić w witrynie Microsoft Azure Portal.
Hive odrzuca metadane i odpowiadające im dane w dowolnej partycji utworzonej po okresie przechowywania. Czas przechowywania jest wyrażany przy użyciu cyfry i następującego znaku lub znaków. Hive odrzuca metadane i odpowiadające im dane w dowolnej partycji utworzonej po okresie przechowywania. Czas przechowywania jest wyrażany przy użyciu liczb i następujących znaków.
ms (milliseconds)
s (seconds)
m (minutes)
d (days)
Aby skonfigurować okres przechowywania partycji przez jeden tydzień.
ALTER TABLE employees SET TBLPROPERTIES ('partition.retention.period'='7d');
Metadane partycji i rzeczywiste dane dla pracowników w usłudze Hive są automatycznie usuwane po tygodniu.
Hive 3
Optymalizacje wydajności dostępne w programie Hive 3
OLAP Vectorization Dynamic Semijoin reduction Parquet support for vectorization with LLAP Automatic query cache (Dynamiczna wektoryzacja Wektoryzacji OLAP Dynamiczne semijoin reduction Parquet obsługa wektoryzacji przy użyciu automatycznej pamięci podręcznej zapytań LLAP).
Nowe funkcje SQL
Zmaterializowane widoki zastępcze klucze ograniczeń magazynu metadanych CachedStore.
Wektoryzacja OLAP
Wektoryzacja umożliwia programowi Hive przetwarzanie partii wierszy razem zamiast przetwarzania jednego wiersza naraz. Każda partia jest zwykle tablicą typów pierwotnych. Operacje są wykonywane w całym wektorze kolumn, co poprawia potoki instrukcji i użycie pamięci podręcznej. Wektorowe wykonywanie zestawów PTF, zestawień i grupowania.
Redukcja dynamiczna Semijoin
Znacznie poprawia wydajność sprzężeń selektywnych. Tworzy filtr blooma z jednej strony sprzężenia i filtruje wiersze z drugiej strony. Pomija skanowanie i dalszą ocenę wierszy, które nie kwalifikują sprzężenia.
Obsługa parquet na potrzeby wektoryzacji za pomocą protokołu LLAP
Wektoryzowane wykonywanie zapytań to funkcja, która znacznie zmniejsza użycie procesora CPU dla typowych operacji zapytań, takich jak
- Skanuje
- filtry
- aggregate
- Łączy
Wektoryzacja jest również implementowana dla formatu ORC. Platforma Spark używa również KtoTo le Stage Codegen i tej wektoryzacji (dla Parquet) od platformy Spark 2.0. Dodano kolumnę sygnatury czasowej dla wektoryzacji Parquet i formatu w obszarze LLAP.
Ostrzeżenie
Zapisy parquet są powolne, gdy konwersja na czas strefowy z sygnatury czasowej. Więcej informacji można znaleźć tutaj.
Automatyczna pamięć podręczna zapytań
- W przypadku
hive.query.results.cache.enabled=trueprogramu każde zapytanie uruchamiane w programie Hive 3 przechowuje jego wynik w pamięci podręcznej. - Jeśli tabela wejściowa ulegnie zmianie, program Hive eksmituje nieprawidłowe dane z pamięci podręcznej. Na przykład w przypadku przeprowadzania agregacji i zmiany tabeli podstawowej zapytania są uruchamiane najczęściej w pamięci podręcznej, ale nieaktualne zapytania są eksmitowane.
- Pamięć podręczna wyników zapytania działa tylko z zarządzanymi tabelami, ponieważ program Hive nie może śledzić zmian w tabeli zewnętrznej.
- Jeśli dołączasz tabele zewnętrzne i zarządzane, program Hive powraca do wykonywania pełnego zapytania. Pamięć podręczna wyników zapytania współpracuje z tabelami ACID. Jeśli zaktualizujesz tabelę ACID, program Hive automatycznie uruchomi zapytanie.
- Możesz włączyć i wyłączyć pamięć podręczną wyników zapytania z wiersza polecenia. Możesz to zrobić, aby debugować zapytanie.
- Wyłącz pamięć podręczną wyników zapytania, ustawiając następujący parametr na false:
hive.query.results.cache.enabled=false - Hive przechowuje pamięć podręczną wyników zapytania w pliku
/tmp/hive/__resultcache__/. Domyślnie program Hive przydziela 2 GB dla pamięci podręcznej wyników zapytania. To ustawienie można zmienić, konfigurując następujący parametr w bajtach:hive.query.results.cache.max.size - Zmiany przetwarzania zapytań: podczas kompilacji zapytań sprawdź pamięć podręczną wyników, aby sprawdzić, czy ma już wyniki zapytania. Jeśli występuje trafienie pamięci podręcznej, plan zapytania jest ustawiony na
FetchTaskwartość odczytaną z lokalizacji buforowanej.
Podczas wykonywania zapytania:
Parquet DataWriteableWriter polega na NanoTimeUtils przekonwertowaniu obiektu znacznika czasu na wartość binarną. To zapytanie wywołuje toString() obiekt znacznika czasu, a następnie analizuje ciąg.
- Jeśli pamięć podręczna wyników może być używana dla tego zapytania
- Zapytanie odczytuje
FetchTasksię z buforowanego katalogu wyników. - Nie są wymagane żadne zadania klastra.
- Zapytanie odczytuje
- Jeśli nie można użyć pamięci podręcznej wyników, uruchom zadania klastra w zwykły sposób
- Sprawdź, czy obliczone wyniki zapytania kwalifikują się do dodania do pamięci podręcznej wyników.
- Jeśli wyniki można buforować, tymczasowe wyniki wygenerowane dla zapytania są zapisywane w pamięci podręcznej wyników. W tym miejscu może być konieczne wykonanie kroków, aby upewnić się, że czyszczenie zapytania nie powoduje usunięcia katalogu wyników zapytania.
Funkcje języka SQL
Zmaterializowane widoki
Początkowa implementacja wprowadzona w programie Apache Hive 3.0.0 koncentruje się na wprowadzeniu zmaterializowanych widoków i automatycznego ponownego zapisywania zapytań na podstawie tych materializacji w projekcie. Zmaterializowane widoki mogą być przechowywane natywnie w programie Hive lub w innych niestandardowych programach obsługi magazynu (ORC) i mogą bezproblemowo wykorzystywać ekscytujące nowe funkcje hive, takie jak przyspieszanie LLAP.
Więcej informacji można znaleźć w temacie Hive — Materialized Views — Microsoft Tech Community
Klucze zastępcze
Użyj wbudowanej SURROGATE_KEY funkcji zdefiniowanej przez użytkownika (UDF), aby automatycznie generować identyfikatory liczbowe dla wierszy podczas wprowadzania danych do tabeli. Wygenerowane klucze zastępcze mogą zastąpić szerokie, wiele kluczy złożonych.
Program Hive obsługuje tylko klucze zastępcze w tabelach ACID. Tabela, którą chcesz połączyć przy użyciu kluczy zastępczych, nie może mieć typów kolumn, które wymagają rzutowania. Te typy danych muszą być typami pierwotnymi, takimi jak INT lub STRING.
Sprzężenia korzystające z wygenerowanych kluczy są szybsze niż sprzężenia przy użyciu ciągów. Użycie wygenerowanych kluczy nie wymusza wymuszenia danych w jednym węźle według numeru wiersza. Klucze można generować jako abstrakcje kluczy naturalnych. Klucze zastępcze mają przewagę nad identyfikatorami UUID, które są wolniejsze i probabilistyczne.
Element SURROGATE_KEY UDF generuje unikatowy identyfikator dla każdego wiersza wstawionego do tabeli.
Generuje klucze na podstawie środowiska wykonawczego w systemie rozproszonym, który obejmuje wiele czynników, takich jak
- Wewnętrzne struktury danych
- Stan tabeli
- Ostatni identyfikator transakcji.
Generowanie kluczy zastępczych nie wymaga żadnej koordynacji między zadaniami obliczeniowymi. Funkcja UDF nie przyjmuje żadnych argumentów lub dwa argumenty są
- Bity identyfikatora zapisu
- Bity identyfikatora zadania
Ograniczenia
Ograniczenia SQL wymuszają integralność danych i zwiększają wydajność. Optymalizator używa informacji ograniczeń do podejmowania inteligentnych decyzji. Ograniczenia mogą sprawić, że dane będą przewidywalne i łatwe do zlokalizowania.
| Ograniczenia | opis |
|---|---|
| Zaznacz | Ogranicza zakres wartości, które można umieścić w kolumnie. |
| KLUCZ PODSTAWOWY | Identyfikuje każdy wiersz w tabeli przy użyciu unikatowego identyfikatora. |
| KLUCZ OBCY | Identyfikuje wiersz w innej tabeli przy użyciu unikatowego identyfikatora. |
| UNIKATOWY KLUCZ | Sprawdza, czy wartości przechowywane w kolumnie są różne. |
| NOT NULL | Gwarantuje, że kolumna nie może być ustawiona na wartość NULL. |
| WŁĄCZYĆ | Gwarantuje, że wszystkie dane przychodzące są zgodne z ograniczeniem. |
| WYŁĄCZYĆ | Nie zapewnia zgodności wszystkich danych przychodzących z ograniczeniem. |
| VALIDATEC | Hecks, że wszystkie istniejące dane w tabeli są zgodne z ograniczeniem. |
| NOVALIDATE | Nie sprawdza, czy wszystkie istniejące dane w tabeli są zgodne z ograniczeniem |
| WYMUSZANE | Mapy WŁĄCZYĆ NOVALIDATE. |
| NIE WYMUSZANE | Mapy wyłączyć NOVALIDATE. |
| POLEGAĆ | Określa przestrzeganie przez ograniczenie; używany przez optymalizator do stosowania dalszych optymalizacji. |
| NORELY | Określa, że ograniczenie nie jest zgodne. |
Aby uzyskać więcej informacji, zobacz https://cwiki.apache.org/confluence/display/Hive/Supported+Features%3A++Apache+Hive+3.1.
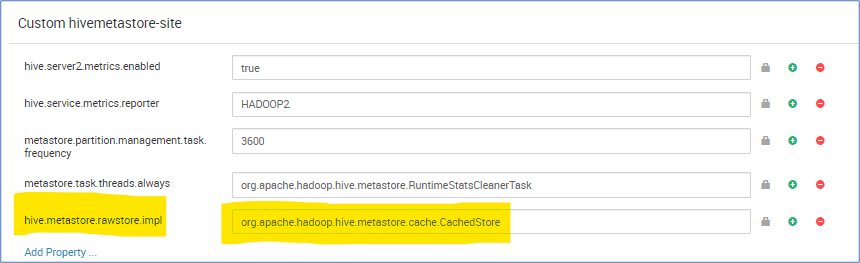
Magazyn metadanych CachedStore
Operacja magazynu metadanych Hive zajmuje dużo czasu, a tym samym spowalnia kompilację programu Hive. W niektórych skrajnych przypadkach czas wykonywania zapytania trwa dłużej niż rzeczywisty czas wykonywania zapytania. Szczególnie uważamy, że opóźnienie bazy danych w chmurze jest wysokie, a 90% całkowitego środowiska uruchomieniowego zapytań oczekuje na operacje bazy danych SQL magazynu metadanych. Na podstawie tej obserwacji wydajność operacji magazynu metadanych jest zwiększona, jeśli mamy strukturę pamięci, która buforuje wynik zapytania bazy danych.
hive.metastore.rawstore.impl=org.apache.hadoop.hive.metastore.cache.CachedStore
Przewodnik po rozwiązywaniu problemów
Przewodnik rozwiązywania problemów z obciążeniami hive w usłudze HDInsight 3.6 do 4.0 zawiera odpowiedzi na typowe problemy występujące podczas migrowania obciążeń hive z usługi HDInsight 3.6 do usługi HDInsight 4.0.
Odwołania
Hive 3.1.0
HBase 2.1.6
https://apache.googlesource.com/hbase/+/ba26a3e1fd5bda8a84f99111d9471f62bb29ed1d/RELEASENOTES.md
Hadoop 3.1.1