Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Apache Hadoop to oryginalna struktura typu „open source” do przetwarzania rozproszonego i analizy zestawów danych big data w klastrach. Ekosystem hadoop obejmuje powiązane oprogramowanie i narzędzia, w tym Apache Hive, Apache HBase, Spark, Kafka i wiele innych.
Usługa Azure HDInsight to w pełni zarządzana, pełna spektrum, usługa analizy typu open source w chmurze dla przedsiębiorstw. Typ klastra Apache Hadoop w usłudze Azure HDInsight umożliwia równoległe przetwarzanie i analizowanie danych wsadowych przy użyciu rozproszonego systemu plików Apache Hadoop (HDFS), zarządzania zasobami apache Hadoop YARN oraz prostego modelu programowania MapReduce. Klastry Hadoop w usłudze HDInsight są zgodne z usługą Azure Data Lake Storage Gen2.
Aby wyświetlić dostępne składniki stosu technologii Hadoop w usłudze HDInsight, zobacz Components and versions available with HDInsight (Składniki i wersje dostępne w usłudze HDInsight). Aby dowiedzieć się więcej o platformie Hadoop w usłudze HDInsight, zobacz stronę z opisem funkcji platformy Azure w usłudze HDInsight.
Co to jest MapReduce
Apache Hadoop MapReduce to struktura oprogramowania do pisania zadań, które przetwarzają ogromne ilości danych. Dane wejściowe są podzielone na niezależne fragmenty. Każdy fragment jest przetwarzany równolegle w węzłach w klastrze. Zadanie MapReduce składa się z dwóch funkcji:
Maper: używa danych wejściowych, analizuje je (zwykle przy użyciu operacji filtrowania i sortowania) i wyprowadza pary klucz-wartość
Reduktor: przetwarza krotków emitowanych przez Mapper i wykonuje operację podsumowania, która tworzy mniejszy, połączony wynik z danych Mappera.
Podstawowy przykład zadania liczenia słów MapReduce przedstawiony jest na poniższym diagramie.
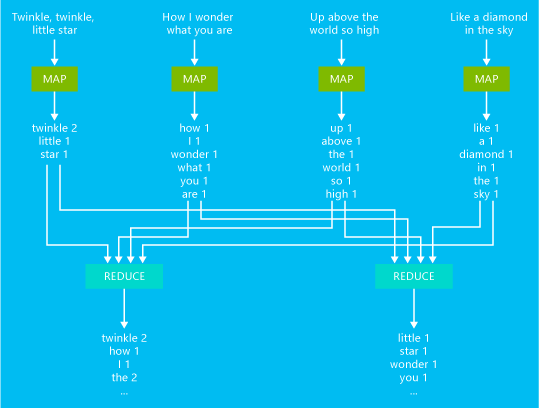
Dane wyjściowe tego zadania to liczba wystąpień każdego wyrazu w tekście.
- Maper pobiera każdy wiersz z tekstu wejściowego jako dane wejściowe i dzieli go na wyrazy. Emituje parę klucz/wartość za każdym razem, gdy słowo wystąpi, a po nim następuje 1. Dane wyjściowe są sortowane przed wysłaniem ich do reduktora.
- Reduktor sumuje ilości wystąpień poszczególnych wyrazów i generuje pojedynczą parę klucz/wartość, która zawiera słowo, po którym następuje suma jego wystąpień.
MapReduce można zaimplementować w różnych językach. Język Java jest najczęstszą implementacją i jest używany do celów demonstracyjnych w tym dokumencie.
Języki programistyczne
Języki lub struktury oparte na języku Java i maszynie wirtualnej Java można uruchamiać bezpośrednio jako zadanie MapReduce. Przykład używany w tym dokumencie to aplikacja Java MapReduce. Języki inne niż Java, takie jak C#, Python lub autonomiczne pliki wykonywalne, muszą używać przesyłania strumieniowego usługi Hadoop.
Hadoop Streaming komunikuje się z maperem i reduktorem za pośrednictwem STDIN i STDOUT. Maper i reduktor odczytują dane linia po linii z STDIN i zapisują je do STDOUT. Każdy wiersz odczytany lub emitowany przez maper i reduktor musi mieć format pary klucz/wartość rozdzielany znakiem tabulacji:
[key]\t[value]
Aby uzyskać więcej informacji, zobacz Przesyłanie strumieniowe w usłudze Hadoop.
Przykłady użycia przesyłania strumieniowego usługi Hadoop w usłudze HDInsight można znaleźć w następującym dokumencie:
Gdzie mogę rozpocząć
- Szybki start: tworzenie klastra Apache Hadoop w usłudze Azure HDInsight przy użyciu witryny Azure Portal
- Samouczek: przesyłanie zadań platformy Apache Hadoop w usłudze HDInsight
- Opracowywanie programów MapReduce w języku Java dla usługi Apache Hadoop w usłudze HDInsight
- Używanie programu Apache Hive jako narzędzia wyodrębniania, przekształcania i ładowania (ETL)
- Wyodrębnianie, przekształcanie i ładowanie (ETL) na dużą skalę
- Operacjonalizacja potoku analizy danych