Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak używać narzędzi Apache Spark i Hive Tools for Visual Studio Code. Użyj narzędzi do tworzenia i przesyłania zadań wsadowych apache Hive, interakcyjnych zapytań Hive i skryptów PySpark dla platformy Apache Spark. Najpierw opiszemy sposób instalowania narzędzi Spark i Hive w programie Visual Studio Code. Następnie przejdziemy przez proces przesyłania zadań do narzędzi Spark i Hive.
Narzędzia Spark i Hive można instalować na platformach obsługiwanych przez program Visual Studio Code. Zwróć uwagę na następujące wymagania wstępne dotyczące różnych platform.
Wymagania wstępne
Do wykonania kroków opisanych w tym artykule są wymagane następujące elementy:
- Klaster usługi Azure HDInsight. Aby utworzyć klaster, zobacz Wprowadzenie do usługi HDInsight. Możesz też użyć klastra Spark i Hive obsługującego punkt końcowy usługi Apache Livy.
- Program Visual Studio Code
- Mono. Mono jest wymagany tylko dla systemów Linux i macOS.
- Interaktywne środowisko PySpark dla programu Visual Studio Code.
- Katalog lokalny. W tym artykule jest używany program
C:\HD\HDexample.
Instalowanie narzędzi Spark i Hive
Po spełnieniu wymagań wstępnych można zainstalować narzędzia Spark i Hive Tools for Visual Studio Code, wykonując następujące kroki:
Otwórz Visual Studio Code.
Na pasku menu przejdź do pozycji Wyświetl>rozszerzenia.
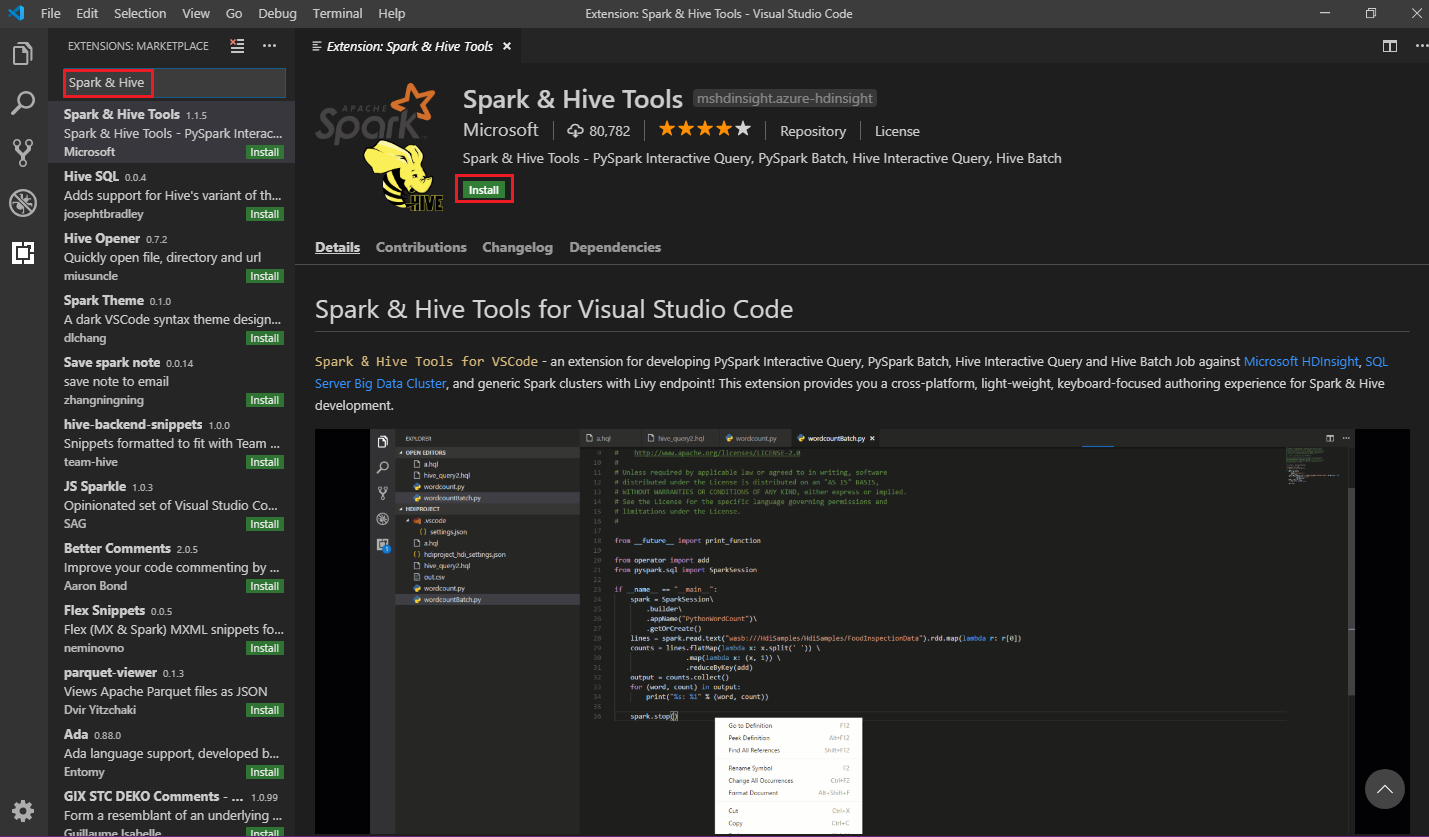
W polu wyszukiwania wpisz Spark & Hive.
Wybierz pozycję Narzędzia Spark i Hive z wyników wyszukiwania, a następnie wybierz pozycję Zainstaluj:
W razie potrzeby wybierz pozycję Załaduj ponownie.
Otwieranie folderu roboczego
Aby otworzyć folder roboczy i utworzyć plik w programie Visual Studio Code, wykonaj następujące kroki:
Na pasku menu przejdź do pozycji Plik>Otwórz folder...>
C:\HD\HDexample, a następnie wybierz przycisk Wybierz folder. Folder zostanie wyświetlony w widoku Eksploratora po lewej stronie.W widoku Eksploratora wybierz
HDexamplefolder, a następnie wybierz ikonę Nowy plik obok folderu roboczego: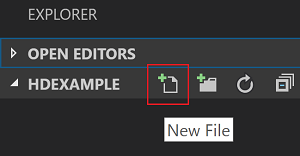
Nazwij nowy plik przy użyciu
.hql(zapytań Hive) lub.pyrozszerzenia pliku (skrypt platformy Spark). W tym przykładzie użyto biblioteki HelloWorld.hql.
Ustawianie środowiska platformy Azure
W przypadku użytkownika chmury krajowej wykonaj następujące kroki, aby najpierw ustawić środowisko platformy Azure, a następnie użyj polecenia Azure: Sign In , aby zalogować się do platformy Azure:
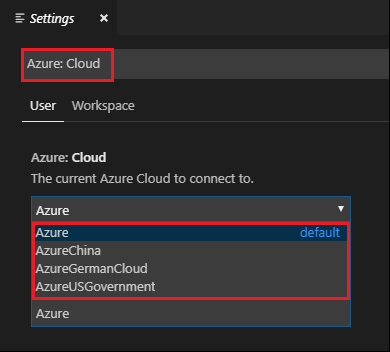
Przejdź do pozycji Ustawienia preferencji>plików.>
Wyszukaj następujący ciąg: Azure: Cloud.
Wybierz chmurę krajową z listy:
Nawiązywanie połączenia z kontem platformy Azure
Zanim będzie można przesłać skrypty do klastrów z poziomu programu Visual Studio Code, użytkownik może zalogować się do subskrypcji platformy Azure lub połączyć klaster usługi HDInsight. Użyj poświadczenia nazwy użytkownika/hasła lub hasła przyłączonego do domeny systemu Ambari dla klastra ESP, aby nawiązać połączenie z klastrem usługi HDInsight. Wykonaj następujące kroki, aby nawiązać połączenie z platformą Azure:
Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń..., a następnie wprowadź polecenie Azure: Sign In:
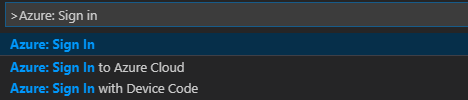
Postępuj zgodnie z instrukcjami logowania, aby zalogować się na platformie Azure. Po nawiązaniu połączenia nazwa konta platformy Azure będzie wyświetlana na pasku stanu w dolnej części okna programu Visual Studio Code.
Łączenie klastra
Link: Azure HDInsight
Klaster normalny można połączyć przy użyciu nazwy użytkownika zarządzanej przez system Apache Ambari lub połączyć bezpieczny klaster Hadoop pakietu Enterprise Security Pack przy użyciu nazwy użytkownika domeny (na przykład: user1@contoso.com).
Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń..., a następnie wprowadź ciąg Spark/Hive: Połącz klaster.

Wybierz typ połączonego klastra Azure HDInsight.
Wprowadź adres URL klastra usługi HDInsight.
Wprowadź nazwę użytkownika systemu Ambari; wartość domyślna to administrator.
Wprowadź hasło systemu Ambari.
Wybierz typ klastra.
Ustaw nazwę wyświetlaną klastra (opcjonalnie).
Przejrzyj widok DANE WYJŚCIOWE w celu weryfikacji.
Uwaga
Połączona nazwa użytkownika i hasło są używane, jeśli klaster jest zalogowany do subskrypcji platformy Azure i połączony klaster.
Link: Ogólny punkt końcowy usługi Livy
Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń..., a następnie wprowadź ciąg Spark/Hive: Połącz klaster.
Wybierz typ połączonego klastra Ogólny punkt końcowy usługi Livy.
Wprowadź ogólny punkt końcowy usługi Livy. Na przykład: http://10.172.41.42:18080..
Wybierz typ autoryzacji — Podstawowy lub Brak. W przypadku wybrania pozycji Podstawowa:
Wprowadź nazwę użytkownika systemu Ambari; wartość domyślna to administrator.
Wprowadź hasło systemu Ambari.
Przejrzyj widok DANE WYJŚCIOWE w celu weryfikacji.
Wyświetlanie listy klastrów
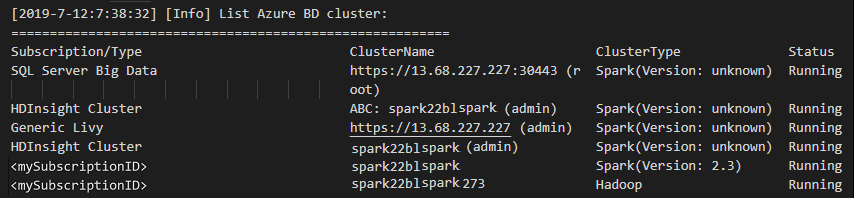
Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń..., a następnie wprowadź ciąg Spark/Hive: Klaster listy.
Wybierz odpowiednią subskrypcję.
Przejrzyj widok DANE WYJŚCIOWE. Ten widok przedstawia połączony klaster (lub klastry) i wszystkie klastry w ramach subskrypcji platformy Azure:
Ustawianie klastra domyślnego
HDexampleOtwórz ponownie omówiony wcześniej folder, jeśli został zamknięty.Wybierz utworzony wcześniej plik HelloWorld.hql. Zostanie otwarty w edytorze skryptów.
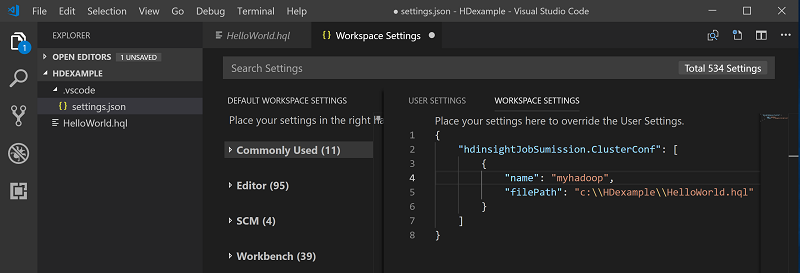
Kliknij prawym przyciskiem myszy edytor skryptów, a następnie wybierz pozycję Spark/Hive: Ustaw klaster domyślny.
Połącz się z kontem platformy Azure lub połącz klaster, jeśli jeszcze tego nie zrobiono.
Wybierz klaster jako domyślny klaster dla bieżącego pliku skryptu. Narzędzia automatycznie aktualizują element . Plik konfiguracji VSCode\settings.json :
Przesyłanie interakcyjnych zapytań Hive i skryptów wsadowych Hive
Za pomocą narzędzi Spark i Hive Tools for Visual Studio Code można przesyłać interakcyjne zapytania Hive i skrypty wsadowe Hive do klastrów.
HDexampleOtwórz ponownie omówiony wcześniej folder, jeśli został zamknięty.Wybierz utworzony wcześniej plik HelloWorld.hql. Zostanie otwarty w edytorze skryptów.
Skopiuj i wklej następujący kod do pliku Hive, a następnie zapisz go:
SELECT * FROM hivesampletable;Połącz się z kontem platformy Azure lub połącz klaster, jeśli jeszcze tego nie zrobiono.
Kliknij prawym przyciskiem myszy edytor skryptów i wybierz pozycję Hive: Interakcyjne , aby przesłać zapytanie, lub użyj skrótu klawiaturowego Ctrl+Alt+I. Wybierz pozycję Hive: usługa Batch , aby przesłać skrypt, lub użyj skrótu klawiaturowego Ctrl+Alt+H.
Jeśli nie określono klastra domyślnego, wybierz klaster. Narzędzia umożliwiają również przesyłanie bloku kodu zamiast całego pliku skryptu przy użyciu menu kontekstowego. Po kilku chwilach wyniki zapytania pojawią się na nowej karcie:
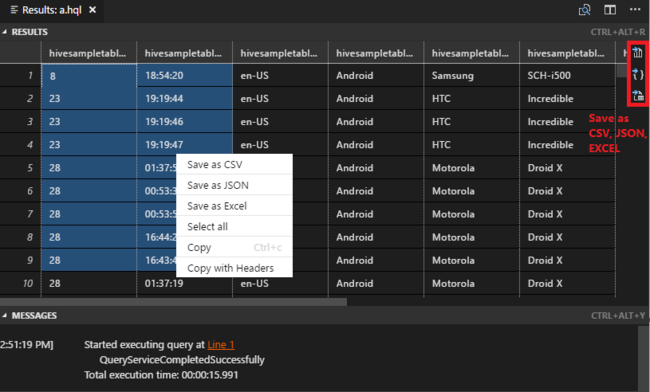
Panel WYNIKI : cały wynik można zapisać jako plik CSV, JSON lub Excel do ścieżki lokalnej lub po prostu wybrać wiele wierszy.
Panel KOMUNIKATY : po wybraniu numeru wiersza przechodzi do pierwszego wiersza uruchomionego skryptu.
Przesyłanie interakcyjnych zapytań PySpark
Wymagania wstępne dotyczące interaktywnego programu Pyspark
Należy pamiętać, że wersja rozszerzenia Jupyter (ms-jupyter): v2022.1.1001614873 i rozszerzenie języka Python (ms-python): v2021.12.1559732655, Python 3.6.x i 3.7.x są wymagane w przypadku interakcyjnych zapytań PySpark w usłudze HDInsight.
Użytkownicy mogą wykonywać interaktywne operacje PySpark w następujący sposób.
Używanie interaktywnego polecenia PySpark w pliku PY
Korzystając z interakcyjnego polecenia PySpark do przesyłania zapytań, wykonaj następujące kroki:
HDexampleOtwórz ponownie omówiony wcześniej folder, jeśli został zamknięty.Utwórz nowy plik HelloWorld.py , wykonując wcześniejsze kroki.
Skopiuj i wklej następujący kod do pliku skryptu:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])Monit o zainstalowanie jądra PySpark/Synapse Pyspark jest wyświetlany w prawym dolnym rogu okna. Możesz kliknąć przycisk Zainstaluj , aby przejść do instalacji PySpark/Synapse Pyspark; lub kliknąć przycisk Pomiń , aby pominąć ten krok.
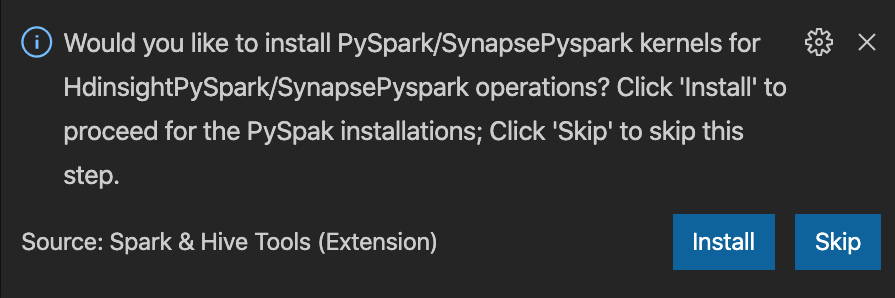
Jeśli chcesz go zainstalować później, możesz przejść do pozycji Ustawienia preferencji>plików>, a następnie usunąć zaznaczenie pola wyboru HDInsight: Włącz opcję Pomiń instalację Pyspark w ustawieniach.
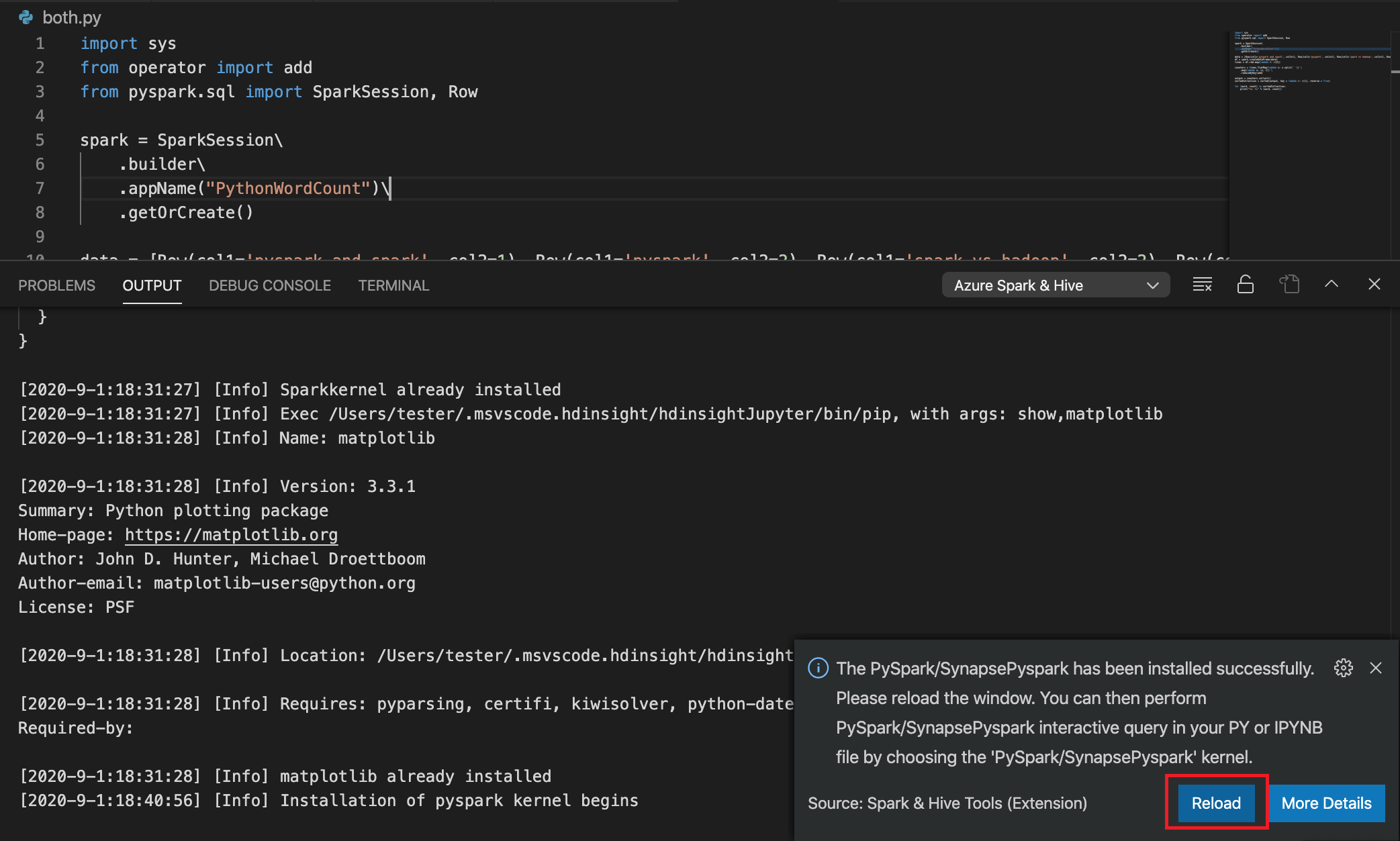
Jeśli instalacja zakończy się pomyślnie w kroku 4, w prawym dolnym rogu okna zostanie wyświetlony komunikat "Instalacja PySpark została pomyślnie zainstalowana". Kliknij przycisk Załaduj ponownie, aby ponownie załadować okno.
Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń... lub użyj skrótu klawiaturowego Shift + Ctrl + P, a następnie wprowadź ciąg Python: Wybierz pozycję Interpreter, aby uruchomić serwer Jupyter.

Wybierz poniższą opcję języka Python.

Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń... lub użyj skrótu klawiaturowego Shift + Ctrl + P, a następnie wprowadź ciąg Developer: Reload Window (Deweloper: załaduj ponownie okno).

Połącz się z kontem platformy Azure lub połącz klaster, jeśli jeszcze tego nie zrobiono.
Wybierz cały kod, kliknij prawym przyciskiem myszy edytor skryptów i wybierz pozycję Spark: PySpark Interactive / Synapse: Pyspark Interactive , aby przesłać zapytanie.
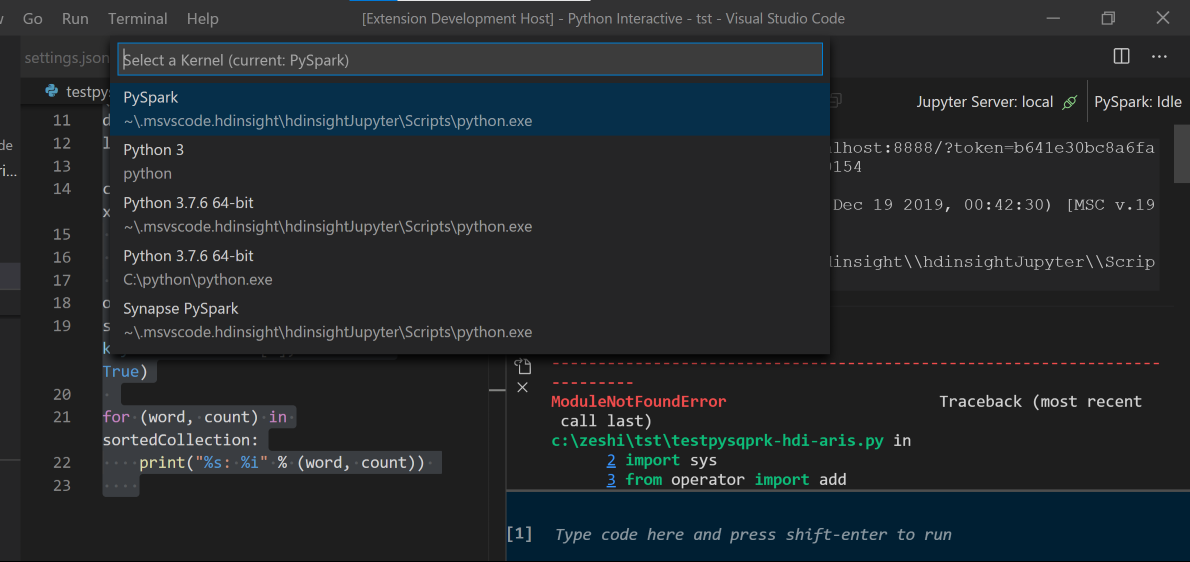
Wybierz klaster, jeśli nie określono klastra domyślnego. Po kilku chwilach wyniki interaktywne języka Python zostaną wyświetlone na nowej karcie. Kliknij pozycję PySpark, aby przełączyć jądro na PySpark /Synapse Pyspark, a kod zostanie uruchomiony pomyślnie. Jeśli chcesz przełączyć się na jądro Synapse Pyspark, zaleca się wyłączenie ustawień automatycznych w witrynie Azure Portal. W przeciwnym razie może upłynąć dużo czasu, aby obudzić klaster i ustawić jądro synapse po raz pierwszy. Jeśli narzędzia umożliwiają również przesyłanie bloku kodu zamiast całego pliku skryptu przy użyciu menu kontekstowego:
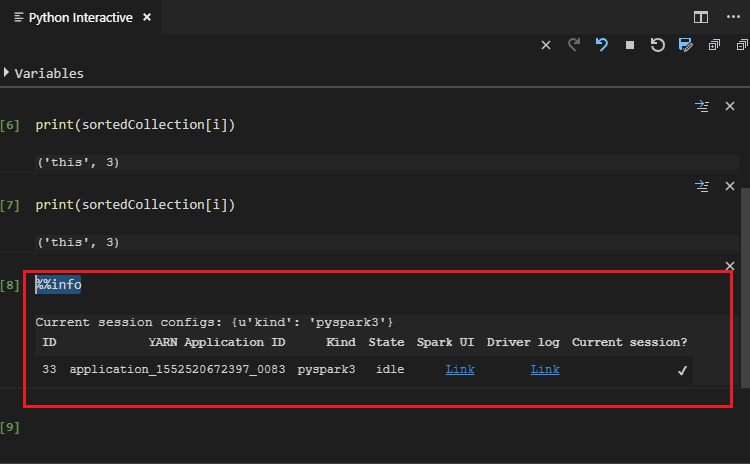
Wprowadź %%info, a następnie naciśnij Shift+Enter, aby wyświetlić informacje o zadaniu (opcjonalnie):
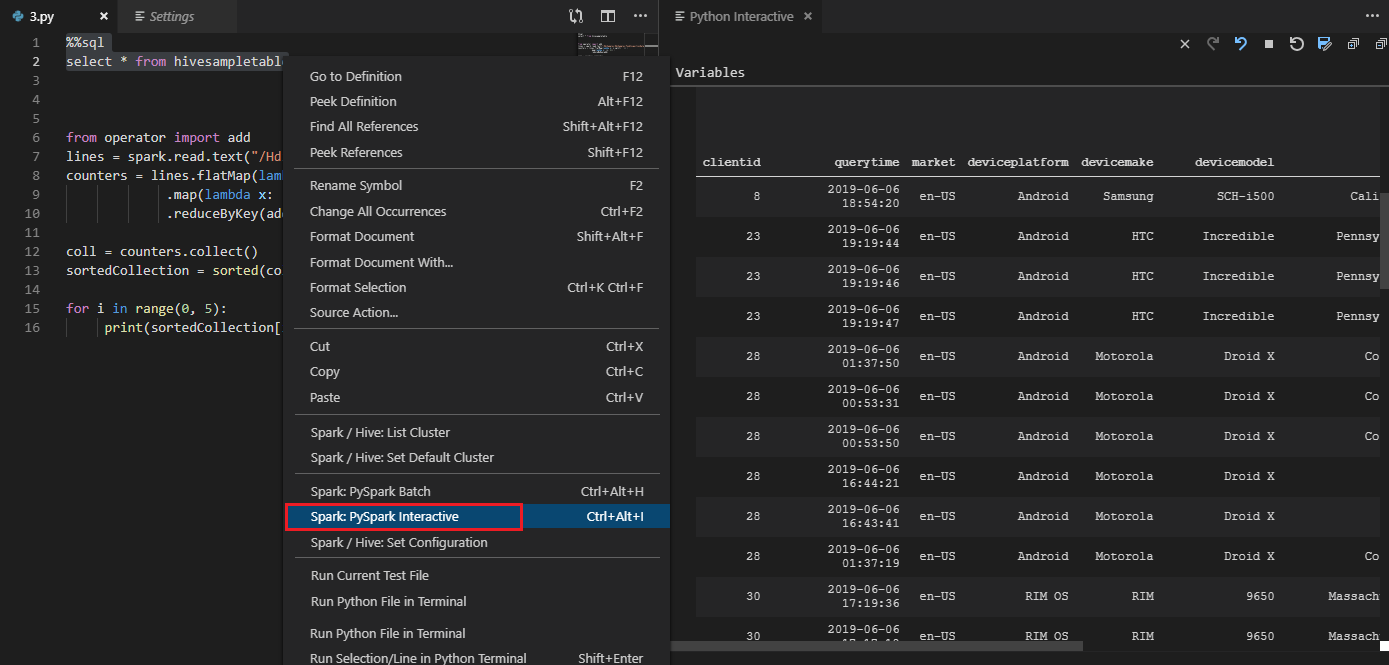
Narzędzie obsługuje również zapytanie Spark SQL :
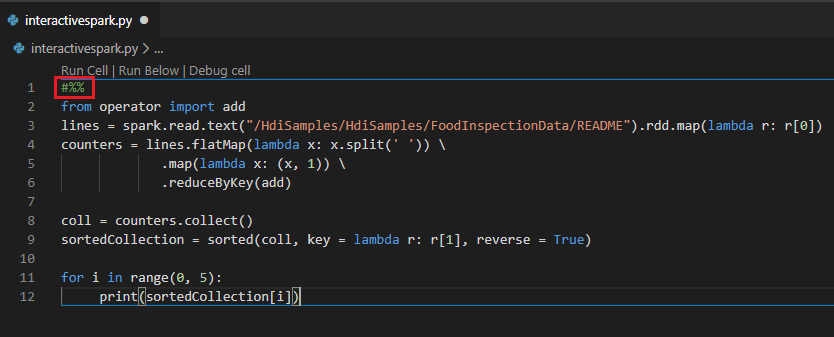
Wykonywanie interakcyjnego zapytania w pliku PY przy użyciu komentarza #%%
Dodaj #%% przed kodem Py, aby uzyskać środowisko notesu.
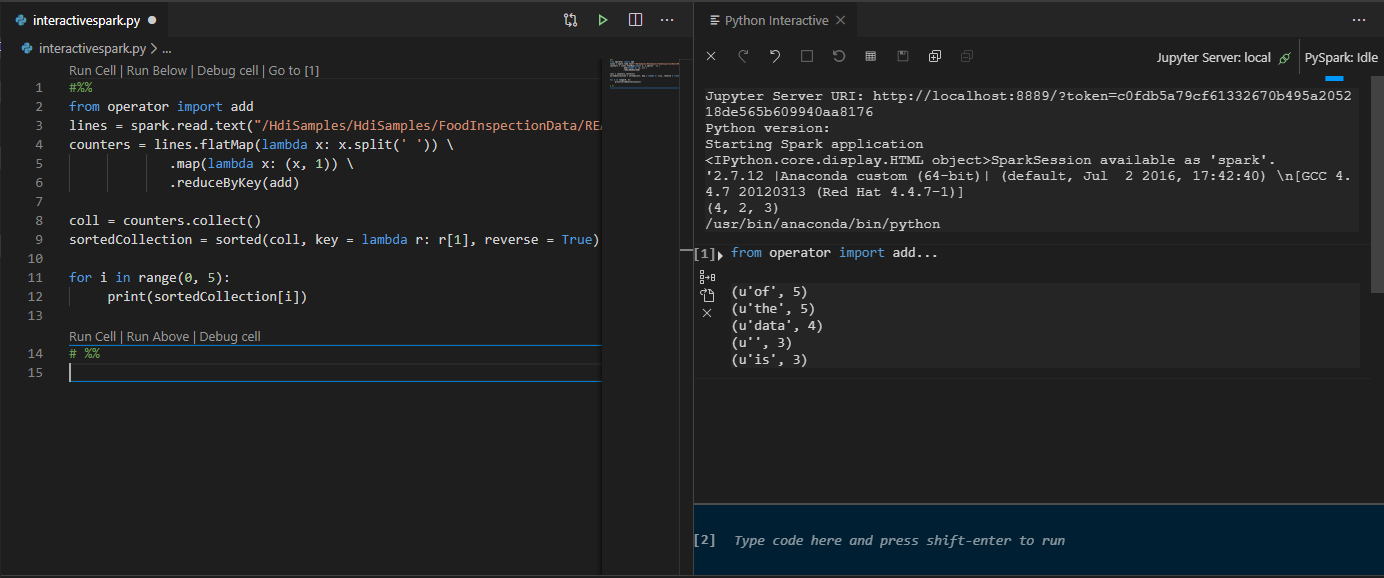
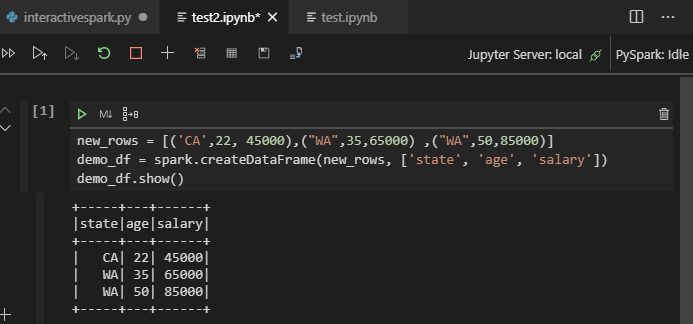
Kliknij pozycję Uruchom komórkę. Po kilku chwilach wyniki interaktywne języka Python pojawią się na nowej karcie. Kliknij pozycję PySpark, aby przełączyć jądro na PySpark/Synapse PySpark, a następnie ponownie kliknij pozycję Uruchom komórkę , a kod zostanie uruchomiony pomyślnie.
Korzystanie z obsługi protokołu IPYNB z rozszerzenia języka Python
Notes Jupyter Notebook można utworzyć za pomocą polecenia z palety poleceń lub tworząc nowy
.ipynbplik w obszarze roboczym. Aby uzyskać więcej informacji, zobacz Praca z notesami Jupyter Notebook w programie Visual Studio CodeKliknij przycisk Uruchom komórkę, postępuj zgodnie z monitami, aby ustawić domyślną pulę spark (zalecamy ustawienie domyślnego klastra/puli za każdym razem przed otwarciem notesu), a następnie okno Ponowne ładowanie.
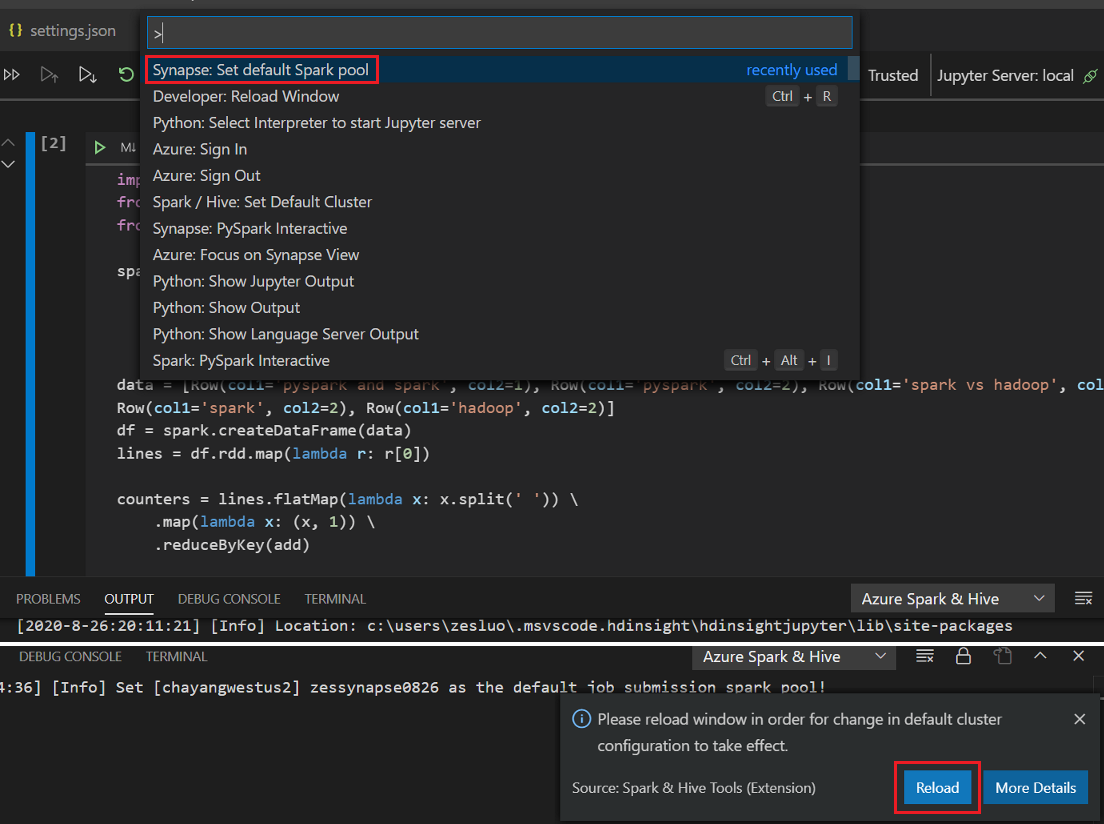
Kliknij pozycję PySpark, aby przełączyć jądro na PySpark / Synapse Pyspark, a następnie kliknij pozycję Uruchom komórkę, po chwili zostanie wyświetlony wynik.
Uwaga
W przypadku błędu instalacji programu Synapse PySpark, ponieważ jego zależność nie będzie już utrzymywana przez inny zespół, nie będzie już utrzymywana. Jeśli spróbujesz użyć interaktywnego programu Synapse Pyspark, przełącz się, aby zamiast tego użyć usługi Azure Synapse Analytics . I to długoterminowa zmiana.
Przesyłanie zadania wsadowego PySpark
HDexampleOtwórz ponownie omówiony wcześniej folder, jeśli został zamknięty.Utwórz nowy plik BatchFile.py , wykonując wcześniejsze kroki.
Skopiuj i wklej następujący kod do pliku skryptu:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Połącz się z kontem platformy Azure lub połącz klaster, jeśli jeszcze tego nie zrobiono.
Kliknij prawym przyciskiem myszy edytor skryptów, a następnie wybierz pozycję Spark: PySpark Batch lub Synapse: PySpark Batch*.
Wybierz klaster/pulę spark, aby przesłać zadanie PySpark do:
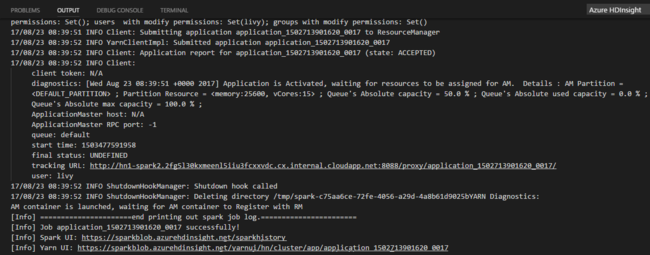
Po przesłaniu zadania języka Python dzienniki przesyłania są wyświetlane w oknie DANE WYJŚCIOWE w programie Visual Studio Code. Pokazano również adres URL interfejsu użytkownika platformy Spark i adres URL interfejsu użytkownika usługi Yarn. Jeśli prześlesz zadanie wsadowe do puli platformy Apache Spark, zostanie również wyświetlony adres URL interfejsu użytkownika historii platformy Spark i adres URL interfejsu użytkownika aplikacji zadań platformy Spark. Możesz otworzyć adres URL w przeglądarce internetowej, aby śledzić stan zadania.
Integracja z usługą HDInsight Identity Broker (HIB)
Nawiązywanie połączenia z klastrem USŁUGI HDInsight ESP za pomocą brokera identyfikatorów (HIB)
Aby zalogować się do subskrypcji platformy Azure, możesz wykonać normalne kroki, aby nawiązać połączenie z klastrem USŁUGI HDInsight ESP za pomocą brokera identyfikatorów (HIB). Po zalogowaniu zobaczysz listę klastrów w eksploratorze platformy Azure. Aby uzyskać więcej instrukcji, zobacz Nawiązywanie połączenia z klastrem usługi HDInsight.
Uruchamianie zadania Programu Hive/PySpark w klastrze ESP usługi HDInsight z usługą ID Broker (HIB)
Aby uruchomić zadanie hive, możesz wykonać normalne kroki, aby przesłać zadanie do klastra USŁUGI HDInsight ESP z brokerem identyfikatora (HIB). Aby uzyskać więcej instrukcji, zapoznaj się z tematem Submit interactive Hive queries and Hive batch scripts (Przesyłanie interakcyjnych zapytań Hive i skryptów wsadowych Hive).
Aby uruchomić interakcyjne zadanie PySpark, możesz wykonać normalne kroki, aby przesłać zadanie do klastra USŁUGI HDInsight ESP z usługą ID Broker (HIB). Zapoznaj się z artykułem Submit interactive PySpark queries (Przesyłanie interakcyjnych zapytań PySpark).
Aby uruchomić zadanie wsadowe PySpark, możesz wykonać normalne kroki, aby przesłać zadanie do klastra USŁUGI HDInsight ESP z brokerem identyfikatorów (HIB). Aby uzyskać więcej instrukcji, zobacz Submit PySpark batch job (Przesyłanie zadania wsadowego PySpark).
Konfiguracja usługi Apache Livy
Obsługiwana jest konfiguracja usługi Apache Livy . Można go skonfigurować w pliku . Plik VSCode\settings.json w folderze obszaru roboczego. Obecnie konfiguracja usługi Livy obsługuje tylko skrypt języka Python. Aby uzyskać więcej informacji, zobacz Livy README.
Jak wyzwolić konfigurację usługi Livy
Metoda 1
- Na pasku menu przejdź do pozycji Ustawienia preferencji>plików>.
- W polu Ustawienia wyszukiwania wpisz HDInsight Job Submission: Livy Conf.
- Wybierz pozycję Edytuj w settings.json dla odpowiedniego wyniku wyszukiwania.
Metoda 2
Prześlij plik i zwróć uwagę, że .vscode folder jest automatycznie dodawany do folderu roboczego. Konfigurację usługi Livy można wyświetlić, wybierając pozycję .vscode\settings.json.
Ustawienia projektu:
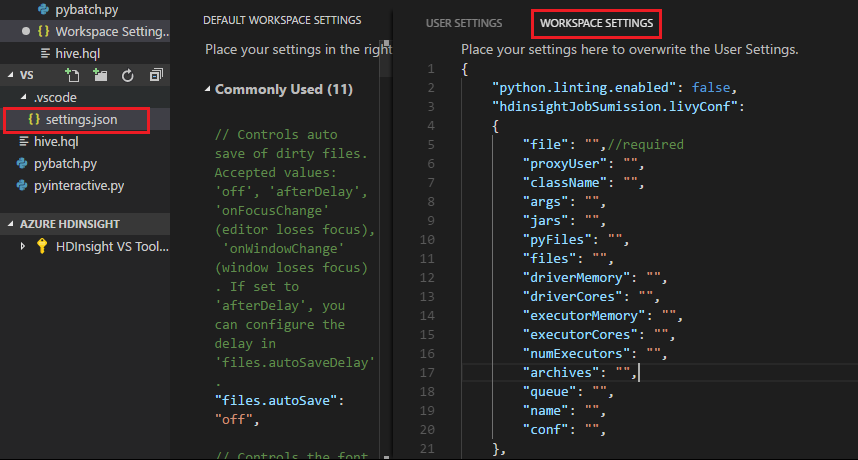
Uwaga
W przypadku ustawień driverMemory i executorMemory ustaw wartość i jednostkę. Na przykład: 1g lub 1024 m.
Obsługiwane konfiguracje usługi Livy:
POST /batches
Treść żądania
name opis type plik Plik zawierający aplikację do wykonania Ścieżka (wymagana) proxyUser Użytkownik do personifikacji podczas uruchamiania zadania String className Klasa główna aplikacji Java/Spark String args Argumenty wiersza polecenia dla aplikacji Lista ciągów Słoiki Pliki Jar do użycia w tej sesji Lista ciągów pyFiles Pliki języka Python, które mają być używane w tej sesji Lista ciągów files Pliki do użycia w tej sesji Lista ciągów driverMemory Ilość pamięci do użycia w procesie sterownika String driverCores Liczba rdzeni do użycia w procesie sterownika Int executorMemory Ilość pamięci do użycia na proces funkcji wykonawczej String Rdzeńy wykonawcze Liczba rdzeni do użycia dla każdego modułu wykonawczego Int numExecutors Liczba funkcji wykonawczych do uruchomienia dla tej sesji Int archiwum Archiwa do użycia w tej sesji Lista ciągów kolejka Nazwa kolejki usługi YARN do przesłania String name Nazwa tej sesji String Conf Właściwości konfiguracji platformy Spark Mapa klucza=val Treść odpowiedzi Utworzony obiekt usługi Batch.
name opis type ID Identyfikator sesji Int appId Identyfikator aplikacji tej sesji String appInfo Szczegółowe informacje o aplikacji Mapa klucza=val Dziennik Wiersze dziennika Lista ciągów stan Stan partii String Uwaga
Przypisana konfiguracja usługi Livy jest wyświetlana w okienku danych wyjściowych podczas przesyłania skryptu.
Integracja z usługą Azure HDInsight z poziomu Eksploratora
Możesz wyświetlić podgląd tabeli Hive w klastrach bezpośrednio za pomocą eksploratora usługi Azure HDInsight :
Połącz się z kontem platformy Azure, jeśli jeszcze tego nie zrobiono.
Wybierz ikonę platformy Azure z lewej kolumny.
W okienku po lewej stronie rozwiń węzeł AZURE: HDINSIGHT. Zostaną wyświetlone dostępne subskrypcje i klastry.
Rozwiń klaster, aby wyświetlić bazę danych metadanych programu Hive i schemat tabeli.
Kliknij prawym przyciskiem myszy tabelę Hive. Na przykład: hivesampletable. Wybierz Podgląd.
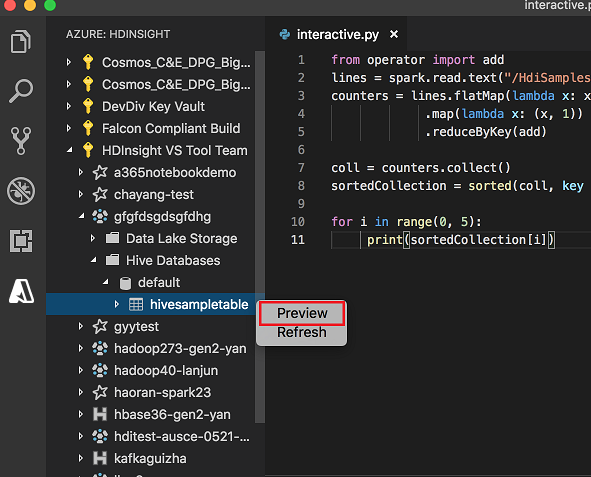
Zostanie otwarte okno Podgląd wyników :
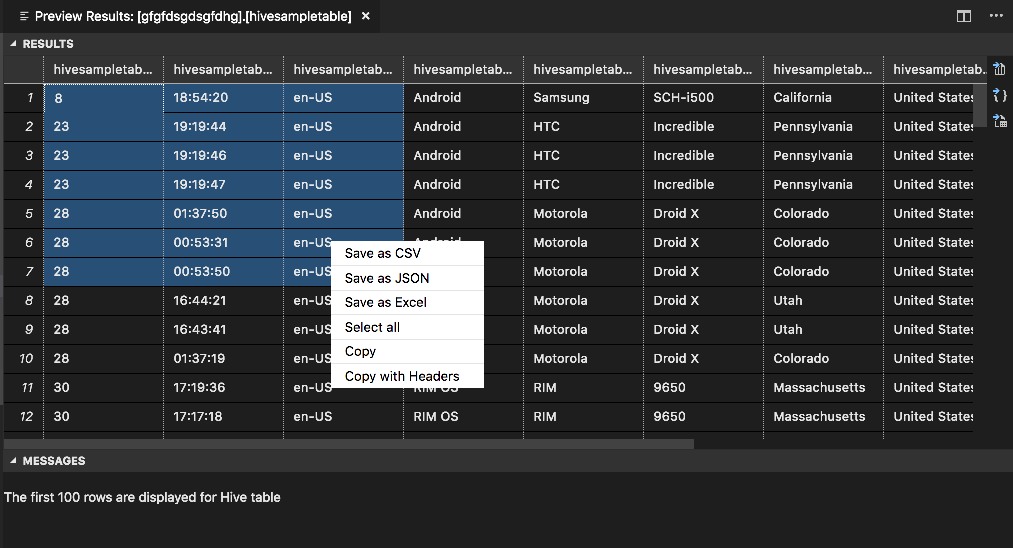
Panel WYNIKI
Cały wynik można zapisać jako plik CSV, JSON lub Excel w ścieżce lokalnej lub po prostu wybrać wiele wierszy.
Panel KOMUNIKATY
Gdy liczba wierszy w tabeli jest większa niż 100, zostanie wyświetlony następujący komunikat: "Pierwsze 100 wierszy jest wyświetlanych dla tabeli Programu Hive".
Gdy liczba wierszy w tabeli jest mniejsza lub równa 100, zostanie wyświetlony następujący komunikat: "60 wierszy jest wyświetlanych dla tabeli Hive".
Jeśli w tabeli nie ma zawartości, zostanie wyświetlony następujący komunikat: "
0 rows are displayed for Hive table."Uwaga
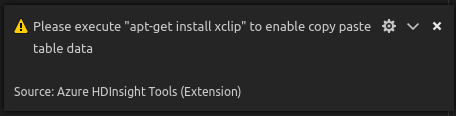
W systemie Linux zainstaluj narzędzie xclip, aby włączyć dane copy-table.
Dodatkowe funkcje
Platforma Spark i hive dla programu Visual Studio Code obsługuje również następujące funkcje:
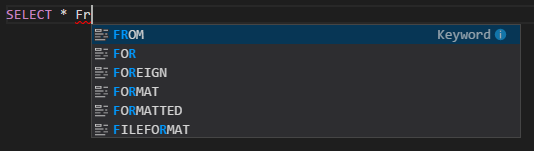
Autouzupełnianie funkcji IntelliSense. Sugestie są wyskakujące dla słów kluczowych, metod, zmiennych i innych elementów programowania. Różne ikony reprezentują różne typy obiektów:
Znacznik błędu funkcji IntelliSense. Usługa językowa podkreśla błędy edytowania skryptu Programu Hive.
Wyróżniana składnia. Usługa językowa używa różnych kolorów do rozróżniania zmiennych, słów kluczowych, typu danych, funkcji i innych elementów programowania:
Rola tylko dla czytelnika
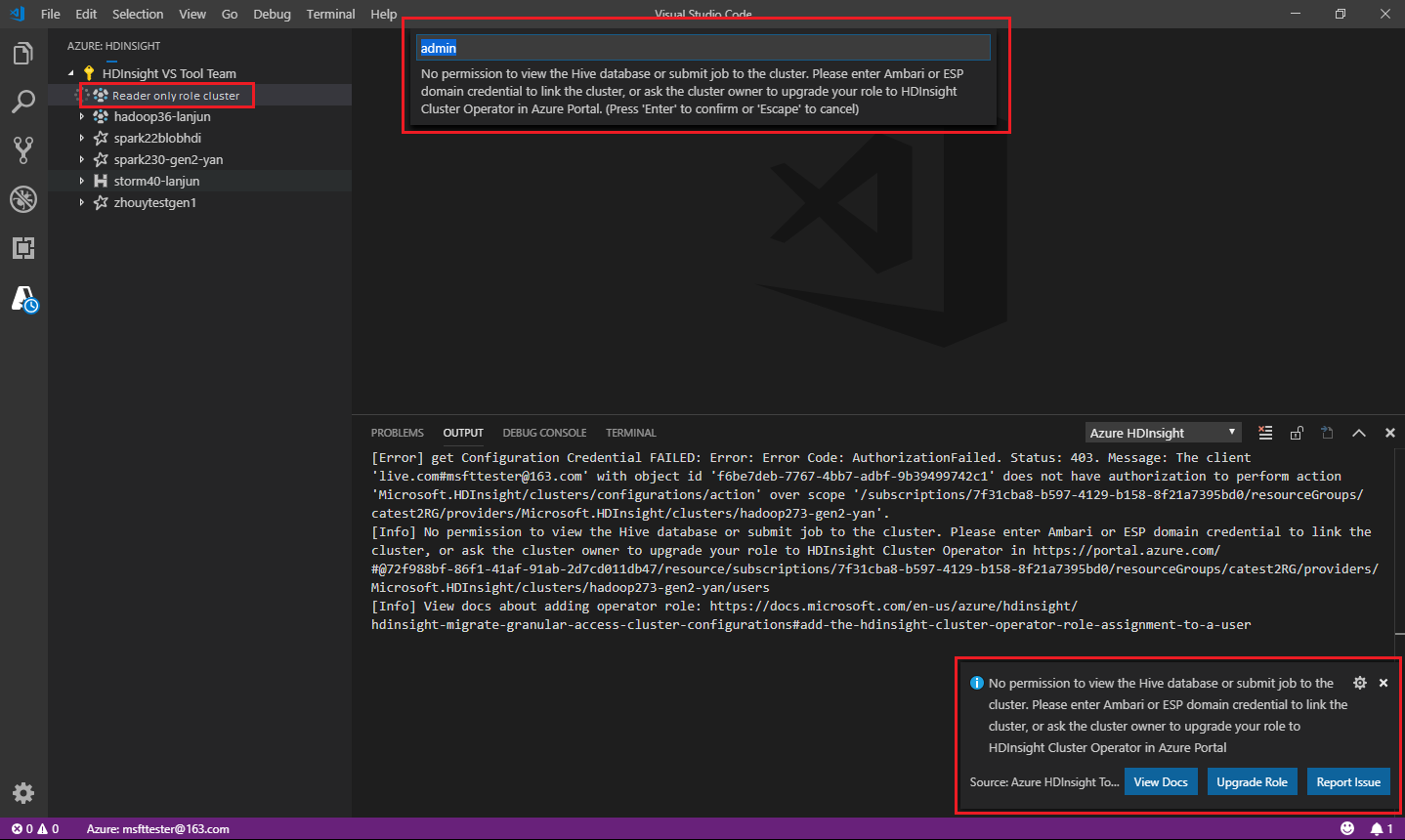
Użytkownicy, którym przypisano rolę tylko do odczytu dla klastra, nie mogą przesyłać zadań do klastra usługi HDInsight ani wyświetlać bazy danych Hive. Skontaktuj się z administratorem klastra, aby uaktualnić swoją rolę do operatora klastra usługi HDInsight w witrynie Azure Portal. Jeśli masz prawidłowe poświadczenia systemu Ambari, możesz ręcznie połączyć klaster, korzystając z poniższych wskazówek.
Przeglądanie klastra usługi HDInsight
Po wybraniu eksploratora usługi Azure HDInsight w celu rozwinięcia klastra usługi HDInsight zostanie wyświetlony monit o połączenie klastra, jeśli masz rolę tylko do odczytu dla klastra. Użyj następującej metody, aby połączyć się z klastrem przy użyciu poświadczeń systemu Ambari.
Przesyłanie zadania do klastra usługi HDInsight
Podczas przesyłania zadania do klastra usługi HDInsight zostanie wyświetlony monit o połączenie klastra, jeśli jesteś w roli tylko czytelnika dla klastra. Wykonaj poniższe kroki, aby połączyć się z klastrem przy użyciu poświadczeń systemu Ambari.
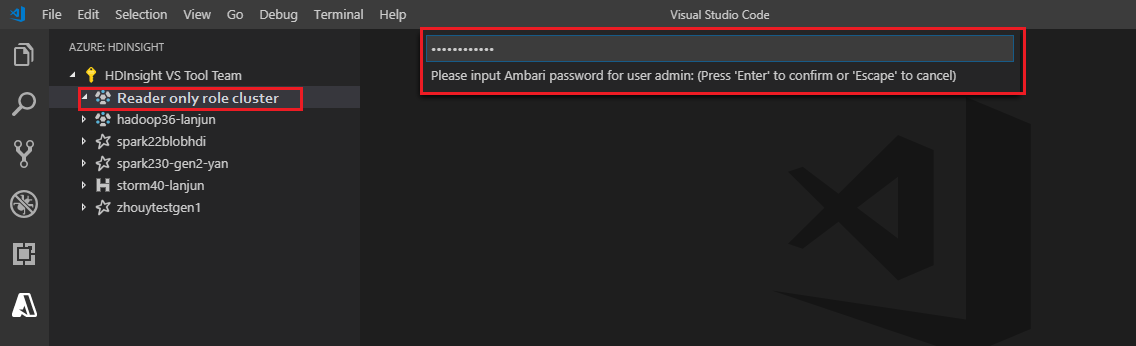
Łączenie z klastrem
Wprowadź prawidłową nazwę użytkownika systemu Ambari.
Wprowadź prawidłowe hasło.
Uwaga
Możesz użyć
Spark / Hive: List Clusterpolecenia , aby sprawdzić połączony klaster:
Azure Data Lake Storage Gen2
Przeglądanie konta usługi Data Lake Storage Gen2
Wybierz eksploratora usługi Azure HDInsight, aby rozwinąć konto usługi Data Lake Storage Gen2. Zostanie wyświetlony monit o wprowadzenie klucza dostępu do magazynu, jeśli twoje konto platformy Azure nie ma dostępu do magazynu Gen2. Po zweryfikowaniu klucza dostępu konto usługi Data Lake Storage Gen2 zostanie automatycznie rozwinięte.
Przesyłanie zadań do klastra usługi HDInsight za pomocą usługi Data Lake Storage Gen2
Przesyłanie zadania do klastra usługi HDInsight przy użyciu usługi Data Lake Storage Gen2. Zostanie wyświetlony monit o wprowadzenie klucza dostępu do magazynu, jeśli twoje konto platformy Azure nie ma dostępu do zapisu w magazynie Gen2. Po zweryfikowaniu klucza dostępu zadanie zostanie pomyślnie przesłane.

Uwaga
Klucz dostępu dla konta magazynu można uzyskać w witrynie Azure Portal. Aby uzyskać więcej informacji, zobacz Zarządzanie kluczami dostępu do konta magazynu.
Odłącz klaster
Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń, a następnie wprowadź ciąg Spark/Hive: Odłącz klaster.
Wybierz klaster, aby odłączyć.
Aby uzyskać weryfikację , zobacz widok DANE WYJŚCIOWE .
Wyloguj się
Na pasku menu przejdź do pozycji Wyświetl>paletę poleceń, a następnie wprowadź polecenie Azure: Wyloguj się.
Znane problemy
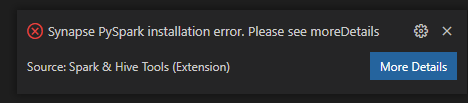
Błąd instalacji programu Synapse PySpark.
W przypadku błędu instalacji programu Synapse PySpark, ponieważ jego zależność nie będzie już utrzymywana przez inny zespół, nie będzie już utrzymywana. Jeśli spróbujesz użyć interaktywnego programu Synapse Pyspark, zamiast tego użyj usługi Azure Synapse Analytics . I to długoterminowa zmiana.
Następne kroki
Aby zapoznać się z filmem wideo przedstawiającym korzystanie z programu Spark &Hive dla programu Visual Studio Code, zobacz Spark & Hive for Visual Studio Code.