Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak uzyskać dostęp do dzienników aplikacji Apache Hadoop YARN (jeszcze innego negocjatora zasobów) w klastrze Apache Hadoop w usłudze Azure HDInsight.
Co to jest Apache YARN?
Usługa YARN obsługuje wiele modeli programowania (Apache Hadoop MapReduce jest jednym z nich) przez oddzielenie zarządzania zasobami od planowania/monitorowania aplikacji. Usługa YARN używa globalnego ResourceManager (RM), węzłów roboczych NodeManagers (NMs), oraz aplikacyjnych ApplicationMasters (AMs). Per-aplikacyjny AM negocjuje zasoby (procesor CPU, pamięć, dysk, sieć) potrzebne do uruchomienia aplikacji z RM. Program RM współpracuje z NM w celu przydzielenia tych zasobów, które są przyznawane jako kontenery. Menadżer kont, w skrócie AM, jest odpowiedzialny za śledzenie postępu kontenerów przypisanych do niego przez menedżera zasobów, oznaczanego jako RM. Aplikacja może wymagać wielu kontenerów w zależności od charakteru aplikacji.
Każda aplikacja może składać się z wielu prób aplikacji. Jeśli aplikacja zakończy się niepowodzeniem, może zostać ponowiona próba. Każda próba jest uruchamiana w kontenerze. W sensie kontener udostępnia kontekst podstawowej jednostki pracy wykonywanej przez aplikację YARN. Wszystkie prace wykonywane w kontekście kontenera są realizowane na pojedynczym węźle roboczym, do którego został przydzielony kontener. Zobacz Hadoop: pisanie aplikacji YARN lub Apache Hadoop YARN , aby uzyskać więcej informacji.
Aby skalować klaster w celu zapewnienia większej przepływności przetwarzania, możesz użyć skalowania automatycznego lub skalowania klastrów ręcznie przy użyciu kilku różnych języków.
Serwer osi czasu YARN
Serwer osi czasu usługi Apache Hadoop YARN zawiera ogólne informacje na temat ukończonych aplikacji
Serwer osi czasu usługi YARN zawiera następujący typ danych:
- Identyfikator aplikacji, unikatowy identyfikator aplikacji
- Użytkownik, który uruchomił aplikację
- Informacje na temat prób ukończenia aplikacji
- Kontenery używane przez dowolną próbę aplikacji
Aplikacje i dzienniki usługi YARN
Dzienniki aplikacji (i skojarzone dzienniki kontenerów) mają kluczowe znaczenie podczas debugowania problematycznych aplikacji Hadoop. Usługa YARN zapewnia miłą strukturę do zbierania, agregowania i przechowywania dzienników aplikacji za pomocą agregacji dzienników.
Funkcja agregacji dziennika sprawia, że uzyskiwanie dostępu do dzienników aplikacji jest bardziej deterministyczne. Agreguje dzienniki we wszystkich kontenerach w węźle procesu roboczego i przechowuje je jako jeden zagregowany plik dziennika na węzeł procesu roboczego. Po zakończeniu działania aplikacji dziennik jest przechowywany w domyślnym systemie plików. Aplikacja może używać setek lub tysięcy kontenerów, ale dzienniki dla wszystkich kontenerów uruchamianych w jednym węźle roboczym są zawsze agregowane do jednego pliku. Więc jest tylko jeden dziennik na każdy węzeł roboczy używany przez aplikację. Agregacja dzienników jest domyślnie włączona w klastrach usługi HDInsight w wersji 3.0 lub nowszej. Zagregowane dzienniki znajdują się w domyślnym magazynie klastra. Następująca ścieżka to ścieżka systemu plików HDFS do dzienników:
/app-logs/<user>/logs/<applicationId>
W ścieżce user jest nazwą użytkownika, który uruchomił aplikację.
applicationId to unikatowy identyfikator przydzielony aplikacji przez YARN RM.
Zagregowane dzienniki nie są bezpośrednio czytelne, ponieważ są zapisywane w formacie binarnym TFileindeksowanym przez kontener. Użyj dzienników usługi YARN ResourceManager lub narzędzi interfejsu wiersza polecenia, aby wyświetlić te dzienniki jako zwykły tekst dla interesujących aplikacji lub kontenerów.
Dzienniki Yarn w klastrze ESP
Do niestandardowego mapred-site elementu w systemie Ambari należy dodać dwie konfiguracje.
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net, gdzieCLUSTERNAMEjest nazwą klastra.W interfejsie użytkownika Ambari przejdź do MapReduce2>Configs>Advanced>Custom mapred-site.
Dodaj jeden z następujących zestawów właściwości:
Ustaw wartość 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Zestaw 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Zapisz zmiany i uruchom ponownie wszystkie objęte usługi.
Narzędzia CLI YARN
Użyj polecenia ssh, aby nawiązać połączenie z klastrem. Zmodyfikuj następujące polecenie, zastępując ciąg CLUSTERNAME nazwą klastra, a następnie wprowadź polecenie:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netWypisz wszystkie identyfikatory aktualnie uruchomionych aplikacji Yarn za pomocą następującego polecenia:
yarn topZanotuj identyfikator aplikacji z kolumny
APPLICATIONID, której dzienniki chcesz pobrać.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerTe dzienniki można wyświetlić jako zwykły tekst, uruchamiając jedno z następujących poleceń:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address><Określ identyfikator applicationId>, <user-who-started-the-application>, <containerId> i <worker-node-address> podczas uruchamiania tych poleceń.
Inne przykładowe polecenia
Pobierz dzienniki kontenerów Yarn dla wszystkich masterów aplikacji za pomocą następującego polecenia. Ten krok tworzy plik dziennika o nazwie
amlogs.txtw formacie tekstowym.yarn logs -applicationId <application_id> -am ALL > amlogs.txtPobierz dzienniki kontenera usługi Yarn tylko dla najnowszego głównego sterownika aplikacji za pomocą następującego polecenia:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtPobierz dzienniki kontenera YARN dla dwóch pierwszych głównych procesów aplikacji za pomocą następującego polecenia:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtPobierz wszystkie dzienniki kontenera usługi Yarn za pomocą następującego polecenia:
yarn logs -applicationId <application_id> > logs.txtPobierz dzienniki kontenera Yarn dla określonego kontenera używając następującego polecenia:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
Interfejs użytkownika usługi YARN ResourceManager
Interfejs użytkownika usługi YARN ResourceManager działa na węźle głównym klastra. Dostęp do niego jest uzyskiwany za pośrednictwem internetowego interfejsu użytkownika systemu Ambari. Aby wyświetlić dzienniki usługi YARN, wykonaj następujące czynności:
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net. Zastąp CLUSTERNAME nazwą klastra usługi HDInsight:Z listy usług po lewej stronie wybierz pozycję YARN.
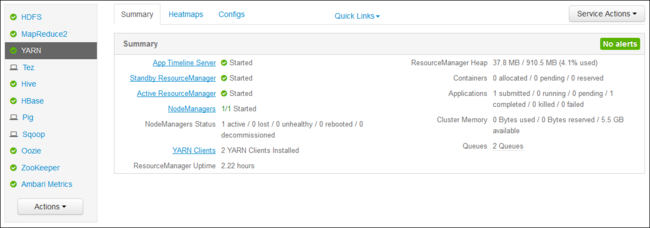
Z listy rozwijanej Szybkie linki wybierz jeden z węzłów głównych klastra, a następnie wybierz pozycję
ResourceManager Log.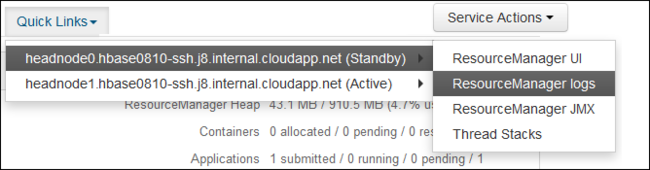
Zostanie wyświetlona lista linków do dzienników usługi YARN.