Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Apache Hadoop zawiera dwa podstawowe składniki: rozproszony system plików Apache Hadoop (HDFS), który zapewnia magazyn, i Apache Hadoop Jeszcze inny negocjator zasobów (YARN), który zapewnia przetwarzanie. Dzięki możliwościom magazynowania i przetwarzania klaster może uruchamiać programy MapReduce w celu wykonania żądanego przetwarzania danych.
Uwaga
System plików HDFS nie jest zwykle wdrażany w klastrze usługi HDInsight w celu zapewnienia magazynu. Zamiast tego warstwa interfejsu zgodna z systemem plików HDFS jest używana przez składniki platformy Hadoop. Rzeczywista możliwość magazynowania jest zapewniana przez usługę Azure Storage lub Azure Data Lake Storage. W przypadku usługi Hadoop zadania MapReduce wykonywane w klastrze usługi HDInsight działają tak, jakby był obecny HDFS i dlatego nie wymagają żadnych zmian do obsługi ich potrzeb dotyczących przechowywania. W Hadoop na HDInsight, magazyn jest zewnętrzny, ale przetwarzanie YARN pozostaje podstawowym składnikiem. Aby uzyskać więcej informacji, zobacz wprowadzenie do usługi Azure HDInsight.
W tym artykule przedstawiono usługę YARN i sposób koordynowania wykonywania aplikacji w usłudze HDInsight.
Podstawy usługi Apache Hadoop YARN
Usługa YARN zarządza i organizuje przetwarzanie danych w usłudze Hadoop. Usługa YARN ma dwa podstawowe usługi, które działają jako procesy w węzłach w klastrze:
- ResourceManager
- NodeManager
Menedżer zasobów przydziela zasoby obliczeniowe klastra aplikacjom, takie jak zadania MapReduce. Menedżer zasobów przyznaje te zasoby jako kontenery, w których każdy kontener składa się z alokacji rdzeni procesora CPU i pamięci RAM. W przypadku połączenia wszystkich zasobów dostępnych w klastrze, a następnie dystrybucji rdzeni i pamięci w blokach, każdy blok zasobów jest kontenerem. Każdy węzeł w klastrze ma pojemność dla określonej liczby kontenerów, dlatego klaster ma stały limit liczby dostępnych kontenerów. Przydzielanie zasobów w kontenerze można skonfigurować.
Gdy aplikacja MapReduce działa w klastrze, menedżer zasobów udostępnia aplikacji kontenery, w których ma zostać wykonana. Menedżer zasobów śledzi stan uruchomionych aplikacji, dostępną pojemność klastra oraz monitoruje aplikacje, gdy zakończą działanie i zwolnią swoje zasoby.
Menedżer zasobów uruchamia również proces serwera internetowego, który udostępnia internetowy interfejs użytkownika do monitorowania stanu aplikacji.
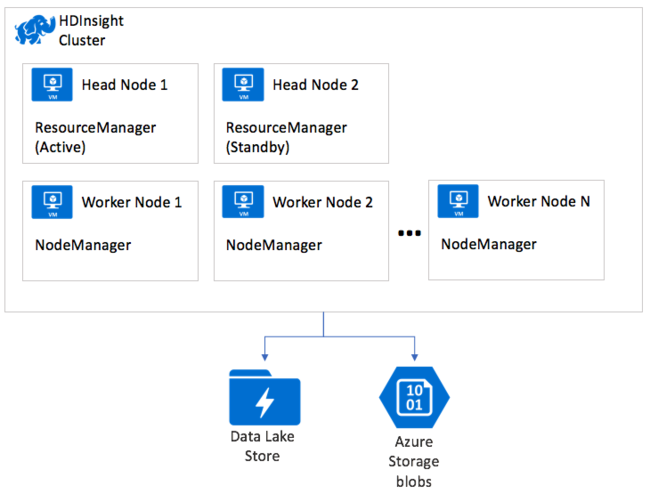
Gdy użytkownik przesyła aplikację MapReduce do uruchomienia w klastrze, aplikacja jest przesyłana do menedżera zasobów. Z kolei menedżer zasobów przydziela kontener w dostępnych węzłach NodeManager. Węzły NodeManager to miejsce, w którym aplikacja rzeczywiście jest wykonywana. Pierwszy przydzielony kontener uruchamia specjalną aplikację o nazwie ApplicationMaster. Ten program ApplicationMaster jest odpowiedzialny za pozyskiwanie zasobów w postaci kolejnych kontenerów potrzebnych do uruchomienia przesłanej aplikacji. ApplicationMaster analizuje etapy aplikacji, takie jak etap mapy i etap redukcji, oraz czynniki dotyczące ilości danych, które należy przetworzyć. Następnie ApplicationMaster żąda (negocjuje) zasobów z usługi ResourceManager w imieniu aplikacji. Menedżer zasobów z kolei przyznaje zasoby z węzłów zarządzających w klastrze do ApplicationMaster do wykorzystania podczas wykonywania aplikacji.
NodeManagerzy uruchamiają zadania, które tworzą aplikację, a następnie zgłaszają postęp i stan do ApplicationMaster. ApplicationMaster z kolei zgłasza stan aplikacji z powrotem do ResourceManager. Menedżer zasobów zwraca wszystkie wyniki do klienta.
Usługa YARN w usłudze HDInsight
Wszystkie typy klastrów usługi HDInsight wdrażają usługę YARN. Menedżer zasobów jest wdrażany pod kątem wysokiej dostępności z wystąpieniem podstawowym i pomocniczym, które jest uruchamiane odpowiednio w pierwszych i drugich węzłach głównych w klastrze. Tylko jedno wystąpienie usługi ResourceManager jest aktywne w danym momencie. Instancje NodeManager działają na dostępnych węzłach roboczych w klastrze.
Usunięcie miękkie
Aby przywrócić plik z konta Storage Account, zobacz:
Azure Storage
- Tymczasowe usuwanie dla obiektów Blob w usłudze Azure Storage
- Przywróć usunięty obiekt blob
Azure Data Lake Storage Gen 1
Restore-AzDataLakeStoreDeletedItem
Azure Data Lake Storage Gen 2
znane problemy z usługą Azure Data Lake Storage Gen2
Przeczyszczanie kosza
Właściwość fs.trash.interval z HDFS>Advanced core-site powinna pozostać na wartości domyślnej 0, ponieważ nie należy przechowywać żadnych danych w lokalnym systemie plików. Ta wartość nie ma wpływu na konta magazynu zdalnego (WASB, ADLS GEN1, ABFS)