Naprawianie błędu braku pamięci usługi Apache Hive w usłudze Azure HDInsight
Dowiedz się, jak naprawić błąd braku pamięci (OOM) apache Hive podczas przetwarzania dużych tabel, konfigurując ustawienia pamięci programu Hive.
Uruchamianie zapytania apache Hive względem dużych tabel
Klient uruchomił zapytanie Hive:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Niektóre niuanse tego zapytania:
- T1 to alias dla dużej tabeli TABLE1, która zawiera wiele typów kolumn STRING.
- Inne tabele nie są tak duże, ale mają wiele kolumn.
- Wszystkie tabele łączą się ze sobą, w niektórych przypadkach z wieloma kolumnami w tabeli TABLE1 i innych.
Wykonanie zapytania hive trwało 26 minut w 24 węźle A3 klastra usługi HDInsight. Klient zauważył następujące komunikaty ostrzegawcze:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Za pomocą aparatu wykonywania Apache Tez. To samo zapytanie trwało 15 minut, a następnie rzuciło następujący błąd:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
Błąd pozostaje podczas korzystania z większej maszyny wirtualnej (na przykład D12).
Debugowanie błędu braku pamięci
Nasze zespoły pomocy technicznej i inżynieryjne razem wykazały, że jednym z problemów powodujących błąd braku pamięci był znany problem opisany w usłudze Apache JIRA:
"Gdy hive.auto.convert.join.noconditionaltask = true sprawdzamy wartość noconditionaltask.size i jeśli suma rozmiarów tabel w sprzężeniu mapy jest mniejsza niż noconditionaltask.size, plan wygenerowałby sprzężenia mapy, Problem polega na tym, że obliczenie nie uwzględnia narzutów wprowadzonych przez inną implementację funkcji HashTable jako wyniki, jeśli suma rozmiarów danych wejściowych jest mniejsza niż rozmiar noconditionaltask przez zapytania z małym marginesem trafi na OOM.
Plik hive.auto.convert.join.noconditionaltask w pliku hive-site.xml został ustawiony na wartość true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Prawdopodobnie sprzężenia mapy były przyczyną błędu stosu Java Heap Space z pamięci. Jak wyjaśniono we wpisie w blogu, ustawienia pamięci usługi Hadoop Yarn w usłudze HDInsight, gdy aparat wykonywania tez jest używany obszar sterty używany rzeczywiście należy do kontenera Tez. Zobacz poniższą ilustrację opisującą pamięć kontenera Tez.
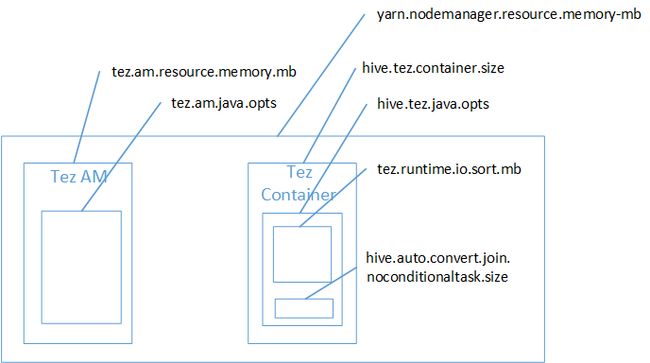
Jak sugeruje wpis w blogu, następujące dwa ustawienia pamięci definiują pamięć kontenera dla sterty: hive.tez.container.size i hive.tez.java.opts. Z naszego doświadczenia wyjątek braku pamięci nie oznacza, że rozmiar kontenera jest zbyt mały. Oznacza to, że rozmiar sterty Java (hive.tez.java.opts) jest za mały. Więc za każdym razem, gdy widzisz brak pamięci, możesz spróbować zwiększyć hive.tez.java.opts. W razie potrzeby może być konieczne zwiększenie rozmiaru hive.tez.container.size. Ustawienie java.opts powinno wynosić około 80% rozmiaru kontenera.
Uwaga
Ustawienie hive.tez.java.opts musi być zawsze mniejsze niż hive.tez.container.size.
Ponieważ maszyna D12 ma 28 GB pamięci, postanowiliśmy użyć rozmiaru kontenera o rozmiarze 10 GB (10240 MB) i przypisać 80% do środowiska java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Po nowych ustawieniach zapytanie pomyślnie uruchomiono w ciągu 10 minut.
Następne kroki
Wyświetlenie błędu OOM nie musi oznaczać, że rozmiar kontenera jest zbyt mały. Zamiast tego należy skonfigurować ustawienia pamięci, aby rozmiar sterty został zwiększony i wynosi co najmniej 80% rozmiaru pamięci kontenera. Aby zoptymalizować zapytania Hive, zobacz Optymalizowanie zapytań Apache Hive dla usługi Apache Hadoop w usłudze HDInsight.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla