Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
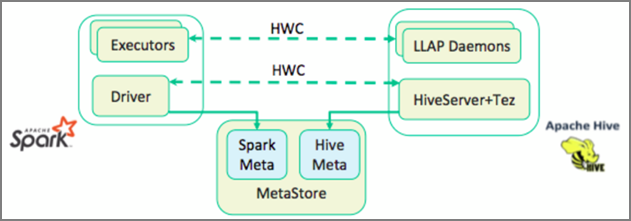
Łącznik usługi Apache Hive Warehouse (HWC) to biblioteka, która umożliwia łatwiejsze pracę z platformami Apache Spark i Apache Hive. Obsługuje zadania, takie jak przenoszenie danych między ramkami danych platformy Spark i tabelami Hive. Ponadto poprzez kierowanie danych przesyłanych strumieniowo platformy Spark do tabel programu Hive. Łącznik magazynu Hive działa jak most między platformą Spark i programem Hive. Obsługuje również język Scala, Java i Python jako języki programowania na potrzeby programowania.
Łącznik magazynu Hive umożliwia korzystanie z unikatowych funkcji technologii Hive i Spark w celu tworzenia zaawansowanych aplikacji danych big data.
Apache Hive oferuje obsługę transakcji bazy danych, które są niepodzielne, spójne, izolowane i trwałe (ACID). Aby uzyskać więcej informacji na temat acid i transakcji w usłudze Hive, zobacz Hive Transactions (Transakcje hive). Usługa Hive oferuje również szczegółowe mechanizmy kontroli zabezpieczeń za pośrednictwem platformy Apache Ranger i przetwarzania analitycznego o małych opóźnieniach (LLAP), które nie są dostępne na platformie Apache Spark.
Platforma Apache Spark ma interfejs API przesyłania strumieniowego ze strukturą, który zapewnia możliwości przesyłania strumieniowego niedostępne w usłudze Apache Hive. Począwszy od usług HDInsight 4.0, Apache Spark 2.3.1 i nowszych oraz Apache Hive 3.1.0 mają oddzielne wykazy magazynów metadanych, co utrudnia współdziałanie.
Łącznik magazynu Hive (HWC) ułatwia jednoczesne korzystanie z platform Spark i Hive. Biblioteka HWC ładuje dane z demonów LLAP do funkcji wykonawczych platformy Spark równolegle. Ten proces sprawia, że jest bardziej wydajny i dostosowywany niż standardowe połączenie JDBC z platformy Spark do programu Hive. Spowoduje to wyświetlenie dwóch różnych trybów wykonywania dla HWC:
- Tryb Hive JDBC za pośrednictwem serwera HiveServer2
- Tryb LLAP programu Hive przy użyciu demonów LLAP [Zalecane]
Domyślnie HWC jest skonfigurowany do używania demonów HIVe LLAP. Aby wykonać zapytania Hive (zarówno odczyt, jak i zapis) przy użyciu powyższych trybów z odpowiednimi interfejsami API, zobacz Interfejsy API HWC.
Niektóre operacje obsługiwane przez łącznik magazynu Hive to:
- Opisywanie tabeli
- Tworzenie tabeli dla danych w formacie ORC
- Wybieranie danych programu Hive i pobieranie ramki danych
- Zapisywanie ramki danych w usłudze Hive w partii
- Wykonywanie instrukcji aktualizacji programu Hive
- Odczytywanie danych tabeli z programu Hive, przekształcanie ich na platformie Spark i zapisywanie ich w nowej tabeli Programu Hive
- Zapisywanie ramki danych lub strumienia Spark w usłudze Hive przy użyciu technologii HiveStreaming
Konfiguracja łącznika magazynu Hive
Ważne
- Wystąpienie interaktywne HiveServer2 zainstalowane w klastrach pakietu Enterprise Security Platformy Spark 2.4 nie jest obsługiwane do użycia z łącznikiem magazynu Hive. Zamiast tego należy skonfigurować oddzielny klaster HiveServer2 Interactive do hostowania obciążeń interaktywnych HiveServer2. Konfiguracja łącznika magazynu Hive, która korzysta z pojedynczego klastra Spark 2.4, nie jest obsługiwana.
- Biblioteka łącznika magazynu Hive (HWC) nie jest obsługiwana w przypadku klastrów interakcyjnych zapytań, w których włączono funkcję zarządzania obciążeniami (WLM).
W scenariuszu, w którym masz tylko obciążenia platformy Spark i chcesz używać biblioteki HWC, upewnij się, że klaster zapytań interakcyjnych nie ma włączonej funkcji zarządzania obciążeniami (hive.server2.tez.interactive.queuekonfiguracja nie jest ustawiona w konfiguracjach programu Hive).
W przypadku scenariusza, w którym istnieją obciążenia platformy Spark (HWC) i obciążenia natywne LLAP, należy utworzyć dwa oddzielne klastry zapytań interakcyjnych z udostępnioną bazą danych magazynu metadanych. Jeden klaster dla natywnych obciążeń LLAP, w których można włączyć funkcję WLM w zależności od potrzeb, a drugi klaster tylko dla obciążenia HWC, w którym nie należy konfigurować funkcji WLM. Należy pamiętać, że można wyświetlić plany zasobów WLM z obu klastrów, nawet jeśli jest on włączony tylko w jednym klastrze. Nie wprowadzaj żadnych zmian w planach zasobów w klastrze, w którym funkcja WLM jest wyłączona, ponieważ może to mieć wpływ na funkcjonalność WLM w innym klastrze. - Mimo że platforma Spark obsługuje język przetwarzania R w celu uproszczenia analizy danych, biblioteka łącznika magazynu Hive (HWC) nie jest obsługiwana do użycia z językiem R. Aby wykonywać obciążenia HWC, można wykonywać zapytania z platformy Spark do programu Hive przy użyciu interfejsu API HiveWarehouseSession w stylu JDBC, który obsługuje tylko język Scala, Java i Python.
- Wykonywanie zapytań (zarówno odczytu, jak i zapisu) za pośrednictwem serwera HiveServer2 za pośrednictwem trybu JDBC nie jest obsługiwane w przypadku złożonych typów danych, takich jak Arrays/Struct/Map.
- HWC obsługuje zapisywanie tylko w formatach plików ORC. Zapisy inne niż ORC (np. formaty plików parquet i tekstowych) nie są obsługiwane za pośrednictwem HWC.
Łącznik magazynu Hive potrzebuje oddzielnych klastrów dla obciążeń spark i interakcyjnych zapytań. Wykonaj następujące kroki, aby skonfigurować te klastry w usłudze Azure HDInsight.
Obsługiwane typy klastrów i wersje
| Wersja HWC | Wersja platformy Spark | Wersja interactiveQuery |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interakcyjne zapytanie 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interakcyjne zapytanie 3.1 | HDI 5.0 |
Tworzenie klastrów
Utwórz klaster platformy Spark 4.0 usługi HDInsight z kontem magazynu i niestandardową siecią wirtualną platformy Azure. Aby uzyskać informacje na temat tworzenia klastra w sieci wirtualnej platformy Azure, zobacz Dodawanie usługi HDInsight do istniejącej sieci wirtualnej.
Utwórz klaster interaktywnego zapytania usługi HDInsight (LLAP) 4.0 z tym samym kontem magazynu i siecią wirtualną platformy Azure co klaster Spark.
Konfigurowanie ustawień HWC
Zbieranie informacji wstępnych
W przeglądarce internetowej przejdź do
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVElokalizacji LLAPCLUSTERNAME jest nazwą klastra interakcyjnego zapytań.Przejdź do pozycji Podsumowanie>Serwera HiveServer2 Interactive JDBC URL i zanotuj wartość. Wartość może być podobna do:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Przejdź do pozycji Configs>Advanced Advanced>hive-site>hive.zookeeper.quorum i zanotuj wartość . Wartość może być podobna do:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Przejdź do adresu Configs>Advanced General>>hive.metastore.uris i zanotuj wartość . Wartość może być podobna do:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Przejdź do pozycji Configs>Advanced Advanced>hive-interactive-site>hive.llap.daemon.service.hosts i zanotuj wartość . Wartość może być podobna do:
@llap0.
Konfigurowanie ustawień klastra Spark
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configslokalizacji CLUSTERNAME to nazwa klastra Apache Spark.Rozwiń węzeł Niestandardowe wartości spark2-defaults.
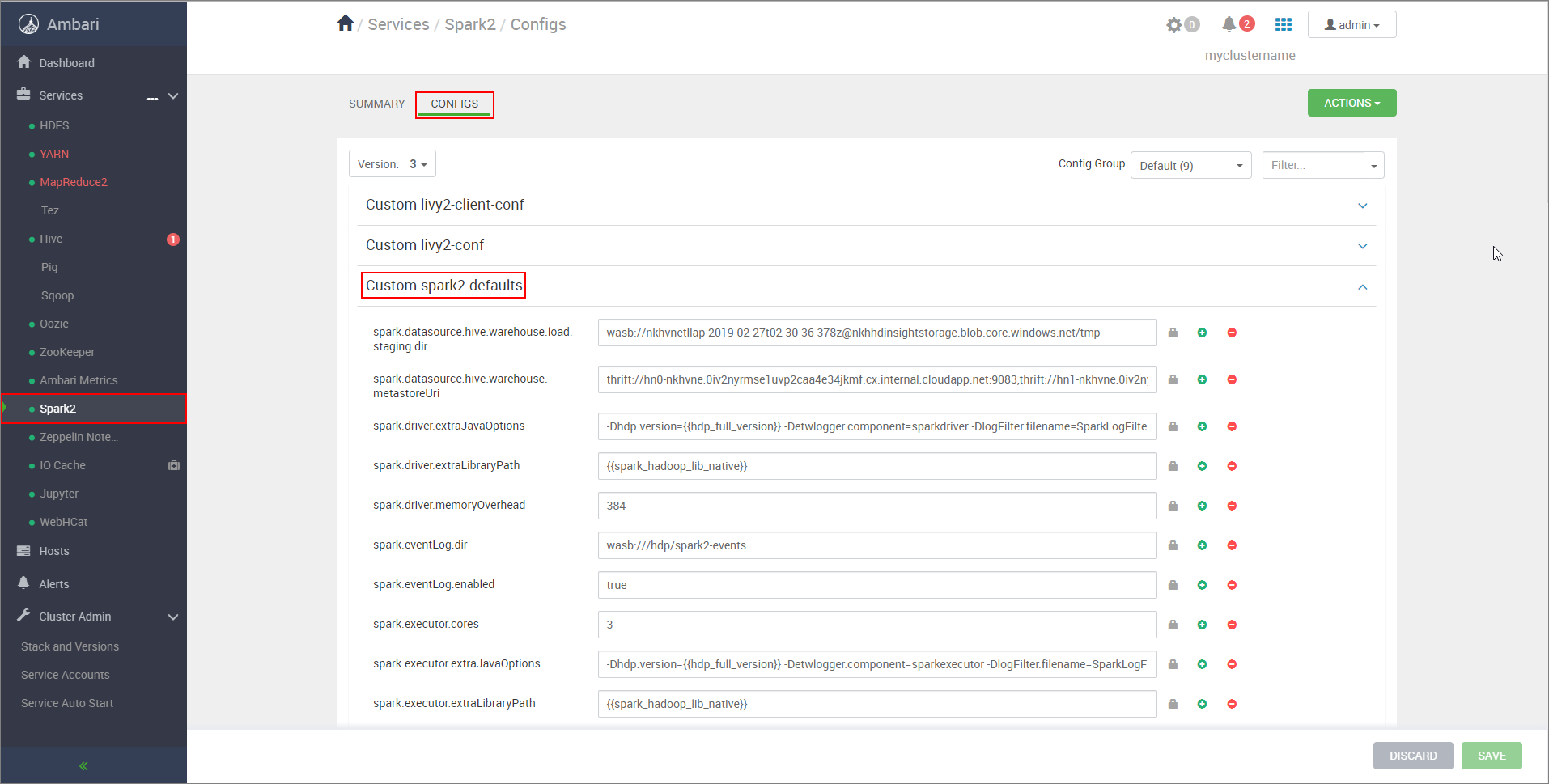
Wybierz pozycję Dodaj właściwość... aby dodać następujące konfiguracje:
Konfigurowanie Wartość spark.datasource.hive.warehouse.load.staging.dirJeśli używasz konta magazynu usługi ADLS Gen2, użyj polecenia abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Jeśli używasz konta usługi Azure Blob Storage, użyj poleceniawasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Ustaw odpowiedni katalog przejściowy zgodny z systemem plików HDFS. Jeśli masz dwa różne klastry, katalog przejściowy powinien być folderem w katalogu przejściowym konta magazynu klastra LLAP, aby serwer HiveServer2 miał do niego dostęp. ZastąpSTORAGE_ACCOUNT_NAMEciąg nazwą konta magazynu używanego przez klaster iSTORAGE_CONTAINER_NAMEnazwą kontenera magazynu.spark.sql.hive.hiveserver2.jdbc.urlWartość uzyskana wcześniej z adresu URL interaktywnego JDBC serwera HiveServer2 spark.datasource.hive.warehouse.metastoreUriWartość uzyskana wcześniej z hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtruedla trybu klastra YARN ifalsetrybu klienta YARN.spark.hadoop.hive.zookeeper.quorumWartość uzyskana wcześniej z hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsWartość uzyskana wcześniej z hive.llap.daemon.service.hosts. Zapisz zmiany i uruchom ponownie wszystkie objęte składniki.
Konfigurowanie serwera HWC dla klastrów pakietu Enterprise Security (ESP)
Pakiet Enterprise Security (ESP) zapewnia funkcje klasy korporacyjnej, takie jak uwierzytelnianie oparte na usłudze Active Directory, obsługa wielu użytkowników i kontrola dostępu oparta na rolach dla klastrów Apache Hadoop w usłudze Azure HDInsight. Aby uzyskać więcej informacji na temat esp, zobacz Use Enterprise Security Package in HDInsight (Korzystanie z pakietu Enterprise Security w usłudze HDInsight).
Oprócz konfiguracji wymienionych w poprzedniej sekcji dodaj następującą konfigurację, aby używać funkcji HWC w klastrach ESP.
W internetowym interfejsie użytkownika systemu Ambari klastra Spark przejdź do pozycji Spark2 CONFIGS Custom spark2-defaults>(Niestandardowe ustawienia spark2-defaults platformy Spark2).>
Zaktualizuj następującą właściwość.
Konfigurowanie Wartość spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summarylokalizacji clusterNAME to nazwa klastra interactive query. Kliknij pozycję HiveServer2 Interactive. Zobaczysz w pełni kwalifikowaną nazwę domeny (FQDN) węzła głównego, na którym działa llAP, jak pokazano na zrzucie ekranu. Zastąp<llap-headnode>wartość tą wartością.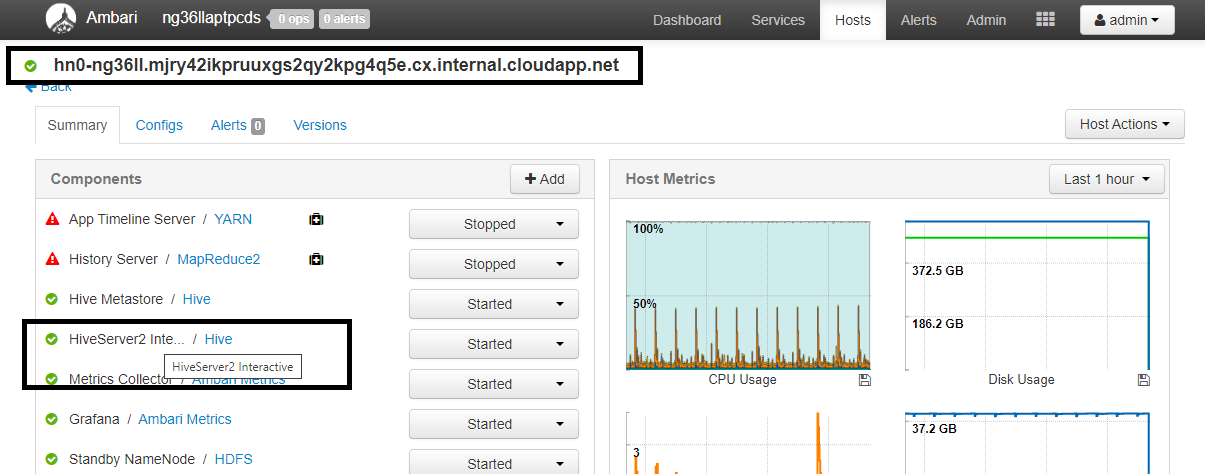
Użyj polecenia SSH, aby nawiązać połączenie z klastrem Interactive Query.
default_realmWyszukaj parametr w/etc/krb5.confpliku . Zastąp ciąg tą wartością wielkimi literami. W<AAD-DOMAIN>przeciwnym razie poświadczenie nie zostanie znalezione.
Przykład:
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Zapisz zmiany i uruchom ponownie składniki zgodnie z potrzebami.
Użycie łącznika magazynu Hive
Możesz wybrać między kilkoma różnymi metodami nawiązywania połączenia z klastrem interakcyjnych zapytań i wykonywać zapytania przy użyciu łącznika magazynu Hive. Obsługiwane metody obejmują następujące narzędzia:
Poniżej przedstawiono kilka przykładów nawiązywania połączenia z systemem HWC z platformy Spark.
Powłoka spark
Jest to sposób interaktywnego uruchamiania platformy Spark za pomocą zmodyfikowanej wersji powłoki Scala.
Użyj polecenia ssh, aby nawiązać połączenie z klastrem Apache Spark. Zmodyfikuj poniższe polecenie, zastępując ciąg CLUSTERNAME nazwą klastra, a następnie wprowadź polecenie:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netW sesji SSH wykonaj następujące polecenie, aby zanotować
hive-warehouse-connector-assemblywersję:ls /usr/hdp/current/hive_warehouse_connectorZmodyfikuj poniższy kod,
hive-warehouse-connector-assemblyaby wersję zidentyfikowaną powyżej. Następnie wykonaj polecenie , aby uruchomić powłokę spark:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falsePo uruchomieniu powłoki spark można uruchomić wystąpienie łącznika usługi Hive Warehouse przy użyciu następujących poleceń:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Przesyłanie na platformie Spark
Spark-submit to narzędzie do przesyłania dowolnego programu Spark (lub zadania) do klastrów Spark.
Zadanie przesyłania platformy Spark skonfiguruje i skonfiguruje łącznik Spark i Hive Warehouse zgodnie z naszymi instrukcjami, wykonaj przekazany program, a następnie oczyści zasoby, które były używane.
Po utworzeniu kodu scala/java wraz z zależnościami w pliku jar zestawu użyj poniższego polecenia, aby uruchomić aplikację Spark. Zastąp <VERSION>wartości i <APP_JAR_PATH> wartościami rzeczywistymi.
Tryb klienta usługi YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarTryb klastra YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
To narzędzie jest również używane, gdy napisaliśmy całą aplikację w narzędziu pySpark i spakowaliśmy do .py plików (Python), dzięki czemu możemy przesłać cały kod do klastra Spark w celu wykonania.
W przypadku aplikacji języka Python przekaż plik .py w miejscu /<APP_JAR_PATH>/myHwcAppProject.jar, a następnie dodaj poniższy plik konfiguracji (Python .zip) do ścieżki wyszukiwania za pomocą --py-filespolecenia .
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Uruchamianie zapytań w klastrach pakietu Enterprise Security (ESP)
Przed uruchomieniem powłoki spark lub spark-submit użyj kinit polecenia . Zastąp ciąg USERNAME nazwą konta domeny z uprawnieniami dostępu do klastra, a następnie wykonaj następujące polecenie:
kinit USERNAME
Zabezpieczanie danych w klastrach Spark ESP
Utwórz tabelę
demoz przykładowymi danymi, wprowadzając następujące polecenia:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Wyświetl zawartość tabeli za pomocą następującego polecenia. Przed zastosowaniem zasad tabela
demozawiera pełną kolumnę.hive.executeQuery("SELECT * FROM demo").show()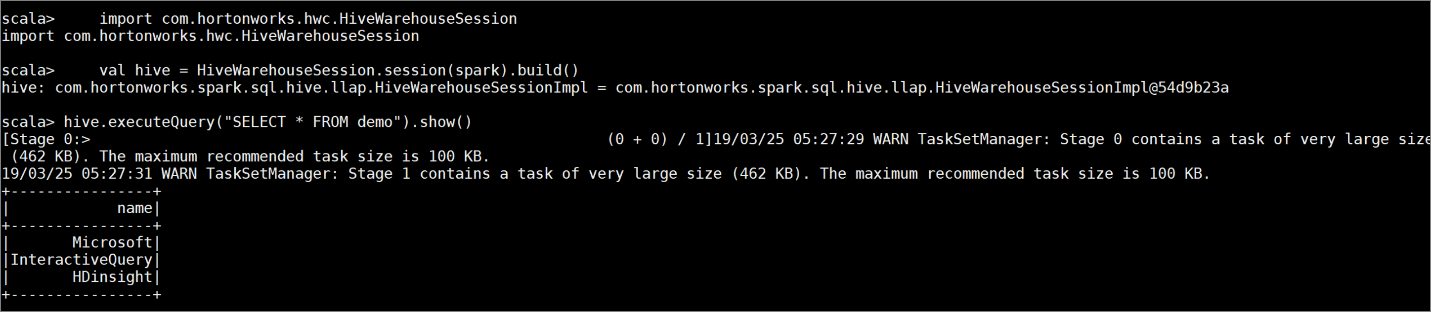
Zastosuj zasady maskowania kolumn, które wyświetlają tylko cztery ostatnie znaki kolumny.
Przejdź do interfejsu użytkownika administratora platformy Ranger pod adresem
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Kliknij usługę Hive dla klastra w obszarze Hive.
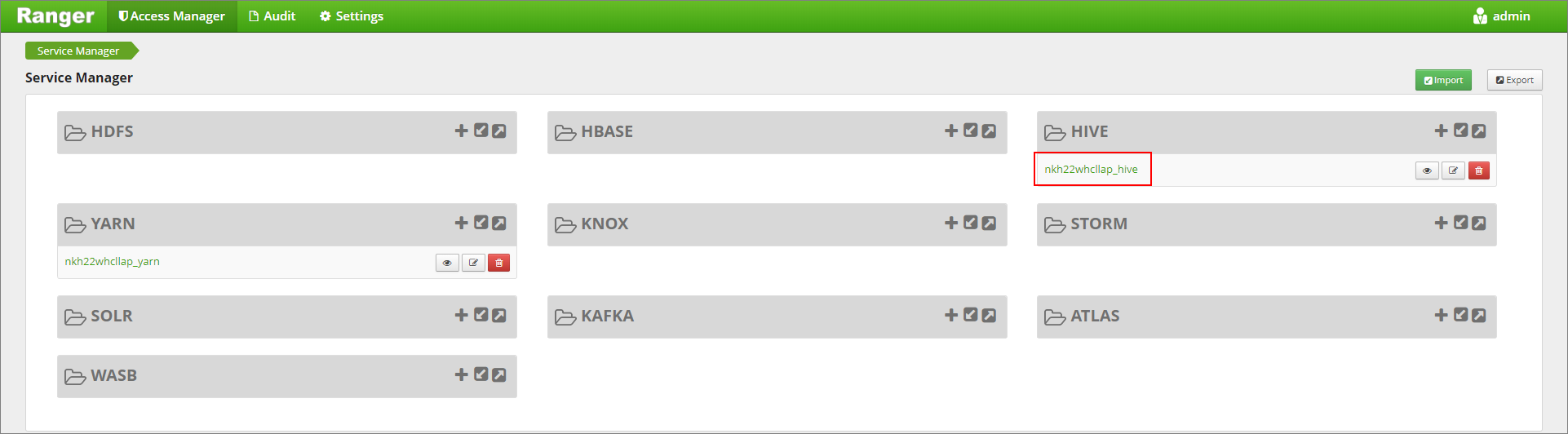
Kliknij kartę Maskowanie , a następnie pozycję Dodaj nowe zasady
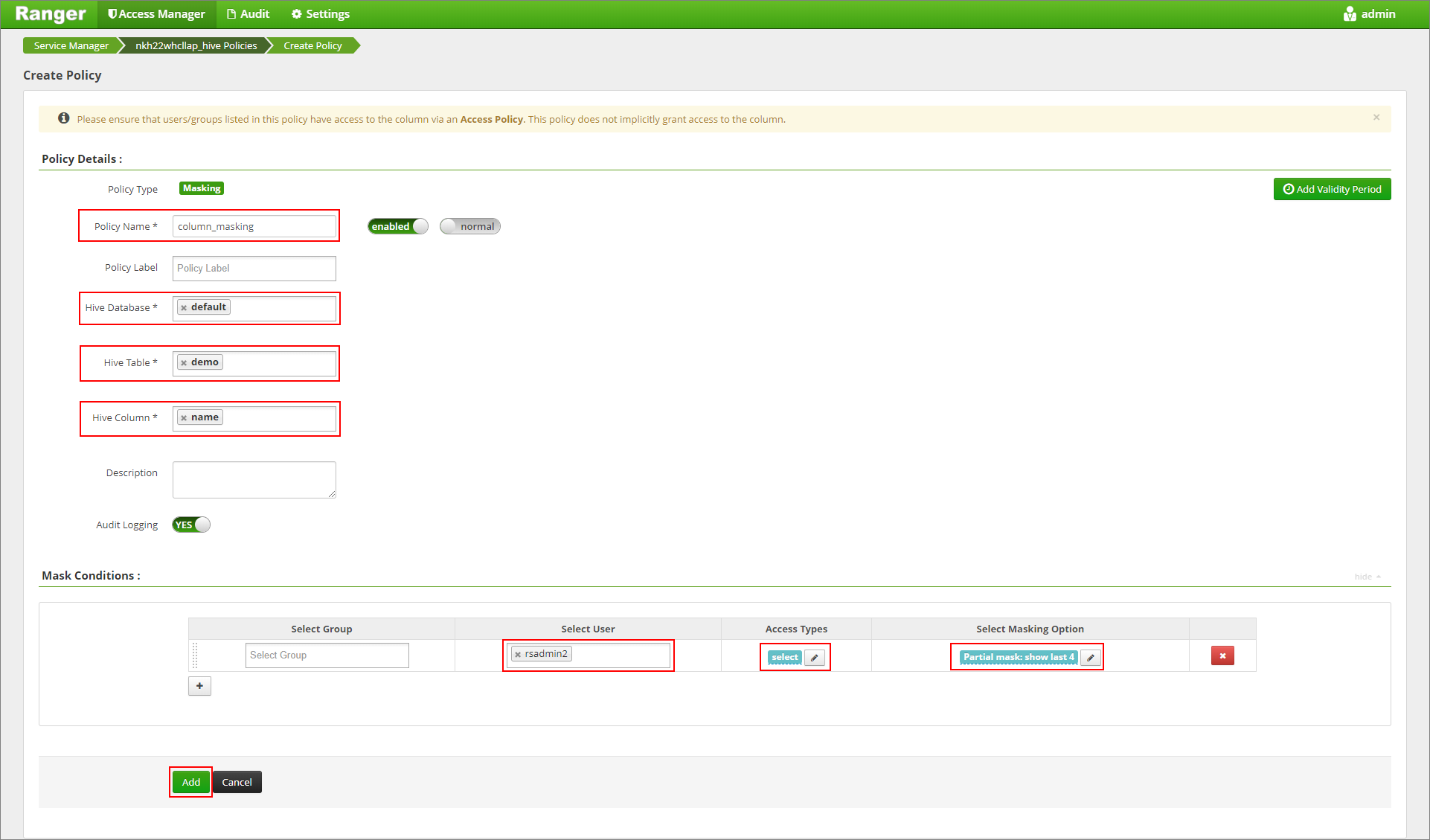
Podaj żądaną nazwę zasad. Wybierz bazę danych: domyślną, tabelę Programu Hive: demo, kolumnę Hive: name, User: rsadmin2, Access Types: select i Partial maska: show last 4 z menu Select Masking Option (Wybieranie opcji maskowania). Kliknij przycisk Dodaj.
Ponownie wyświetl zawartość tabeli. Po zastosowaniu zasad ranger możemy zobaczyć tylko cztery ostatnie znaki kolumny.
