Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Zapytanie interakcyjne (nazywane również apache Hive LLAP lub przetwarzaniem analitycznym o małych opóźnieniach) to typ klastra usługi Azure HDInsight. Zapytanie interakcyjne obsługuje buforowanie w pamięci, co sprawia, że zapytania Apache Hive są szybsze i bardziej interaktywne. Klienci używają zapytania interakcyjnego do wykonywania zapytań dotyczących danych przechowywanych w usłudze Azure Storage i Azure Data Lake Storage w bardzo szybki sposób. Interakcyjne zapytanie ułatwia deweloperom i analitykom danych pracę z danymi big data przy użyciu narzędzi analizy biznesowej, które najbardziej kochają. Zapytanie interakcyjne usługi HDInsight obsługuje kilka narzędzi umożliwiających łatwy dostęp do danych big data.
Klaster zapytań interakcyjnych różni się od klastra Apache Hadoop. Zawiera tylko usługę Hive.
Dostęp do usługi Hive można uzyskać w klastrze interaktywnych zapytań tylko za pośrednictwem widoku Apache Ambari Hive, Beeline oraz sterownika Microsoft Hive Open Database Connectivity (Hive ODBC). Nie można uzyskać do niego dostępu za pośrednictwem konsoli programu Hive, Templeton, klasycznego interfejsu wiersza polecenia platformy Azure ani programu Azure PowerShell.
Tworzenie klastra zapytań interakcyjnych
Aby uzyskać informacje na temat tworzenia klastra usługi HDInsight, zobacz Tworzenie klastrów Apache Hadoop w usłudze HDInsight. Wybierz typ klastra Interaktywnych zapytań.
Ważne
Minimalny rozmiar węzła głównego klastrów zapytań interakcyjnych jest Standard_D13_v2. Aby uzyskać więcej informacji, zobacz wykres ustalania rozmiaru maszyny wirtualnej platformy Azure.
Wykonywanie zapytań Apache Hive z zapytania interakcyjnego
Aby wykonać zapytania programu Hive, dostępne są następujące opcje:
Aby znaleźć parametry połączenia łączności bazy danych Java (JDBC):
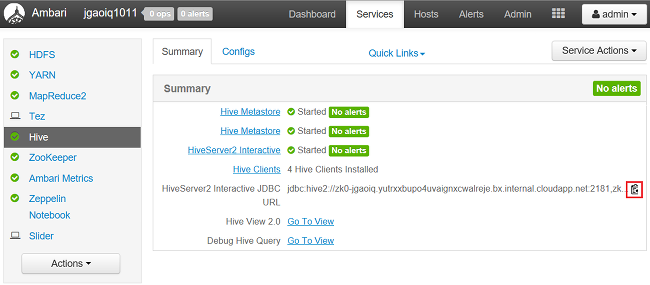
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, gdzieCLUSTERNAMEjest nazwą klastra.Aby skopiować adres URL, wybierz ikonę schowka:
Następne kroki
- Dowiedz się, jak tworzyć klastry zapytań interakcyjnych w usłudze HDInsight.
- Dowiedz się, jak wizualizować dane big data za pomocą usługi Power BI w usłudze Azure HDInsight.
- Dowiedz się, jak uruchamiać zapytania Apache Hive w usłudze Azure HDInsight za pomocą rozwiązania Apache Zeppelin.