Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Apache Kafka to rozproszona platforma przesyłania strumieniowego typu open source. Jest ona często używana jako broker komunikatów, ponieważ oferuje funkcje podobne do systemu publikowania i subskrybowania komunikatów.
Z tego przewodnika Szybki start dowiesz się, jak utworzyć klaster platformy Apache Kafka przy użyciu witryny Azure Portal. Dowiesz się także, jak używać dołączonych narzędzi do wysyłania i odbierania komunikatów na platformie Apache Kafka. Aby uzyskać szczegółowe wyjaśnienia dotyczące dostępnych konfiguracji, zobacz Konfigurowanie klastrów w usłudze HDInsight. Aby uzyskać dodatkowe informacje dotyczące korzystania z portalu do tworzenia klastrów, zobacz Tworzenie klastrów w portalu.
Ostrzeżenie
Rozliczenia dla klastrów usługi HDInsight są naliczane proporcjonalnie na minutę, niezależnie od tego, czy są używane. Pamiętaj, aby usunąć klaster po zakończeniu korzystania z niego. Zobacz , jak usunąć klaster usługi HDInsight.
Dostęp do interfejsu API platformy Apache Kafka mogą uzyskać tylko zasoby będące w tej samej sieci wirtualnej. W tym przewodniku szybkiego startu uzyskujesz dostęp do klastra bezpośrednio przy użyciu protokołu SSH. Aby do platformy Apache Kafka podłączyć inne usługi, sieci lub maszyny wirtualne, należy najpierw utworzyć sieć wirtualną, a następnie utworzyć zasoby w obrębie tej sieci. Aby uzyskać więcej informacji, zobacz dokument Connect to Apache Kafka using a virtual network (Nawiązywanie połączenia z platformą Apache Kafka za pomocą sieci wirtualnej). Aby uzyskać więcej ogólnych informacji na temat planowania sieci wirtualnych dla usługi HDInsight, zobacz Planowanie sieci wirtualnej dla usługi Azure HDInsight.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Klient SSH. Aby uzyskać więcej informacji, zobacz Łączenie się z usługą HDInsight (Apache Hadoop) przy użyciu protokołu SSH.
Tworzenie klastra platformy Apache Kafka
Aby utworzyć klaster platformy Apache Kafka w usłudze HDInsight, wykonaj następujące kroki:
Zaloguj się w witrynie Azure Portal.
W menu górnym wybierz pozycję + Utwórz zasób.
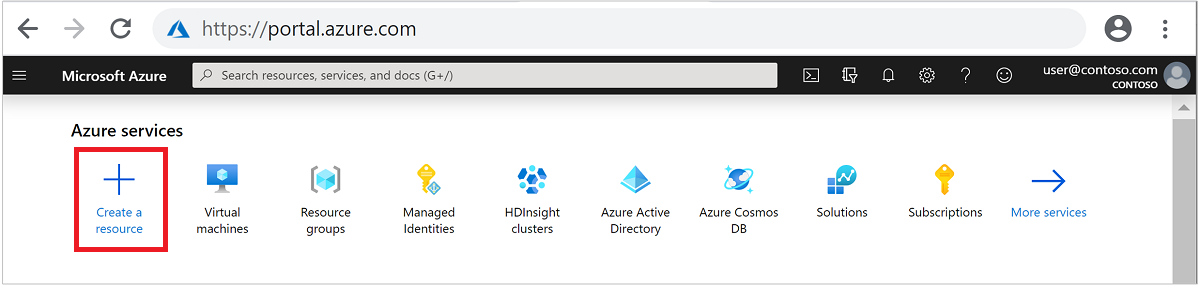
Wybierz Analiza>Azure HDInsight, aby przejść do strony Tworzenie klastra HDInsight.
Na karcie Podstawowe podaj następujące informacje:
Własność Opis Subskrypcja Z listy rozwijanej wybierz subskrypcję platformy Azure używaną dla klastra. Grupa zasobów Utwórz grupę zasobów lub wybierz istniejącą grupę zasobów. Grupa zasobów jest kontenerem składników platformy Azure. W tym przypadku grupa zasobów zawiera klaster usługi HDInsight i zależne konto usługi Azure Storage. Nazwa klastra Podaj globalnie unikatową nazwę. Nazwa może składać się z maksymalnie 59 znaków, w tym liter, cyfr i łączników. Łącznik nie może być pierwszym ani ostatnim znakiem nazwy. Region Z listy rozwijanej wybierz region, w którym jest tworzony klaster. Wybierz region bliżej Ciebie, aby uzyskać lepszą wydajność. Typ klastra Wybierz pozycję Wybierz typ klastra, aby otworzyć listę. Z listy wybierz Kafka jako typ klastra. Wersja Zostanie określona domyślna wersja dla typu klastra. Wybierz z listy rozwijanej, jeśli chcesz określić inną wersję. Nazwa użytkownika i hasło logowania do klastra Domyślna nazwa logowania to admin. Hasło musi mieć długość co najmniej 10 znaków i musi zawierać co najmniej jedną cyfrę, jedną wielką literę i jedną małą literę, jeden znak inny niż alfanumeryczny (z wyjątkiem znaków' ` "). Upewnij się, że nie udostępniasz typowych haseł, takich jakPass@word1.Nazwa użytkownika protokołu SSH (Secure Shell) Domyślna nazwa użytkownika to sshuser. Możesz podać inną nazwę użytkownika protokołu SSH.Używanie hasła logowania klastra dla protokołu SSH Zaznacz to pole wyboru, aby użyć tego samego hasła dla użytkownika SSH, który został podany dla użytkownika logowania klastra. 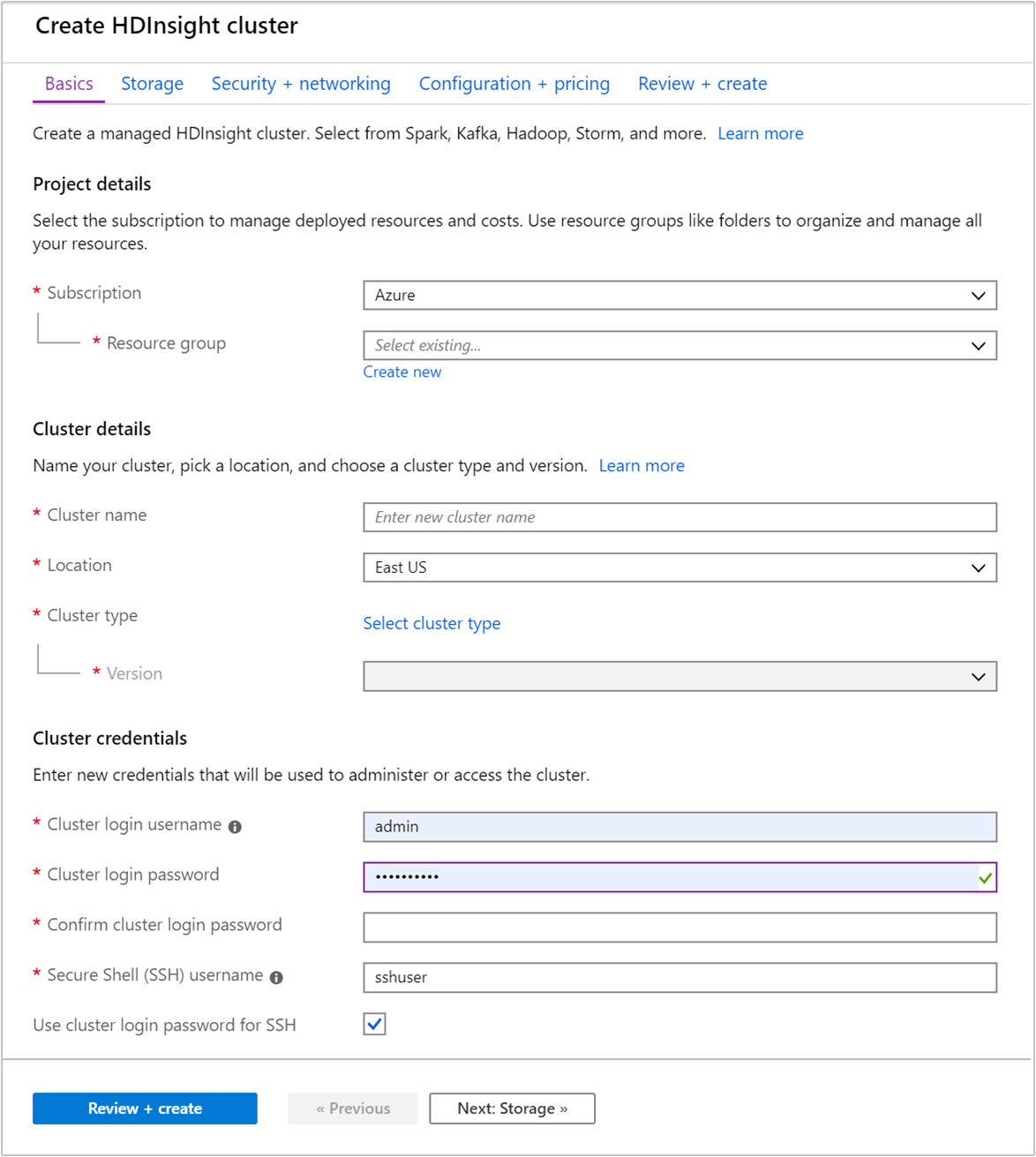
Każdy region (lokalizacja) świadczenia usługi Azure udostępnia domeny błędów. Domena błędów to logiczna grupa bazowego sprzętu w centrum danych platformy Azure. Wszystkie domeny błędów korzystają ze wspólnego źródła zasilania i przełącznika sieciowego. Maszyny wirtualne i dyski zarządzane, które implementują węzły w klastrze usługi HDInsight są rozdzielone między te domeny błędów. Taka architektura ogranicza wpływ potencjalnych awarii sprzętu fizycznego.
Aby zapewnić wysoką dostępność danych, wybierz region (lokalizację), który zawiera trzy domeny błędów. Aby uzyskać informacje dotyczące liczby domen błędów w regionie, zobacz dokument Availability of Linux virtual machines (Dostępność maszyn wirtualnych z systemem Linux).
Wybierz kartę Dalej: Magazyn >> , aby przejść do ustawień magazynu.
Na karcie Magazyn podaj następujące wartości:
Własność Opis Podstawowy typ magazynu Użyj domyślnej wartości Azure Storage. Metoda wybierania Użyj wartości domyślnej Wybierz z listy. Konto magazynu podstawowego Użyj listy rozwijanej, aby wybrać istniejące konto magazynowe lub wybierz Utwórz nowe. Jeśli tworzysz nowe konto, nazwa musi mieć długość od 3 do 24 znaków i może zawierać tylko cyfry i małe litery Kontener Użyj wartości wypełnionej automatycznie. 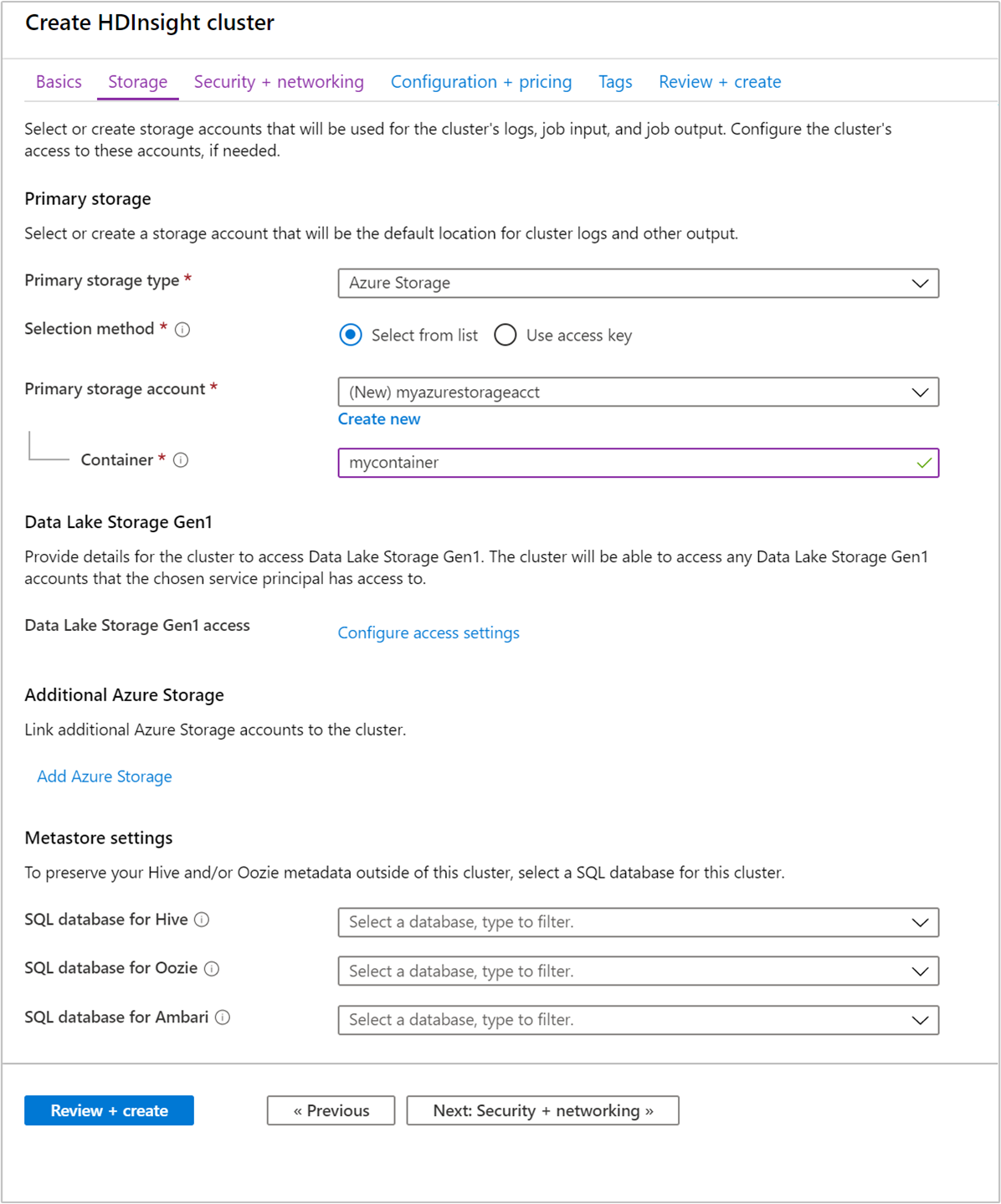
Wybierz kartę Zabezpieczenia i sieć .
W tym przewodniku Quickstart pozostaw domyślne ustawienia zabezpieczeń. Aby dowiedzieć się więcej o pakiecie Enterprise Security, odwiedź stronę Konfigurowanie klastra usługi HDInsight z pakietem Enterprise Security przy użyciu usług Microsoft Entra Domain Services. Aby dowiedzieć się, jak używać własnego klucza na potrzeby szyfrowania dysków platformy Apache Kafka, odwiedź stronę Szyfrowanie dysków klucza zarządzanego przez klienta
Jeśli chcesz połączyć klaster z siecią wirtualną, wybierz sieć wirtualną z listy rozwijanej Sieć wirtualna.
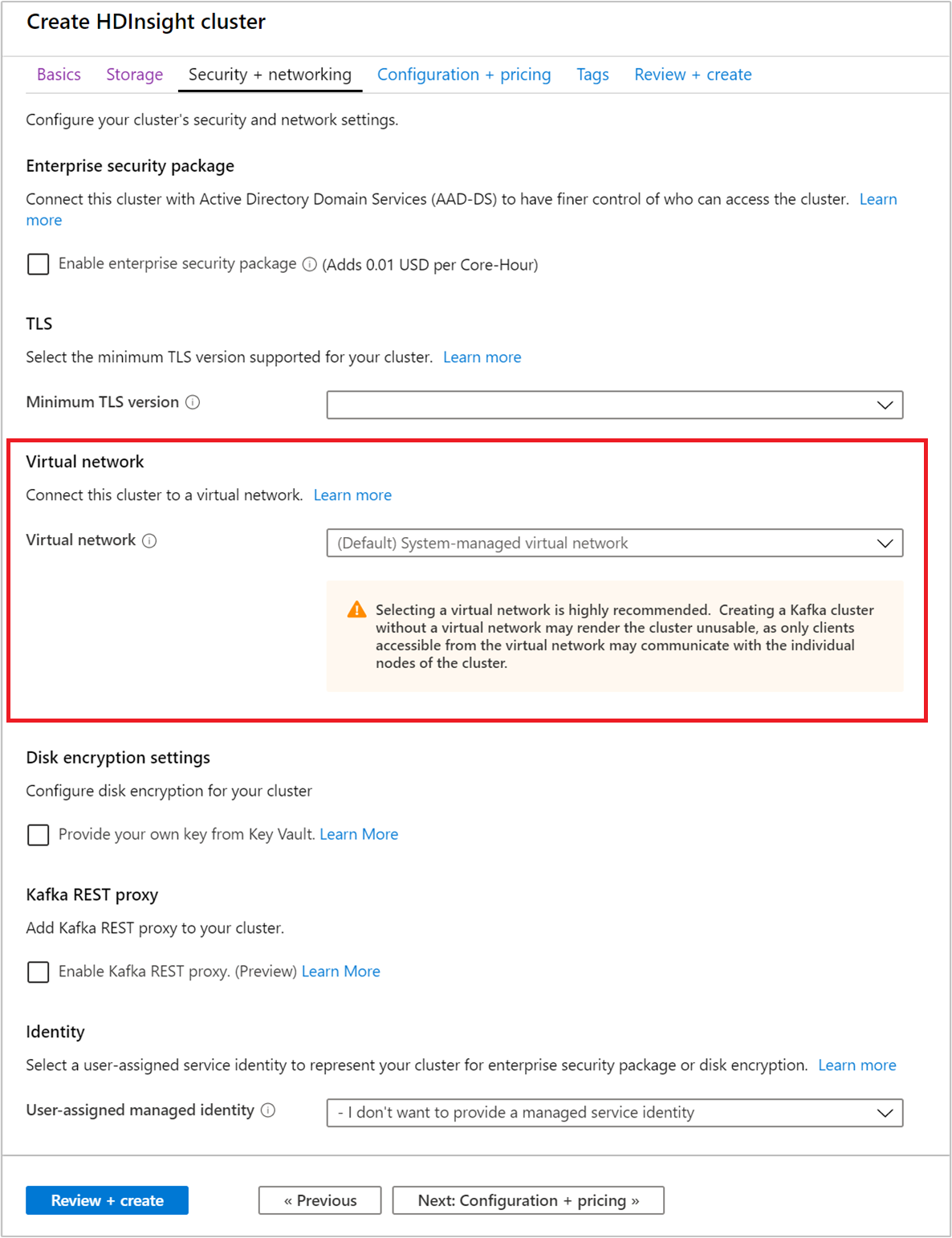
Wybierz kartę Konfiguracja i cennik .
Aby zagwarantować dostępność platformy Apache Kafka w usłudze HDInsight, liczba węzłów w węźle Roboczym musi być ustawiona na 3 lub większą. Wartość domyślna to 4.
Wpis Standardowe dyski na węzeł roboczy konfiguruje skalowalność platformy Apache Kafka w usłudze HDInsight. Do przechowywania danych platforma Apache Kafka w usłudze HDInsight używa dysku lokalnego maszyn wirtualnych w klastrze. Ze względu na duże obciążenie we/wy platformy Apache Kafka używana jest funkcja Dyski zarządzane platformy Azure, która zapewnia wysoką przepływność i więcej miejsca do magazynowania w każdym węźle. Można wybrać typ dysku zarządzanego Standardowy (HDD) lub Premium (SSD). Typ dysku zależy od rozmiaru maszyny wirtualnej używanej przez węzły robocze (brokery Apache Kafka). Dyski w warstwie Premium są używane automatycznie przez maszyny wirtualne serii DS i GS. Wszystkie pozostałe typy maszyn wirtualnych korzystają z dysków standardowych.
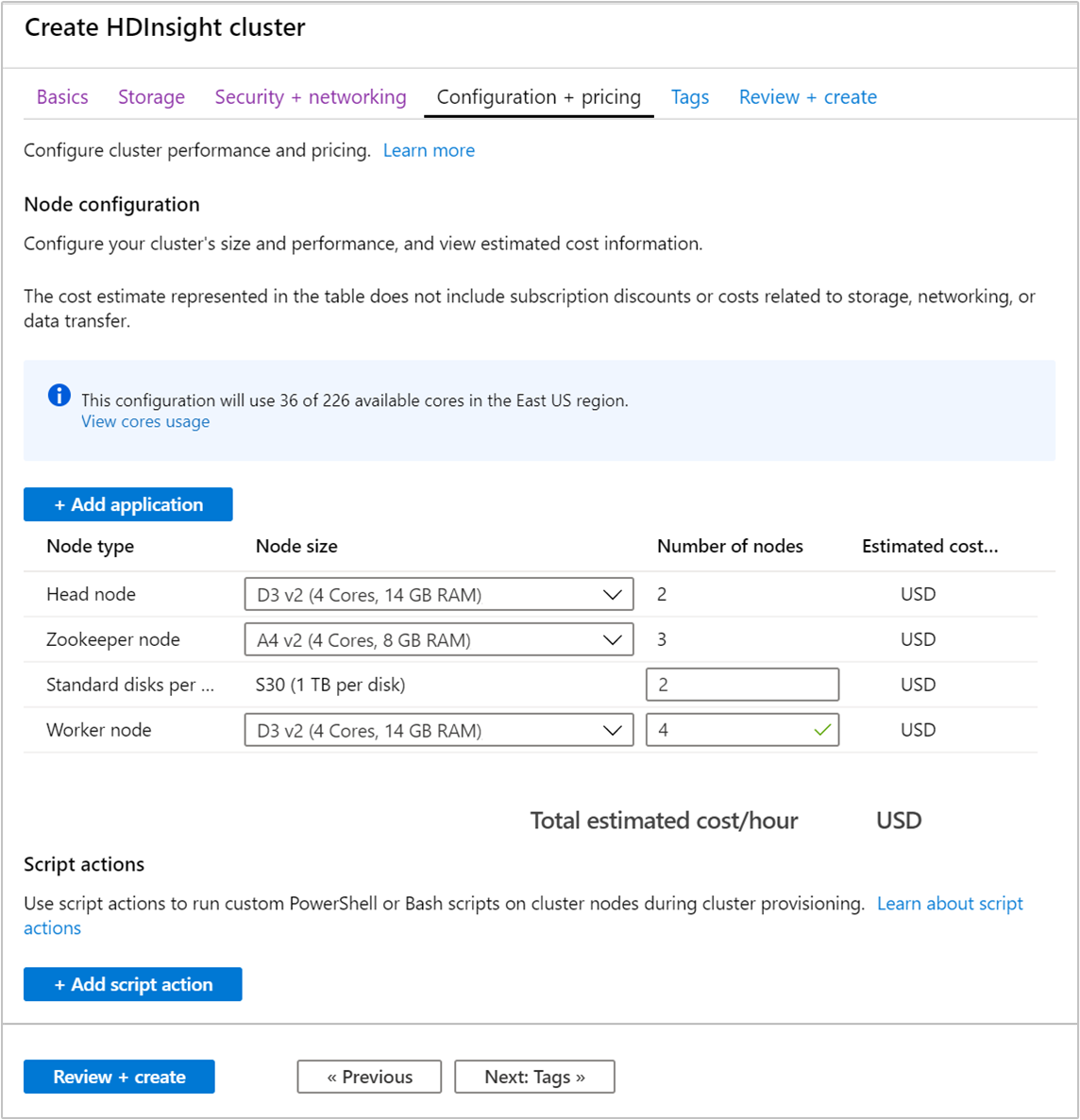
Wybierz kartę Przeglądanie i tworzenie .
Przejrzyj konfigurację klastra. Zmień wszystkie ustawienia, które są nieprawidłowe. Na koniec wybierz pozycję Utwórz , aby utworzyć klaster.
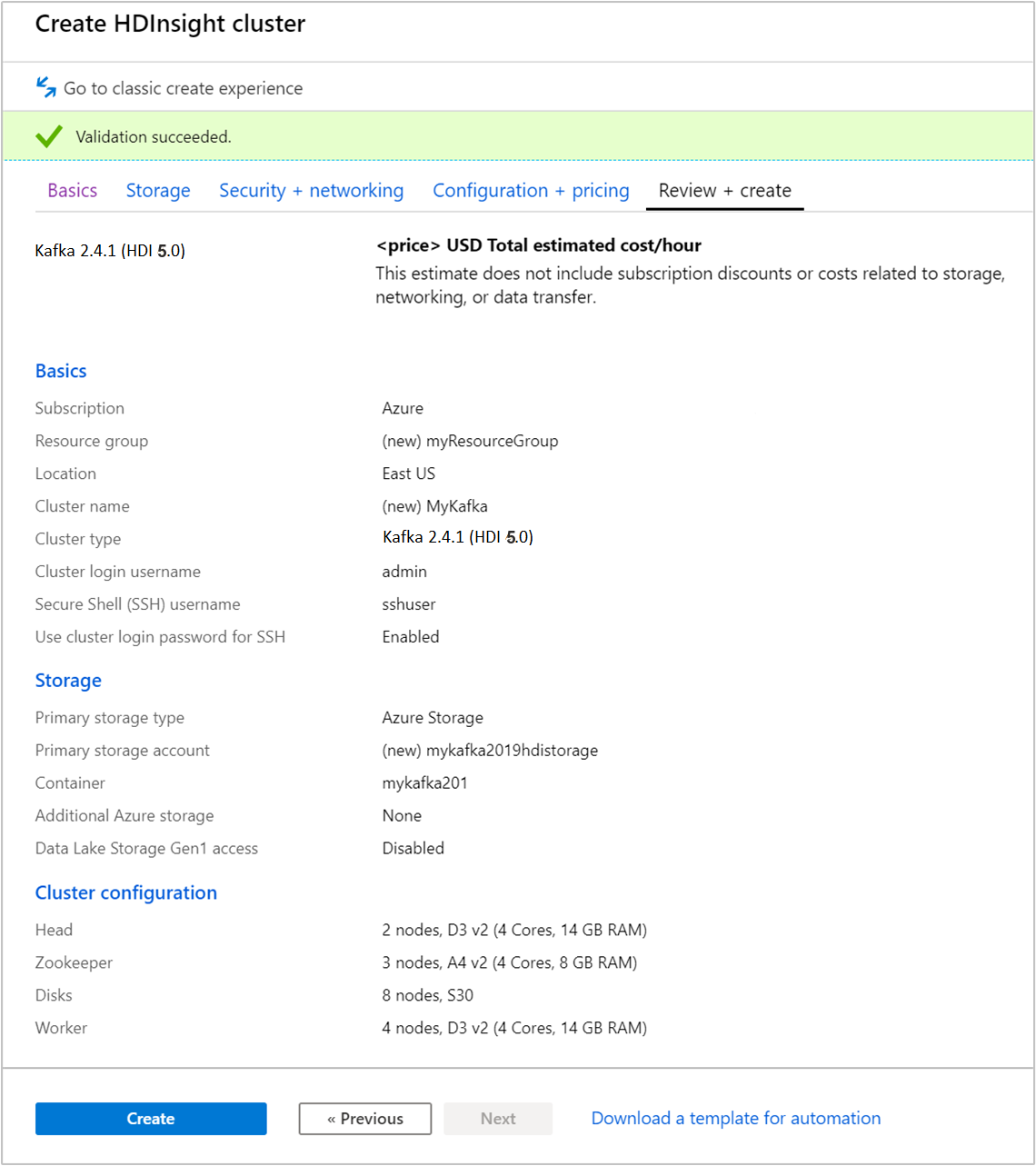
Tworzenie klastra może potrwać do 20 minut.
Łączenie z klastrem
Użyj polecenia ssh, aby nawiązać połączenie z klastrem. Zmodyfikuj poniższe polecenie, zastępując ciąg CLUSTERNAME nazwą klastra, a następnie wprowadź polecenie:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPo wyświetleniu monitu wprowadź hasło użytkownika SSH.
Po nawiązaniu połączenia zostanie wyświetlona informacja podobna do następującej:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Pobierz informacje dotyczących hostów Apache Zookeeper i Broker
Podczas pracy z platformą Kafka musisz znać hosty Apache Zookeeper i Broker. Te hosty są używane z interfejsem API platformy Apache Kafka i wieloma narzędziami oferowanymi z platformą Kafka.
W tej sekcji uzyskasz informacje o hoście z interfejsu API REST Apache Ambari w klastrze.
Zainstaluj jq, narzędzie do przetwarzania JSON w wierszu poleceń. To narzędzie służy do analizowania dokumentów JSON i jest przydatne podczas analizowania informacji o hoście. W otwartym połączeniu SSH wprowadź następujące polecenie, aby zainstalować program
jq:sudo apt -y install jqKonfigurowanie zmiennej hasła. Zastąp
PASSWORDhasłem do logowania klastra, a następnie wprowadź polecenie:export PASSWORD='PASSWORD'Wyodrębnij nazwę klastra z poprawnym formatowaniem wielkości liter. Rzeczywista wielkość liter nazwy klastra może być inna niż oczekiwano, w zależności od sposobu utworzenia klastra. To polecenie uzyska rzeczywistą wielkość liter, a następnie zapisze ją w zmiennej. Podaj następujące polecenie:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Uwaga
Jeśli wykonujesz ten proces spoza klastra, istnieje inna procedura przechowywania nazwy klastra. Uzyskaj nazwę klastra małymi literami z portalu Azure. Następnie zastąp nazwę klastra w następującym poleceniu
<clustername>i wykonaj je:export clusterName='<clustername>'.Aby ustawić zmienną środowiskową z informacjami o hoście usługi Zookeeper, użyj poniższego polecenia. Polecenie pobiera wszystkie hosty Zookeeper, a następnie zwraca tylko dwa pierwsze wpisy. Taka nadmiarowość jest wymagana, jeśli jeden z hostów będzie nieosiągalny.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Uwaga
To polecenie wymaga dostępu systemu Ambari. Jeśli klaster znajduje się za NSG, uruchom to polecenie z maszyny, która może uzyskać dostęp do systemu Ambari.
Aby sprawdzić, czy zmienna środowiskowa jest poprawnie ustawiona, użyj następującego polecenia:
echo $KAFKAZKHOSTSTo polecenie zwraca informacje podobne do następującego tekstu:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Aby ustawić zmienną środowiskową zawierającą informacje o hoście brokera Apache Kafka, użyj następującego polecenia:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Uwaga
To polecenie wymaga dostępu systemu Ambari. Jeśli klaster znajduje się za sieciową grupą zabezpieczeń, uruchom to polecenie z maszyny, która może uzyskać dostęp do systemu Ambari.
Aby sprawdzić, czy zmienna środowiskowa jest poprawnie ustawiona, użyj następującego polecenia:
echo $KAFKABROKERSTo polecenie zwraca informacje podobne do następującego tekstu:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Zarządzanie tematami platformy Apache Kafka
Platforma Kafka przechowuje strumienie danych w tematach. Tematami można zarządzać za pomocą narzędzia kafka-topics.sh.
Aby utworzyć temat, użyj następującego polecenia, korzystając z połączenia SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSTo polecenie łączy się z brokerem z użyciem informacji o hoście przechowywanych w
$KAFKABROKERS. Następnie tworzy ono temat platformy Apache Kafka o nazwie test.Dane przechowywane w tym temacie są podzielone między osiem partycji.
Każda partycja jest replikowana na trzech węzłach roboczych w klastrze.
Jeśli klaster został utworzony w regionie świadczenia usługi Azure, który udostępnia trzy domeny błędów, użyj współczynnika replikacji o wartości 3. W przeciwnym razie użyj współczynnika replikacji o wartości 4.
W regionach z trzema domenami błędów współczynnik replikacji o wartości 3 umożliwia rozmieszczenie replik w różnych domenach błędów. W regionach z dwoma domenami błędów współczynnik replikacji o wartości cztery umożliwia równomierne rozmieszczenie replik między domenami.
Aby uzyskać informacje dotyczące liczby domen błędów w regionie, zobacz dokument Availability of Linux virtual machines (Dostępność maszyn wirtualnych z systemem Linux).
Platforma Apache Kafka nie uwzględnia domen błędów platformy Azure. Przy tworzeniu replik partycji dla tematów, mogą one nie zostać prawidłowo rozmieszczone w celu zapewnienia wysokiej dostępności.
Aby zapewnić wysoką dostępność, użyj narzędzia do ponownego równoważenia partycji platformy Apache Kafka. To narzędzie należy uruchomić, korzystając z połączenia SSH z węzłem głównym klastra platformy Apache Kafka.
Aby zapewnić najwyższą dostępność danych na platformie Apache Kafka, należy stosować ponowne równoważenie replik partycji dla tematu, gdy:
Tworzysz nowy temat lub partycję
Skalujesz klaster w górę
Aby wyświetlić listę tematów, użyj następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSTo polecenie wyświetla listę dostępnych tematów w klastrze platformy Apache Kafka.
Aby usunąć temat, użyj następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSTo polecenie usuwa temat o nazwie
topicname.Ostrzeżenie
W przypadku usunięcia utworzonego wcześniej tematu
testkonieczne będzie jego ponowne utworzenie. Jest on używany w czynnościach opisanych w dalszej części tego dokumentu.
Aby uzyskać więcej informacji na temat poleceń dostępnych w narzędziu kafka-topics.sh, użyj następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Tworzenie i używanie rekordów
Platforma Kafka przechowuje rekordy w tematach. Rekordy są tworzone przez producentów i używane przez odbiorców. Producenci i odbiorcy komunikują się z usługą brokera platformy Kafka. Każdy węzeł roboczy w twoim klastrze HDInsight jest hostem brokera Apache Kafka.
Poniżej przedstawiono procedurę zapisywania rekordów w utworzonym wcześniej temacie testowym i odczytywania ich za pomocą odbiorcy:
Aby zapisać rekordy w temacie, użyj narzędzia
kafka-console-producer.sh, korzystając z połączenia SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testPo wykonaniu tego polecenia przejdziesz do pustego wiersza.
Wprowadź wiadomość tekstową do pustego wiersza, a następnie naciśnij klawisz Enter. Wprowadź w ten sposób kilka wiadomości, a następnie użyj kombinacji klawiszy Ctrl + C, aby powrócić do normalnego monitu. Każdy wiersz jest wysyłany do tematu usługi Apache Kafka jako oddzielny rekord.
Aby odczytać rekordy z tematu, użyj narzędzia
kafka-console-consumer.sh, korzystając z połączenia SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningTo polecenie umożliwia pobranie rekordów z tematu i ich wyświetlenie. Użycie
--from-beginninginformuje odbiorcę, by rozpocząć od początku strumienia, co umożliwia pobranie wszystkich rekordów.Jeśli korzystasz ze starszej wersji platformy Kafka, zastąp element
--bootstrap-server $KAFKABROKERSelementem--zookeeper $KAFKAZKHOSTS.Użyj klawiszy Ctrl+C, aby zatrzymać odbiorcę.
Producentów i odbiorców można również utworzyć programowo. Przykład korzystania z tego interfejsu API znajduje się w dokumencie Apache Kafka Producer and Consumer API with HDInsight (Interfejs API producenta i odbiorcy platformy Apache Kafka w usłudze HDInsight).
Czyszczenie zasobów
Aby wyczyścić zasoby utworzone w tym samouczku szybkiego startu, możesz usunąć grupę zasobów. Usunięcie grupy zasobów powoduje również usunięcie skojarzonego klastra usługi HDInsight i wszystkich innych zasobów skojarzonych z tą grupą zasobów.
Aby usunąć grupę zasobów za pomocą witryny Azure Portal:
- W witrynie Azure Portal rozwiń menu po lewej stronie, aby otworzyć menu usług, a następnie wybierz pozycję Grupy zasobów, aby wyświetlić listę grup zasobów.
- Znajdź grupę zasobów do usunięcia, a następnie kliknij prawym przyciskiem myszy przycisk Więcej (...) po prawej stronie listy.
- Wybierz pozycję Usuń grupę zasobów i potwierdź.
Ostrzeżenie
Usunięcie klastra platformy Apache Kafka w usłudze HDInsight powoduje usunięcie wszystkich danych przechowywanych na platformie Kafka.