Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Apache Kafka to rozproszona platforma przesyłania strumieniowego typu „open source”, która umożliwia tworzenie aplikacji i potoków danych przesyłania strumieniowego w czasie rzeczywistym. Ponadto platforma Kafka oferuje funkcję brokera komunikatów, która działa podobnie do kolejki komunikatów. Pozwala ona publikować i subskrybować w nazwanych strumieniach danych.
Konkretne cechy platformy Kafka w usłudze HDInsight są następujące:
Jest to usługa zarządzana, która zapewnia uproszczony proces konfiguracji. W wyniku powstaje konfiguracja przetestowana i obsługiwana przez firmę Microsoft.
Firma Microsoft gwarantuje 99,9% czasu sprawnego działania platformy Kafka zgodnie z Umową dotyczącą poziomu usług (SLA). Aby uzyskać więcej informacji, zobacz dokument HDInsight — umowa SLA.
Kafka używa dysków zarządzanych platformy Azure jako magazynu zapasowego. Funkcja Dyski zarządzane zapewnia do 16 TB pamięci masowej dla każdego brokera platformy Kafka. Aby uzyskać informacje dotyczące konfigurowania dysków zarządzanych na platformie Kafka w usłudze HDInsight, zobacz Increase scalability of Apache Kafka on HDInsight (Zwiększanie skalowalności platformy Apache Kafka w usłudze HDInsight).
Aby uzyskać więcej informacji o funkcji Dyski zarządzane, zobacz artykuł Funkcja Dyski zarządzane platformy Azure.
Platforma Kafka została zaprojektowana z myślą o jednowarstwowym widoku szafy. Platforma Azure rozdziela ten regał na dwa wymiary — domeny aktualizacji (UD) i domeny błędów (FD). Firma Microsoft udostępnia narzędzia, za pomocą których można ponownie zrównoważyć partycje i repliki platformy Kafka między domenami aktualizacji i błędów.
Aby uzyskać więcej informacji, zobacz High availability with Apache Kafka on HDInsight (Wysoka dostępność na platformie Apache Kafka w usłudze HDInsight).
Usługa HDInsight umożliwia zmianę liczby węzłów roboczych (które hostują brokerów Kafka) po utworzeniu klastra. Skalowanie w górę można wykonać z poziomu witryny Azure Portal, programu Azure PowerShell i innych interfejsów zarządzania platformy Azure. W przypadku platformy Kafka po wykonaniu operacji skalowania należy przeprowadzić ponowne równoważenie replik partycji. Ponowne równoważenie partycji umożliwia Kafka skorzystanie z nowej liczby węzłów roboczych.
Platforma Kafka usługi HDInsight nie obsługuje skalowania w dół ani nie zmniejsza liczby brokerów w klastrze. Jeśli zostanie podjęta próba zmniejszenia liczby węzłów, zwracany jest błąd
InvalidKafkaScaleDownRequestErrorCode.Aby uzyskać więcej informacji, zobacz High availability with Apache Kafka on HDInsight (Wysoka dostępność na platformie Apache Kafka w usłudze HDInsight).
Do monitorowania platformy Kafka w usłudze HDInsight można użyć dzienników usługi Azure Monitor. Dzienniki usługi Azure Monitor wydobywają informacje dotyczące maszyn wirtualnych, takie jak metryki dysków i kart sieciowych oraz metryki JMX z platformy Kafka.
Aby uzyskać więcej informacji, zobacz Analizowanie dzienników dla Apache Kafka na HDInsight.
Architektura platformy Apache Kafka w usłudze HDInsight
Poniższy diagram przedstawia typową konfigurację platformy Kafka korzystającą z grup konsumentów, partycjonowania i replikacji w celu zapewnienia równoległego odczytu zdarzeń przy zachowaniu odporności na uszkodzenia:
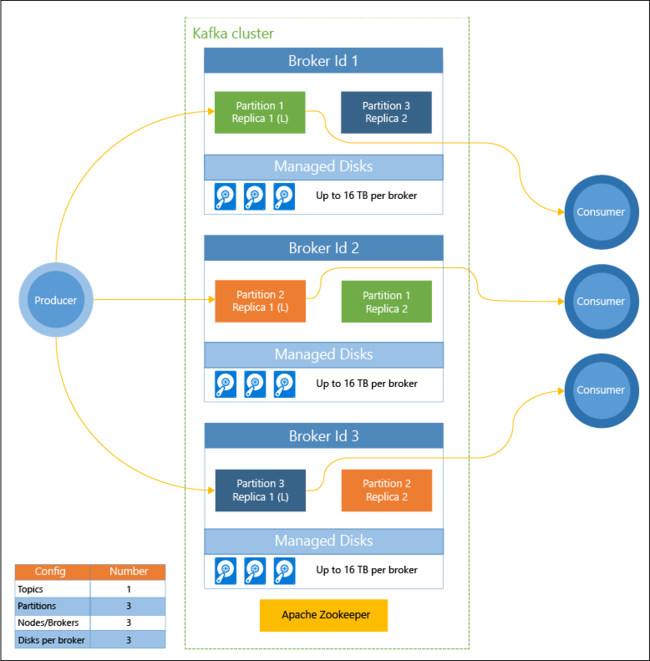
Usługa Apache ZooKeeper zarządza stanem klastra Kafka. Usługę Zookeeper zaprojektowano pod kątem obsługi jednoczesnych, odpornych transakcji o małych opóźnieniach.
Platforma Kafka przechowuje rekordy (dane) w tematach. Rekordy są tworzone przez producentów i używane przez odbiorców. Producenci wysyłają rekordy do brokerów platformy Kafka. Każdy węzeł roboczy w klastrze usługi HDInsight jest brokerem Kafka.
Tematy dzielą rekordy między brokerami. Podczas korzystania z rekordów można użyć maksymalnie jednego odbiorcy na jedną partycję, aby osiągnąć równoległe przetwarzanie danych.
Dzięki replikacji zapewniono duplikowanie partycji w węzłach, co gwarantuje ochronę przed awariami węzła (brokera). Partycja oznaczona symbolem (L) na diagramie jest wiodąca dla danej partycji. Ruch producenta jest kierowany do lidera każdego węzła przy użyciu stanu zarządzanego przez usługę ZooKeeper.
Dlaczego warto używać platformy Apache Kafka w usłudze HDInsight?
Poniżej przedstawiono typowe zadania i wzorce, które mogą być wykonywane przy użyciu platformy Kafka w usłudze HDInsight:
| Użycie | opis |
|---|---|
| Replikacja danych platformy Apache Kafka | platforma Kafka udostępnia narzędzie MirrorMaker, które replikuje dane między klastrami Kafka. Aby uzyskać informacje na temat używania narzędzia MirrorMaker, zobacz Replicate Apache Kafka topics with Apache Kafka on HDInsight (Replikowanie tematów platformy Apache Kafka na platformie Apache Kafka w usłudze HDInsight). |
| Wzorzec obsługi komunikatów publikowania i subskrybowania | Platforma Kafka udostępnia interfejs API producenta do publikowania rekordów w temacie Kafka. Interfejs API klienta jest używany podczas subskrybowania tematu. Aby uzyskać więcej informacji, zobacz Start with Apache Kafka on HDInsight (Rozpoczynanie pracy z platformą Apache Kafka w usłudze HDInsight). |
| Przetwarzanie strumieniowe | Platforma Kafka jest często używana z platformą Spark do przetwarzania strumienia w czasie rzeczywistym. Platforma Kafka 2.1.1 i 2.4.1 (HDInsight w wersji 4.0 i 5.0) obsługuje interfejsy API przesyłania strumieniowego, które umożliwiają tworzenie rozwiązań przesyłania strumieniowego bez konieczności używania platformy Spark. Aby uzyskać więcej informacji, zobacz Start with Apache Kafka on HDInsight (Rozpoczynanie pracy z platformą Apache Kafka w usłudze HDInsight). |
| Skala pozioma | Platforma Kafka dzieli strumienie na partycje, rozmieszczając je w węzłach klastra HDInsight. Procesy konsumenckie mogą być przypisane do poszczególnych partycji, aby umożliwić równoważenie obciążenia podczas przetwarzania rekordów. Aby uzyskać więcej informacji, zobacz Start with Apache Kafka on HDInsight (Rozpoczynanie pracy z platformą Apache Kafka w usłudze HDInsight). |
| Dostarczanie w zamówieniu | rekordy na każdej partycji są przechowywane w strumieniu w tej samej kolejności, w której zostały odebrane. Skojarzenie jednego procesu klienta z jedną partycją pozwala zagwarantować, że rekordy są przetwarzane we właściwej kolejności. Aby uzyskać więcej informacji, zobacz Start with Apache Kafka on HDInsight (Rozpoczynanie pracy z platformą Apache Kafka w usłudze HDInsight). |
| Wiadomości | platforma Kafka obsługuje wzorzec przesyłania komunikatów dotyczących publikowania i subskrybowania, dlatego jest często używana jako broker komunikatów. |
| Śledzenie działań | platforma Kafka rejestruje rekordy w określonej kolejności, dlatego może służyć do śledzenia i ponownego tworzenia działań. Mogą to być na przykład działania użytkownika w witrynie sieci Web lub aplikacji. |
| Agregacja | przetwarzanie strumienia pozwala agregować informacje z różnych strumieni w celu łączenia i centralizowania informacji w formie danych operacyjnych. |
| Przekształcenie | Wykorzystując przetwarzanie strumieniowe, możesz łączyć i wzbogacać dane z wielu tematów wejściowych, tworząc jeden lub więcej tematów wyjściowych. |
Następne kroki
Aby dowiedzieć się, jak korzystać z platformy Apache Kafka w usłudze HDInsight, użyj następujących linków: