Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym poradniku szybkiego startu użyjesz szablonu Azure Resource Manager (szablonu ARM) do utworzenia klastra Apache Kafka w usłudze Azure HDInsight. Kafka to rozproszona platforma przesyłania strumieniowego typu „open source”. Jest ona często używana jako broker komunikatów, ponieważ oferuje funkcje podobne do kolejki komunikatów dotyczących publikowania i subskrybowania.
Szablon usługi Azure Resource Manager to plik JavaScript Object Notation (JSON), który definiuje infrastrukturę i konfigurację projektu. W szablonie używana jest składnia deklaratywna. Możesz opisać zamierzone wdrożenie bez konieczności pisania sekwencji poleceń programowania w celu utworzenia wdrożenia.
Dostęp do interfejsu API platformy Kafka mogą uzyskać tylko zasoby będące w tej samej sieci wirtualnej. W tym szybkim starcie uzyskujesz dostęp do klastra bezpośrednio przy użyciu protokołu SSH. Aby do platformy Kafka podłączyć inne usługi, sieci lub maszyny wirtualne, należy najpierw utworzyć sieć wirtualną, a następnie utworzyć zasoby w obrębie tej sieci. Aby uzyskać więcej informacji, zobacz dokument Connect to Apache Kafka using a virtual network (Nawiązywanie połączenia z platformą Apache Kafka za pomocą sieci wirtualnej).
Jeśli Twoje środowisko spełnia wymagania wstępne i masz doświadczenie w korzystaniu z szablonów ARM, wybierz przycisk Wdróż na platformie Azure. Szablon zostanie otwarty w witrynie Azure Portal.

Wymagania wstępne
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Przegląd szablonu
Szablon używany w tym szybkim starcie pochodzi z szablonów szybkiego startu platformy Azure.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.26.54.24096",
"templateHash": "14433491779040889275"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the Kafka cluster to create. This must be a unique name."
}
},
"clusterLoginUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards."
}
},
"clusterLoginPassword": {
"type": "securestring",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to remotely access the cluster."
}
},
"sshPassword": {
"type": "securestring",
"minLength": 6,
"maxLength": 72,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"HeadNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"WorkerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the worerdnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"ZookeeperNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the Zookeepernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"variables": {
"defaultStorageAccount": {
"name": "[uniqueString(resourceGroup().id)]",
"type": "Standard_LRS"
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2023-01-01",
"name": "[variables('defaultStorageAccount').name]",
"location": "[parameters('location')]",
"sku": {
"name": "[variables('defaultStorageAccount').type]"
},
"kind": "StorageV2",
"properties": {
"minimumTlsVersion": "TLS1_2",
"supportsHttpsTrafficOnly": true,
"allowBlobPublicAccess": false
}
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2023-08-15-preview",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"clusterDefinition": {
"kind": "kafka",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(concat(reference(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name), '2021-08-01').primaryEndpoints.blob), 'https:', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('HeadNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 4,
"hardwareProfile": {
"vmSize": "[parameters('WorkerNodeVirtualMachineSize')]"
},
"dataDisksGroups": [
{
"disksPerNode": 2
}
],
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "zookeepernode",
"targetInstanceCount": 3,
"hardwareProfile": {
"vmSize": "[parameters('ZookeeperNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name)]"
]
}
],
"outputs": {
"name": {
"type": "string",
"value": "[parameters('clusterName')]"
},
"resourceId": {
"type": "string",
"value": "[resourceId('Microsoft.HDInsight/clusters', parameters('clusterName'))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')), '2023-08-15-preview')]"
},
"resourceGroupName": {
"type": "string",
"value": "[resourceGroup().name]"
},
"location": {
"type": "string",
"value": "[parameters('location')]"
}
}
}
Dwa zasoby platformy Azure są zdefiniowane w szablonie:
- Microsoft.Storage/storageAccounts: utwórz konto usługi Azure Storage.
- Microsoft.HDInsight/cluster: utwórz klaster usługi HDInsight.
Wdrażanie szablonu
Wybierz poniższy przycisk Wdróż na platformie Azure, aby zalogować się na platformie Azure i otworzyć szablon usługi ARM.
Wprowadź lub wybierz poniższe wartości:
Nieruchomość Opis Subskrypcja Z listy rozwijanej wybierz subskrypcję platformy Azure używaną dla klastra. Grupa zasobów Z listy rozwijanej wybierz istniejącą grupę zasobów lub wybierz pozycję Utwórz nową. Lokalizacja Wartość zostanie automatycznie uzupełniona lokalizacją używaną przez grupę zasobów. Nazwa klastra Podaj globalnie unikatową nazwę. W tym szablonie użyj tylko małych liter i cyfr. Nazwa użytkownika logowania klastra Podaj nazwę użytkownika, wartość domyślna to admin.Hasło logowania klastra Podaj hasło. Hasło musi mieć długość co najmniej 10 znaków i musi zawierać co najmniej jedną cyfrę, jedną wielką literę i jedną małą literę, znak inny niż alfanumeryczny (z wyjątkiem znaków ' ` ").Nazwa użytkownika SSH Podaj nazwę użytkownika, wartość domyślna to sshuser.Hasło SSH Podaj hasło. 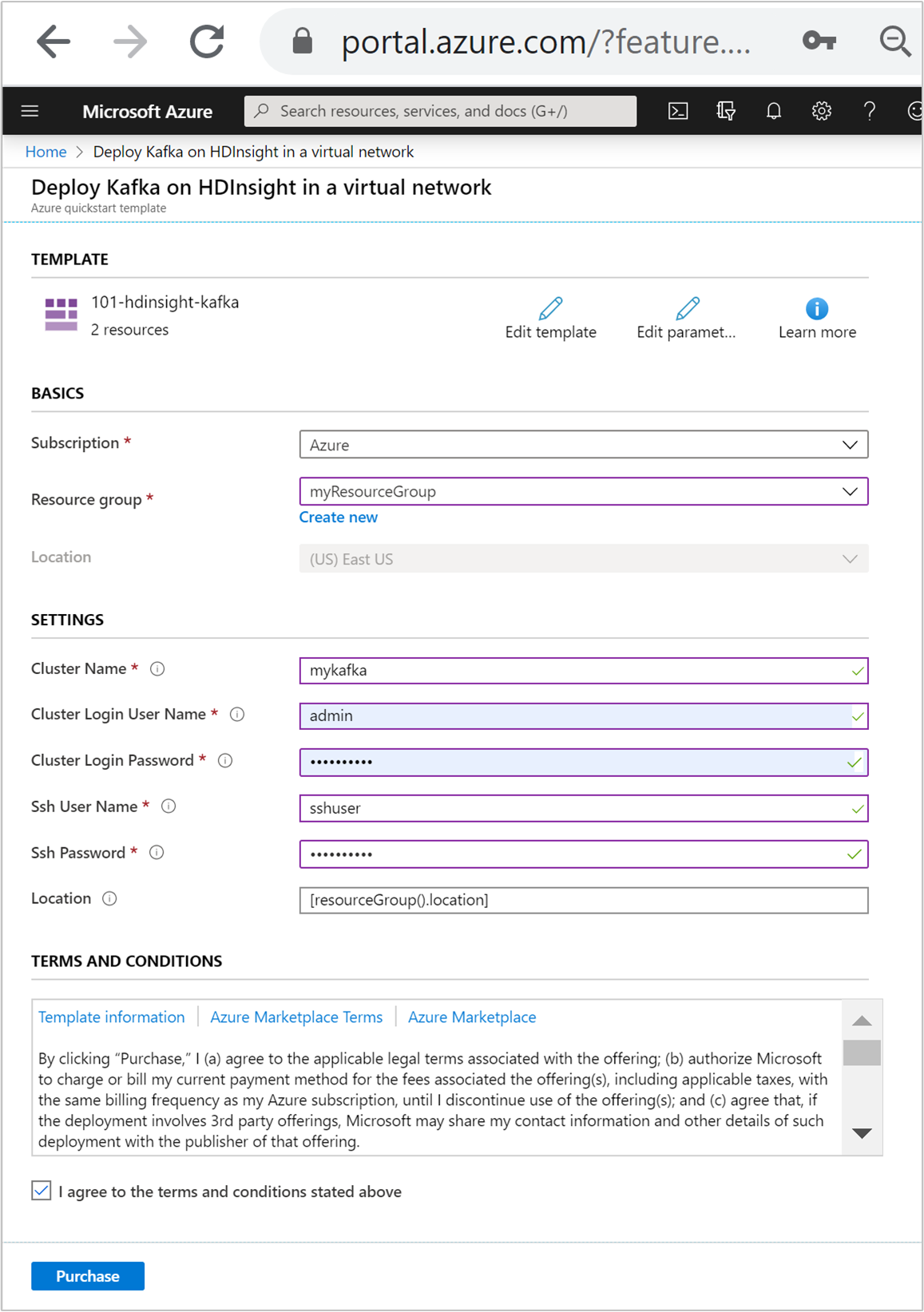
Zapoznaj się z warunkami i postanowieniami. Następnie wybierz pozycję Zgadzam się na powyższe warunki i postanowienia, a następnie pozycję Kup. Otrzymasz powiadomienie, że wdrożenie jest w toku. Utworzenie klastra trwa około 20 minut.
Przeglądanie wdrożonych zasobów
Po utworzeniu klastra otrzymasz powiadomienie Wdrożenie zakończyło się pomyślnie z linkiem Przejdź do zasobu . Strona grupy zasobów będzie zawierać listę nowego klastra usługi HDInsight oraz domyślny magazyn skojarzony z klastrem. Każdy klaster ma konto usługi Azure Blob Storage lub Azure Data Lake Storage Gen2 zależność. Jest to nazywane domyślnym kontem magazynu. Klaster usługi HDInsight i jego domyślne konto magazynu muszą być kolokowane w tym samym regionie świadczenia usługi Azure. Usunięcie klastrów nie powoduje usunięcia konta magazynu.
Pobierz informacje dotyczących hostów Apache Zookeeper i Broker
Podczas pracy z platformą Kafka musisz znać hosty Apache Zookeeper i Broker. Te hosty są używane z interfejsem API platformy Kafka i wieloma narzędziami oferowanymi z platformą Kafka.
W tej sekcji uzyskasz informacje o hoście z interfejsu API REST Ambari w klastrze.
Użyj polecenia ssh, aby nawiązać połączenie z klastrem. Zmodyfikuj poniższe polecenie, zastępując ciąg CLUSTERNAME nazwą klastra, a następnie wprowadź polecenie:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netZ poziomu połączenia SSH użyj następującego polecenia, aby zainstalować
jqnarzędzie. To narzędzie służy do analizowania dokumentów JSON i jest przydatne podczas pobierania informacji o hoście:sudo apt -y install jqAby ustawić zmienną środowiskową na nazwę klastra, użyj następującego polecenia:
read -p "Enter the Kafka on HDInsight cluster name: " CLUSTERNAMEPo wyświetleniu monitu wprowadź nazwę klastra Kafka.
Aby ustawić zmienną środowiskową z informacjami o hoście usługi Zookeeper, użyj poniższego polecenia. Polecenie pobiera wszystkie hosty Zookeepera, a następnie zwraca tylko dwa pierwsze wpisy. Taka nadmiarowość jest wymagana, jeśli jeden z hostów będzie nieosiągalny.
export KAFKAZKHOSTS=`curl -sS -u admin -G https://$CLUSTERNAME.azurehdinsight.net/api/v1/clusters/$CLUSTERNAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2`Po wyświetleniu monitu wprowadź hasło dla konta logowania klastra (nie dla konta SSH).
Aby sprawdzić, czy zmienna środowiskowa jest poprawnie ustawiona, użyj następującego polecenia:
echo '$KAFKAZKHOSTS='$KAFKAZKHOSTSTo polecenie zwraca informacje podobne do następującego tekstu:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Aby ustawić zmienną środowiskową z informacjami o hoście brokera Kafka, użyj następującego polecenia:
export KAFKABROKERS=`curl -sS -u admin -G https://$CLUSTERNAME.azurehdinsight.net/api/v1/clusters/$CLUSTERNAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2`Po wyświetleniu monitu wprowadź hasło dla konta logowania klastra (nie dla konta SSH).
Aby sprawdzić, czy zmienna środowiskowa jest poprawnie ustawiona, użyj następującego polecenia:
echo '$KAFKABROKERS='$KAFKABROKERSTo polecenie zwraca informacje podobne do następującego tekstu:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Zarządzanie tematami platformy Apache Kafka
Platforma Kafka przechowuje strumienie danych w tematach. Tematami można zarządzać za pomocą narzędzia kafka-topics.sh.
Aby utworzyć temat, użyj następującego polecenia, korzystając z połączenia SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --zookeeper $KAFKAZKHOSTSTo polecenie umożliwia nawiązanie połączenia z hostem Zookeeper przy użyciu informacji o hoście przechowywanych w elemencie
$KAFKAZKHOSTS. Następnie tworzy topic Kafka o nazwie test.Dane przechowywane w tym temacie są podzielone między osiem partycji.
Każda partycja jest replikowana na trzech węzłach roboczych w klastrze.
Jeśli klaster został utworzony w regionie świadczenia usługi Azure, który udostępnia trzy domeny błędów, użyj współczynnika replikacji o wartości 3. W przeciwnym razie użyj współczynnika replikacji o wartości 4.
W regionach z trzema domenami błędów współczynnik replikacji o wartości 3 umożliwia rozmieszczenie replik w różnych domenach błędów. W regionach z dwoma domenami błędów współczynnik replikacji o wartości cztery umożliwia równomierne rozmieszczenie replik między domenami.
Aby uzyskać informacje dotyczące liczby domen błędów w regionie, zobacz dokument Availability of Linux virtual machines (Dostępność maszyn wirtualnych z systemem Linux).
Platforma Kafka nie zna domen błędów platformy Azure. Przy tworzeniu replik partycji dla tematów, repliki mogą nie być właściwie rozmieszczone, co może wpłynąć na zapewnienie wysokiej dostępności.
Aby zapewnić wysoką dostępność, użyj narzędzia do ponownego równoważenia partycji platformy Apache Kafka. To narzędzie należy uruchomić, korzystając z połączenia SSH z węzłem głównym klastra platformy Kafka.
Aby zapewnić najwyższą dostępność danych w Kafka, należy wykonać ponowne równoważenie replik partycji dla topiku, gdy:
Tworzysz nowy temat lub partycję
Skalujesz klaster w górę
Aby wyświetlić listę tematów, użyj następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $KAFKAZKHOSTSTo polecenie wyświetla listę dostępnych tematów w klastrze platformy Kafka.
Aby usunąć temat, użyj następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --zookeeper $KAFKAZKHOSTSTo polecenie usuwa temat o nazwie
topicname.Ostrzeżenie
W przypadku usunięcia utworzonego wcześniej tematu
testkonieczne będzie jego ponowne utworzenie. Jest on używany w czynnościach opisanych w dalszej części tego dokumentu.
Aby uzyskać więcej informacji na temat poleceń dostępnych w narzędziu kafka-topics.sh, użyj następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Tworzenie i używanie rekordów
Platforma Kafka przechowuje rekordy w tematach. Rekordy są tworzone przez producentów i używane przez odbiorców. Producenci i odbiorcy komunikują się z usługą brokera platformy Kafka. Każdy węzeł roboczy w klastrze usługi HDInsight jest hostem brokera Kafka.
Poniżej przedstawiono procedurę zapisywania rekordów w utworzonym wcześniej temacie testowym i odczytywania ich za pomocą odbiorcy:
Aby zapisać rekordy w temacie, użyj narzędzia
kafka-console-producer.sh, korzystając z połączenia SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testPo wykonaniu tego polecenia przejdziesz do pustego wiersza.
Wprowadź wiadomość tekstową do pustego wiersza, a następnie naciśnij klawisz Enter. Wprowadź w ten sposób kilka wiadomości, a następnie użyj kombinacji klawiszy Ctrl + C, aby powrócić do normalnego monitu. Każdy wiersz jest wysyłany jako oddzielny rekord do tematu Kafka.
Aby odczytać rekordy z tematu, użyj narzędzia
kafka-console-consumer.sh, korzystając z połączenia SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningTo polecenie umożliwia pobranie rekordów z tematu i ich wyświetlenie. Polecenie
--from-beginninginformuje odbiorcę, aby rozpocząć od początku strumienia w celu pobrania wszystkich rekordów.Jeśli używasz starszej wersji Kafka, zastąp
--bootstrap-server $KAFKABROKERS--zookeeper $KAFKAZKHOSTS.Użyj klawiszy Ctrl+C, aby zatrzymać odbiorcę.
Producentów i odbiorców można również utworzyć programowo. Przykład korzystania z tego interfejsu API znajduje się w dokumencie Apache Kafka Producer and Consumer API with HDInsight (Interfejs API producenta i odbiorcy platformy Apache Kafka w usłudze HDInsight).
Czyszczenie zasobów
Po zakończeniu pracy z przewodnikiem Szybki start możesz usunąć klaster. W usłudze HDInsight dane są przechowywane w usłudze Azure Storage, dzięki czemu można bezpiecznie usunąć klaster, gdy nie jest używany. Opłaty są również naliczane za klaster usługi HDInsight, nawet jeśli nie jest używany. Ponieważ opłaty za klaster są wielokrotnie większe niż opłaty za magazyn, warto usunąć klastry, gdy nie są używane.
W witrynie Azure Portal przejdź do klastra i wybierz pozycję Usuń.
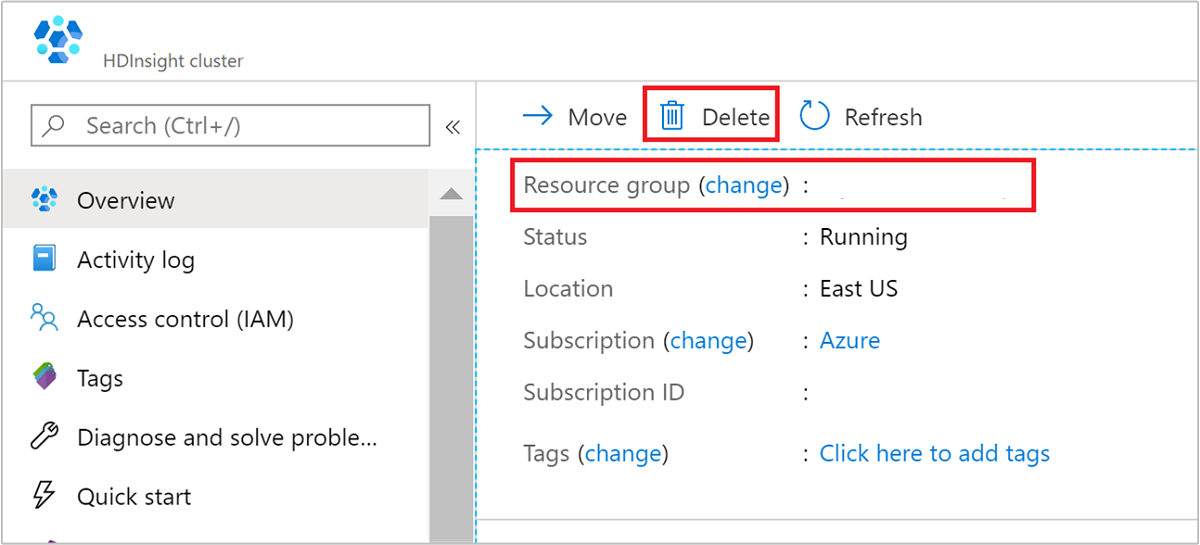
Dodatkowo możesz wybrać nazwę grupy zasobów, aby otworzyć stronę grupy zasobów, a następnie wybrać pozycję Usuń grupę zasobów. Usunięcie grupy zasobów powoduje usunięcie zarówno klastra usługi HDInsight, jak i domyślnego konta magazynu.
Następne kroki
W tym szybkim przewodniku nauczyłeś się tworzyć klaster Apache Kafka w usłudze HDInsight przy użyciu szablonu ARM. W następnym artykule dowiesz się, jak utworzyć aplikację korzystającą z interfejsu API strumieni platformy Apache Kafka i uruchomić ją za pomocą platformy Kafka w usłudze HDInsight.