Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym notesie pokazano, jak analizować dane dziennika przy użyciu biblioteki niestandardowej z platformą Apache Spark w usłudze HDInsight. Używana biblioteka niestandardowa to biblioteka języka Python o nazwie iislogparser.py.
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight.
Zapisywanie danych pierwotnych jako RDD
W tej sekcji użyjemy notesu Jupyter Notebook skojarzonego z klastrem Apache Spark w usłudze HDInsight, aby uruchamiać zadania przetwarzające nieprzetworzone przykładowe dane i zapisywać je jako tabelę programu Hive. Przykładowe dane są domyślnie plikiem .csv (hvac.csv) dostępnym we wszystkich klastrach.
Po zapisaniu danych jako tabeli Apache Hive w następnej sekcji połączymy się z tabelą Hive przy użyciu narzędzi analizy biznesowej, takich jak Power BI i Tableau.
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/jupyterlokalizacji , gdzieCLUSTERNAMEjest nazwą klastra.Utwórz nowy notes. Wybierz pozycję Nowy, a następnie pozycję PySpark.
 Notebook" border="true":::
Notebook" border="true":::Zostanie utworzony i otwarty nowy notes o nazwie Untitled.pynb. Wybierz nazwę notesu u góry i wprowadź przyjazną nazwę.
Ponieważ notes został utworzony przy użyciu jądra PySpark, nie trzeba jawnie tworzyć żadnych kontekstów. Konteksty Spark i Hive zostaną automatycznie utworzone po uruchomieniu pierwszej komórki kodu. Możesz zacząć od zaimportowania typów wymaganych w tym scenariuszu. Wklej poniższy fragment kodu w pustej komórce, a następnie naciśnij klawisze Shift + Enter.
from pyspark.sql import Row from pyspark.sql.types import *Utwórz rdD przy użyciu przykładowych danych dziennika, które są już dostępne w klastrze. Dostęp do danych można uzyskać na domyślnym koncie magazynu skojarzonym z klastrem pod adresem
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Wykonaj następujący kod:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Pobierz przykładowy zestaw dzienników, aby sprawdzić, czy poprzedni krok zakończył się pomyślnie.
logs.take(5)Powinny zostać wyświetlone dane wyjściowe podobne do następującego tekstu:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Analizowanie danych dziennika przy użyciu niestandardowej biblioteki języka Python
W powyższych danych wyjściowych pierwsze wiersze kilku zawierają informacje nagłówka, a każdy pozostały wiersz pasuje do schematu opisanego w tym nagłówku. Analizowanie takich dzienników może być skomplikowane. Dlatego używamy niestandardowej biblioteki języka Python (iislogparser.py), która znacznie ułatwia analizowanie takich dzienników. Domyślnie ta biblioteka jest dołączona do klastra Spark w usłudze HDInsight pod adresem
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.Jednak ta biblioteka nie znajduje się w pliku
PYTHONPATH, więc nie można jej używać przy użyciu instrukcji import, takiej jakimport iislogparser. Aby użyć tej biblioteki, musimy ją dystrybuować do wszystkich węzłów procesu roboczego. Uruchom poniższy fragment kodu.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserUdostępnia funkcję, która zwracaNone,parse_log_linejeśli wiersz dziennika jest wierszem nagłówka i zwraca wystąpienieLogLineklasy, jeśli napotka wiersz dziennika.LogLineUżyj klasy , aby wyodrębnić tylko wiersze dziennika z RDD:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Pobierz kilka wyodrębnionych wierszy dziennika, aby sprawdzić, czy krok zakończył się pomyślnie.
logLines.take(2)Dane wyjściowe powinny być podobne do następującego tekstu:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]Klasa
LogLinema z kolei kilka przydatnych metod, takich jakis_error(), która zwraca, czy wpis dziennika ma kod błędu. Użyj tej klasy, aby obliczyć liczbę błędów w wyodrębnionych wierszach dziennika, a następnie zarejestrować wszystkie błędy w innym pliku.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')Dane wyjściowe powinny mieć stan
There are 30 errors and 646 log entries.Możesz również użyć biblioteki Matplotlib do utworzenia wizualizacji danych. Jeśli na przykład chcesz odizolować przyczynę żądań, które są uruchamiane przez długi czas, możesz znaleźć pliki, które zwykle zajmują więcej czasu. Poniższy fragment kodu pobiera 25 najważniejszych zasobów, które przez większość czasu obsługiwały żądanie.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])Powinny zostać wyświetlone dane wyjściowe podobne do następującego tekstu:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]Te informacje można również przedstawić w postaci wykresu. Pierwszym krokiem do utworzenia wykresu jest utworzenie tabeli tymczasowej AverageTime. Tabela grupuje dzienniki według czasu, aby sprawdzić, czy w danym momencie wystąpiły jakieś nietypowe skoki opóźnień.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')Następnie możesz uruchomić następujące zapytanie SQL, aby pobrać wszystkie rekordy w tabeli AverageTime .
%%sql -o averagetime SELECT * FROM AverageTimeNastępnie magia
%%sql-o averagetimegwarantuje, że dane wyjściowe zapytania są utrwalane lokalnie na serwerze Jupyter (zazwyczaj w węźle głównym klastra). Dane wyjściowe są utrwalane jako ramka danych biblioteki Pandas o określonej nazwie averagetime.Powinny zostać wyświetlone dane wyjściowe podobne do poniższego obrazu:
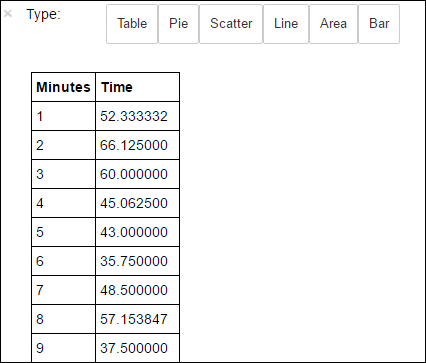 yter sql query output" border="true":::
yter sql query output" border="true":::Aby uzyskać więcej informacji na temat
%%sqlmagii, zobacz Parametry obsługiwane za pomocą magii %%sql.Teraz możesz użyć biblioteki Matplotlib służącej do konstruowania wizualizacji danych w celu utworzenia wykresu. Ponieważ wykres musi zostać utworzony na podstawie lokalnie utrwalonej ramki danych averagetime , fragment kodu musi zaczynać się
%%localod magii. Dzięki temu kod jest uruchamiany lokalnie na serwerze Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')Powinny zostać wyświetlone dane wyjściowe podobne do poniższego obrazu:
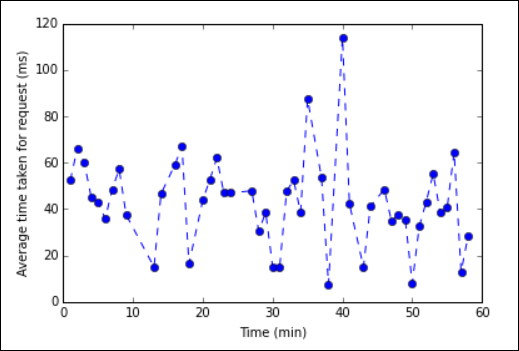 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::Po zakończeniu uruchamiania aplikacji należy zamknąć notes, aby zwolnić zasoby. W tym celu w menu File (Plik) w notesie wybierz pozycję Close and Halt (Zamknij i zatrzymaj). Ta akcja spowoduje zamknięcie i zamknięcie notesu.
Następne kroki
Zapoznaj się z następującymi artykułami: