Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym przewodniku szybkiego startu utworzysz klaster Apache Spark w usłudze Azure HDInsight za pomocą szablonu ARM Azure Resource Manager. Następnie utworzysz plik notesu Jupyter i użyj go do przeprowadzania zapytań Spark SQL na tabelach Apache Hive. Azure HDInsight jest zarządzaną usługą analityczną typu „open source” o szerokim zakresie, z przeznaczeniem dla przedsiębiorstw. Platforma Apache Spark dla usługi HDInsight umożliwia szybką analizę danych i przetwarzanie klastrów przy użyciu przetwarzania w pamięci. Jupyter Notebook umożliwia interakcję z Twoimi danymi, łączenie kodu z tekstem w formacie markdown i tworzenie prostych wizualizacji.
Jeśli używasz wielu klastrów razem, musisz utworzyć sieć wirtualną, a jeśli używasz klastra Spark, musisz również użyć łącznika magazynu Hive. Aby uzyskać więcej informacji, zobacz Zaplanuj sieć wirtualną dla usługi Azure HDInsight oraz Zintegrowanie platform Apache Spark i Apache Hive z Łącznikiem Magazynu Hive.
Szablon usługi Azure Resource Manager to plik JavaScript Object Notation (JSON), który definiuje infrastrukturę i konfigurację projektu. W szablonie używana jest składnia deklaratywna. Możesz opisać zamierzone wdrożenie bez konieczności pisania sekwencji poleceń programowania w celu utworzenia wdrożenia.
Jeśli Twoje środowisko spełnia wymagania wstępne i masz doświadczenie w korzystaniu z szablonów ARM, wybierz przycisk Wdróż na platformie Azure. Szablon zostanie otwarty w witrynie Azure Portal.

Wymagania wstępne
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Przegląd szablonu
Szablon używany w tym przewodniku szybkiego startu pochodzi z Azure Quickstart Templates.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
Dwa zasoby platformy Azure są zdefiniowane w szablonie:
- Microsoft.Storage/storageAccounts: utwórz konto usługi Azure Storage.
- Microsoft.HDInsight/cluster: utwórz klaster usługi HDInsight.
Wdrażanie szablonu
Wybierz poniższy przycisk Wdróż na platformie Azure, aby zalogować się na platformie Azure i otworzyć szablon usługi ARM.
Wprowadź lub wybierz poniższe wartości:
Właściwość Opis Subskrypcja Z listy rozwijanej wybierz subskrypcję platformy Azure używaną dla klastra. Grupa zasobów Z listy rozwijanej wybierz istniejącą grupę zasobów lub wybierz pozycję Utwórz nową. Lokalizacja Wartość zostanie wypełniona automatycznie na podstawie lokalizacji używanej dla grupy zasobów. Nazwa klastra Podaj globalnie unikatową nazwę. W tym szablonie użyj tylko małych liter i cyfr. Nazwa użytkownika logowania klastra Podaj nazwę użytkownika, wartość domyślna to admin.Hasło logowania klastra Podaj hasło. Hasło musi mieć długość co najmniej 10 znaków i musi zawierać co najmniej jedną cyfrę, jedną wielką literę i jedną małą literę, znak inny niż alfanumeryczny (z wyjątkiem znaków ' ` ").Nazwa użytkownika SSH Podaj nazwę użytkownika, wartość domyślna to sshuser.Hasło SSH Podaj hasło. 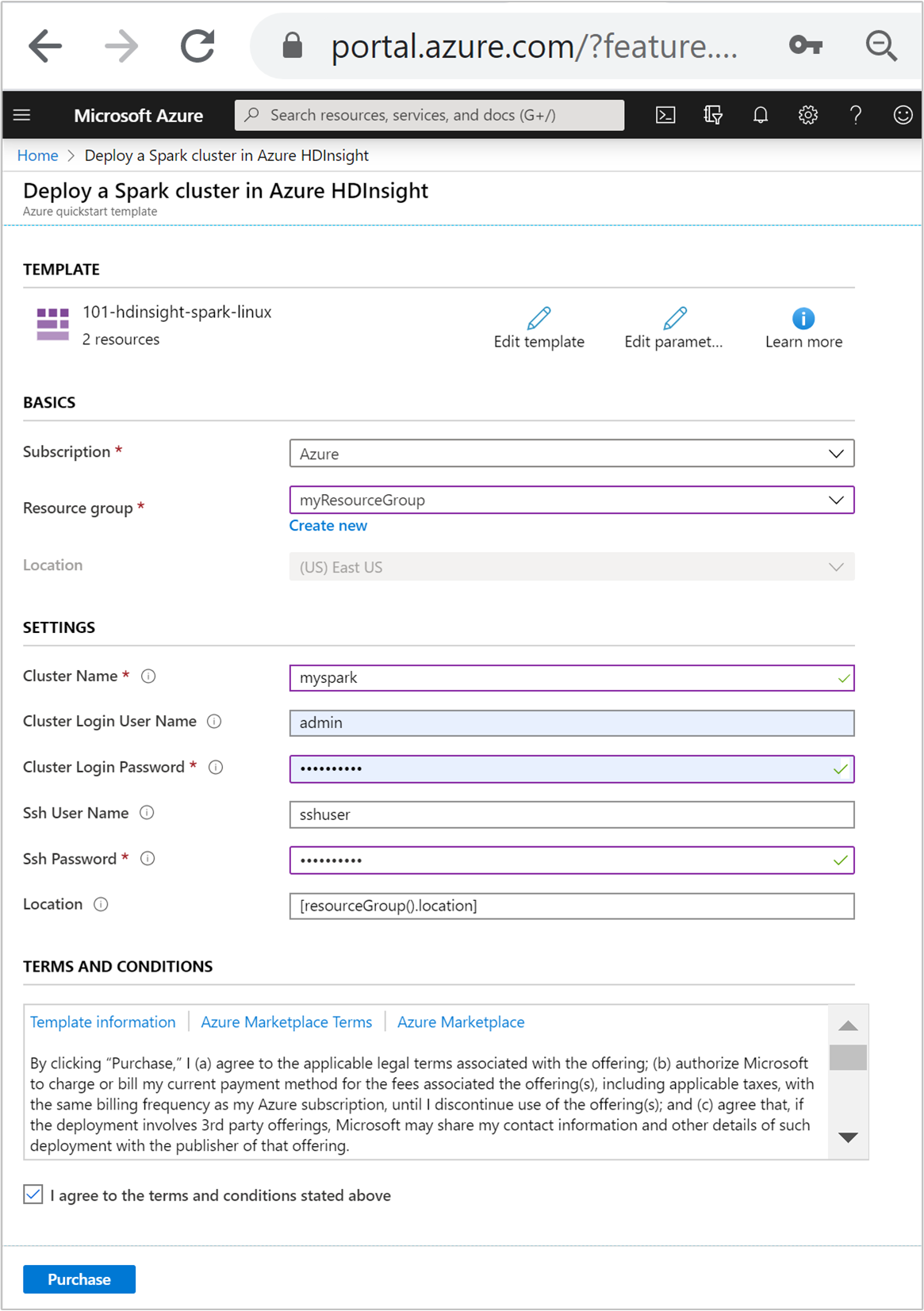
Zapoznaj się z warunkami i postanowieniami. Następnie wybierz pozycję Zgadzam się na powyższe warunki i postanowienia, a następnie pozycję Kup. Otrzymasz powiadomienie, że wdrożenie jest w toku. Utworzenie klastra trwa około 20 minut.
Jeśli wystąpi problem z tworzeniem klastrów usługi HDInsight, może to oznaczać, że nie masz odpowiednich uprawnień do tego. Aby uzyskać więcej informacji, zobacz Wymagania dotyczące kontroli dostępu.
Przeglądanie wdrożonych zasobów
Po utworzeniu klastra otrzymasz powiadomienie Wdrożenie zakończyło się pomyślnie z linkiem Przejdź do zasobu . Strona grupy zasobów będzie wymieniać nowy klaster HDInsight oraz domyślny magazyn powiązany z klastrem. Każdy klaster ma usługę Azure Storage albo zależność Azure Data Lake Storage Gen2. Jest to nazywane domyślnym kontem magazynu. Klaster usługi HDInsight i jego domyślne konto magazynu muszą być kolokowane w tym samym regionie świadczenia usługi Azure. Usunięcie klastrów nie powoduje usunięcia zależności konta magazynu. Jest to nazywane domyślnym kontem magazynu. Klaster usługi HDInsight i jego domyślne konto magazynu muszą być kolokowane w tym samym regionie świadczenia usługi Azure. Usunięcie klastrów nie powoduje usunięcia konta magazynu.
Tworzenie pliku notesu Jupyter Notebook
Jupyter Notebook to interakcyjne środowisko notesu, które obsługuje różne języki programowania. Plik jupyter Notebook umożliwia interakcję z danymi, łączenie kodu z tekstem markdown i wykonywanie prostych wizualizacji.
Otwórz portal Azure.
Wybierz pozycję Klastry usługi HDInsight, a następnie wybierz utworzony klaster.
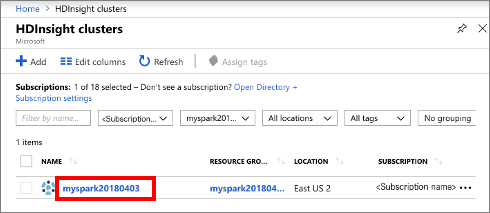
W portalu, w sekcji Pulpity nawigacyjne klastra, wybierz Jupyter Notebook. Jeśli zostanie wyświetlony monit, wprowadź poświadczenia logowania dla klastra.
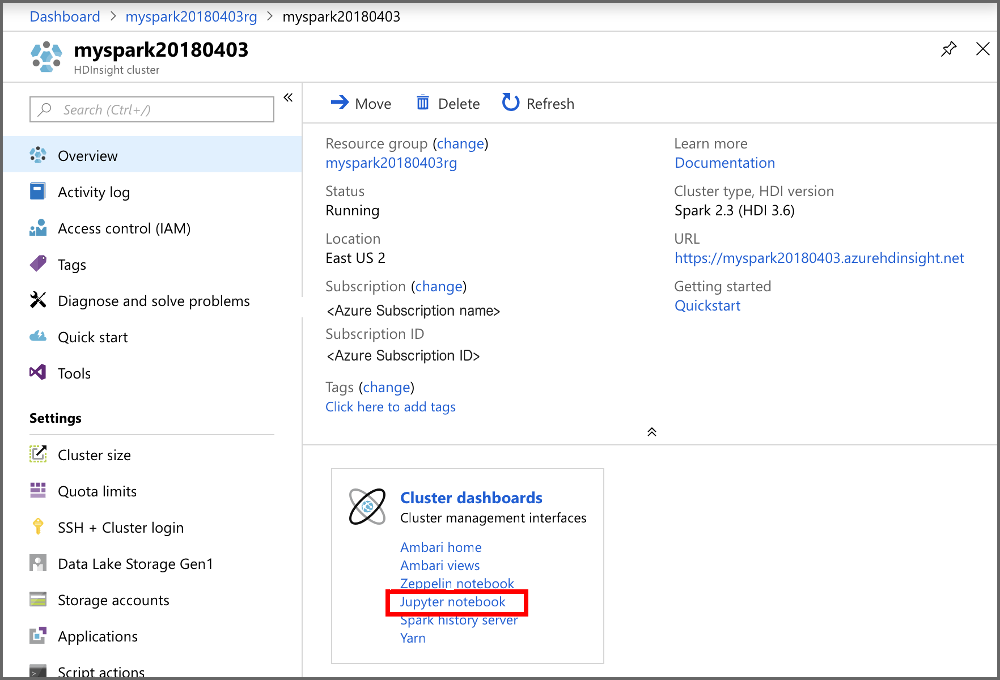
Aby utworzyć notatnik, wybierz Nowy>PySpark.
Utwórz plik Jupyter Notebook, aby uruchomić interaktywne zapytanie Spark SQL.
Utworzony i otwarty zostanie nowy notes o nazwie "Untitled" (Untitled.pynb).
Uruchamianie instrukcji Apache Spark SQL
SQL (Structured Query Language) to najczęściej używany język służący do przekształcania danych i wykonywania zapytań na tych danych. Rozwiązanie Spark SQL stanowi rozszerzenie platformy Apache Spark służące do przetwarzania danych strukturalnych za pomocą dobrze znanej składni języka SQL.
Sprawdź, czy jądro jest gotowe. Gotowość jądra jest sygnalizowana pustym okręgiem obok nazwy jądra w notesie. Pełne kółko oznacza, że jądro jest zajęte.
 alt-text="Stan jądra." border="true":::
alt-text="Stan jądra." border="true":::Podczas pierwszego uruchamiania notesu jądro wykonuje pewne zadania w tle. Poczekaj, aż jądro będzie gotowe.
Wklej następujący kod do pustej komórki, a następnie naciśnij klawisze SHIFT + ENTER, aby go uruchomić. Polecenie wyświetla listę tabel Hive w klastrze:
%%sql SHOW TABLESJeśli używasz pliku notesu Jupyter Notebook z klastrem usługi HDInsight, uzyskasz wstępnie ustawioną
sparksesję, której można użyć do uruchamiania zapytań programu Hive przy użyciu usługi Spark SQL. Wyrażenie%%sqlinformuje Jupyter Notebook o konieczności użycia ustawionej z góry sesjisparkdo uruchomienia zapytania Hive. Zapytanie pobiera pierwszych 10 wierszy z tabeli programu Hive (hivesampletable), która jest dostępna domyślnie na wszystkich klastrach usługi HDInsight. Przy pierwszym przesłaniu zapytania program Jupyter utworzy aplikację Platformy Spark dla notesu. Utworzenie jej zajmuje około 30 sekund. Gdy aplikacja Spark będzie gotowa, zapytanie jest wykonywane w około sekundzie i generuje wyniki. Dane wyjściowe wyglądają następująco: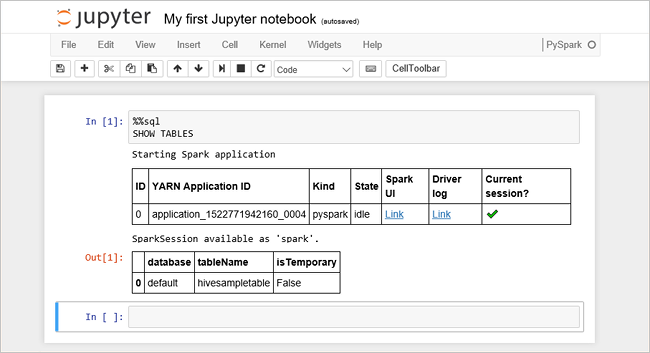 y in HDInsight" border="true":::
y in HDInsight" border="true":::Za każdym razem, gdy uruchamiasz zapytanie w programie Jupyter, tytuł okna przeglądarki internetowej pokazuje status (Busy) wraz z tytułem notatnika. Widzisz także pełne kółko obok tekstu PySpark w prawym górnym rogu.
Uruchom inne zapytanie, aby wyświetlić dane z tabeli
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Ekran zostanie odświeżony w celu wyświetlenia wyników zapytania.
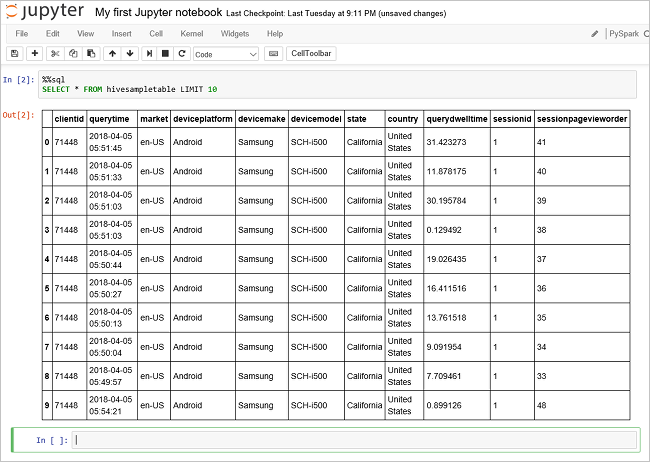 Insight" border="true":::
Insight" border="true":::W menu File (Plik) w notesie wybierz pozycję Close and Halt (Zamknij i zatrzymaj). Zamknięcie notesu zwalnia zasoby klastra, w tym aplikację Platformy Spark.
Czyszczenie zasobów
Po zakończeniu szybkiego startu warto rozważyć usunięcie klastra. W usłudze HDInsight dane są przechowywane w usłudze Azure Storage, dzięki czemu można bezpiecznie usunąć klaster, gdy nie jest używany. Opłaty są również naliczane za klaster usługi HDInsight, nawet jeśli nie jest używany. Ponieważ opłaty za klaster są wielokrotnie większe niż opłaty za magazyn, warto usunąć klastry, gdy nie są używane.
W witrynie Azure Portal przejdź do klastra i wybierz pozycję Usuń.
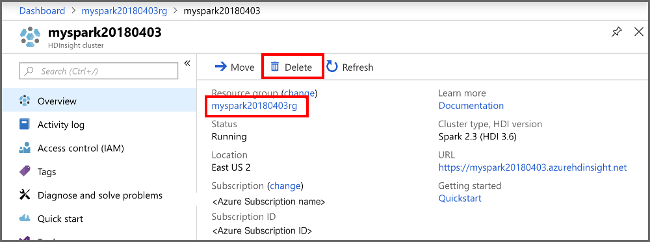 sight cluster" border="true":::
sight cluster" border="true":::
Dodatkowo możesz wybrać nazwę grupy zasobów, aby otworzyć stronę grupy zasobów, a następnie wybrać pozycję Usuń grupę zasobów. Usunięcie grupy zasobów powoduje usunięcie zarówno klastra usługi HDInsight, jak i domyślnego konta magazynu.
Następne kroki
W tym przewodniku Szybki start przedstawiono sposób tworzenia klastra Apache Spark w usłudze HDInsight i uruchamiania podstawowego zapytania Spark SQL. Przejdź do następnego samouczka, aby dowiedzieć się, jak używać klastra usługi HDInsight do uruchamiania interakcyjnych zapytań dotyczących przykładowych danych.