Tworzenie aplikacji Platformy Apache Spark dla klastra usługi HDInsight za pomocą zestawu narzędzi Azure Toolkit for IntelliJ
W tym artykule pokazano, jak opracowywać aplikacje platformy Apache Spark w usłudze Azure HDInsight przy użyciu wtyczki Azure Toolkit dla środowiska IDE IntelliJ. Azure HDInsight to zarządzana usługa analizy typu open source w chmurze. Usługa umożliwia korzystanie z platform typu open source, takich jak Hadoop, Apache Spark, Apache Hive i Apache Kafka.
Możesz użyć wtyczki Azure Toolkit na kilka sposobów:
- Tworzenie i przesyłanie aplikacji Scala Spark do klastra SPARK usługi HDInsight.
- Uzyskiwanie dostępu do zasobów klastra Platformy Spark w usłudze Azure HDInsight.
- Lokalnie twórz i uruchamiaj aplikację Platformy Spark w języku Scala.
W tym artykule omówiono sposób wykonywania następujących zadań:
- Korzystanie z wtyczki Azure Toolkit for IntelliJ
- Tworzenie aplikacji platformy Apache Spark
- Przesyłanie aplikacji do klastra usługi Azure HDInsight
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight. Obsługiwane są tylko klastry usługi HDInsight w chmurze publicznej, podczas gdy inne bezpieczne typy chmur (np. chmury dla instytucji rządowych) nie są obsługiwane.
Zestaw Oracle Java Development. W tym artykule użyto języka Java w wersji 8.0.202.
IntelliJ IDEA. W tym artykule użyto środowiska IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Zobacz Installing the Azure Toolkit for IntelliJ (Instalowanie zestawu Azure Toolkit for IntelliJ).
Instalowanie wtyczki Scala dla środowiska IntelliJ IDEA
Kroki instalacji wtyczki Scala:
Otwórz środowisko IntelliJ IDEA.
Na ekranie powitalnym przejdź do pozycji Configure (Konfiguruj)>Plugins (Wtyczki), aby otworzyć okno Plugins (Wtyczki).
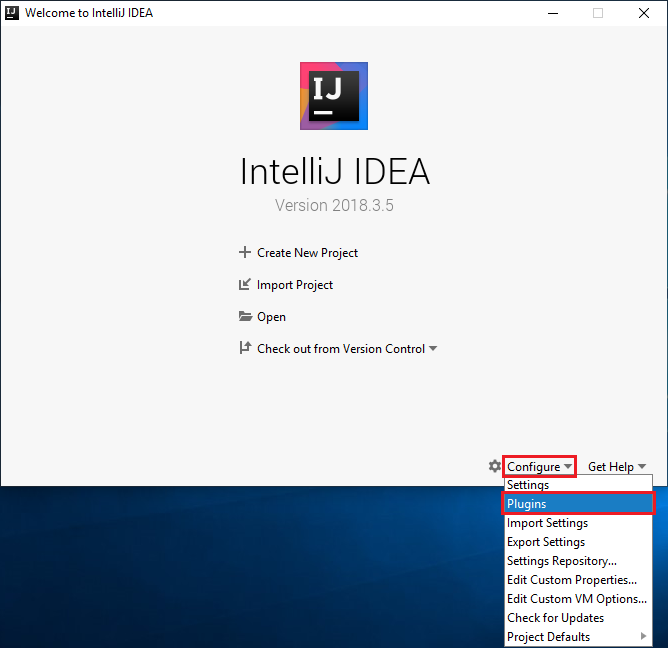
Wybierz pozycję Install (Instaluj) dla wtyczki Scala, która zostanie wyświetlona w nowym oknie.
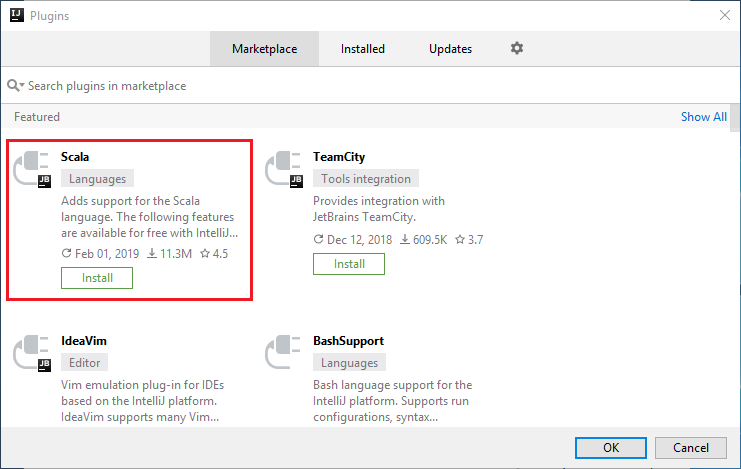
Po pomyślnym zainstalowaniu wtyczki musisz ponownie uruchomić środowisko IDE.
Tworzenie aplikacji Spark Scala dla klastra SPARK w usłudze HDInsight
Uruchom środowisko IntelliJ IDEA i wybierz pozycję Create New Project (Utwórz nowy projekt), aby otworzyć okno New Project (Nowy projekt).
Wybierz pozycję Azure Spark/HDInsight w okienku po lewej stronie.
Wybierz pozycję Spark Project (Scala) w głównym oknie.
Z listy rozwijanej Narzędzie kompilacji wybierz jedną z następujących opcji:
Maven — w celu obsługi kreatora tworzenia projektu Scala.
SBT — na potrzeby zarządzania zależnościami i kompilacji projektu Scala.
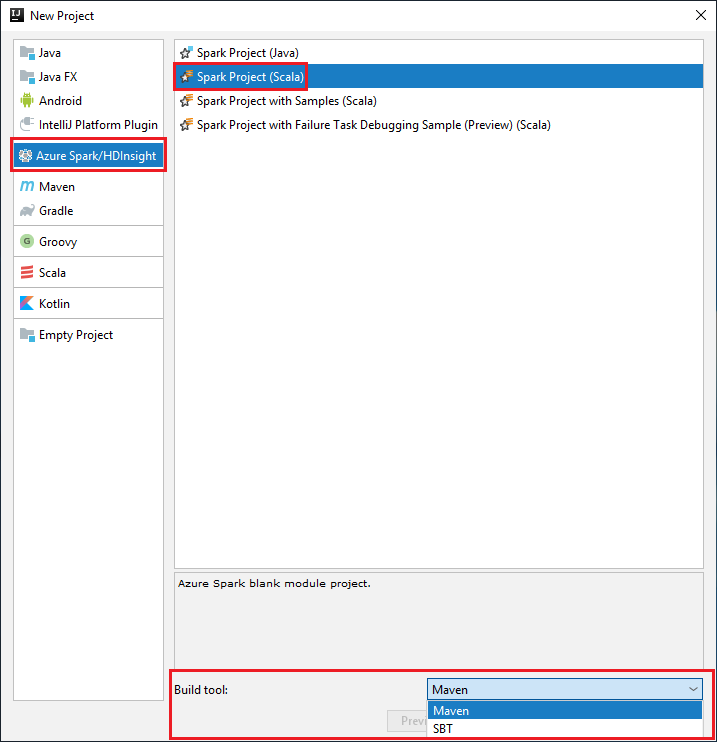
Wybierz Dalej.
W oknie New Project (Nowy projekt) podaj następujące informacje:
Właściwości opis Nazwa projektu Wprowadź nazwę. W tym artykule jest używany program myApp.Lokalizacja projektu Wprowadź lokalizację do zapisania projektu. Zestaw SDK projektu To pole może być puste w pierwszym użyciu środowiska IDEA. Wybierz pozycję New... (Nowy...) i przejdź do swojego zestawu JDK. Wersja platformy Spark Kreator tworzenia integruje poprawną wersję dla zestawów Spark SDK i Scala SDK. Jeśli wersja klastra Spark jest starsza niż 2.0, wybierz wartość Spark 1.x. W przeciwnym razie wybierz Spark2.x. W tym przykładzie używana jest wersja Spark 2.3.0 (Scala 2.11.8). 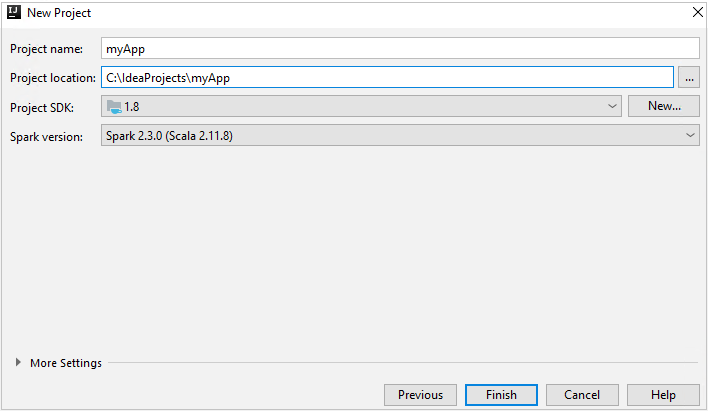
Wybierz Zakończ. Udostępnienie projektu może potrwać kilka minut.
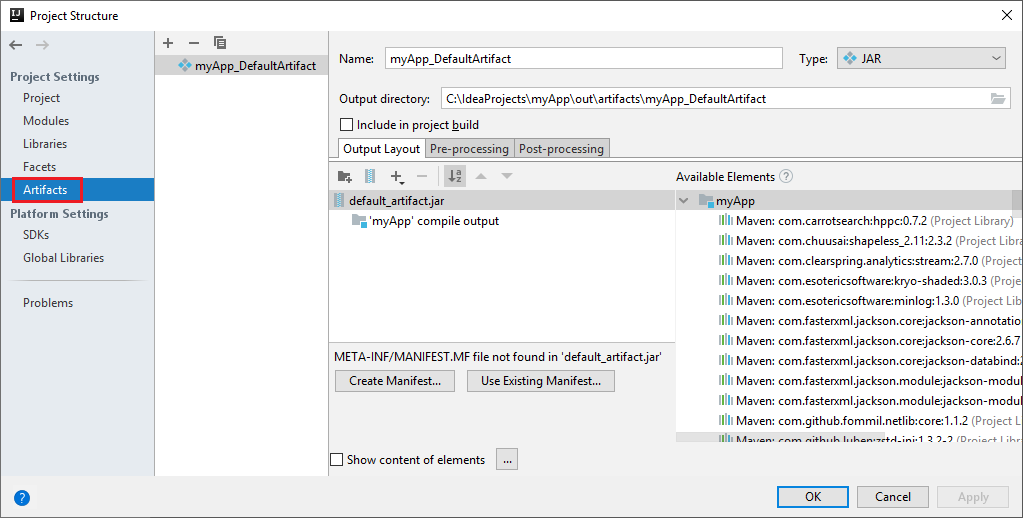
Projekt Spark automatycznie tworzy artefakt. Aby wyświetlić artefakt, wykonaj następujące czynności:
a. Na pasku menu przejdź do pozycji Struktura projektu plików>....
b. W oknie Struktura projektu wybierz pozycję Artefakty.
c. Po wyświetleniu artefaktu wybierz pozycję Anuluj .
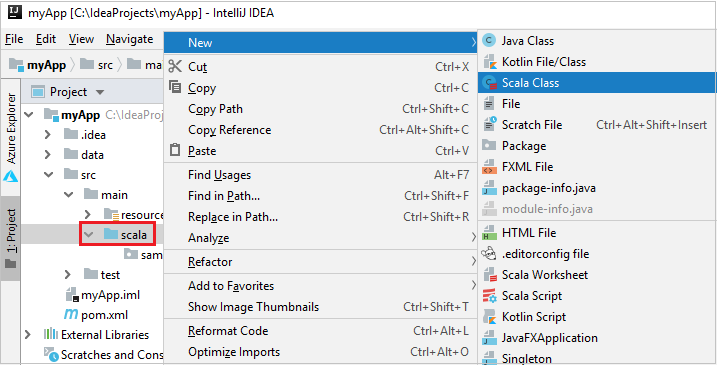
Dodaj kod źródłowy aplikacji, wykonując następujące czynności:
a. W obszarze Project przejdź do głównej>scala usługi myApp>src.>
b. Kliknij prawym przyciskiem myszy pozycję scala, a następnie przejdź do pozycji Nowa>klasa Scala.
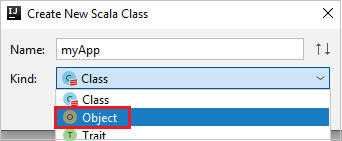
c. W oknie dialogowym Tworzenie nowej klasy Scala podaj nazwę, wybierz pozycję Obiekt z listy rozwijanej Rodzaj, a następnie wybierz przycisk OK.
d. Plik myApp.scala zostanie otwarty w widoku głównym. Zastąp domyślny kod poniższym kodem:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Kod odczytuje dane z HVAC.csv (dostępne we wszystkich klastrach spark usługi HDInsight), pobiera wiersze zawierające tylko jedną cyfrę w siódmym pliku CSV i zapisuje dane wyjściowe
/HVACOutw domyślnym kontenerze magazynu dla klastra.
Połączenie do klastra usługi HDInsight
Użytkownik może zalogować się do subskrypcji platformy Azure lub połączyć klaster usługi HDInsight. Użyj poświadczenia nazwy użytkownika/hasła lub hasła przyłączonego do domeny systemu Ambari, aby nawiązać połączenie z klastrem usługi HDInsight.
Zaloguj się do Twojej subskrypcji platformy Azure.
Na pasku menu przejdź do pozycji Wyświetl>narzędzie Windows>Azure Explorer.
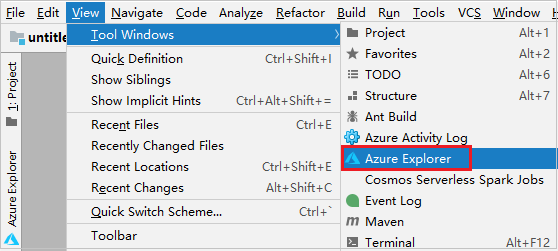
W eksploratorze platformy Azure kliknij prawym przyciskiem myszy węzeł platformy Azure, a następnie wybierz pozycję Zaloguj.
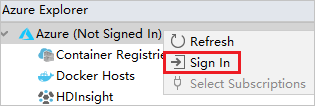
W oknie dialogowym Logowanie do platformy Azure wybierz pozycję Logowanie do urządzenia, a następnie wybierz pozycję Zaloguj.
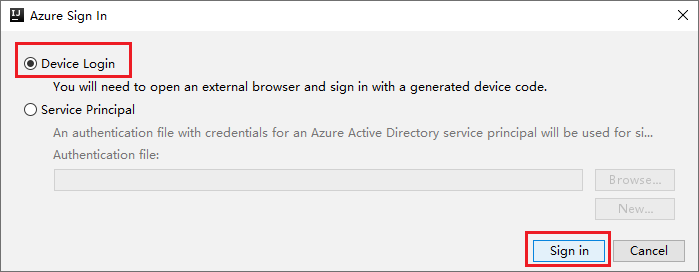
W oknie dialogowym Logowanie do urządzenia platformy Azure kliknij pozycję Kopiuj i otwórz.
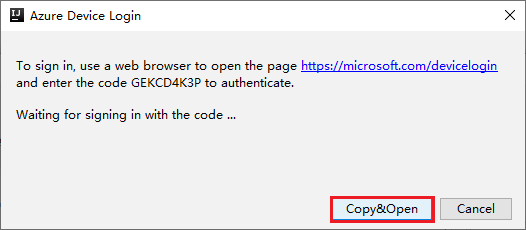
W interfejsie przeglądarki wklej kod, a następnie kliknij przycisk Dalej.
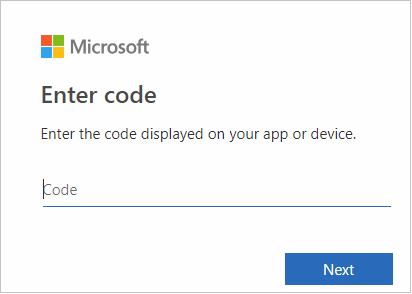
Wprowadź poświadczenia platformy Azure, a następnie zamknij przeglądarkę.
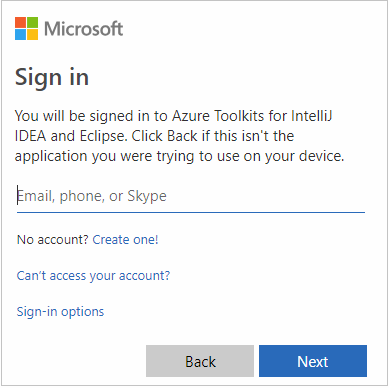
Po zalogowaniu okno dialogowe Wybieranie subskrypcji zawiera listę wszystkich subskrypcji platformy Azure skojarzonych z poświadczeniami. Wybierz subskrypcję, a następnie wybierz przycisk Wybierz .
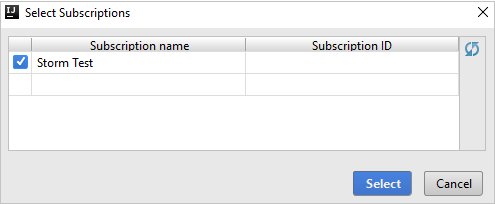
W usłudze Azure Explorer rozwiń węzeł HDInsight , aby wyświetlić klastry Spark usługi HDInsight, które znajdują się w Twoich subskrypcjach.
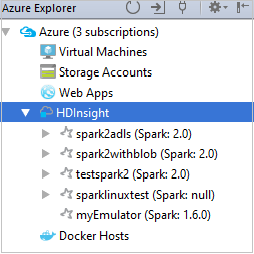
Aby wyświetlić zasoby (na przykład konta magazynu), które są skojarzone z klastrem, możesz dodatkowo rozwinąć węzeł nazwy klastra.
Łączenie klastra
Klaster usługi HDInsight można połączyć przy użyciu zarządzanej nazwy użytkownika apache Ambari. Podobnie w przypadku klastra usługi HDInsight przyłączonego do domeny można połączyć za pomocą domeny i nazwy użytkownika, takiej jak user1@contoso.com. Możesz również połączyć klaster usługi Livy Service.
Na pasku menu przejdź do pozycji Wyświetl>narzędzie Windows>Azure Explorer.
W programie Azure Explorer kliknij prawym przyciskiem myszy węzeł usługi HDInsight , a następnie wybierz pozycję Połącz klaster.
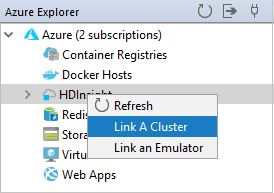
Dostępne opcje w oknie Łączenie klastra A różnią się w zależności od wartości wybranej z listy rozwijanej Link Typ zasobu. Wprowadź wartości, a następnie wybierz przycisk OK.
Klaster usługi HDInsight
Właściwości Wartość Połącz typ zasobu Wybierz pozycję Klaster usługi HDInsight z listy rozwijanej. Nazwa/adres URL klastra Wprowadź nazwę klastra. Typ uwierzytelniania Pozostaw jako uwierzytelnianie podstawowe Nazwa użytkownika Wprowadź nazwę użytkownika klastra, wartość domyślna to administrator. Hasło Wprowadź hasło dla nazwy użytkownika. 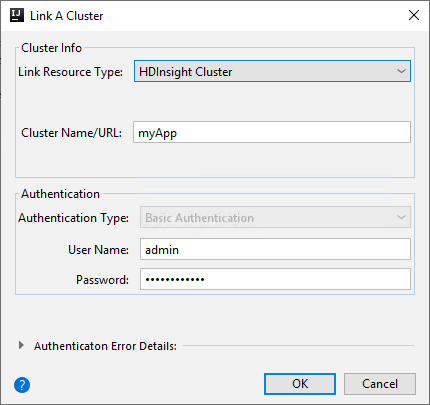
Usługa Livy
Właściwości Wartość Połącz typ zasobu Wybierz pozycję Livy Service z listy rozwijanej. Punkt końcowy usługi Livy Wprowadź punkt końcowy usługi Livy Nazwa klastra Wprowadź nazwę klastra. Punkt końcowy usługi Yarn Opcjonalny. Typ uwierzytelniania Pozostaw jako uwierzytelnianie podstawowe Nazwa użytkownika Wprowadź nazwę użytkownika klastra, wartość domyślna to administrator. Hasło Wprowadź hasło dla nazwy użytkownika. 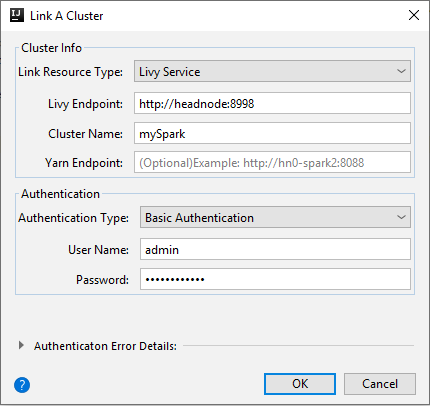
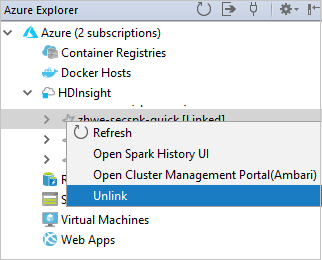
Możesz zobaczyć połączony klaster z węzła usługi HDInsight .
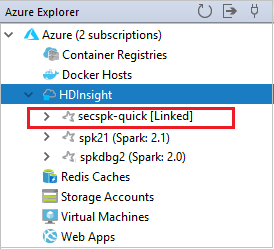
Możesz również odłączyć klaster z poziomu eksploratora platformy Azure.
Uruchamianie aplikacji Spark Scala w klastrze SPARK w usłudze HDInsight
Po utworzeniu aplikacji Scala można przesłać ją do klastra.
W obszarze Project przejdź do głównej>aplikacji myApp>src>myApp.> Kliknij prawym przyciskiem myszy pozycję myApp i wybierz pozycję Prześlij aplikację spark (prawdopodobnie będzie ona znajdować się w dolnej części listy).
W oknie dialogowym Przesyłanie aplikacji platformy Spark wybierz pozycję 1. Platforma Spark w usłudze HDInsight.
W oknie Edytowanie konfiguracji podaj następujące wartości, a następnie wybierz przycisk OK:
Właściwości Wartość Klastry Spark (tylko system Linux) Wybierz klaster HDInsight Spark, na którym chcesz uruchomić aplikację. Wybieranie artefaktu do przesłania Pozostaw ustawienie domyślne. Nazwa klasy głównej Wartość domyślna to klasa główna z wybranego pliku. Klasę można zmienić, wybierając wielokropek(...) i wybierając inną klasę. Konfiguracje zadań Możesz zmienić klucze domyślne i lub wartości. Aby uzyskać więcej informacji, zobacz Interfejs API REST usługi Apache Livy. Argumenty wiersza polecenia W razie potrzeby można wprowadzić argumenty rozdzielone spacją dla klasy głównej. Przywoływania plików Jar i plików, do których odwołuje się odwołanie Jeśli istnieją, możesz wprowadzić ścieżki dla przywołynych plików Jars i plików. Możesz również przeglądać pliki w wirtualnym systemie plików platformy Azure, który obecnie obsługuje tylko klaster usługi ADLS Gen 2. Aby uzyskać więcej informacji: Konfiguracja platformy Apache Spark. Zobacz również How to upload resources to cluster (Jak przekazać zasoby do klastra). Przekazywanie magazynu zadań Rozwiń, aby wyświetlić dodatkowe opcje. Typ magazynu Wybierz pozycję Użyj obiektu blob platformy Azure do przekazania z listy rozwijanej. Konto magazynu Wprowadź konto magazynu. Klucz magazynu Wprowadź klucz magazynu. Kontener magazynu Wybierz kontener magazynu z listy rozwijanej po wprowadzeniu konta magazynu i klucza magazynu. 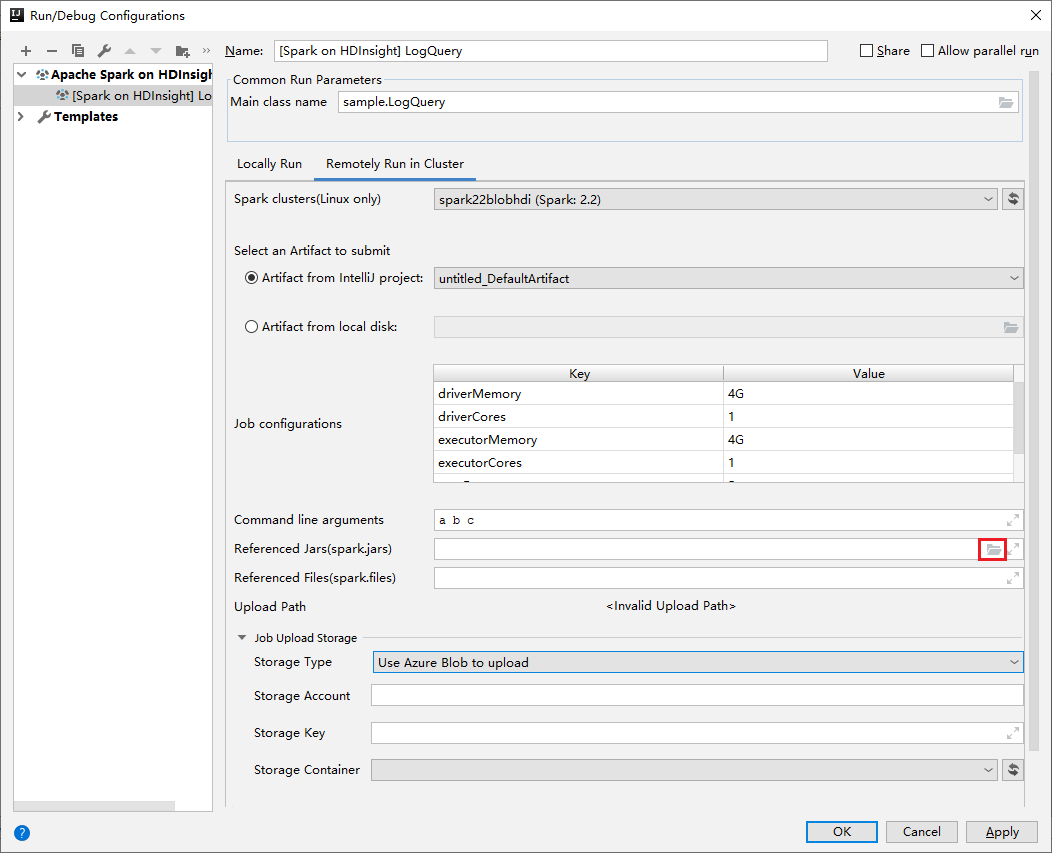
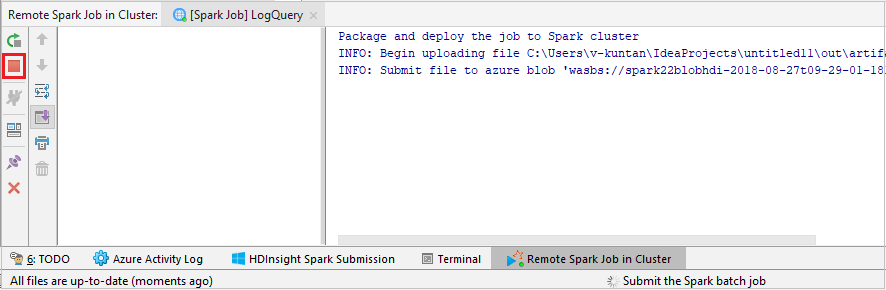
Wybierz pozycję SparkJobRun , aby przesłać projekt do wybranego klastra. Na karcie Zdalne zadanie spark w klastrze jest wyświetlany postęp wykonywania zadania u dołu. Aplikację można zatrzymać, klikając czerwony przycisk.
Lokalne lub zdalne debugowanie aplikacji platformy Apache Spark w klastrze usługi HDInsight
Zalecamy również inny sposób przesyłania aplikacji Spark do klastra. Można to zrobić, ustawiając parametry w środowisku IDE Uruchom/Debugowanie . Zobacz Debugowanie aplikacji platformy Apache Spark lokalnie lub zdalnie w klastrze usługi HDInsight za pomocą zestawu narzędzi Azure Toolkit for IntelliJ za pośrednictwem protokołu SSH.
Uzyskiwanie dostępu do klastrów platformy Spark w usłudze HDInsight i zarządzanie nimi przy użyciu zestawu narzędzi Azure Toolkit for IntelliJ
Różne operacje można wykonywać przy użyciu zestawu narzędzi Azure Toolkit for IntelliJ. Większość operacji jest uruchamiana z poziomu programu Azure Explorer. Na pasku menu przejdź do pozycji Wyświetl>narzędzie Windows>Azure Explorer.
Uzyskiwanie dostępu do widoku zadania
W eksploratorze platformy Azure przejdź do obszaru Zadania klastra>>w usłudze HDInsight.><
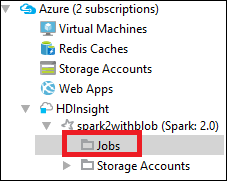
W okienku po prawej stronie na karcie Widok zadania platformy Spark są wyświetlane wszystkie aplikacje, które zostały uruchomione w klastrze. Wybierz nazwę aplikacji, dla której chcesz wyświetlić więcej szczegółów.
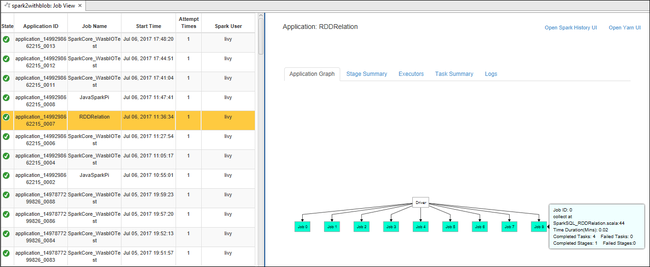
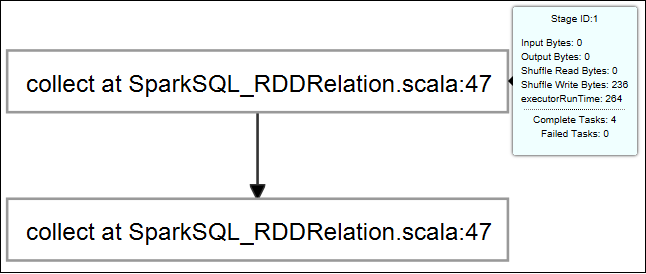
Aby wyświetlić podstawowe informacje o uruchomionym zadaniu, umieść wskaźnik myszy na grafie zadań. Aby wyświetlić wykres etapów i informacje generowane przez każde zadanie, wybierz węzeł na wykresie zadań.
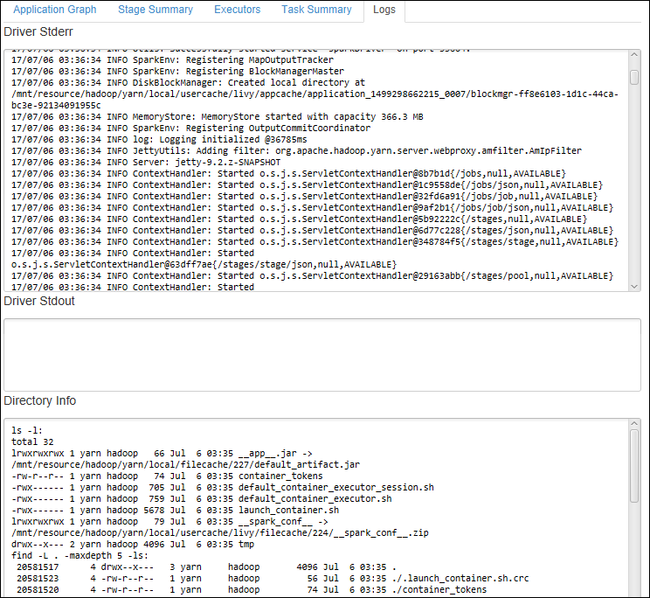
Aby wyświetlić często używane dzienniki, takie jak Driver Stderr, Driver Stdout i Informacje o katalogu, wybierz kartę Dziennik .
Możesz wyświetlić interfejs użytkownika historii platformy Spark i interfejs użytkownika usługi YARN (na poziomie aplikacji). Wybierz link w górnej części okna.
Uzyskiwanie dostępu do serwera historii platformy Spark
W eksploratorze platformy Azure rozwiń węzeł HDInsight, kliknij prawym przyciskiem myszy nazwę klastra Spark, a następnie wybierz pozycję Otwórz interfejs użytkownika historii platformy Spark.
Po wyświetleniu monitu wprowadź poświadczenia administratora klastra określone podczas konfigurowania klastra.
Na pulpicie nawigacyjnym serwera historii platformy Spark możesz użyć nazwy aplikacji, aby wyszukać właśnie uruchomioną aplikację. W poprzednim kodzie należy ustawić nazwę aplikacji przy użyciu polecenia
val conf = new SparkConf().setAppName("myApp"). Nazwa aplikacji platformy Spark to myApp.
Uruchamianie portalu systemu Ambari
W eksploratorze platformy Azure rozwiń węzeł HDInsight, kliknij prawym przyciskiem myszy nazwę klastra Spark, a następnie wybierz pozycję Otwórz portal zarządzania klastrem (Ambari).
Po wyświetleniu monitu wprowadź poświadczenia administratora dla klastra. Te poświadczenia zostały określone podczas procesu instalacji klastra.
Zarządzanie subskrypcjami platformy Azure
Domyślnie zestaw narzędzi Azure Toolkit for IntelliJ wyświetla listę klastrów Spark ze wszystkich subskrypcji platformy Azure. W razie potrzeby możesz określić subskrypcje, do których chcesz uzyskać dostęp.
W Eksploratorze Azure kliknij prawym przyciskiem myszy węzeł główny platformy Azure , a następnie wybierz pozycję Wybierz subskrypcje.
W oknie Wybieranie subskrypcji wyczyść pola wyboru obok subskrypcji, do których nie chcesz uzyskiwać dostępu, a następnie wybierz pozycję Zamknij.
Konsola platformy Spark
Możesz uruchomić konsolę lokalną platformy Spark (Scala) lub uruchomić konsolę interakcyjnej sesji usługi Spark Livy (Scala).
Konsola lokalna platformy Spark (Scala)
Upewnij się, że spełniono wymagania wstępne WINUTILS.EXE.
Na pasku menu przejdź do pozycji Uruchom>konfiguracje edycji....
W oknie Uruchamianie/debugowanie konfiguracji w okienku po lewej stronie przejdź do platformy Apache Spark w usłudze HDInsight>[Spark w usłudze HDInsight] myApp.
W oknie głównym wybierz kartę
Locally Run.Podaj następujące wartości, a następnie wybierz przycisk OK:
Właściwości Wartość Główna klasa zadania Wartość domyślna to klasa główna z wybranego pliku. Klasę można zmienić, wybierając wielokropek(...) i wybierając inną klasę. Zmienne środowiskowe Upewnij się, że wartość HADOOP_HOME jest poprawna. lokalizacja WINUTILS.exe Upewnij się, że ścieżka jest poprawna. 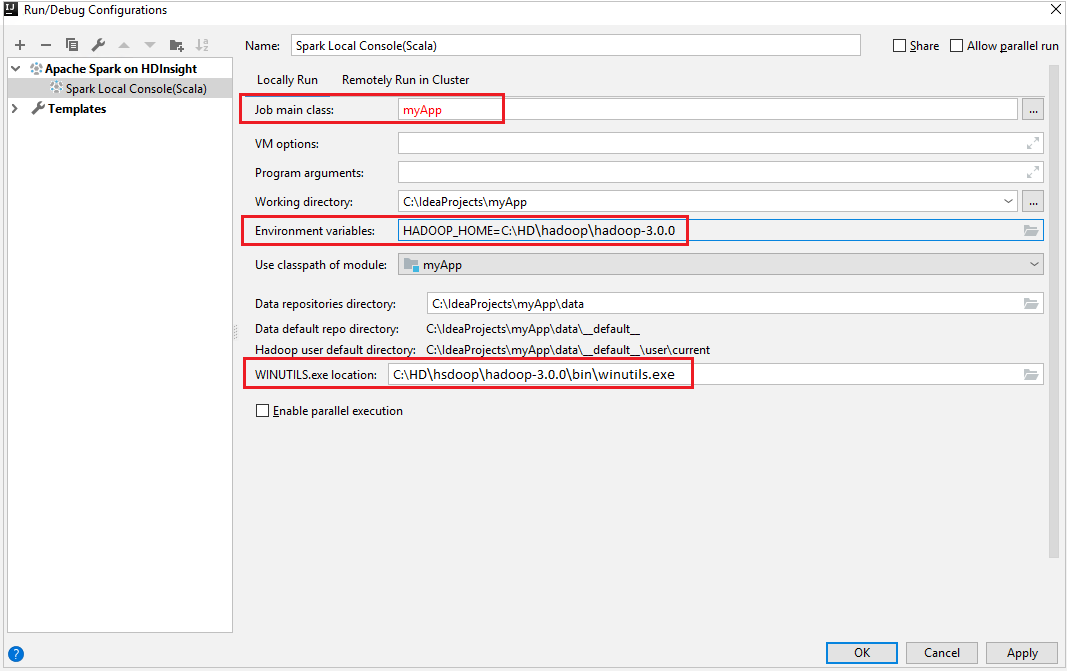
W obszarze Project przejdź do głównej>aplikacji myApp>src>myApp.>
Na pasku menu przejdź do pozycji Narzędzia>Konsola platformy Spark Uruchom konsolę>lokalną Platformy Spark (Scala).
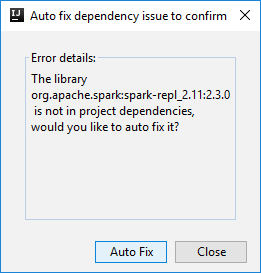
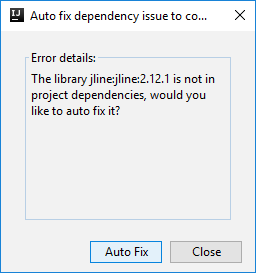
Następnie mogą zostać wyświetlone dwa okna dialogowe z pytaniem, czy chcesz automatycznie naprawić zależności. Jeśli tak, wybierz pozycję Automatyczna poprawka.
Konsola powinna wyglądać podobnie do poniższej ilustracji. W oknie konsoli wpisz
sc.appName, a następnie naciśnij klawisze Ctrl+Enter. Wynik zostanie wyświetlony. Konsolę lokalną można zakończyć, klikając czerwony przycisk.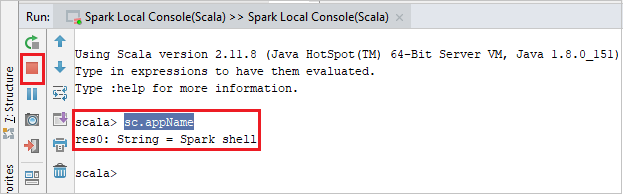
Konsola interakcyjnej sesji usługi Spark Livy (Scala)
Na pasku menu przejdź do pozycji Uruchom>konfiguracje edycji....
W oknie Uruchamianie/debugowanie konfiguracji w okienku po lewej stronie przejdź do platformy Apache Spark w usłudze HDInsight>[Spark w usłudze HDInsight] myApp.
W oknie głównym wybierz kartę
Remotely Run in Cluster.Podaj następujące wartości, a następnie wybierz przycisk OK:
Właściwości Wartość Klastry Spark (tylko system Linux) Wybierz klaster HDInsight Spark, na którym chcesz uruchomić aplikację. Nazwa klasy głównej Wartość domyślna to klasa główna z wybranego pliku. Klasę można zmienić, wybierając wielokropek(...) i wybierając inną klasę. 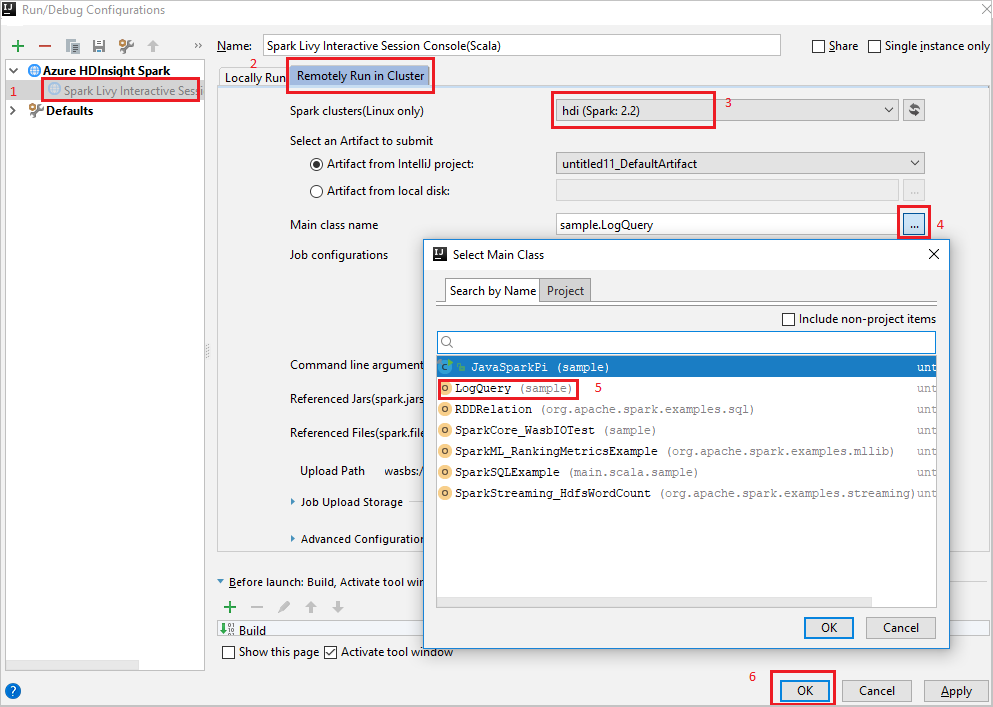
W obszarze Project przejdź do głównej>aplikacji myApp>src>myApp.>
Na pasku menu przejdź do pozycji Narzędzia>Konsola platformy Spark Uruchom konsolę>interakcyjnej sesji platformy Spark Usługi Livy (Scala).
Konsola powinna wyglądać podobnie do poniższej ilustracji. W oknie konsoli wpisz
sc.appName, a następnie naciśnij klawisze Ctrl+Enter. Wynik zostanie wyświetlony. Konsolę lokalną można zakończyć, klikając czerwony przycisk.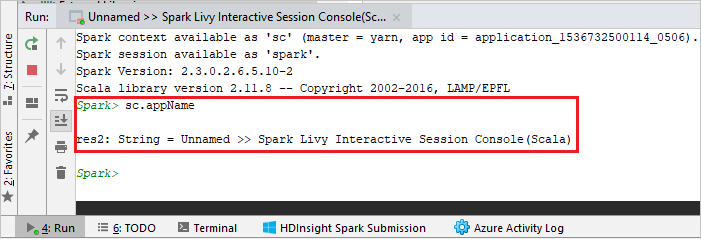
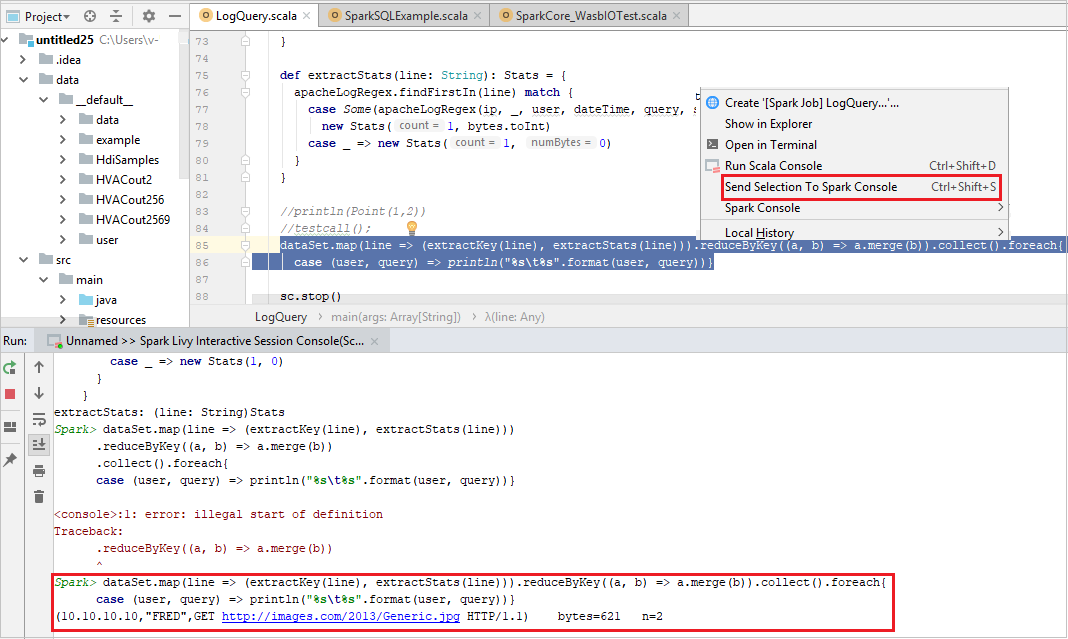
Wysyłanie zaznaczenia do konsoli platformy Spark
Wygodne jest przewidywanie wyniku skryptu przez wysłanie kodu do konsoli lokalnej lub konsoli sesji interakcyjnej usługi Livy (Scala). Możesz wyróżnić kod w pliku Scala, a następnie kliknąć prawym przyciskiem myszy pozycję Wyślij zaznaczenie do konsoli Spark. Wybrany kod zostanie wysłany do konsoli programu . Wynik zostanie wyświetlony po kodzie w konsoli programu . Konsola sprawdzi błędy, jeśli istnieje.
Integracja z usługą HDInsight Identity Broker (HIB)
Połączenie do klastra USŁUGI HDInsight ESP z brokerem identyfikatorów (HIB)
Aby zalogować się do subskrypcji platformy Azure, możesz wykonać normalne kroki, aby nawiązać połączenie z klastrem USŁUGI HDInsight ESP za pomocą brokera identyfikatorów (HIB). Po zalogowaniu zobaczysz listę klastrów w eksploratorze platformy Azure. Aby uzyskać więcej instrukcji, zobacz Połączenie do klastra usługi HDInsight.
Uruchamianie aplikacji Spark Scala w klastrze ESP usługi HDInsight z brokerem identyfikatorów (HIB)
Możesz wykonać normalne kroki, aby przesłać zadanie do klastra USŁUGI HDInsight ESP za pomocą brokera identyfikatorów (HIB). Aby uzyskać więcej instrukcji, zobacz Run a Spark Scala application on an HDInsight Spark cluster (Uruchamianie aplikacji Spark Spark w klastrze HDInsight Spark).
Przekażemy niezbędne pliki do folderu o nazwie przy użyciu konta logowania i zobaczysz ścieżkę przekazywania w pliku konfiguracji.

Konsola Spark w klastrze USŁUGI HDInsight ESP z brokerem identyfikatorów (HIB)
Możesz uruchomić konsolę lokalną platformy Spark (Scala) lub uruchomić konsolę interakcyjnej sesji platformy Spark (Scala) w klastrze USŁUGI HDInsight ESP z brokerem identyfikatorów (HIB). Aby uzyskać więcej instrukcji, zapoznaj się z konsolą platformy Spark.
Uwaga
W przypadku klastra USŁUGI HDInsight ESP z usługą Id Broker (HIB) połącz klaster i zdalne debugowanie aplikacji platformy Apache Spark nie jest obecnie obsługiwane.
Rola tylko dla czytelnika
Gdy użytkownicy przesyłają zadanie do klastra z uprawnieniami roli tylko dla czytelnika, wymagane są poświadczenia systemu Ambari.
Łączenie klastra z menu kontekstowego
Zaloguj się przy użyciu konta roli tylko dla czytelnika.
W programie Azure Explorer rozwiń węzeł HDInsight, aby wyświetlić klastry usługi HDInsight , które znajdują się w twojej subskrypcji. Klastry oznaczone jako "Role:Reader" mają uprawnienia tylko do roli tylko czytelnika.
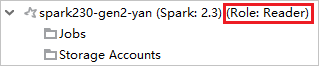
Kliknij prawym przyciskiem myszy klaster z uprawnieniem tylko do odczytu. Wybierz pozycję Połącz ten klaster z menu kontekstowego, aby połączyć klaster. Wprowadź nazwę użytkownika systemu Ambari i hasło.
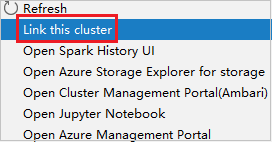
Jeśli klaster zostanie pomyślnie połączony, usługa HDInsight zostanie odświeżona. Etap klastra zostanie połączony.
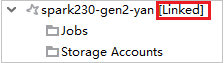
Łączenie klastra przez rozwinięcie węzła Zadania
Kliknij węzeł Zadania , zostanie wyświetlone okno Odmowa dostępu do zadań klastra .
Kliknij pozycję Połącz ten klaster , aby połączyć klaster.

Łączenie klastra z okna Uruchamianie/debugowanie konfiguracji
Utwórz konfigurację usługi HDInsight. Następnie wybierz pozycję Uruchom zdalnie w klastrze.
Wybierz klaster z uprawnieniami tylko do odczytu dla klastrów Spark (tylko system Linux). Zostanie wyświetlony komunikat ostrzegawczy. Możesz kliknąć pozycję Połącz ten klaster , aby połączyć klaster.
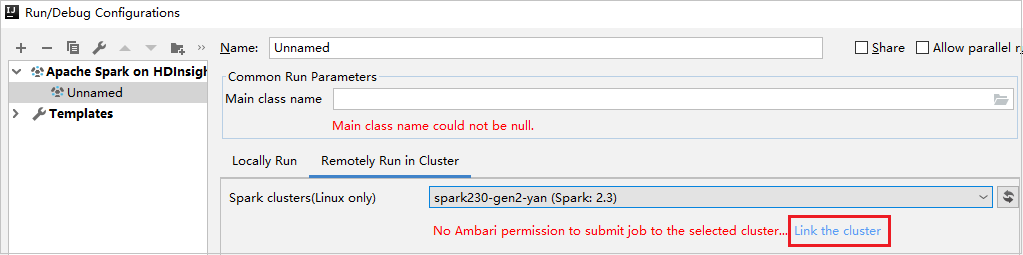
Wyświetlanie kont magazynu
W przypadku klastrów z uprawnieniami tylko do odczytu kliknij węzeł Konta magazynu, zostanie wyświetlone okno Odmowa dostępu do magazynu. Możesz kliknąć pozycję Otwórz Eksplorator usługi Azure Storage, aby otworzyć Eksplorator usługi Storage.
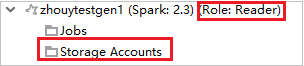

W przypadku połączonych klastrów kliknij węzeł Konta magazynu, zostanie wyświetlone okno Odmowa dostępu do magazynu. Możesz kliknąć pozycję Otwórz usługę Azure Storage, aby otworzyć Eksplorator usługi Storage.

Konwertowanie istniejących aplikacji IntelliJ IDEA na korzystanie z zestawu narzędzi Azure Toolkit for IntelliJ
Istniejące aplikacje Spark Scala utworzone w środowisku IntelliJ IDEA można przekonwertować na zgodne z zestawem narzędzi Azure Toolkit for IntelliJ. Następnie możesz użyć wtyczki, aby przesłać aplikacje do klastra Spark usługi HDInsight.
W przypadku istniejącej aplikacji Spark Scala utworzonej za pomocą środowiska IntelliJ IDEA otwórz skojarzony
.imlplik.Na poziomie głównym element modułu jest podobny do następującego tekstu:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Edytuj element w celu dodania
UniqueKey="HDInsightTool", aby element modułu wyglądał podobnie do następującego tekstu:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Zapisz zmiany. Aplikacja powinna być teraz zgodna z zestawem narzędzi Azure Toolkit for IntelliJ. Możesz ją przetestować, klikając prawym przyciskiem myszy nazwę projektu w programie Project. Menu podręczne zawiera teraz opcję Prześlij aplikację Spark do usługi HDInsight.
Czyszczenie zasobów
Jeśli nie zamierzasz nadal korzystać z tej aplikacji, usuń utworzony klaster, wykonując następujące czynności:
Zaloguj się w witrynie Azure Portal.
W polu Wyszukaj w górnej części wpisz HDInsight.
Wybierz pozycję Klastry usługi HDInsight w obszarze Usługi.
Na wyświetlonej liście klastrów usługi HDInsight wybierz pozycję ... obok klastra utworzonego na potrzeby tego artykułu.
Wybierz Usuń. Wybierz opcję Tak.
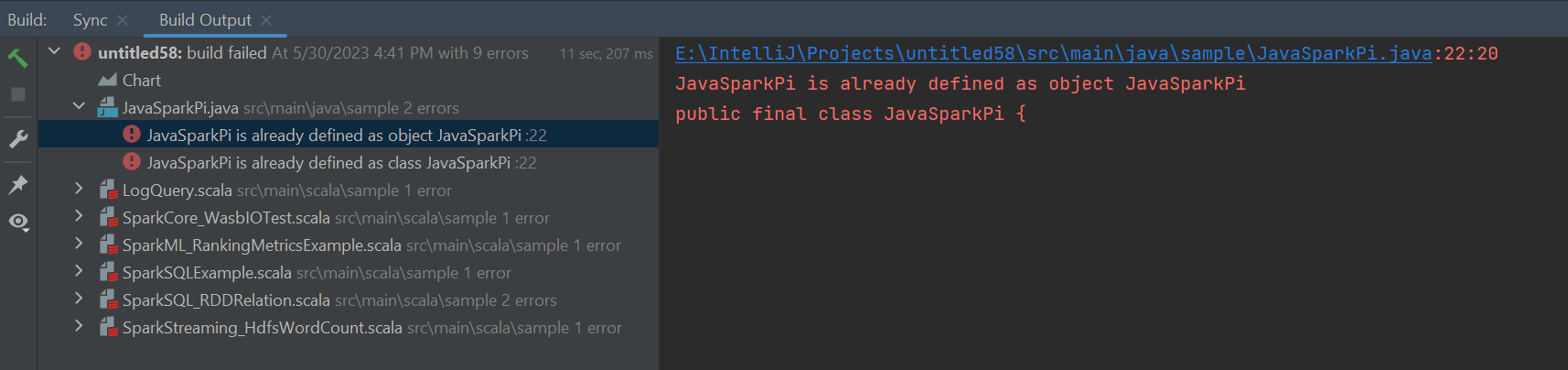
Błędy i rozwiązanie
Usuń oznaczenie folderu src jako Źródła , jeśli kompilacja nie powiodła się, jak pokazano poniżej:
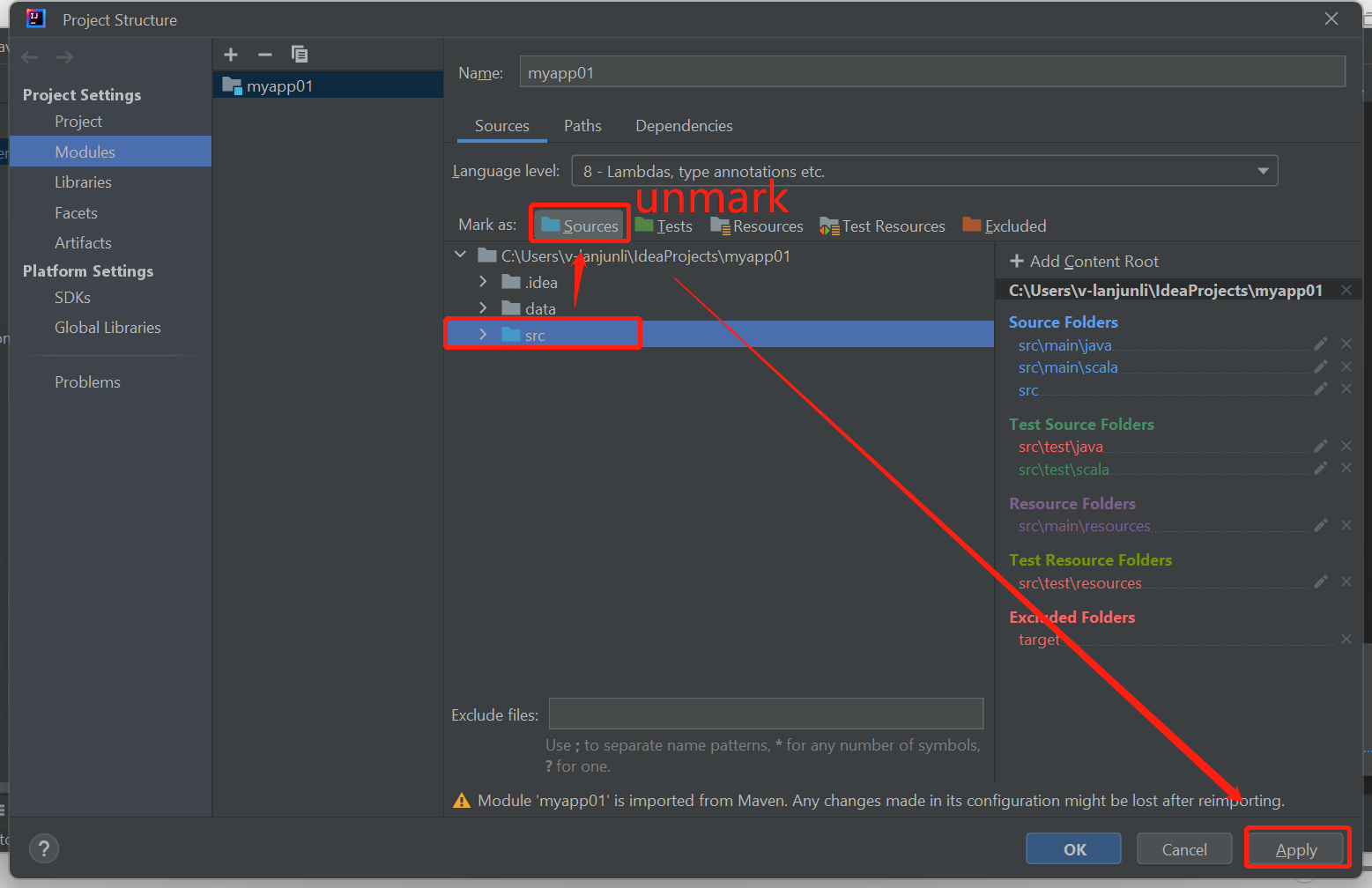
Usuń oznaczenie folderu src jako Źródła , aby rozwiązać ten problem:
Przejdź do pozycji Plik i wybierz strukturę projektu.
Wybierz moduły w obszarze Ustawienia projektu.
Wybierz plik src i usuń znacznik jako Źródła.
Kliknij przycisk Zastosuj, a następnie kliknij przycisk OK, aby zamknąć okno dialogowe.
Następne kroki
W tym artykule przedstawiono sposób używania wtyczki Azure Toolkit for IntelliJ do tworzenia aplikacji platformy Apache Spark napisanych w języku Scala. Następnie przesłano je do klastra Spark usługi HDInsight bezpośrednio ze zintegrowanego środowiska projektowego IntelliJ (IDE). Przejdź do następnego artykułu, aby dowiedzieć się, w jaki sposób można ściągnąć dane zarejestrowane na platformie Apache Spark do narzędzia analizy biznesowej, takiego jak usługa Power BI.