Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym przewodniku szybkiego startu utworzysz klaster Apache Spark w usłudze Azure HDInsight za pomocą Portalu Azure. Następnie utworzysz Jupyter Notebook i użyjesz go do uruchamiania zapytań Spark SQL względem tabel Apache Hive. Azure HDInsight to zarządzana usługa analizy typu open source o pełnym spektrum dla przedsiębiorstw. Platforma Apache Spark dla usługi HDInsight umożliwia szybką analizę danych i przetwarzanie klastrów przy użyciu przetwarzania w pamięci. Jupyter Notebook umożliwia interakcję z danymi, łącząc kod z tekstem markdown oraz wykonując proste wizualizacje.
Aby uzyskać szczegółowe wyjaśnienia dotyczące dostępnych konfiguracji, zobacz Konfigurowanie klastrów w usłudze HDInsight. Aby uzyskać więcej informacji na temat używania portalu do tworzenia klastrów, zobacz Tworzenie klastrów w portalu.
Jeśli używasz wielu klastrów razem, możesz utworzyć sieć wirtualną, lub jeśli korzystasz z klastra Spark, możesz również chcieć użyć Hive Warehouse Connector. Aby uzyskać więcej informacji, zobacz Planowanie sieci wirtualnej dla usługi Azure HDInsight i Integracja platformy Apache Spark oraz Apache Hive za pomocą łącznika magazynu Hive.
Ważne
Rozliczenia dla klastrów usługi HDInsight są rozliczane proporcjonalnie na minutę, bez względu na ich użycie. Pamiętaj, aby usunąć klaster po zakończeniu korzystania z niego. Aby uzyskać więcej informacji, zobacz sekcję Oczyszczanie zasobów w tym artykule.
Wymagania wstępne
Konto Azure z aktywną subskrypcją. Utwórz konto bezpłatnie.
Tworzenie klastra Apache Spark w usłudze HDInsight
Portal Azure służy do tworzenia klastra HDInsight, który używa obiektów blob w Azure Storage jako magazynu dla klastra. Aby uzyskać więcej informacji na temat korzystania z usługi Data Lake Storage Gen2, zobacz Szybki start: konfigurowanie klastrów w usłudze HDInsight.
Zaloguj się do witryny Azure Portal.
W menu górnym wybierz pozycję + Utwórz zasób.
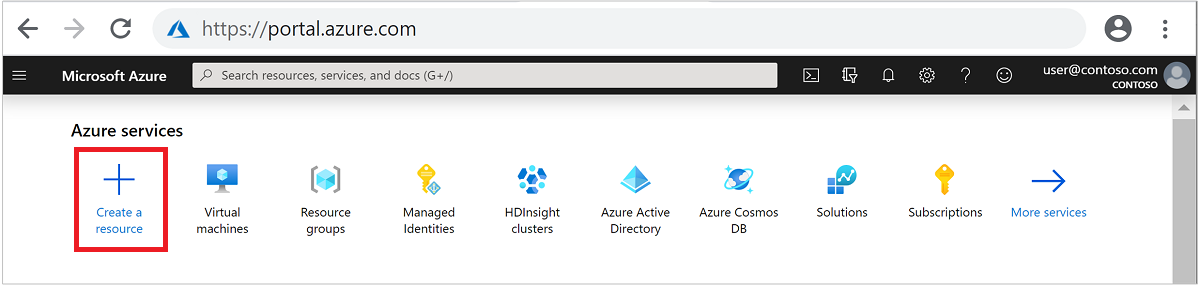
Wybierz Analytics>Azure HDInsight, aby przejść do strony Tworzenie klastra HDInsight.
Na karcie Podstawowe podaj następujące informacje:
Majątek Description Subscription Z listy rozwijanej wybierz subskrypcję platformy Azure używaną dla klastra. Grupa zasobów Z listy rozwijanej wybierz istniejącą grupę zasobów lub wybierz pozycję Utwórz nową. Nazwa klastra Wprowadź globalnie unikatową nazwę. Region Z listy rozwijanej wybierz region, w którym jest tworzony klaster. Strefa dostępności Opcjonalnie — określ strefę dostępności, w której ma zostać wdrożony klaster Typ klastra Wybierz typ klastra, aby otworzyć listę. Z listy wybierz pozycję Spark. Wersja klastra To pole zostanie automatycznie wypełnione wersją domyślną po wybraniu typu klastra. Nazwa użytkownika logowania klastra Wprowadź nazwę użytkownika logowania klastra. Domyślną nazwą jest administrator. To konto służy do logowania się do notesu Jupyter Notebook w dalszej części przewodnika Szybki start. Hasło logowania do klastra Wprowadź hasło logowania klastra. Nazwa użytkownika protokołu SSH (Secure Shell) Wprowadź nazwę użytkownika protokołu SSH. Nazwa użytkownika SSH używana do tego szybkiego startu to sshuser. Domyślnie to konto ma takie samo hasło jak konto użytkownika logowania klastra. 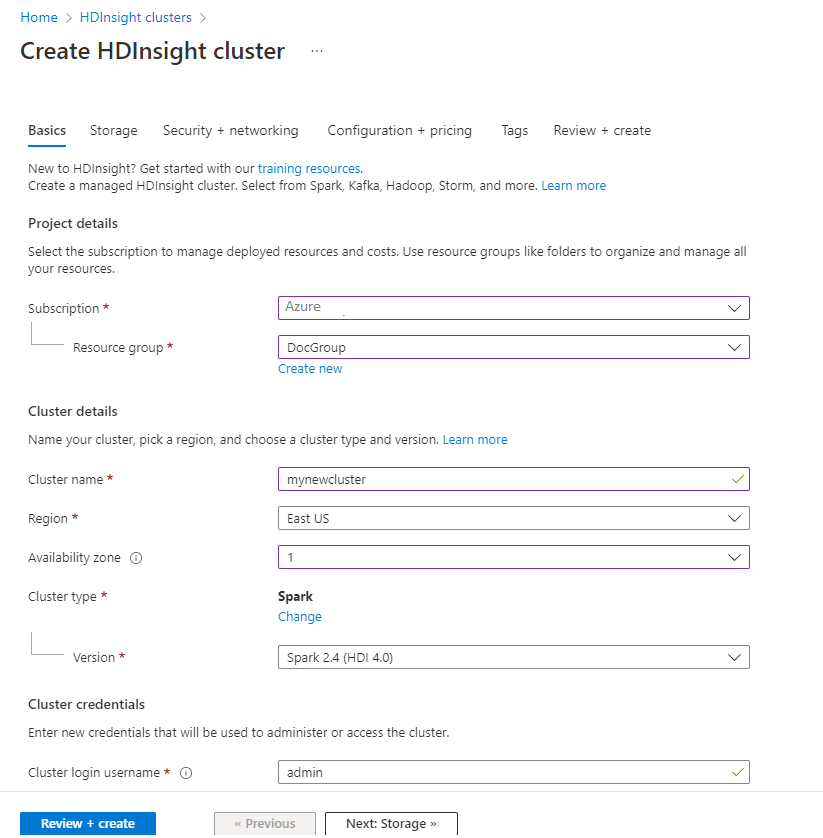
Wybierz Dalej: Magazyn>>, aby przejść do strony Magazyn.
W obszarze Magazyn podaj następujące wartości:
Majątek Description Podstawowy typ magazynu Użyj wartości domyślnej usługi Azure Storage. Metoda wybierania Użyj wartości domyślnej Wybierz z listy. Konto magazynu podstawowego Użyj wartości wypełnionej automatycznie. Pojemnik Użyj wartości wypełnionej automatycznie. 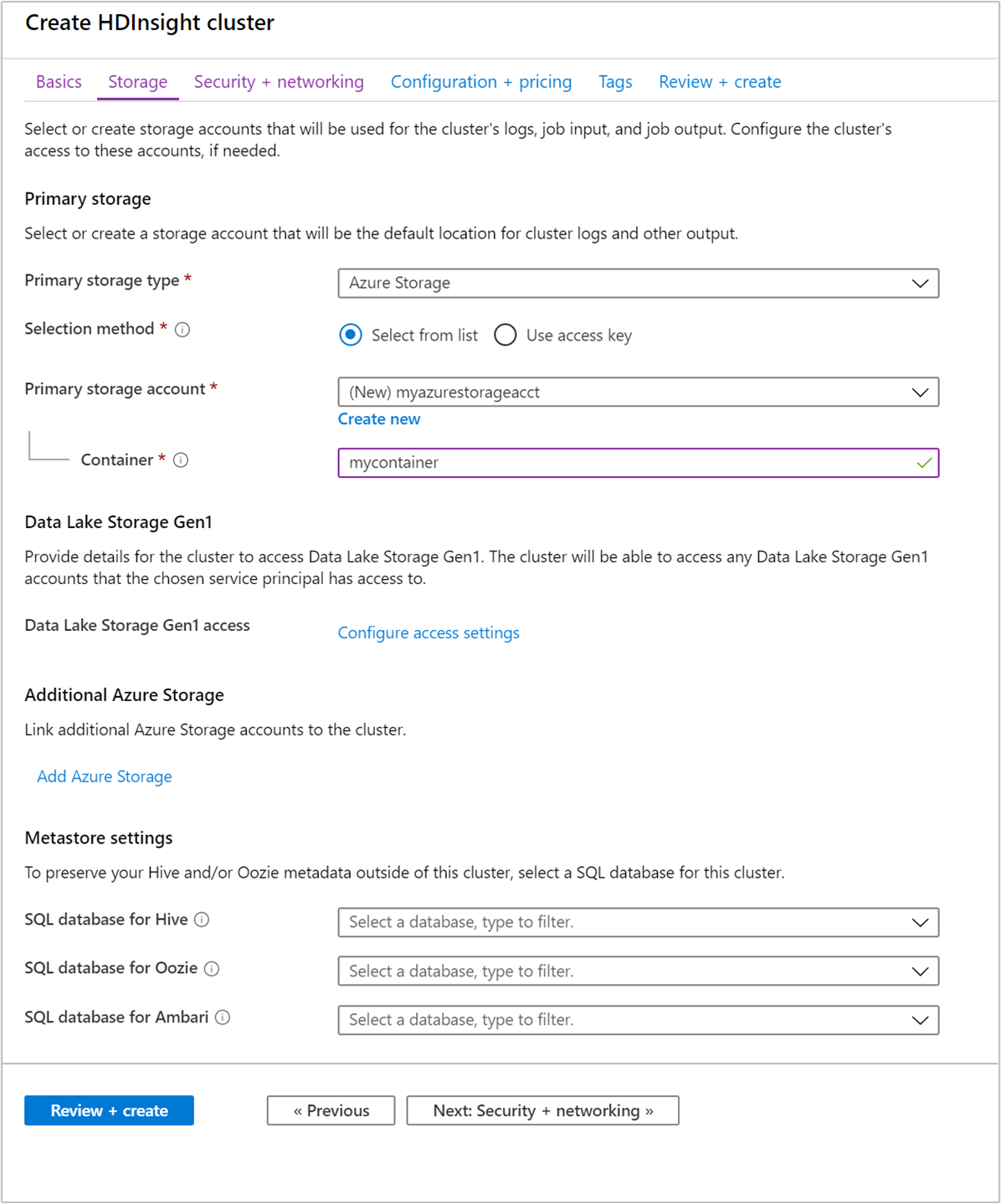
Wybierz pozycję Przejrzyj i utwórz , aby kontynuować.
W obszarze Przeglądanie i tworzenie wybierz pozycję Utwórz. Utworzenie klastra trwa około 20 minut. Przed przejściem do następnej sesji należy utworzyć klaster.
Jeśli wystąpi problem z tworzeniem klastrów usługi HDInsight, może to oznaczać, że nie masz odpowiednich uprawnień do tego. Aby uzyskać więcej informacji, zobacz Wymagania dotyczące kontroli dostępu.
Tworzenie notesu Jupyter
Jupyter Notebook to interaktywne środowisko notesu, które obsługuje różne języki programowania. Notatnik umożliwia interakcję z danymi, łączenie kodu z tekstami w markdown i wykonywanie prostych wizualizacji.
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.net/jupyter, gdzieCLUSTERNAMEjest nazwą klastra. Jeśli zostanie wyświetlony monit, wprowadź poświadczenia logowania do klastra.Wybierz pozycję Nowy>PySpark , aby utworzyć notes.
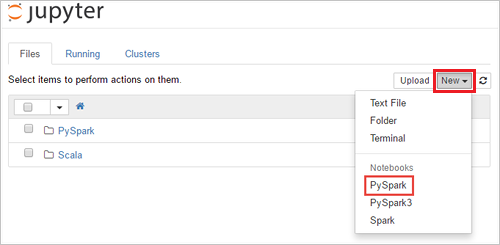
Tworzony jest i otwierany nowy notes o nazwie Untitled(Untitled.pynb).
Uruchamianie instrukcji Apache Spark SQL
SQL (ustrukturyzowany język zapytań) jest najczęściej używanym językiem do wykonywania zapytań i definiowania danych. Platforma Spark SQL działa jako rozszerzenie platformy Apache Spark do przetwarzania danych strukturalnych przy użyciu znanej składni SQL.
Sprawdź, czy jądro jest gotowe. Jądro jest gotowe po wyświetleniu pustego koła obok nazwy jądra w notesie. Stałe koło oznacza, że jądro jest zajęte.

Po pierwszym uruchomieniu notesu jądro wykonuje niektóre zadania w tle. Poczekaj, aż jądro będzie gotowe.
Wklej następujący kod w pustej komórce, a następnie naciśnij SHIFT + ENTER , aby uruchomić kod. Polecenie wyświetla listę tabel programu Hive w klastrze:
%%sql SHOW TABLESJeśli używasz notesu Jupyter z klastrem usługi HDInsight, uzyskasz ustawienie wstępne
sqlContext, którego można użyć do uruchamiania zapytań programu Hive przy użyciu usługi Spark SQL.%%sqlinstruuje Jupyter Notebook, aby użył ustawienia wstępnegosqlContextdo uruchomienia zapytania Hive. Zapytanie pobiera 10 pierwszych wierszy z tabeli Programu Hive (hivesampletable), która jest domyślnie dostarczana ze wszystkimi klastrami usługi HDInsight. Uzyskanie wyników zajmuje około 30 sekund. Dane wyjściowe wyglądają następująco: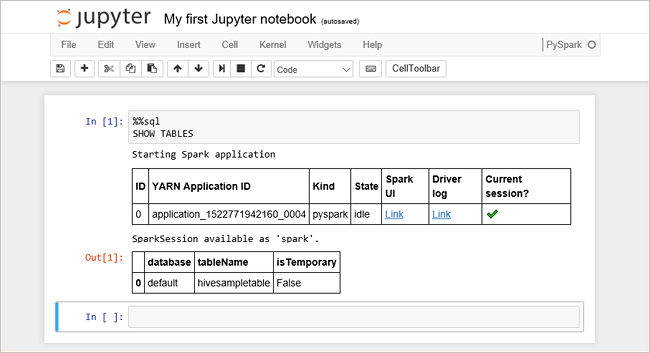 is quickstart." border="true":::
is quickstart." border="true":::Za każdym razem, gdy uruchamiasz zapytanie w programie Jupyter, tytuł okna przeglądarki internetowej wyświetla stan (Zajęty) wraz z tytułem notesu. Obok tekstu PySpark w prawym górnym rogu zobaczysz również solidne kółko.
Uruchom inne zapytanie, aby wyświetlić dane w pliku
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10Ekran zostanie odświeżyny, aby wyświetlić dane wyjściowe zapytania.
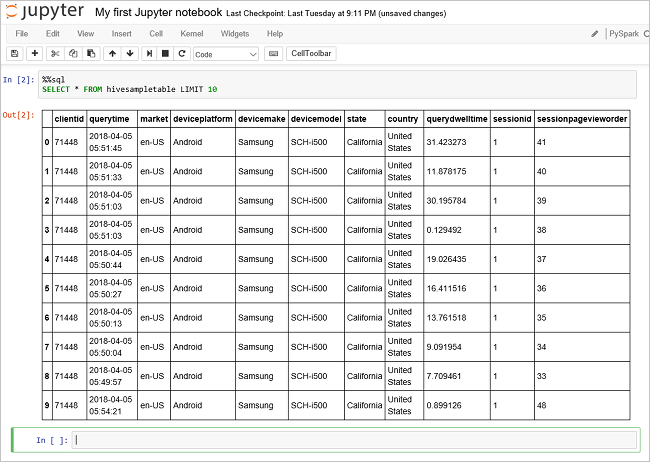 Insight" border="true":::
Insight" border="true":::W menu Plik w notesie wybierz pozycję Zamknij i zatrzymaj. Wyłączenie laptopa zwalnia zasoby klastra.
Uprzątnij zasoby
Usługa HDInsight zapisuje dane w usłudze Azure Storage lub Azure Data Lake Storage, dzięki czemu można bezpiecznie usunąć klaster, gdy nie jest używany. Opłaty są również naliczane za klaster usługi HDInsight, nawet jeśli nie jest używany. Ponieważ opłaty za klaster są wielokrotnie większe niż opłaty za magazyn, warto usunąć klastry, gdy nie są używane. Jeśli planujesz pracować nad samouczkiem wymienionym w sekcji Następne kroki od razu, możesz chcieć pozostawić klaster.
Wróć do witryny Azure Portal i wybierz pozycję Usuń.
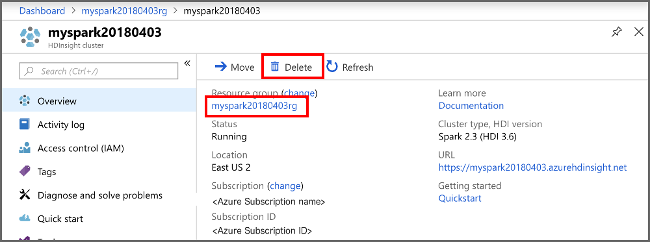 sight cluster" border="true":::
sight cluster" border="true":::
Możesz również wybrać nazwę grupy zasobów, aby otworzyć stronę grupy zasobów, a następnie wybrać pozycję Usuń grupę zasobów. Usunięcie grupy zasobów powoduje również usunięcie klastra HDInsight oraz domyślnego konta magazynowania.
Dalsze kroki
W tym przewodniku Szybki start przedstawiono sposób tworzenia klastra Apache Spark w usłudze HDInsight i uruchamiania podstawowego zapytania Spark SQL. Przejdź do następnego samouczka, aby dowiedzieć się, jak używać klastra usługi HDInsight do uruchamiania interakcyjnych zapytań dotyczących przykładowych danych.